안녕하세요 오늘은 Pytorch 코드를 보다보면 종종 볼 수 있는 Initialization에 대해서 정리해보겠습니다.
Initialization이란 신경망 학습에서 가중치의 초깃값을 어떻게 정해야 하는지에 대한 방법론입니다. 초깃값을 어떻게 설정하느냐에 따라 성공적으로 학습이 이뤄지느냐, 실패하느냐가 결정되기도 하니 별 것 아니어 보이지만 꽤 중요한 설정값이겠습니다.
Initialization(초기화)의 중요성
Initialization의 중요성을 알기위해 간단한 실험을 하나 진행해보겠습니다. 5개의 hidden-layer를 가지고 있는 신경망 모델에 가중치의 초깃값을 바꿔보면서 각 층의 활성화 값을 보면 Xavier Initialization과 He Initialization이 어떤 상황에서 필요하고, 왜 필요한지 알 수 있습니다.
1. 표준편차가 1인 정규분포

이 그래프는 표준편차가 1인 정규분포 초깃값으로 가중치를 설정한 모델에 Activation(활성화) 함수로 Sigmoid를 사용해 각 layer 활성화 값을 그래프로 나타낸 것입니다. 위에서 볼 수 있듯이 활성화 값이 0과 1에 집중되어 있는 것을 알 수 있습니다. 이렇게 활성화 값이 0과 1이 되면 Sigmoid 특성상 Gradient 값이 0에 가까워서 기울기 손실(Gradient Vanishing) 문제가 발생할 수 있습니다.
2. 표준편차가 0.01인 정규분포
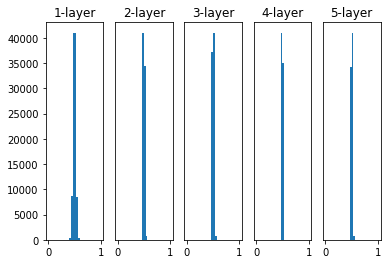
이 그래프는 표준편차가 0.01인 정규분포를 가중치의 초깃값으로 한 활성화 값 그래프입니다. 이 그래프에서는 활성화 값이 0과 1에 집중되어 있어 기울기 손실 문제는 없지만, 층이 깊어질수록 0.5와 가까운 값에 점점 모여드는 것을 알 수 있습니다. 한 층의 뉴런들이 비슷한 값에 모인다는 것은 학습이 원활이 진행되고 있지 않다는 것을 의미합니다.
3. Xavier Initialization(초깃값) 사용
Activation 함수로 Sigmoid가 설정되어 있을 때 유용한 초깃값으로 제안되는 것이 Xavier 초깃값입니다. Xavier라는 사람이 제안한 방법론이라 이름을 따서 명명하게 되었는데, 식은 간단합니다.
-
Xavier Normal Initialization
-
Xavier Uniform Initialization
이렇게 정규분포와 균등분포에 따라 상수항은 일부 다르지만 기본적으로 input dimension과 output dimension의 합을 이용한 표준편차를 갖도록 설정합니다. 이 과정을 통해 각 층의 활성화 값을 광범위하게 분포시키는 초기 가중치 값을 찾을 수 있게 됩니다.
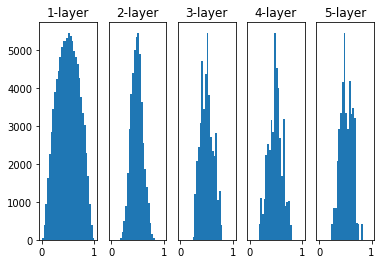
위의 그래프를 보면 각 층에 가중치 값들이 0~1 사이에 골고루 분포하고 있음을 알 수 있습니다. 이렇게 균등하게 가중치값이 분포되어 있어야 학습이 원활하게 진행될 수 있습니다.
4. He Initialization(초깃값) 사용
He 초기화는 Sigmoid보다는 ReLU함수를 활성화 함수로 활용할 때 효과적인 초기화 방법입니다. HE 초기화도 정규분포와 균등분포 두가지 방법으로 활용할 수 있습니다.
-
He Normal Initialization
-
He Uniform Initialization
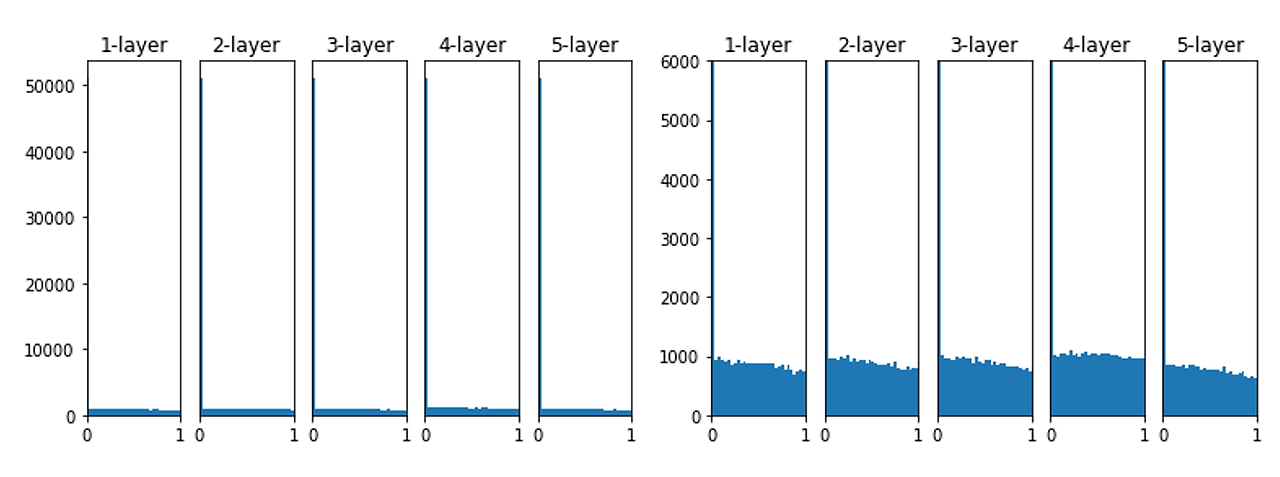
이 그래프는 He 초기화를 이용한 각 층들의 가중치 값입니다. ReLU 함수의 특성상 음수값이 모두 0으로 대치되기 때문에 0 값이 많은 것을 제외하면 다른 값들은 골고루 분포해 있는 것을 알 수 있습니다.
Conclusion
가중치 초기화가 별 것 아닌 것 처럼 보이지만 생각보다 초기 학습에 중요하다는 점을 알 수 있었습니다. 가장 대표적으로 많이 쓰이는 두 Initialization에 대해서 이해하고 상황에 맞게 필요에 따라 활용하는 것이 중요하겠습니다. 최근 대부분의 모델에서는 He 초기화를 주로 선택하고 있다는 점도 참고하시면 좋겠습니다.
