
버블 정렬은 인접한 두 요소를 비교하여 의도한 순서가 될 때까지 교체하는 정렬 알고리즘이다. 물 속의 기포가 표면으로 올라오는 것처럼 배열의 각 요소는 각 반복에서 끝으로 이동한다고 해서 버블 정렬이라고 부른다.
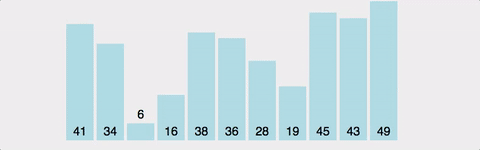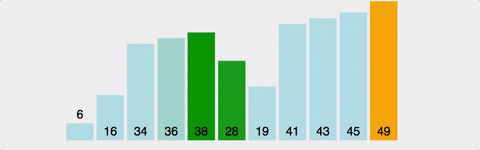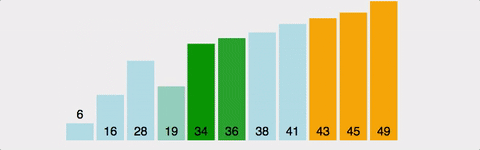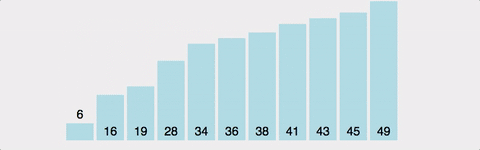
버블 정렬 작업 순서
데이터를 오름차순으로 정렬을 한다고 가정해보자.
1. 첫 번째 반복(비교 및 교환)
1. 첫 번째 인덱스부터 시작해서 첫 번째 요소와 두 번째 요소를 비교한다.
2. 첫 번째 요소가 두 번째 요소보다 크면 서로 교체된다.
3. 이제 두 번째 요소와 세 번째 요소를 비교해 보자. 순서가 맞지 않으면 교환한다.
4. 이 과정이 마지막 요소까지 계속된다.2. 남은 반복
나머지 반복에 대해서도 동일한 프로세스가 진행된다.
각 반복 후에 정렬되지 않은 요소 중 가장 큰 요소가 끝에 배치된다.
시간 복잡도
이게 사이클을 돌때마다 n, n-1, n-2, ... 2, 1번 실행이 되게 되므로, 전체적인 시간 복잡도는 O(n^2)으로 표기된다. 이때문에 양이 많지 않은 데이터는 버블 정렬을 써도 문제가 되지 않겠지만, 데이터 양이 증가함에 따라 시간이 제곱으로 늘어나기 때문에 더 효율적인 알고리즘을 써야 한다.
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
# 두 원소의 위치를 바꿈
arr[j], arr[j+1] = arr[j+1], arr[j]
# 사용 예시
my_list = [64, 34, 25, 12, 22, 11, 90]
bubble_sort(my_list)
print("정렬된 리스트:", my_list)
간단한 코드 예시로는 n, n+1의 값을 비교해서 swap해주는 형식으로 진행될수가 있다. 여기에서 한가지 생각해볼게 있다. 만약에 한 사이클이 돌아갔는데 한번도 swap이 일어나지 않는다면 이미 정렬이 완성이 되있는 상태일 것이다. 이렇게 된다면 다음 사이클을 돌릴필요없이 종료가 되면 되는 것이다.
def bubble_sort(arr):
n = len(arr)
for i in range(n):
# 플래그 초기화
swap_occurred = False
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
# 두 원소의 위치를 바꿈
arr[j], arr[j+1] = arr[j+1], arr[j]
# 교환이 일어났으므로 플래그 설정
swap_occurred = True
# 한 번의 사이클 동안 교환이 없었다면 이미 정렬된 상태이므로 종료
if not swap_occurred:
break
# 사용 예시
my_list = [64, 34, 25, 12, 22, 11, 90]
bubble_sort(my_list)
print("정렬된 리스트:", my_list)
이를 보고 최적화를 시킨 버블정렬이라고 할수가 있다. swap_occurred라는 플래그를 가지고 단한번에 교환이 일어나지 않는다면 break를 통해 함수를 종료시키는 방식으로 물론 이렇게 해서 시간복잡도가 달라지는 것은 아니지만, 조금이나마 더 효율적인 알고리즘으로 바뀔수가 있다.
.jpg)
RECORD DEVELOPER