개요
링킹 과정에서는 목적 코드들에 정의된 심볼들( 함수들이나 객체들 ) 의 위치를 확정 시킵니다.
이때, C++에서 심볼들의 위치를 정할 때,
어떠한 방식으로 정할지 알려주는 키워드들이 있는데,
이들을 바로 Storage Class Specifier 라고 합니다.
굳이 번역하자면 저장 방식 지정자 정도 입니다.
저장 방식 지정자
C++에서 허용하는 저장 방식 지정자는 아래와 같이 총 4가지 입니다.
* `static`
* `thread_local`
* `extern`
* `mutable` <- 이 녀석의 경우 저장 기간과 링크 방식에 영향을 주지는 않습니다.이전에는 auto와 register 지정자들도 있었지만,
각각 C++11 과 C++17에서 사라졌습니다.
이 키워드들을 통해 심볼들의 두 가지 중요한 정보들을 지정할 수 있습니다.
바로 저장 기간( Storage Duration )과 링크 방식( Linkage ) 입니다.
저장 기간( Storage Duration )
프로그램에서의 모든 객체들의 경우 반드시
아래 넷 중에 한 가지 방식의 저장 기간을 가지게 됩니다.
자동( Automatic ) 저장 기간
여기에 해당하는 객체들의 경우 보통 {} 안에 정의된 녀석들로,
코드 블록을 빠져나가게 되면 자동으로 소멸합니다.
static, extern, thread_local 로 지정된 객체들 이외의 모든 지역 객체들이
바로 이 자동 저장 기간을 가지게 됩니다.
쉽게 말해, 우리가 흔히 생각하는 지역 변수들이 해당됩니다.
int func()
{
int a;
SomeObject x;
{
std::string s;
}
static int not_automatic;
}위 경우, a, x, s 모두 자동 저장 기간을 가지지만 not_automatic 은 아닙니다.
static 저장 기간
static 저장 기간에 해당하는 객체들의 경우 프로그램이 시작할 때 할당되고,
프로그램이 끝날 때 소멸 됩니다.
그리고 static 객체들은 프로그램에서 유일하게 존재합니다.
예를 들어, 지역 변수의 경우, 여러 쓰레드에서 같은 함수를 실행한다면
같은 지역 변수의 복사본들이 여러 군데 존재하겠지만,
static 객체들은 이 경우에도 유일하게 존재합니다.
보통 함수 밖에 정의된 것들이나( 즉 namespace 단위에서 정의된 것들 ) static,
혹은 extern으로 정의된 객체들이 static 저장 기간을 가집니다.
참고로 static 키워드와 static 저장 기간을 가진다는 것을 구분해야 합니다.
static 키워드가 붙은 객체들이 static 저장 기간을 가지는 것은 맞지만,
다른 방식으로 정의된 것들도 static 저장 기간을 가질 수 있습니다.
예를 들어,
int a; // 전역 변수 static 저장 기간
namespace ss
{
int b; // static 저장 기간
}
extern int a; // static 저장 기간
int func()
{
static int x; // static 저장 기간
}위와 같이 여러가지 방식으로 정의된 객체들이 static 저장 기간을 가지게 됩니다.
쓰레드( Thread ) 저장 기간
쓰레드 저장 기간에 해당하는 객체들의 경우
쓰레드가 시작할 때할당 되고, 쓰레드가 종료될 때 소멸됩니다.
각 쓰레드들이 해당 객체들의 복사본을 갖게 되며, thread_local 로 선언된 객체들이
이 쓰레드 저장 기간을 가질 수 있습니다.
#include <iostream>
#include <thread>
thread_local int i = 0;
void g() { std::cout << i; }
void threadFunc(int init) {
i = init;
g();
}
int main() {
std::thread t1(threadFunc, 1);
std::thread t2(threadFunc, 2);
std::thread t3(threadFunc, 3);
t1.join();
t2.join();
t3.join();
std::cout << i;
}예를 들어 아마 몇 번 실행하다보면 1230, 2130, 3120 등과 같은 결과를 볼 수 있습니다.
그 이유는 thread_local로 정의된 i 가 각 쓰레드에 유일하게 존재하기 때문이죠.
마치 전역 변수인 것 처럼 정의되어 있지만,
실제로는 각 쓰레드에 하나씩 복사본이 존재하게 되고,
각 쓰레드 안에서 해당 i를 전역변수인것마냥 참조할 수 있게 됩니다.
동적( Dynamic ) 저장 기간
동적 저장 기간의 경우 동적 할당 함수를 통해서 할당 되고 해제되는 객체들을 의미 합니다.
대표적으로 new와 delete로 정의되는 객체들을 의미합니다.
이러한 저장 방식은 나중에 링커에서 해당 변수나 함수들을 배치시에
어디에 배치할 지 중요한 정보로 사용됩니다.
링크 방식( Linkage )
앞선 저장 방식이 객체들에게만 해당되는 내용이였다면,
링크 방식의 경우 C++ 모든 객체, 함수, 클래스, 템플릿, 이름 공간 등을
지칭하는 이름들에 적용되는 내용입니다.
C++에선 아래와 같은 링크 방식들을 제공합니다.
이 링크 방식에 따라 이름이 어디에서 사용되는지 지정할 수 있습니다.
링크 방식 없음( No Linkage )
블록 스코프 {} 안에 정의되어 있는 이름들이 이 경우에 해당합니다. (extern 이 아닌 이상)
링크 방식이 지정되지 않는 개체들의 경우에는 같은 스코프 안에서만 참조할 수 있습니다.
예를 들어,
{ int a = 3; }
a; // 오류위 경우, a라는 변수는 {}안에 링크 방식이 없는 상태로 정의되어 있기 때문에,
스코프 밖에서 a를 참조할 수 없게 됩니다.
내부 링크 방식( Internal Linkage )
static으로 정의된 함수, 변수, 템플릿 함수, 템플릿 변수들이 내부 링크 방식에 해당됩니다.
내부 링크 방식으로 정의된 것들의 경우 같은 TU 안에서만 참조할 수 있습니다.
그 외에도 익명의 이름 공간에 정의된 함수나 변수들 모두 내부 링크 방식이 적용됩니다.
예를 들어,
namespace
{
int a; // 내부 링크 방식
}
static int a; // 이와 동일한 의미외부 링크 방식( External Linkage )
외부 링크 방식으로 정의된 객체들은 다른 TU에서도 참조 가능합니다.
참고로 외부 링크 방식으로 정의된 개체들에 언어 링크 방식을 정의할 수 있어서,
다른 언어( C와 C++ ) 사이에서 함수를 공유하는 것이 가능해 집니다.
앞서 링크 방식이 없는 경우나 내부 링크 방식을 개체들을 정의하는 경우를 제외하면
나머지 모두 외부 링크 방식으로 정의됨을 알 수 있습니다.
참고로, 블록 스코프 안에 정의된 변수를 외부 링크 방식으로 선언하고 싶다면
extern 키워드를 사용하면 됩니다.
extern "C" int func(); // C 및 C++에서 사용할 수 있는 함수
// C++에서만 사용할 수 있는 함수. 기본적으로 C++의 모든 함수들에 extern "C++"
// 이 숨어 있다고 생각하면 됩니다. 따라서 아래처럼 굳이 명시해줄 필요가 없습니다.
extern "C++" int func2();
int func2(); // 위와 동일이름 맹글링( Name Mangling )
앞서 C에서 C++의 함수를 사용하기 위해서는
extern "C"로 언어 링크 방식을 명시해주어야 한다 했습니다.
그 이유는, 목적 파일 생성 시, C 컴파일러가 함수 이름을 변환하는 방식과
C++ 컴파일러가 함수 이름을 변환하는 방식이 다르기 때문입니다.
일단 C의 경우 함수 이름 변환 자체가 이루어 지지 않습니다.
만약에 아래와 같이 func이란 함수를 정의했다고 해봅시다.
int func(const char* s) {}이를 C 컴파일러가 컴파일 하면 변환된 이름은 그냥
$ nm a.out
0000000000000000 T funcfunc 임을 알 수 있습니다.
참고로 nm은 목적 파일에 정의되어 있는 심볼들을 모두 출력해주는 프로그램입니다.
반면에 똑같은 소스코드를 C++ 컴파일러로 컴파일 해봅시다.
$ nm a.out
0000000000000000 T _Z4funcPKcC++에서는 위와 같이 목적 코드 생성시에,
컴파일러가 함수의 이름을 바꾸는 것을 볼 수 있습니다.
이를 이름 맹글링( Name Mangling ) 이라합니다.
이렇게 이름 맹글링을 하는 이유는
C++에서는 함수 오버로딩을 통해 같은 이름의 함수를 정의할 수 있기 때문입니다.
이름 맹글링을 하게 되면 원래의 함수 이름에
이름 공간 정보와 함수의 인자 타입 정보들이 추가됩니다.
따라서 같은 이름의 함수일 지라도, 이름 맹글링을 거치고 나면,
다른 이름의 함수로 바뀌기 때문에 링킹을 성공적으로 수행할 수 있습니다.
int func(const char* s) {}
int func(int i) {}
int func(char c) {}
namespace n {
int func(const char* s) {}
int func(int i) {}
int func(char c) {}위와 같은 이름이 같은 모든 함수는, 이름 맹글링이 되면,
$ nm test.o
000000000000001d T _Z4funcc
000000000000000f T _Z4funci
0000000000000000 T _Z4funcPKc
000000000000004a T _ZN1n4funcEc
000000000000003c T _ZN1n4funcEi
000000000000002d T _ZN1n4funcEPKc다음과 같이 변하게 됩니다.
참고로 컴파일러마다 이름 맹글링을 하는 방식이 조금씩 다르기 때문에,
A라는 컴파일러에서 생성한 목적 코드를 B 컴파일러가 링킹할 때 문제가 될 수 있습니다.
아무튼 C에서 C++의 함수를 호출하기 위해서는 반드시 이름 맹글링이 되지 않는
함수 심볼을 생성해야 합니다. 따라서, extern "C"를 통해서
이 함수는 이름 맹글링을 하지 마!!
라고 컴파일러에게 전달할 수 있습니다.
당연히도 extern "C"가 붙은 함수들끼리는 오버로딩을 할 수 없습니다.
왜냐하면 심볼 생성 시, 두 함수를 구분할 수 있는 방법이 없기 때문이죠.
링킹
위 단계에서 아무런 문제가 없었다면, 이제 비로소 진짜 링킹( Linking )을 수행할 수 있습니다.
링킹이란,
각각의 TU들에서 목적 코드들을 한데 모아서 **하나의 실행 파일**을 만들어내는 작업입니다.
물론 단순히 목적 코드들을 이어 붙이는 작업만 하는 것은 아닙니다.
링킹 과정이 끝나기 전까진 변수들과 함수, 그리고 데이터들의 위치를 확정시킬 수 없습니다.
따라서 TU들이 생성한 목적 코드들엔, 심볼들의 저장 방식과 링크방식에 따라,
여기 어디에 배치했으면 좋겠다 라는 희망 사항만 써져있을 뿐입니다.
예를 들어,
static int a = 3;
int b = 3;
const int c = 3;
static int d;
int func() {}
static int func2() {}위 코드는
$ nm test.o
0000000000000004 D b
0000000000000000 T _Z4funcv
0000000000000000 d _ZL1a
0000000000000000 r _ZL1c
0000000000000000 b _ZL1d
000000000000000b t _ZL5func2vnm 프로그램을 통해 어떠한 방식으로 링크 시, 심볼을 배치할지
에 대한 정보를 볼 수 있습니다.
먼저 가운데 알파벳을 봅시다.
대문자 알파벳의 경우, 해당 심볼은 외부 링크 방식으로 선언된 심볼이란 의미입니다.
즉, 해당 심볼은 다른 TU에서 접근할 수 있는 심볼입니다.
소문자 알파벳의 경우, 해당 심볼은 내부 링크 방식으로 선언된 심볼이란 의미입니다.
따라서 해당 심볼은 이 TU 안에서만 접근이 가능합니다.
그 다음 알파벳 자체는 어떠한 방식으로 해당 심볼을 배치할지 알려줍니다.
nm의 man 페이지에서 전체 알파벳들에 대한 설명을 볼 수 있지만 일부만 소개한다면,
* `B, b` : 초기화 되지 않은 데이터 섹션( BSS 섹션 )
* `D, d' : 초기화 된 데이터 섹션
* `T, t' : 텍스트( 코드 ) 섹션
* `R, r` : 읽기 전용( Read Only ) 섹션입니다.
재배치( Relocation )
컴파일된 소스 코드들을 목적 파일( Object File )로 변환한 후,
여러 목적 파일들을 하나의 실행 파일로 결합하는 과정에서
주소들을 조정하는 작업을 말합니다.
이는, 컴파일 시점에서는 정확한 메모리 주소를 알 수 없기 때문에,
프로그램이 메모리에 로드된 이후에야 실행 주소를 정확히 매핑할 수 있기 때문입니다.
링킹 단계에서 재배치 정보는 목적 파일( Object File )에 저장되어 있으며,
실행 파일로 링킹될 때 해당 정보가 사용됩니다.
재배치는 주로 하드웨어 아키텍처와 운영체제에 따라 다르며,
컴파일러와 링커가 이러한 재배치를 자동으로 처리합니다.
이렇게 함으로써 프로그래머는
프로그램의 절대 주소를 다룰 필요 없이 상대 주소를 사용하여 프로그래밍을 할 수 있습니다.
링크 방식( 정적 링킹 vs 동적 링킹 )
컴파일러가 여러 목적 파일들을 링크하는 방식은
정적 링킹( Static Linking )과 동적 링킹( Dynamic Linking ) 으로 구분됩니다.
정적 링킹은 정적 라이브러리( Static Library )를 링크하는 방식이고
동적 링킹은 동적 라이브러리( Dynamic Library ), 다른 말로
공유 라이브러리( Shared Library )를 링크하는 방식입니다.
정적 라이브러리
정적 라이브러리를 설명하기 전에, 먼저 라이브러리의 개념을 먼저 생각해봅시다.
라이브러리란
단순히 프로그램이 동작하기 위해 필요한 외부 목적 코드들이라고 생각하시면 됩니다.
정적 라이브러리는 우리가 필요로 하는 라이브러리가 링킹 후에
완성된 프로그램 안에 포함된다고 생각하면 됩니다.
정적 라이브러리 만들기
예를 들어 foo 라는 함수를 제공하는 foo.cc 파일과
bar라는 함수를 제공하는 bar.cc 파일이 있다고 해봅시다.
// bar.h
void bar();
// bar.cc
void bar() {}
// foo.h
int foo();
// foo.cc
#include "bar.h"
int x = 1;
int foo()
{
bar();
x++;
return 1;
}이 파일들을 컴파일 하면 foo.o 와 bar.o라는 목적 코드가 생성이 됩니다.
만일 이 두 함수를 제공하는 정적 라이브러리를 만들기 위해서는,
이 두 목적 파일들을 묶어주면 됩니다.
$ ar crf libfoobar.a foo.o bar.o라고 치면 libfoobar.a 라는 정적 라이브러리가 만들어 집니다.
이 정적 라이브러리를 사용하는 방법은 간단합니다.
예를 들어,
main.cc라는 파일에서 foo함수를 사용하고 싶다면,
foo함수가 선언된 헤더파일 하나만 필요합니다.
#include "foo.h"
int main()
{
foo();
}통상적인 상황이라면 main을 컴파일 하면서 실행파일을 생성할 때,
foo.cc 코드와 bar.cc 코드를 같이 컴파일해서 링킹했어야 하지만,
우리는 이미 foo.cc와 bar.cc가 이미 컴파일 되어 있는
libfoobar.a라는 라이브러리가 있기 때문에, 굳이 다시 컴파일 할 필요가 없습니다.
따라서 아래와 같이 실행 파일을 생성 시에
# g++ main.cc libfoobar.a -0 main위 처럼 링크해주기만 하면 됩니다.
이렇게 정적 라이브러리는 링크 타임에 바인딩 된다고 생각하시면 됩니다.
공유 라이브러리( 동적 라이브러리 )
정적 라이브러리의 가장 큰 문제점은
모든 프로그램들이 같은 라이브러리를 링킹하더라도, 정적으로 링킹할 경우,
프로그램 내에 동일한 라이브러리 코드를 포함해야 한다 였습니다.
그렇다면 이렇게 많은 프로그램 상에서 사용되는 라이브러리를
컴퓨터 메모리 상에 딱 하나 올려놓고,
이를 사용하는 프로그램들이 해당 라이브러리를 공유하면 어떨까요?
이것이 공유 라이브러리의 시작입니다.
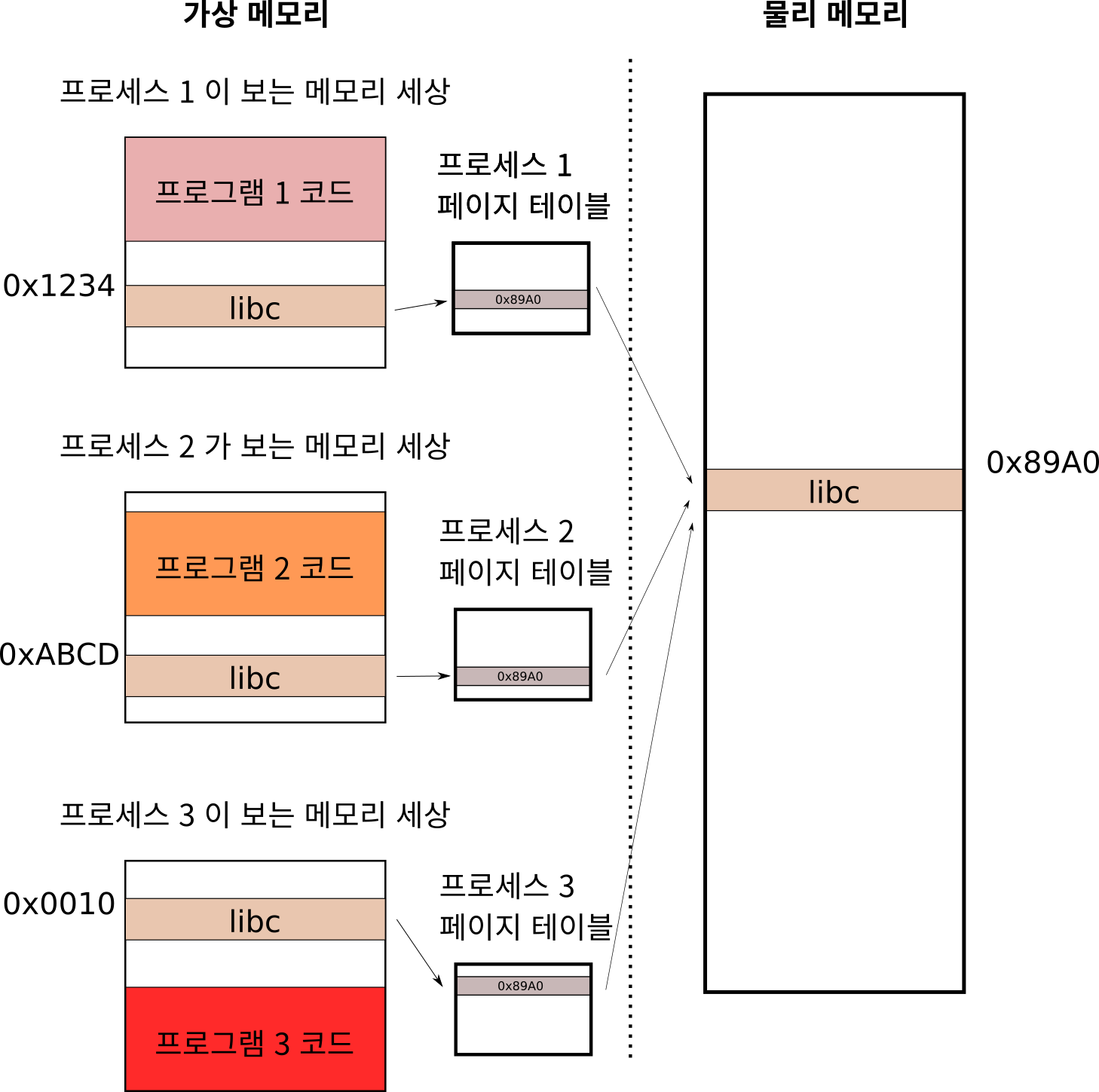
하지만 각 프로세스들의 메모리는 다른 프로세스들과 독립적이고
서로 접근할 수 없는 것으로 알고 있을 것입니다.
그런데 어떻게 서로 다른 프로그램이 같은 메모리를 공유할 수 있는 것일까요?
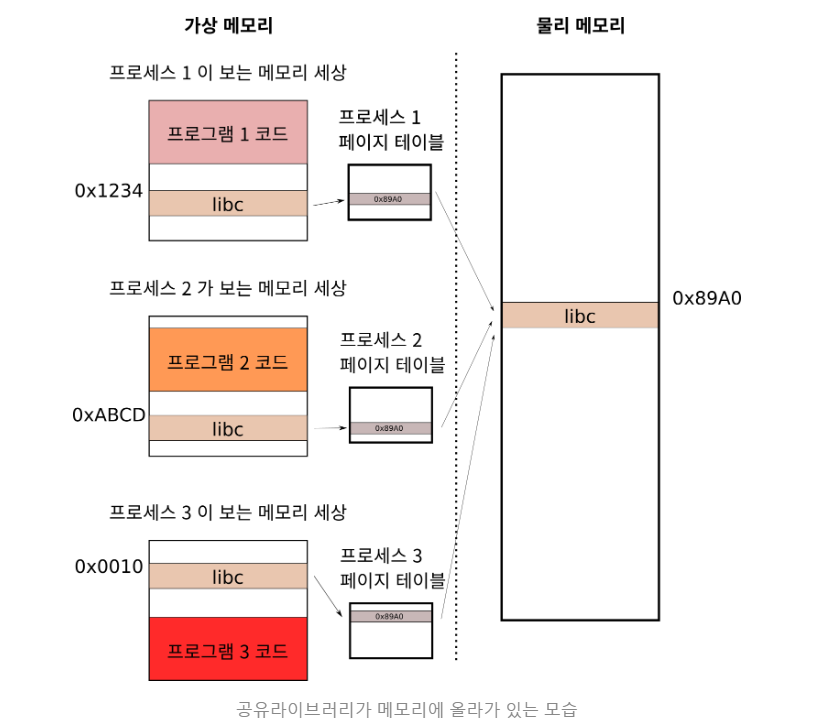
위 처럼 각각의 프로세스에는 고유의 페이지 테이블이 있습니다.
실제 프로세스가 보는 가상 메모리에서는 가상 메모리 단의 오른쪽과 같습니다.
문제는 프로세스마다 코드의 크기가 다르기 때문에, 공유 라이브러리가
각 프로세스의 가상 메모리에 놓이는 위치가 다르게 된다는 점입니다.
하지만 이는, 프로세스마다 가상메모리를 물리메모리로 변환하는
페이지 테이블이 있기 때문에,
실제 물리 메모리에 libc 코드를 딱 한 군데만 올려 놓고,
각 프로세스의 페이지 테이블 내용을 바꿔줌으로써
마치 프로세스마다 고유의 위치에 libc 코드가 있는 것처럼 사용할 수 있습니다.
동적 라이브러리 만들기
정적 라이브러리와는 다르게 동적 라이브러리는 임의의 위치에 라이브러리가 위치할 수 있어,
섹션의 위치를 특정할 수 없습니다.
따라서 결국에는 foo.cc와 bar.cc를 다시 컴파일해야 합니다.
이 때, 컴파일 시에 인자로 **위치와 무관한 코드( Position Independent Code - PIC )를 만들라는 의미의 -fpic 인자를 전달해야 합니다.
$ g++ -c -fpic foo.cc
$ g++ -c -fpic bar.cc
$ g++ -shared foo.o bar.o -o libfoobar.so를 하면, 공유 라이브러리인 libfoobar.so 가 잘 생성된 것을 볼 수 있습니다.
so -> Shared Object
이를 링크하는 방법은
$ g++ main.cc libfoobar.so -g -o main으로 하면 됩니다.
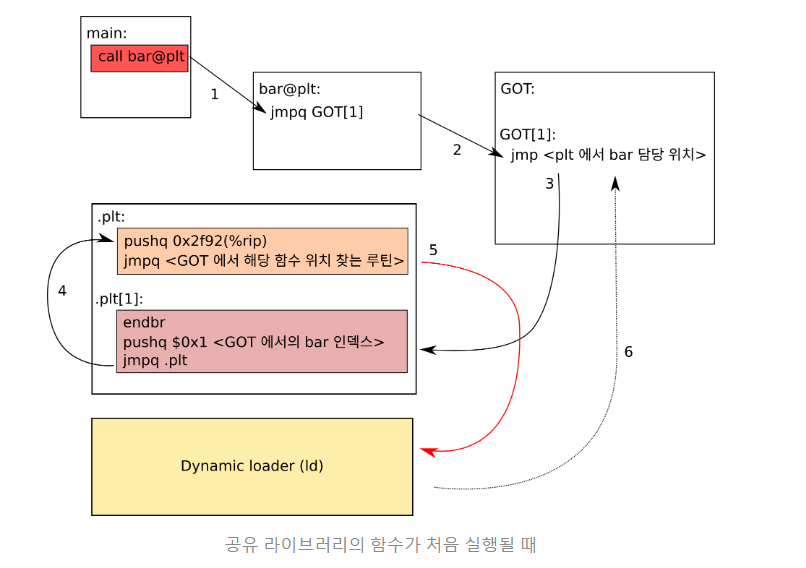
위 사진을 보고 main함수에서 공유 라이브러리 내의 bar를 호출한다 합시다.
만일 bar가 정적으로 링크된 라이브러리 함수라면,
그냥 bar가 정의된 위치를 호출했을 겁니다.
하지만 공유 라이브러리의 경우, 프로그램 어디에 위치 되었는지 알 수 없기 때문에
해당 함수를 직접 호출하는 것은 불가능 합니다.
따라서 GOT( Global Offset Table ) 라는 이름의 데이터 테이블을 프로그램 내부에 만든 후,
실제 함수들의 주소값을 이 테이블에 적어 놓습니다.
그리고 우리가 함수를 호출하게 되면
해당 함수의 실제 위치를 이 테이블을 통해서 알아내게 됩니다.
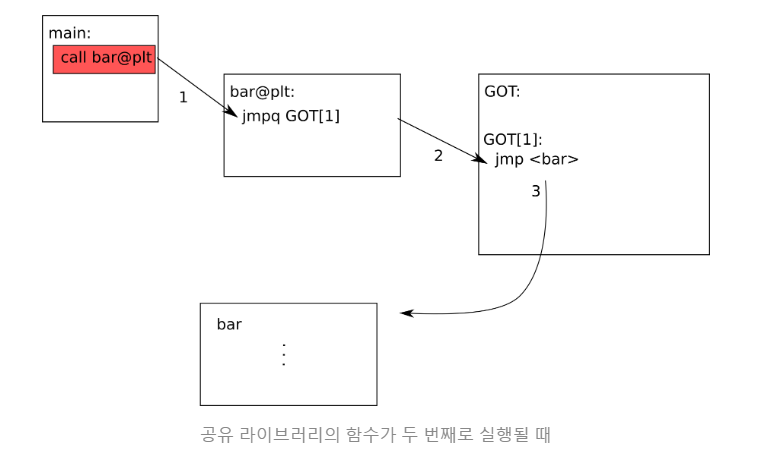
하지만 공유 라이브러리의 함수가 두 번째로 실행될 때에는
GOT[1] 안에 bar의 주소값이 들어 있기 때문에 그냥 바로 bar를 호출할 수 있게 됩니다.
이와 같이 함수가 실행될 때, GOT 엔트리에 등록되는 방식을 lazy binding이라고 합니다.
lazy binding의 장점은, bar이 한 번도 호출되지 않았다면 시간을 절약할 수 있습니다.
하지만 lazy binding의 문제점은,
해당 함수를 첫 번째로 실행하는 시점에서 많은 시간이 소요된다는 점입니다.
따라서, 차라리 프로그램 시작 시에
모든 동적으로 바인딩 되는 심볼들을 찾아버리는 것이 오히려 나을 수도 있습니다.
예를 들어 포토샵의 경우,
프로그램 시작 시 실행 시간이 매우 긴데, 이게 대부분 공유 라이브러리에서
사용되는 함수들을 찾느라 걸리는 시간입니다.
참조 : 모두의 코드 - 씹어먹는 C++
