
오배이안 🪙
웹 애플리케이션 아키텍처
클라이언트 - 서버 아키텍처
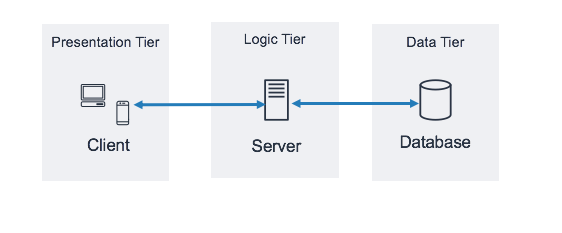
클라이언트- 서버 아키텍처(2-Tier 아키텍처)
리소스를 사용하는 앱(클라이언트) 와 리소스가 존재하는 곳(서버)를 분리시킨 것
클라이언트- 서버 는 요청과 응답을 주고 받는 관계 ( 선 요청 --> 후 응답 )
- 3-Tier 아키텍처
클라이언트---서버---데이터베이스기존의 2티어 아키텍처에 데이터베이스가 추가된 형태를 3티어 아키텍처라고 부른다.
서버는 저장되어 있는 리소스를 전달해주는 역할만 담당한다.
이때 리소스가 저장되어 있는 공간을데이터베이스라고 부른다.
데이터베이스는 창고 같은 역할을 한다.
- 리소스를 사용하는 앱 (클라이언트) 의 종류
클라이언트는 플랫폼에 따라 구분된다.
브라우저의 웹 플랫폼 : 웹 앱
스마트폰/태블릿 플랫폼 : 스마트폰/태블릿용 앱
데스크탑(Pc) 플랫폼 : 데스크탑 앱
- 서버도 무엇을 하느냐에 따라 종류가 달라진다.
웹 서버
파일서버
메일서버
데이터베이스 서버 : 데이터베이스도 데이터 제공자로서 일하니까 서버라고 볼 수 있다.
클라이언트 - 서버의 통신
클라이언트와 - 서버의 통신은
요청 --> 응답으로 구성된다.
서버에서 먼저 마음대로 응답하지 않는다는 말이다. 클라이언트에서 요청이 있어야 응답도 있는 것
클라이언트가 요청을 할 시에는 프로토콜을 지켜서 요청을 해야한다.
프로토콜이란?
프로토콜은 통신 규약, 즉 약속이다.
클라이언트가 서버에게 원하는 리소스를 요청할 시에 지켜야 하는 약속이 몇 가지 존재한다.그 중
웹 애플리케이션 아키텍쳐는HTTP라는 프로토콜을 이용해 클라이언트인 브라우저와 서버가 서로 대화를 나눈다.
HTTP를 통해 주고 받는 메세지를HTTP 메세지라고 부른다.
- API (Application Programming Interface)
다른 소프트웨어 시스템과 데이터를 주고 받기 위해 따라야 하는 규칙들 (일종의 메뉴?)
클라이언트가 프로토콜을 지키면서 서버에게 리소스를 요청을 해야하는데 서버가 어떻게 구성되어 있는지 모른다면?
마치 식당을 갔는데 메뉴판이 없어 무엇을 파는지 모르는 것과 같은 상황이다.
이런 경우에서버는 클라이언트가 리소스를 잘 활용할 수 있도록인터페이스 (Interface)를 제공해줘야한다. (메뉴판을 제공해줘야한다는 뜻)서버가 리소스 전달을 위한 메뉴판, 즉 API를 구축해놓아야 클라이언트가 이를 활용할 수 있다.
HTTP API
보통 인터넷상에서 브라우저와 서버간에 데이터를 요청할 때에는 HTTP라는 프로토콜을 사용하며, 주소(URL, URI)를 통해 접근할 수 있다.
웹 상에는 브라우저(클라이언트)가 서버에게 데이터를 요청할때 사용하라고 만든
HTTP API가 존재하는데,
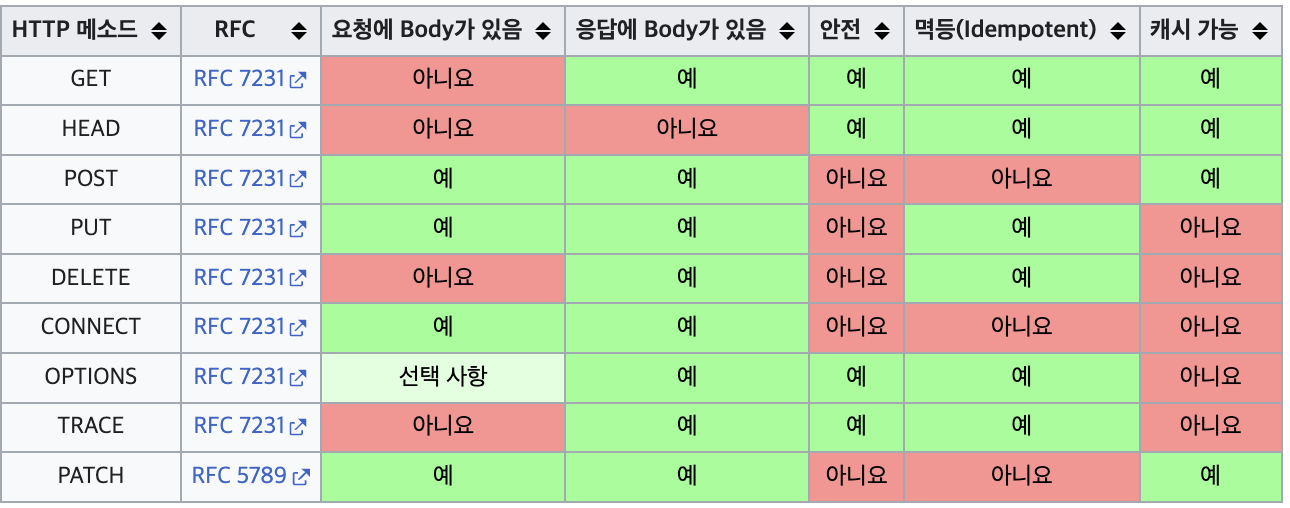
HTTP API에는 클라이언트가 서버에 데이터를 요청할때 사용하는메서드가 존재한다.
- Create(추가,생성) : POST 메소드
- Read (조회) : GET 메소드
- Update( 갱신) : PUT 또는 PATCH 메소드
- Delete ( 삭제) : DELETE 메소드
HTTP 메서드는 리소스를 이용하여, 하려는 행동에 맞게 적절하게 써야 한다는 점에 주의해야한다.
만일 GET 요청을 했는데 갑자기 서버에서 리소스가 지워진다면 좋은 API 디자인이라고 볼 수 없다.
HTTP 메서드 요약 정리
출처 : 위키백과
브라우저의 작동 원리 (보이지 않는 곳)
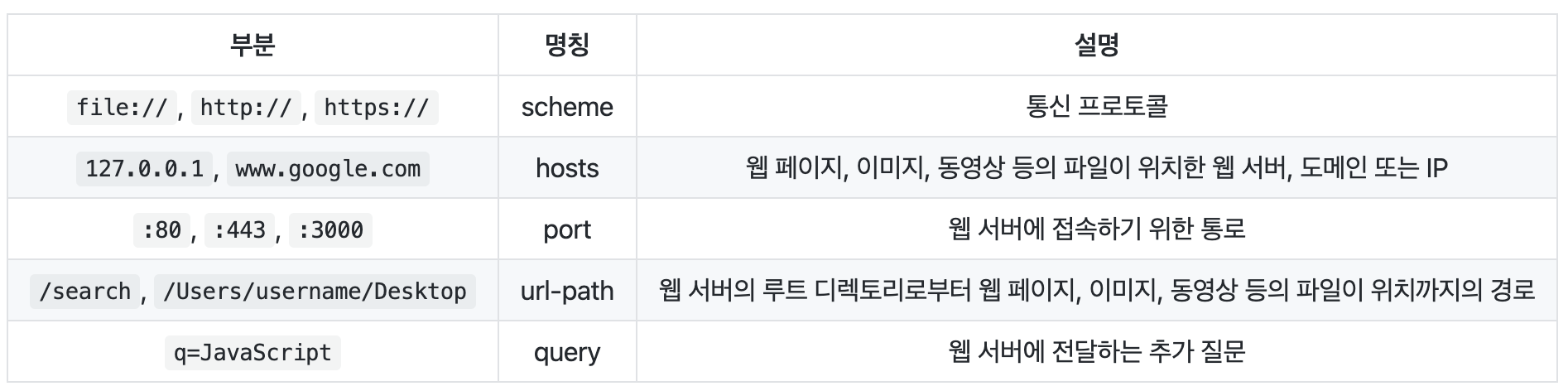
URL (Uniform Resource Locator)
URL 이란 네트워크 상에서 웹 페이지, 이미지, 동영상 등의 파일이 위치한 정보를 나타낸다.
URL은scheme, hosts, url-path로 구분할 수 있다.
URI (Uniform Resource Identifier)
URI는 URL의 기본 요소인
scheme, hosts, url-path+query, fragment를 포함한다.
fragment는 일종의 북마크 기능을 수행하며 URL에 fragment(#)와 특정 HTML 요소의 id를 전달하면 해당 요소가 있는 곳으로 스크롤을 이동할 수 있다.
브라우저의 검색창을 클릭하면 나타나는 주소가
URI이다.
URI는URL을 포함하는 상위개념 이다. 따라서,URL은 URI다.는 참이고,URI는 URL이다.는 거짓입니다.
출처 : 코드스테이츠
url-path과queryurl-path: 어떤 리소스를 식별하고 싶을 때 사용
query: 정렬이나 필터링을 원하는 경우에는 query 파라미터를 사용
- IP ( Internet Protocol )
인터넷 상에서 사용하는 주소 체계를 의미한다.
인터넷에 연결된 모든 pc는 IP 주소 체계에 따라333.333.33.3형태로 네 덩이의 숫자로 구분되는데 각 덩이마다 0~255 사이의 숫자가 들어갈 수 있다. 이를IPv4라고한다.
IPv4주소 체계에는 용도가 정해져 있는 IP주소가 있다.
localhost,127.0.0.1: 현재 사용 중인 로컬 PC를 지칭함0.0.0.0,255.255.255.255: IP주소를 이렇게 저장하게 되면 모든 기기에서 이 서버에 접근할 수 있게 된다.컴퓨터 보급률이 전세계적으로 높아 짐에 따라
IPv4로 할당할 수 있는 pc가 한계를 넘어서게 되어IPv6라는 새로운 주소 체계가 나왔다.
- PORT
localhost뒤에:3001과 같은 숫자를POST라고한다.
POST 는 IP 주소가 가리키는 PC에 접속할 수 있는 통로(채널)을 의미한다.
이미 사용 중인 포트는 중복해서 사용할 수 없다.포트는 0 ~65535 까지 사용할 수 있고 그 중 0~1024 번 까지의 포트 번호는 주요 통신을 위한 규약에 따라 이미 정해져 있다.
하지만 이미 정해진 포트라도 필요에 따라 자유롭게 사용할 수 있다.
- 알아야할 포트번호
22 : SSH
80 : HTTP
443 : HTTPS

- Domain name
IP 주소를 대신하여 사용할 수 있는 주소로 IP 가 숫자로 이루어진 덩이 였다면 도메인은 문자로 이루어진 주소라고 생각하면 된다.
naver, google 등도메인 이름을 사용하게 되면 한눈에 파악하기 힘든 IP주소를 보다 간단하게 나타낼 수 있다.
터미널에서 도메인 이름을 통해 IP주소를 확인하는 명령어
nslookup를 활용해 IP 주소를 알아낼 수 있다.
- DNS
도메인 이름과 매칭된 IP 주소를 확인하는 작업을 하는 네트워크 상 서버를 DNS(Domain Name System)이라고 한다
DNS는 호스트의 도메인 이름을 IP 주소로 변환하거나 반대의 경우를 수행할 수 있도록 개발된 데이터베이스 시스템이다.
HTTP
HTTP란?HTML 과 같은 문서를 전송하기 위한 프로토콜이고,
웹 브라우저와 <---> 웹 서버의 소통을 위해 디자인 된 프로토콜이다.
HTTP특징Stateless
무상태성으로 HTTP는 클라이언트와 서버의 상태를 확인하지 않는다. 상태를 저장하고 싶으면 쿠키나 세션, API 를 통해서 상태를 저장해야한다.
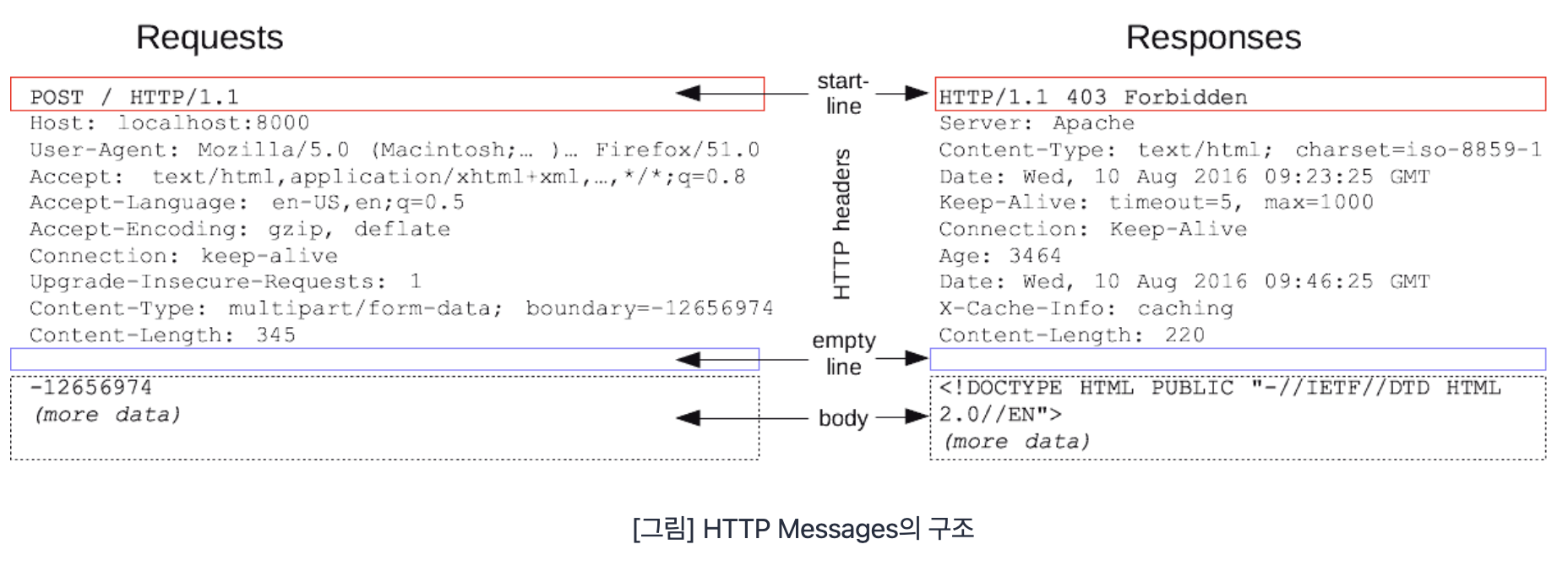
HTTP Messages클라이언트와 서버 사이에 데이터가 교환 되는 방식을 말한다. 이에는 두가지 유형이 존재한다.
- 요청(Requests)
- 응답(Responses)
HTTP Messages의 요청과 응답의 구조
start line:요청이나 응답의 상태를 나타내고, 항상 첫 번째 줄에 위치합니다.
응답에서는status line이라고 부른다.
HTTP headers: 요청을 지정하거나, 메시지에 포함된 본문을 설명하는 헤더의 집합
empty line: 헤더와 본문을 구분하는 빈 줄
body: 요청과 관련된 데이터나 응답과 관련된 데이터 또는 문서를 포함하고, 요청과 응답의 유형에 따라 선택적으로 사용start line과 HTTP headers를 묶어 요청이나
응답의 헤드(head)라고 하고, body를payload라고 이야기한다.body부분은 메소드에 따라 있을 수도 있고 없을 수도 있다.사진출처 : 코드스테이츠
HTTP Requests: 클라이언트가 서버에게 보내는 메세지
body는 GET, DELETE처럼 서버에 리소스를 요청하는 경우에는 필요하지 않고,
POST나 PUT과 같은 일부 요청은 데이터를 업데이트하기 위해 사용한다.
HTTP Responses: 서버가 클라이언트에게 보내는 메서지
status line에는현재 프로토콜의 버전,상태 코드,상태 텍스트가 적힌다.
body는 201, 204와 같은 상태 코드를 가지는 응답에는 본문이 필요없다.? 201은 새로운 리소스가 생성된 것이니까 응답이 필요한거 아닌가?,,,,🤔
상태 코드 (메서드에 따라 요청이 성공적으로 이루어 졌는지! )
성공
200 ok: 요청이 성공적으로 되었음 (주로 GET 메서드)201 created: 요청이 성공적으로 되었고 그 결과 새로운 리소스가 생성됨 (주로 POST 메서드)204 no content: 리소스가 성공적으로 삭제 되었음, 응답 본문이 없다.(주로 DELETE 메서드)
리다이렉션 메세지
304 not modified: 이전에 전달해준거야~ 캐시에 남아 있어~ 캐쉬에서 자원을 사용해~(응답으로)
클라이언트 실패
400 bad request: 잘못된 문법으로 요청했다~ 문법 고쳐라~ 서버는 이해할 수 없다.401 unathorized: 요청에 사용자 인증이 필요해~ (서버는 클라이언트가 누군지 모름)403 forbidden: 너(클라이언트) 나(서버) 한테 접근할 권한이 없어 ~(서버는 클라가 누군지는 알고 있음)404 not found: 요청 받은 리소스를 찾을 수 없어~ (서버 한테 있는 리소스(정보)야?)
서버 실패
500 internal sever error: 서버가 처리 방법을 모르는 상황 (아직 서버는 처리 방법을 모릅니다.)
브라우저의 작동 원리 (보이는 곳)
- AJAX (Asynchronous JavaScript And XMLHttpRequest)
JavaScript, DOM, Feach 를 활용해 웹 페이지를 비동기적으로 구현하는 기법
기존에는 웹 페이지에서 변경될 데이터가 있을 때마다 서버에서 변경될 데이터를 포함한 웹 페이지 전체 데이터를 가져와 렌더링 하기 때문에 화면 깜빡임 현상이 일어난다.
하지만AJAX를 사용하면 웹 페이지에서 변경될 데이터가 있는 경우에는 서버에서 변경될 데이터만을 보내면 되기 때문에 화면 깜빡임 현상없이 화면에서 변경될 부분만 리렌더링된다.
- AJAX 장점
1. 서버에서 HTML을 완성하여 보내주지 않아도 웹페이지를 만들 수 있다. CSR
원하는 부분의 데이터만 비동기적으로 받기 때문에 속도측면에서도 유리하고 화면 깜빡임(리렌더링)도 없다.
- 유저 중심의 애플리케이션 개발
- 표준화된 방법
- 더 작은 대역폭(네트워트 통신 한번에 보낼 수 있는 데이터 크기)
- AJAX 단점
- Search Engine Optimization(SEO)에 불리하다.
HTML문서는 뼈대만 있고 모든 코드들이 JavaScript로 이루어져 있기 때문에 HTML을 기준으로 검색 키워드를 찾는 SEO에 불리하다.
- 이전상태를 기억 못함
뒤로가기 버튼을 누르면 이전 페이지가 보이는 것과 같이 이전상태를 기억하기 위해선 별도로History API를 사용해야한다. AJAX는 이전 상태를 기억하지 않기 때문이다.
SSR & CSR
SSR & CSR 는 어디에서 렌더링 되느냐에 따른 나뉜다.
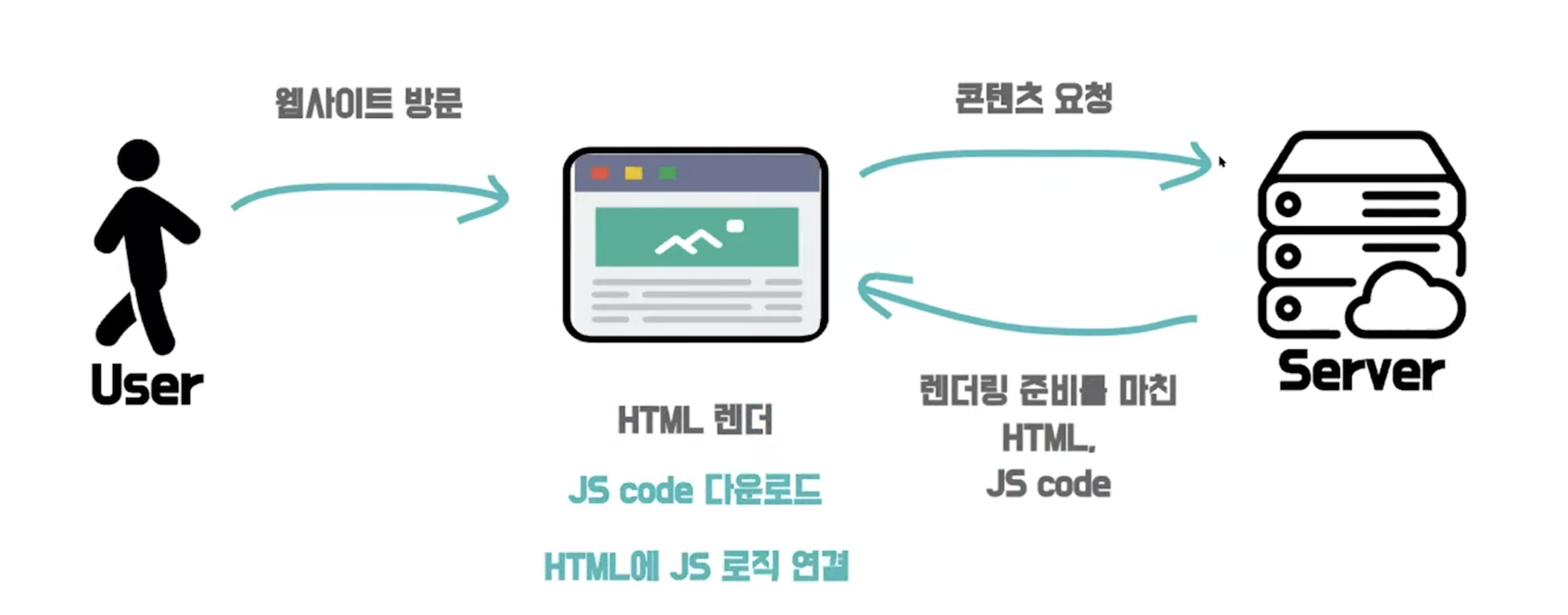
- SSR (Server Side Rendering)
SSR은 웹 페이지의 렌더링을 브라우저에서 하는게 아닌 서버에서 렌더링을 하는 것을 말한다.
서버에서 데이터를 보내줄때 모든 데이터가 HTML에 들어가 있고 JS파일을 따로 준비해서 같이 브라우저로 보내준다.
SSR동작과정
- 유저가 웹 사이트 방문 시 브라우저가 서버에게 요청을 보냄
- 서버에서 HTML 파일을 렌더링한 후 해당 HTML 파일과 JS파일을 브라우저로 응답을 보냄
- 브라우저에서는 전달받은 HTML 파일을 렌더링한 후 후 JS파일을 다운로드 하고 HTML에 JS 로직을 연결
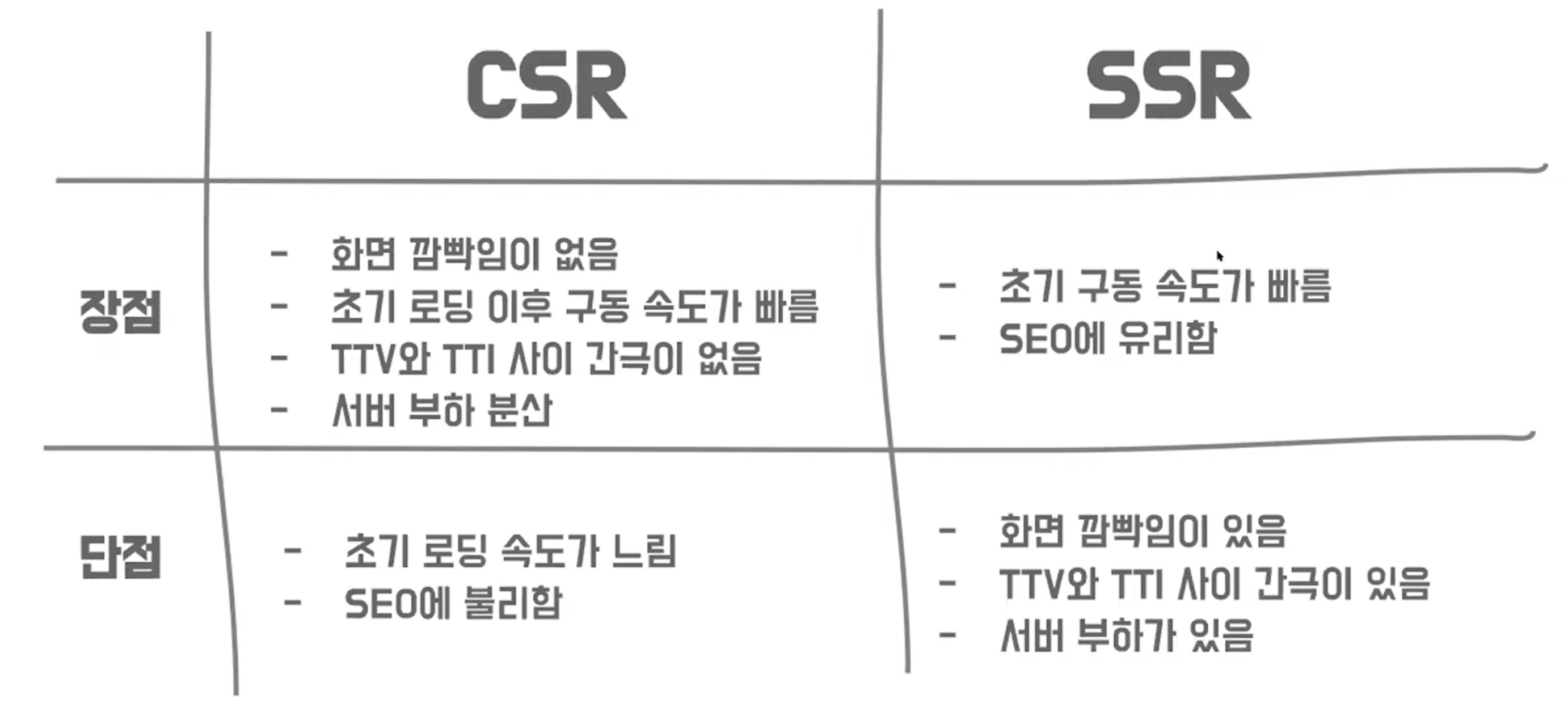
장점
- 서버에서 HTML에 모든 데이터를 넣고 렌더링을 하기 때문에 검색최적화엔진인
SEO에 유리하다.- 서버에서 렌더링된 화면을 가져오기 때문에 초기 구동 속도가 빠르다는 장점이 있다.
단점
- 브라우저는 서버에서 전달받은 렌더링된 HTML 파일을 바로 보여주긴 하지만 JS 파일은 다운 후 로직을 연결하기 까지 걸리는 시간이 있기 때문에 그 시간 사이에 사용자가 버튼을 클릭하거나 이동하려고하면 아무 반응이 없을 수가 있다.
이것을 TTI(Time to Interact)(반응) 와 TTV(Time to view)(보여지는것) 사이에 시간 간격이 존재한다고 한다.
화면 깜빡임이 있다. (요청시마다 항상 새로운 페이지를 렌더링하니까)
사용자가 많아질수록 요청도 많아지기 때문에 서버의 부하가 있을 수 있다.
- CSR(Client Side Rendering)
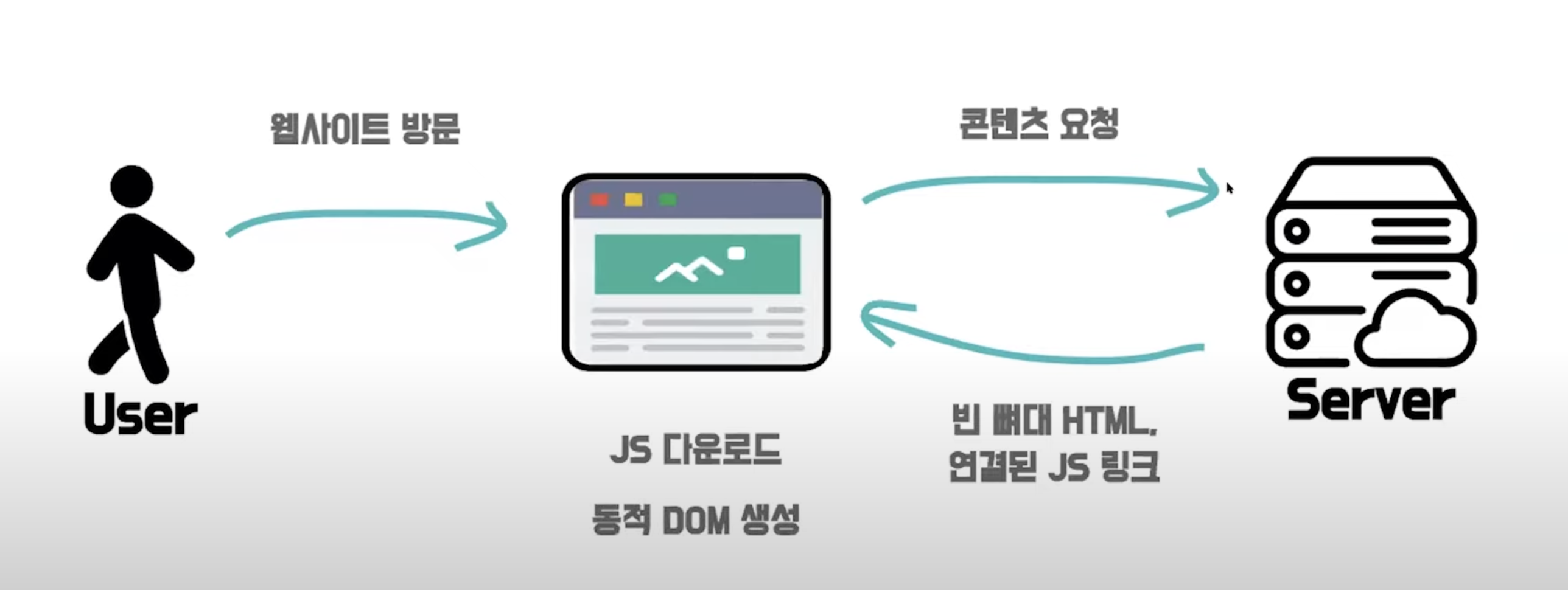
CSR은 클라이언트 즉 브라우저에서 웹 페이지의 렌더링을 하는 것을 말한다.
서버에서 데이터를 보내줄 때 모든 데이터가 HTML이 아닌 JS 파일에 들어가 있다.
CSR동작 과정
- 유저가 웹사이트 방문 시 브라우저가 서버에게 요청을 보냄
- 서버에서는 비어있는 HTML에 연결된 JS 파일을 브라우저로 응답을 보냄
- 브라우저에서 JS 파일을 다운받고 동적으로 DOM을 생성해서 웹 페이지를 렌더링함
장점
초기 로딩 이후 구동 속도가 빠르다.
(초기 로딩시에 서버에서 모든 파일을 가져오기때문에 데이터 크기에 따라 시간이 걸리지만, 초기 로딩 이후에 페이지 일부를 변경할 때는 서버에서 해당 데이터만 요청하면 되기 대문에 이후 구동속도는 빠르다.)TTI(Time to Interact) 와 TTV(Time to View) 사이의 시간 간격이 없다.
(브라우저에서 js 파일을 다운로드 후 화면을 렌더링하기 때문)서버의 부하가 적다. (서버에서 렌더링을 하지 않기 때문에 사용자가 증가해도 부하가 SSR에 비해 상대적으로 적다.)
화면 깜빡임이 없다. (초기 로딩 이후 필요한 부분만 데이터를 서버에서 가져오기 때문에 깜빡임 현상이 없다.)
단점
초기 구동 속도가 느리다.
(브라우저에 렌더링할 모든 데이터가 JS파일에 들어가 있기 때문에 JS 파일이 커지면 커질수록 초기 구동 속도가 느리다.)검색최적화엔진인
SEO에 불리하다.
(SEO는 HTML을 기반으로 검색 키워드를 수집하는데CSR의 경우에는 모든 데이터가 JS 파일에 들어가 있고 HTML 은 빈 뼈대만 있기 때문에 검색 키워드를 노출 시킬 수 없다는 단점이 있다.)
CSR 과 SSR 장단점 한 눈에 정리
SSR ,CSR 어떤 경우에 사용하나?
1. CSR
- 유저와 상호작용이 많다.
- 개인정보를 다루는 페이지에는 검색엔진에 노출될 필요가 없다 모든 서비스에
SEO가 필요하지는 않다.
2. SSR
- 회사의 홈페이지를 노출시킬 필요가 있다
- 누구에게나 동일한 내용을 보여줘야한다
- 업데이트가 자주 일어나 해당 페이지의 데이터가 자주 바뀐다
3. Universal Rendering ( CRS+ SSR)
CSR 과 SSR의 단점을 보안한 방식으로
- 초기 로딩 속도를 보안
- SEO 개선
- CSR 의 장점들을 합친 방법이다.
- 사용자에 따라 페이지의 내용이 변하거나
- 빠른 interaction과 화면 깜빡임이 없어야 한다거나
- SEO를 포기할 수 없어 상위노출을 원하는 경우
SSR & CSR 은 어느 방식이든지 단점은 존재하기에 상황에 맞게 원하는 렌더링 방식을 선택해서 사용하는게 좋을 듯 하다.
사진 출처 : [10분 테코톡] 신세한탄의 CSR&SSR , 코드스테이츠
