
안녕하세요:) 오늘은 네이버 부스트캠프 최종 프로젝트를 하면서 처음으로 접했던 병렬처리 (멀티프로세스)에 대해서 알아보겠습니다.
프로젝트에서 하이퍼클로바 API와 DALL-E API를 차례대로 불러오는 과정이 있었는데요, 이를 순차적으로 수행하면서 API 통신의 시간이 장시간 소요된다는 문제점을 발견했습니다. 이로 인해 서비스 시간이 대략 2분 이상 소요되어 서비스 사용자 경험이 저하될 수 있다고 생각했습니다.
이를 해결하기 위해 저는 멘토님께 팁을 좀 받아서 병렬처리를 적용하게 되었습니다.
병렬처리
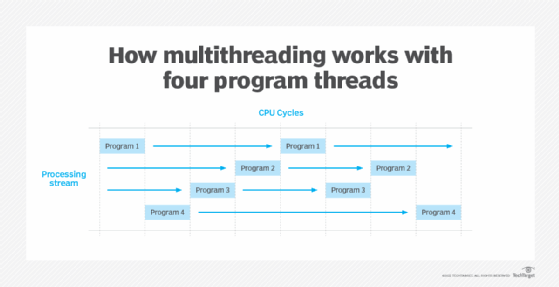
병렬처리는 위에서 보는 사진과 같이 한번에 여러 작업을 동시에 병렬적으로 수행하는 것입니다.
GPU나 CPU의 제한이 없다면 자원을 최대한 활용하면서 동시에 여러작업을 수행할 수 있기 때문에 시간 단축에 효율적인 방법입니다.
파이썬에는 병렬처리를 구현하는 방법으로 멀티 쓰레딩과 멀티 프로세싱 두가지 방법이 있습니다.
멀티 쓰레딩 (Multi-threading)
멀티 쓰레딩은 하나의 프로세스 내에서 여러개의 쓰레드(Thread)가 작업을 동시에 수행하는 방식으로 각 Thread는 동일한 메모리(RAM)을 공유한다 특징이 있습니다.
이 때 Python은 한 번에 하나의 쓰레드만 실행이 가능하기 때문에 CPU연산 작업에서는 효과가 제한적이라는 단점이 있어 웹 크롤링, API 호출 등에 장점이 있습니다.
import threading
import time
def A_1():
print("A_1 작업 시작")
time.sleep(2)
print("A_1 작업 완료")
def A_2():
print("A_2 작업 시작")
time.sleep(3)
print("A_2 작업 완료")
def B():
print("B 작업 시작")
time.sleep(4)
print("B 작업 완료")
def A():
st = time.time()
A_1() # A_1 작업이 끝난 후
a1_time = time.time()
print(a1_time-st) #A_1 작업 2초 소요
# A_2와 B를 동시에 실행
thread_A2 = threading.Thread(target=A_2)
thread_B = threading.Thread(target=B)
a2_time = time.time()
thread_A2.start()
thread_B.start()
thread_A2.join()
thread_B.join()
b_time = time.time()
print("A_2와 B 작업 완료")
print(b_time-a2_time) #A_2, B 병렬 처리로 4초 소요
A()멀티 프로세스 (Multi-Processing)
CPU 연산이 많은 경우에는 threading대신 multiprocessing을 사용할 수 있습니다. 멀티프로세싱은 여러 개의 프로세스를 생성해 병렬적으로 작업하는 방식으로 각 프로세스가 독립적으로 메모리 공간을 갖기 때문에 CPU 연산이 많은 경우에 효과적이라는 장점이 있습니다.
import multiprocessing
import time
def worker(n):
print(f"작업 {n} 시작")
time.sleep(2)
print(f"작업 {n} 완료")
if __name__ == "__main__":
processes = []
for i in range(3):
p = multiprocessing.Process(target=worker, args=(i,))
processes.append(p)
p.start()
for p in processes:
p.join() # 모든 프로세스가 끝날 때까지 기다림concurrent 모듈
본 프로젝트에서는 FAST API를 활용해 비동기식(async) 서비스를 했기 때문에 멀티 쓰레드, 멀티 프로세싱 과정에서 무한 로딩이 발생했습니다.
찾아보니 멀티 쓰레딩과 멀티 프로세싱을 통합적으로 제공하는 concurrent.futures 라는 모듈이 있었고, 이는 비동기식 처리에도 효과적으로 작동하면서 활용성이 가장 높았습니다.
저는 API 호출하는 과정을 병렬적으로 수행하기 때문에 이 모듈을 사용해 멀티 쓰레딩을 구현했습니다.
아래는 예제입니다.
import concurrent.futures
import time
def get_dalle(input_json,captions):
return
def get_blog(model,images, input_json, files):
return
def get_stamp(input_json):
return
def multi_process(model,images,input_json,captions,files):
'''
API를 활용하는 3가지 과정(블로그, 엽서, 스탬프)을 multi process로 실행하는 함수입니다.
multi process를 활용해 전체 프로세스를 30초 단축
'''
with futures.ThreadPoolExecutor() as executor:
dalle = executor.submit(get_dalle, input_json, captions)
blog = executor.submit(get_blog, model, images, input_json, files)
stamp = executor.submit(get_stamp,input_json)
blog_results = blog.result()
dalle_results = dalle.result()
stamp_results = stamp.result()
return blog_results, dalle_results, stamp_results위와 같이 submit 함수를 사용하면 함수와 해당 함수의 인자를 넣어줄 수 있고, result()를 통해 해당 함수의 실행결과를 반환할 수 있습니다.
저는 위와 같이 구현한 덕분에 GPU도 효율적으로 활용하고, API 호출 과정의 전체 시간을 30초 가량 절약할 수 있었습니다.
여러분들도 병렬처리를 적절하게 활용해 프로젝트에 유용하게 활용해보세요!
