자료구조는 데이터를 효율적으로 조직화하고 저장하는 방법을 정의하는 학문이다. 이를 통해 데이터를 쉽게 검색, 삽입, 삭제 및 조작할 수 있다. 자료구조는 소프트웨어 개발에서 매우 중요한 개념으로, 프로그램의 성능과 효율성에 직접적인 영향을 미친다.
자료구조를 이해하고 개발을 해야하는 이유
1. 성능 향상
- 적절한 자료구조를 선택하고 사용함으로써 프로그램의 성능을 향상시킬 수 있습니다. 예를 들어, 특정 작업에 적합한 검색이나 정렬 알고리즘을 사용하여 작업을 더 빠르게 처리할 수 있다.
2. 메모리 관리
- 효율적인 메모리 사용을 위해 적절한 자료구조를 선택하고 메모리 할당 및 해제를 관리할 수 있고, 이를 통해 메모리 누수와 같은 문제를 방지할 수 있다
3. 코드 가독성 및 유지보수성
- 적절한 자료구조를 사용하면 코드를 더 쉽게 이해하고 유지보수할 수 있고, 코드의 가독성을 높이고 버그를 줄일 수 있다.
4. 문제 해결 능력 향상
- 다양한 자료구조와 알고리즘을 학습하면 문제 해결 능력이 향상되고, 복잡한 문제를 해결할 때 적절한 자료구조와 알고리즘을 선택하여 효율적으로 해결할 수 있다.
자료구조의 형태
1. 선형 자료구조(Linear Data Structure)
- 선형 자로규조는 데이터 요소들이 선형적으로 연결되어 있는 구조를 가진다. 즉, 각 요소는 다음 요소와 이전 요소와 연결되어 있다. 선형 자로구죠는 단순하고 직관적이며, 순차적으로 데이터에 접근할 수 있다.
2. 비선형 자료구조(Non-linear Data Structure)
- 비선형 자료구조는 데이터 요소들이 계층적인 구조를 가지며 선형적으로 연결되어 있지 않다.
- 각 요소가 여러 개의 다른 요소와 연결되어 있을 수 있습니다.
자료구조의 종류
- 선형 자료 구조 -
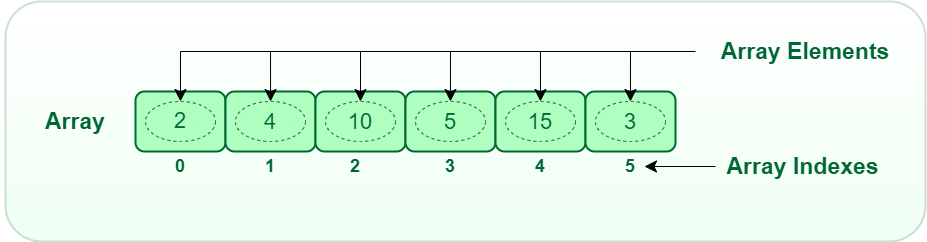
1. 배열(Array)
배열은 메모리에 연속적으로 저장된 데이터 구조이다. 이는 배열의 각 요소가 인접한 메모리 위치에 순차적으로 저장되어 있음을 의미한다.
# Python에서 배열은 리스트(List)로 구현할 수 있습니다.
arr = [1, 2, 3, 4, 5]
print(arr[0]) # 인덱스를 통해 요소에 접근장점
1. 빠른 접근 속도
- 배열은 인덱스를 통해 빠르게 요소에 접근할 수 있다. 이는 배열이 메모리에 연속적으로 저장되어 있기 때문이다.
2. 메모리 효율성
- 배열은 요소들이 연속적으로 저장되므로 다른 자료구조보다 메모리를 효율적으로 사용할 수 있다.
단점
1. 크기 변경이 어려움
- 배열은 크기를 동적으로 변경하기 어려우며, 초기에 설정한 크기를 초과하면 새로운 배열을 생성하고 데이터를 복사해야 한다. 이로 인해 크기 변경이 피룡한 경우 추가적인 비용이 발생할수 있다.
2. 요소 삽입 및 삭제의 어려움
- 배열은 요소를 삽입하거나 삭제할 때 다른 요소들을 이동시켜야 한다. 따라서 삽입 및 삭제 연산이 많은 경우에는 다른 자료구조를 사용하는 것이 더 효율 적이다.
배열은 데이터를 순차적으로 저장하고 빠르게 접근해야 하는 경우에 유용하게 사용된다. 하지만 크기 변경이나 요소의 삽입 및 삭제가 빈번한 경우에는 다른 자료구조를 고려하는 것이 좋다.
2. 연결 리스트(Linked List)
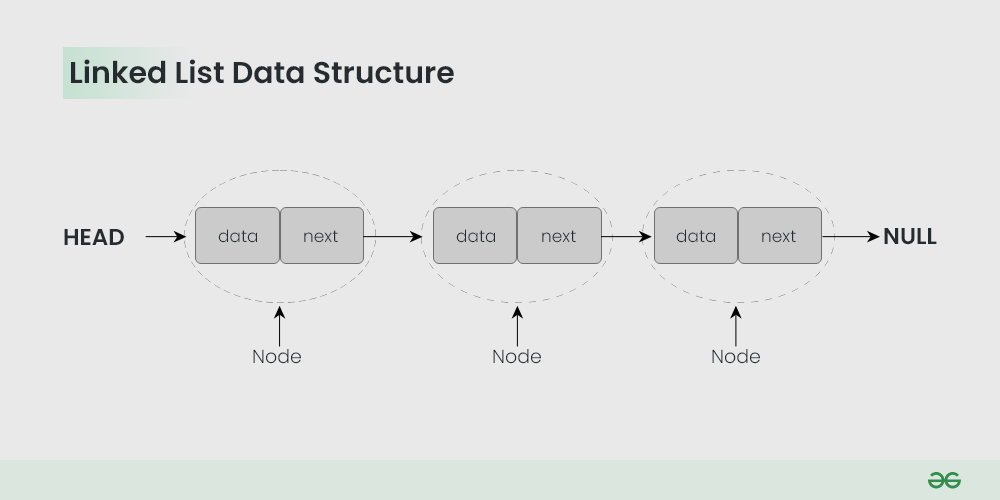
연결 리스트는 메모리에서 각 노드가 데이터와 다음 노드를 가리키는 포인터로 구성된다. 이 구조는 각 노드가 메모리의 임의의 위치에 저장될 수 있으며, 서로 인접하지 않은 위치에 존재할 수 있다.
# 노드를 정의합니다.
class Node:
def __init__(self, data):
self.data = data
self.next = None
# 연결 리스트를 구현합니다.
class LinkedList:
def __init__(self):
self.head = None
# 노드를 추가하는 메서드
def append(self, data):
new_node = Node(data)
if self.head is None:
self.head = new_node
return
last_node = self.head
while last_node.next:
last_node = last_node.next
last_node.next = new_node
# 연결 리스트를 출력하는 메서드
def print_list(self):
current_node = self.head
while current_node:
print(current_node.data, end=" -> ")
current_node = current_node.next
print("None")
# 연결 리스트를 생성하고 테스트합니다.
llist = LinkedList()
llist.append(1)
llist.append(2)
llist.append(3)
llist.print_list() # 출력: 1 -> 2 -> 3 -> None장점
1. 동적 메모리 할당
- 연결 리스트는 동적으로 메모리를 할당하여 노드를 추가할 수 있다. 이는 배열과는 달리 미리 정해진 크기의 메모리를 필요로 하지 않으며, 필요할 때마다 새로운 노드를 할당하여 연결 리스트에 추가할 수 있다.
2. 유연한 크기 조절
- 연결 리스트는 삽입과 삭제가 간단하며, 노드의 개수에 따라 크기를 동적으로 조절할 수 있다. 이는 연결 리스트가 크기가 자주 변하는 상황에서 유용하게 사용될 수 있음을 의미한다.
3. 메모리의 비연속적 사용
- 각 노드가 메모리의 임의의 위치에 저장될 수 있기 때문에, 메모리의 연속적인 공간을 필요로 하지 않는다. 따라서 연결 리스트는 메모리의 효율적인 사용을 가능하게 하다.
단점
1. 포인터 오버헤드
- 각 노드는 다음 노드를 가리키는 포인터를 저장해야 하므로, 포인터 오버헤드가 발생할 수 있다. 이는 메모리 사용량을 늘리는 요인이 될 수 있다.
2. 무작위 접근의 어려움
- 연결 리스트는 각 노드가 메모리의 임의의 위치에 저장되어 있기 때문에, 무작위 접근(Random Access)이 어렵다. 특정 인덱스에 직접적으로 접근하기 위해서는 처음부터 순차적으로 노드를 탐색해야 한다.
3. 추가적인 메모리 공간
- 각 노드는 다음 노드를 가리키는 포인터를 저장해야 하므로, 추가적인 메모리 공간이 필요로한다. 특히 노드의 개수가 많을수록 포인터 오버헤드가 더 커질 수 있다.
포인터: 메모리 주소를 저장하는 변수로, 다른 변수나 데이터 구조의 위치를 가리키는 역할을 한다. 즉, 메모리내의 특정 위치를 가리키는 변수라고 할수 있다.
포인터 오버헤드 커짐: 일반적으로 포인터를 사용할 때 발생하는 부가적인 비용이나 메모리 사용량이 증가한다는 말이다.
4. 캐시 효율성 감소
- 연결 리스트는 노드들이 메모리에 연속적으로 저장되지 않기 때문에, CPU 캐시의 효율성이 감소할 수 있다. 이는 데이터를 읽을 때 메모리 접근 속도가 느려질 수 있음을 의미한다.
메모리 연속성과 CPU 캐시의 효율성
캐시 메모리는 일반적으로 한 번에 여러 개의 연속된 메모리 위치를 한번에 가져올 수 있다. 그러나 데이터가 연속적으로 저장되지 않으면 캐시가 한 번에 가져올 수 있는 데이터의 범위가 줄어들어 캐시의 효율성이 낮아진다.
연결 리스트는 데이터의 동적인 삽입과 삭제가 자주 발생하거나, 무작위 접근이 필요 없는 경우에 유용하게 사용될수 있다.
3. 스택(Stack)
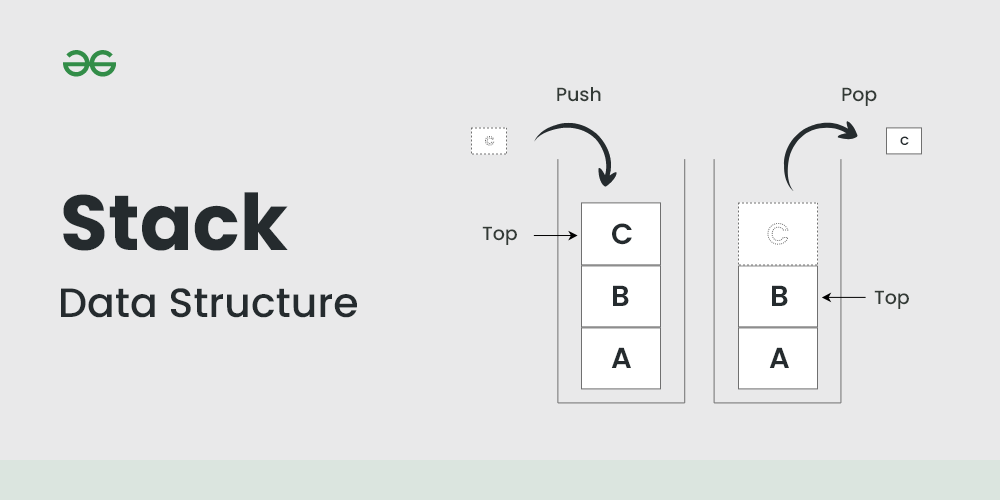
스택은 후입선출(LIFO, Last-In-Frist-Out) 구조를 가진 자료구조이다. 요소의 추가 및 삭제는 항상 최상위(top)에서 이루어 진다.
# Python에서 스택은 리스트를 활용하여 구현할 수 있습니다.
stack = []
# 데이터를 스택에 추가하는 함수
def push(item):
stack.append(item)
# 데이터를 스택에서 제거하고 반환하는 함수
def pop():
if not stack:
return "Stack is empty"
return stack.pop()
push(1)
push(2)
push(3)
print(pop()) # 출력: 3장점
1. 간단한 구현
- 스택은 간단한 자료구조로, 데이터의 삽입과 제거가 매우 간단하고 빠르게 이루어진다. 이는 스택이 배열이나 연결 리스트 등의 간단한 구조로 구현될 수 있다는 것을 의미한다.
2. 메모리 효율성
- 스택은 후입선출(LIFO) 구조이기 때문에 가장 최근에 삽입된 데이터가 가장 먼저 제거되는 특성을 가지고 있다. 이는 메모리의 관리를 단순화하고 메모리 사용량을 최적화하는 데 도움이 된다.
단점
1. 제한된 용량
- 스택은 일반적으로 정적으로 할당되는 용량을 가지고 있으며, 이 용량을 초과하는 데이터의 삽입을 허용하지 않는다. 이는 스택을 사용하는 프로그램에서 예상치 못한 오버플로우(overflow) 상황을 방지하기 위해 용량을 충분히 설정해야 함을 의미한다.
2. 프로그램 메모리 영역에 제한적
- 스택은 프로그램 메모리의 스택 영역에 할당되며, 이 영역은 제한적일 수 있다. 따라서 스택에 저장되는 데이터의 크기가 크거나 스택의 재귀적 호출이 너무 깊은 경우에는 스택 오버플로우가 발생할 수 있다.
스택 오버 플로우: 스택 메모리 영역에 할당된 메모리를 초과하여 데이터를 삽입하려고 할 때 발생하는 상황을 말한다. 스택은 데이터를 쌓아 올리고 제거하는데, 데이터의 양이 메모리에 할당된 용량을 초과하면 스택 오버 플로우가 발생하게 된다. 스택 오버 플로우가 발생하면 프로그램이 비정상적으로 종료되거나, 시스템 전체가 강제 종료될 수 있다.
스택은 간단하고 빠른 데이터 삽입 및 제거를 제공하는 반면에 제한된 용량과 메모리 영역에 제한적인 단점을 가지고 있다.
4. 큐(Queue)
- 큐는 선입선출(FIFO, First-In-First-Out) 구조를 가진 자료구조이다. 요소의 추가는 큐의 끝(rear)에서 이루어지고, 삭제는 큐의 시작(front)에서 이루어진다.
# Python에서 큐는 collections 모듈의 deque를 활용하여 구현할 수 있습니다.
from collections import deque
queue = deque()
# 데이터를 큐에 추가하는 함수
def enqueue(item):
queue.append(item)
# 데이터를 큐에서 제거하고 반환하는 함수
def dequeue():
if not queue:
return "Queue is empty"
return queue.popleft()
enqueue(1)
enqueue(2)
enqueue(3)
print(dequeue()) # 출력: 1장점
- 메모리 구조가 간단하고 직관적이며, 쉽게 구현할수 있다.
- 데이터가 선입선출 방식으로 처리되기 때문에 데이터의 처리 순서를 예측할 수 있다.
- 큐는 데이터를 추가하고 제거하는 연산이 각각의 끝에서 일어나기 때문에, 데이터를 추가하거나 제거할 때 다른 데이터에 영향을 미치지 않는다.
단점
- 큐의 크기가 제한되어 있을 경우, 큐가 가득 찬 상태에서 데이터를 추가하려고 하면 오버플로우가 발생한다.
- 큐에서 데이터를 제거할 때 데이터가 존재하지 않는 경우(비어있는 큐에서 데이터를 제거하려는 경우)에는 언더플로우가 발생한다.
- 배열을 이용한 정적 큐의 경우, 크기를 지정해야 하기 때문에 메모리를 효율적으로 사용하지 못할 수 있다.
- 동적 큐의 경우, 메모리의 할당과 해제로 인한 오버헤드가 발생할 수 있다.
- 비선형 자료 구조 -
1. 트리(Tree)
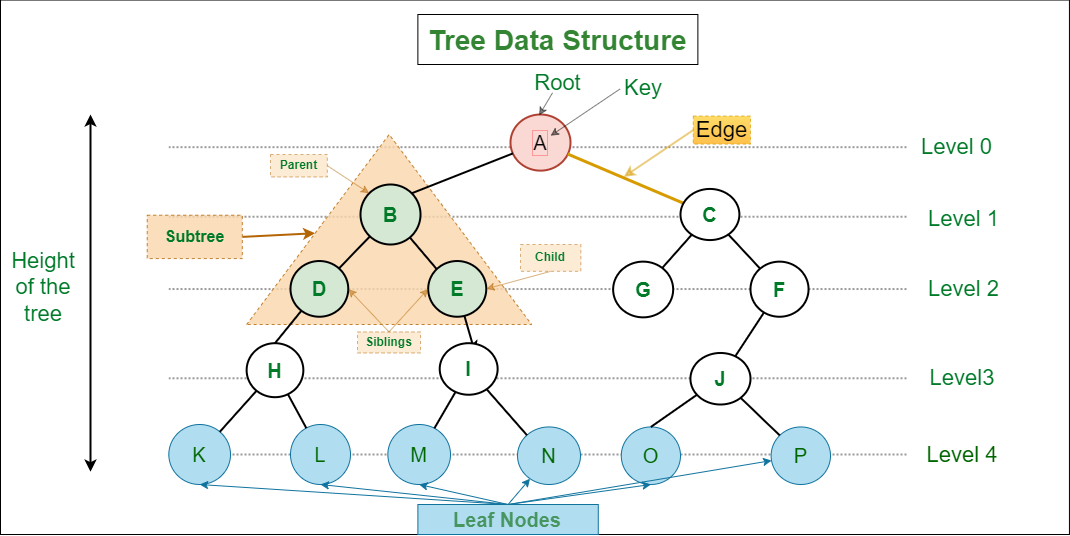
트리(Tree) 자료구조는 계층적인 구조로, 부모와 자식 노드 간의 관계를 가지고 있다. 각 노드는 하나의 부모 노드와 여러 개의 자식 노드를 가질 수 있다. 트리는 많은 형태와 종류가 있지만, 여기서는 이진 트리를 중점적으로 다룬다.
이진 트리의 장단점
장점
1. 빠른 검색 및 탐색
- 이진 트리는 데이터를 빠르게 검색할 수 있다. 트리의 높이에 따라 검색 시간이 결정되며, 잘 균형잡힌 트리일수록 빠른 검색이 가능하다.
2. 정렬된 데이터 저장
- 이진 탐색 트리(BST)의 경우, 데이터가 항상 정렬된 상태로 유지된다. 이를 이용해 범위 검색 등의 연산이 빠르게 수행될 수 있다.
3. 유연한 구조
- 트리는 다양한 문제 해결에 유용하게 사용될 수 있는 유연한 구조를 가지고 있다. 예를 들어, 파일 시스템이나 데이터베이스 인덱스 등에 활용될 수 있다.
단점
1. 메모리 사용량
- 일반적으로 트리는 링크드 리스트보다 더 많은 메모리를 사용한다. 각 노드에는 부모와 자식 노드를 가리키는 포인터가 있기 때문에 메모리 소모량이 높을 수 있다.
2. 삽입 및 삭제 비용
- 트리의 구조를 유지하기 위해 삽입 및 삭제 연산이 필요할 때, 비용이 발생할 수 있다. 특히 불균형한 트리에서는 이러한 연산이 더욱 비효율적일 수 있다.
이진 트리 메모리
1. 메모리 사용량
- 이진 트리의 경우 각 노드마다 포인터들을 저장해야 하므로 메모리 사용량이 크게 증가할 수 있다. 트리의 깊이가 깊어질수록 많은 메모리가 필요로 한다.
2. 포인터 오버헤드
- 포인터는 추가적인 메모리 공간을 차지하며, 메모리 접근 및 관리에 오버헤드를 초래할 수 있다. 트리가 매우 커지면 포인터 오버헤드가 증가할 수 있다.
3. 캐시 효율성
- 이진 트리의 경우 데이터가 메모리에 연속적으로 저장되지 않기 때문에 CPU 캐시의 효율성이 감소할 수 있다. 이는 메모리 접근 속도를 저하시킬 수 있다.
2. 그래프(Graph)
그래프(Graph)의 메모리에 따른 장단점은 주로 그래프를 표현하는 방식에 따라 다르고, 이에는 주로 인접 행렬(Adjacency Matrix)과 인접 리스트(Adjacency List)를 비교하는 것이 일반적이다.
인접 행렬(Adjacency Matrix)
장점
- 간선의 존재 여부를 바로 확인할 수 있어 빠른 접근이 가능하다.
- 두 정점 사이의 간선 가중치(Weight)를 효과적으로 저장할 수 있다.
단점
- 그래프의 크기가 커질수록 메모리 사용량이 증가한다. 특히 희소 그래프의 경우에도 많은 메모리를 사용하게 된다.
- 정점의 차수(Degree)가 낮은 경우에도 메모리를 낭비할 수 있다.
인접 리스트(Adjacency List)
장점
- 희소 그래프에서는 메모리를 효율적으로 사용할 수 있다. 연결된 정점들만 리스트로 저장하기 때문에 필요한 메모리가 적다.
- 정점의 차수에 비례하는 메모리만 사용하므로 정점의 차수가 낮은 경우에 효율적이다.
단점
- 특정 간선의 존재 여부를 확인하기 위해선 해당 정점의 리스트를 순회해야 한다. 이는 접근 시간이 인접 행렬에 비해 오래 걸릴 수 있다.
- 간선 가중치를 저장하기 어려운 경우가 있다.
3. 힙(Heap)
최댓값 또는 최솟값을 빠르게 찾을 수 있는 자료구조로, 트리의 형태를 가지고 있다. 최대 힙과 최소 힙이 있다.
장점
- 최대값 또는 최솟값을 빠르게 찾을 수 있다. 최대 힙은 루트 노드에 최대값을, 최소 힙은 루트 노드에 최솟값을 가지고 있어서 상수 시간(O(1))에 접근할 수 있다.
- 우선순위 큐와 같이 정렬된 데이터를 유지하고 싶을 때 유용하다.
단점
- 데이터의 삽입과 삭제에 대한 시간복잡도가 높다. 삽입 및 삭제 연산은 힙의 높이에 비례하여 시간이 걸리기 때문에 최악의 경우에는 O(log n)의 시간이 소요될 수 있다.
- 메모리 사용량이 상대적으로 크다.
4. 해시 테이블(Hash Table)
키-값(key-value) 쌍을 저장하는 자료구조로, 키를 해시 함수를 통해 배열의 인덱스로 변환하여 저장합니다.
장점
- 해시 함수를 사용하여 데이터를 저장하고 검색하기 때문에 매우 빠른 검색 속도를 가진다. 평균적으로 상수 시간(O(1))에 데이터에 접근할 수 있다.
- 메모리 공간을 효율적으로 사용할 수 있다. 충분한 해시 함수의 사용으로 해시 충돌을 최소화할 수 있다.
단점
- 충돌(Collision) 발생 시 처리해야 한다. 이를 위해 충돌을 해결하는 방법(예: 체이닝, 개방 주소법)이 필요하다.
- 해시 함수의 품질에 따라 성능이 크게 달라진다. 부적절한 해시 함수는 해시 충돌을 늘릴 수 있다.
.jpg)