일반적으로 우리 모델을 원하는 방향으로 활용하기 위해서는 Pre-trained된 모델을 Fine-Tuning 하는 방식을 많이 사용해왔습니다. 그러나 LLM과 같이 Large 한 모델들이 등장하면서 이 모델의 모든 파라미터를 재학습하고, 배포하는 데 막대한 자원이 필요해지기 시작했습니다. 따라서 2021년을 기점으로 이 LLM을 효율적으로 Fine-Tuning과 비슷하게 학습할 수 있는 방법은 없는지에 대한 연구가 나오기 시작했습니다.
PEFT
이 때 제안된 방법들은 Parameter-Efficient Fine-Tuning(PEFT)라고 불립니다.
모델의 모든 parameter를 학습하지 않고 일부 파라미터만 Fine-Tuning 하는 방법으로 2019년부터 다양한 방법론들이 제안되고 있습니다.
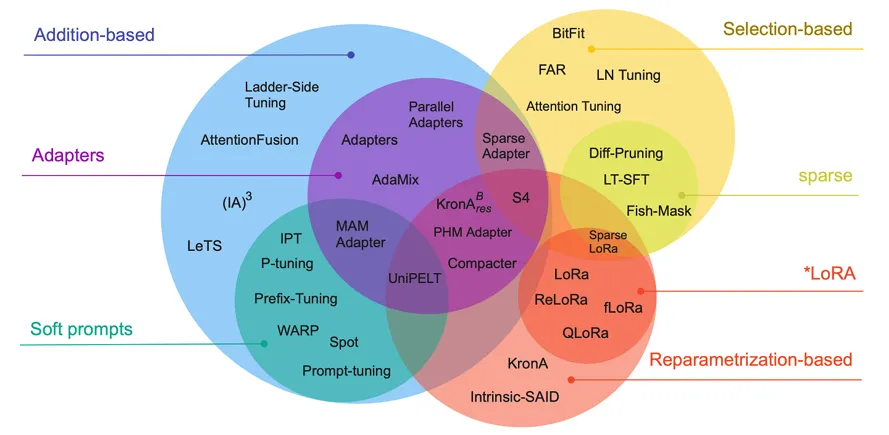 Scaling Down to Scale Up: A Guide to Pararmeter-Efficient Fine Tuning, Lialin et al., 2023
Scaling Down to Scale Up: A Guide to Pararmeter-Efficient Fine Tuning, Lialin et al., 2023
가장 대표적인 방식은 아래 4가지가 있습니다.
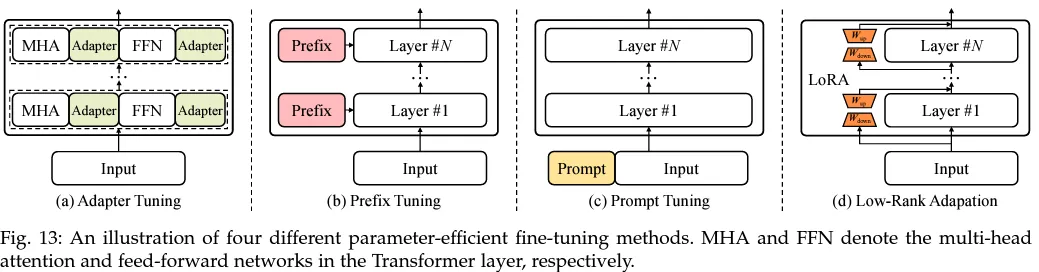 A Survey of Large Language Models, Zhao et al., 2023
A Survey of Large Language Models, Zhao et al., 2023
- Adapter 2. Prefix Tuning 3. Prompt Tuning 4. Low-Rank Adaptation
각각 하나씩 알아 보겠습니다.
1. Adapter
 Language Models are Few-Shot Learners, Brown et al., 2020
Language Models are Few-Shot Learners, Brown et al., 2020
기존의 Transformer layer에 Adapter라는 layer를 추가해 Transformer의 가중치는 학습하지 않고, Adapter만 학습하는 방법입니다. Adapter layer는 2개의 Feed forward layer로 이뤄져 있으며 첫번째 layer을 통해 정보를 압축했다가 두번째 layer에서 원래의 차원으로 정보를 다시 복구해 정보를 이어줍니다.
2. Prefix Tuning
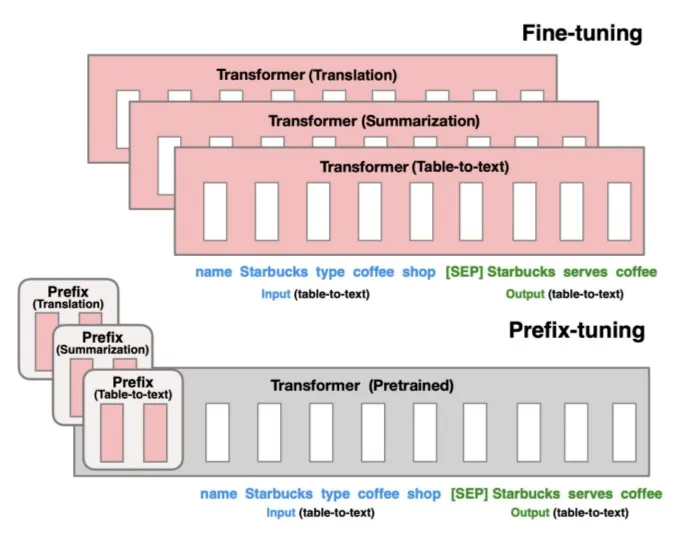 "Prefix-tuning: Optimizing continuous prompts for generation, Li et al., 2021"
"Prefix-tuning: Optimizing continuous prompts for generation, Li et al., 2021"
Transformer의 각 layer의 앞 부분에 prefix라는 훈련 가능한 vector를 추가하는 방법으로 Transformer 전체를 Fine-Tuning 하는 것에 비해 2개의 벡터만 학습하면 되기 때문에 학습 파라미터 수를 크게 줄일 수 있었습니다.
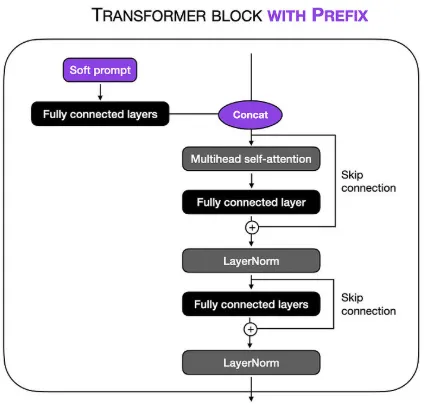
출처: https://magazine.sebastianraschka.com/p/understanding-parameter-efficient
위의 그림과 같이 prefix(FC layer)는 soft prompt를 통해 task별로 각각 학습하게 됩니다. 이렇게 학습된 Prefix는 Inference 과정에서 task에 따라 활용되며, 해당 task의 정보를 Transformer에게 전달해 Transformer가 task에 대한 이해를 돕고, 모델의 성능 향상시키는데 도움을 줍니다.
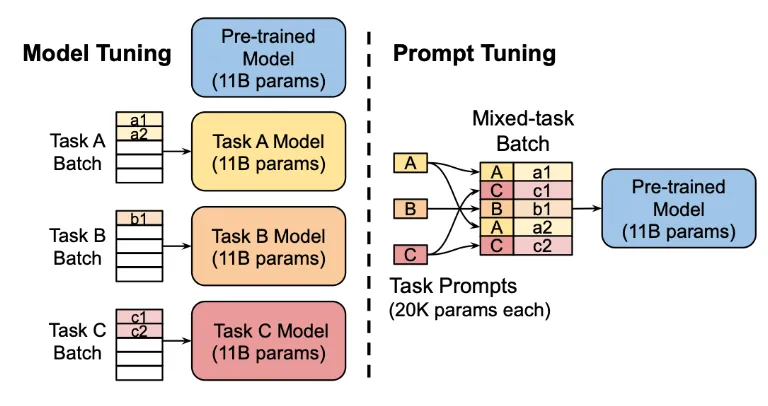
3. Prompt Tuning
 "The Power of Scale for Parameter-Efficient Prompt Tuning, Lester etal, 2021"
"The Power of Scale for Parameter-Efficient Prompt Tuning, Lester etal, 2021"
Prefix Tuning은 Transformer에 vector를 추가했다면 Prompt Tuning은 input sequence에 학습 가능한 task prompt vector를 추가해 embedding vector를 학습시키는 방법입니다.
기존의 Pre-trained 모델의 가중치는 고정하고, 프롬포트의 임베딩을 업데이트 하는 과정이기 때문에 모델 학습 과정을 크게 줄일 수 있었습니다.
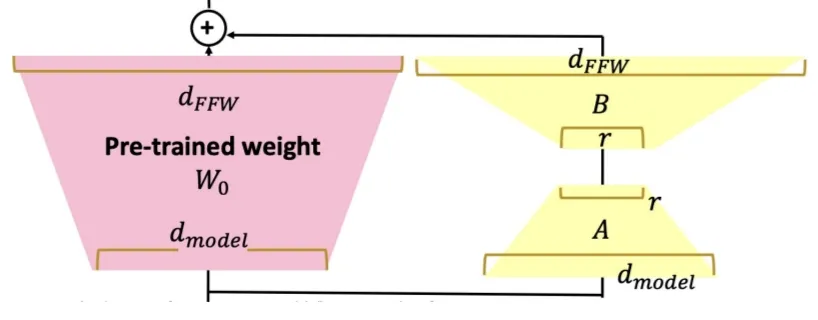
4. Low-Rank Adaptation
 LoRA: Low-Rank Adaptation of Large Language Models Hu et al., 2021
LoRA: Low-Rank Adaptation of Large Language Models Hu et al., 2021
LoRA라고도 불리는 이 방식은 PEFT methods 중 가장 널리 쓰이는 방법론 입니다. 위의 그림과 같이 기존의 pre-trained 모델의 layer 마다 가중치는 고정하고, 학습 가능한 rank decomposition 행렬을 삽입합니다.
이 행렬은 입력 차원을 ‘rank’ 만큼 줄이는 행렬과 이를 다시 출력 차원으로 바꿔주는 행렬로 구성되어 있으며, 이렇게 계산된 lora parameter를 pre-trained 모델의 layer output에 더해줌으로써 tuning이 이뤄집니다.
보통 이런 방식의 Adapter를 활용하게 되면 Inference latency가 매우 증가해 활용하기 어렵다는 단점이 있는데, LoRA는 Adapter의 output을 기존 모델에 합쳐 줌으로서 추가연산이 필요하지 않기 때문에 Inference speed와 모델 아키텍쳐를 유지하며 활용 가능 하다는 장점이 있습니다.
Refernces
https://codingsmu.tistory.com/162
https://stydy-sturdy.tistory.com/45
