3계층형 시스템
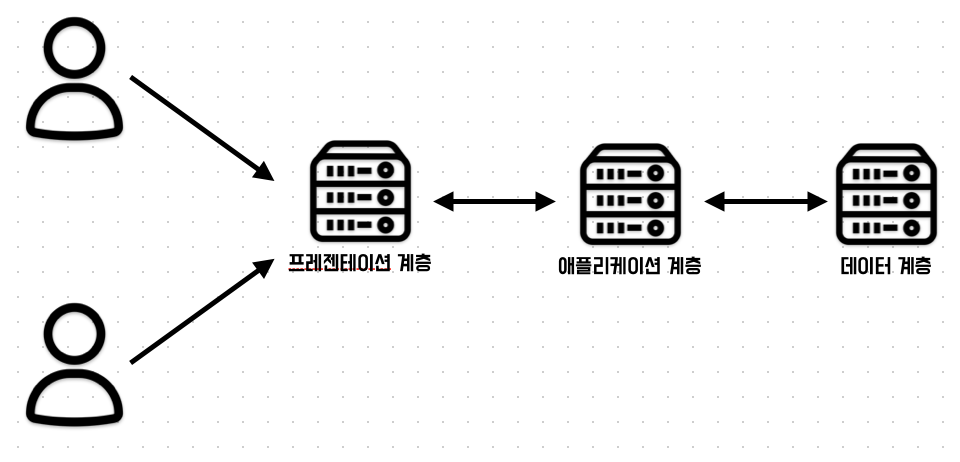
클라이언트-서버형을 발전시키고 각 계층의 역할을 명확히 구분되어 있는 시스템이다.
프레젠테이션 계층에서는 웹 서버, 애플리케이션 계층에서는 AP서버, 데이터 계층에서는 DB서버를 사용한다.
흐름
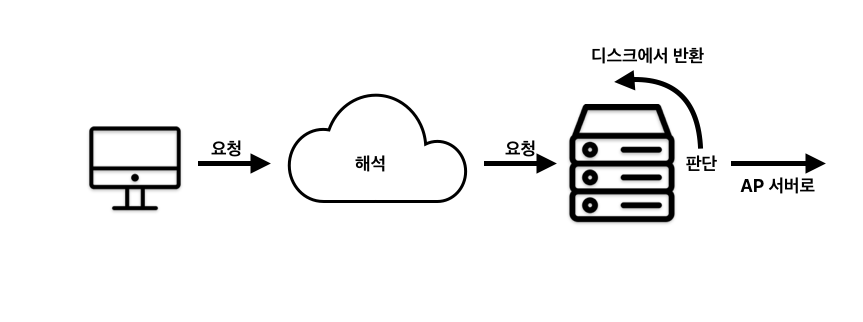
클라이언트 PC -> 웹 서버
- 웹 브라우저가 요청을 발행한다.
- 이름 해석을 한다.
- 웹 서버가 요청을 접수한다.
- 웹 서버가 정적 컨텐츠인지 동적 컨텐츠인지 판단한다.
- 필요한 경로로 데이터에 엑세스 한다.
클라이언트는 주소창에 주소를 입력을 한다.
하지만 웹 브라우저는 이 서버가 어디에 있는지 모르기 때문에 IP주소를 알아내기 위한 작업을 거친다.
웹 서버의 역할은 HTTP 요청에 대해 적절한 파일이나 컨텐츠를 반환하는 것이다.
이 때, 요청에 대한 응답으로 정적 컨텐츠와 동적 컨텐츠로 나누어 진다.
정적 컨테츠라면 디스크에 미리 저장해두고 이것을 바로 반환한다.
동적 컨텐츠는 웹서버의 디스크에 파일로 저장하면 비효율적이기 때문에 이 요청을 AP서버에 던지고 기다린다.
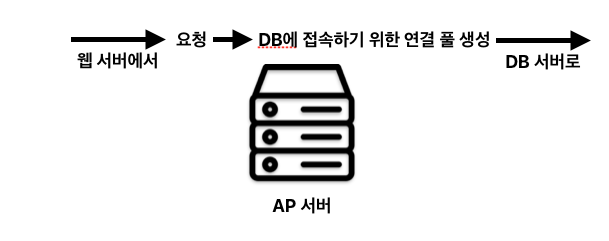
웹 서버 -> AP서버
- 웹 서버로부터 요청이 도착한다.
- 스레드가 요청을 받으면 자신이 계산할 수 있는지, 아니면 DB접속이 필요한지 판단한다.
- DB접속이 필요하면 연결 풀에 엑세스한다.
- DB서버에 요청을 던진다.
동적 컨텐츠에 대해서는 아직 존재하지 않는 컨텐츠를 만들어 내야한다. 이 역할을 담당하는 것이 AP 서버이다.
자바를 이용한 AP 서버에서는 Java Virtual Machine(JVM)이라 불리는 가상 머신이 동작하고 있다.
예를 들어 '1+1의 계산 결과'라는 요청이 들어온다면, 이런 단순한 요청은 AP서버에서 계산할 수 있기 때문에 담당 스레드가 계산한 후 결과를 반환한다.
AP서버에서 많은 데이터를 가지고 있는 것은 비효율적이고, 대량의 데이터 관리가 목적이라면 DB서버가 적합하다.
AP서버가 가지고 있지 않은 정보라면 AP서버의 스레드는 DB서버에 질의하고 그 결과를 HTML 등으로 정리해서 반환한다.
데이터가 필요하면 DB서버에 접속하는 것이 일반적이지만 항상 효율적이지는 않다.
잘 바뀌지 않고 규모가 작은 정보는 매번 데이터베이스에 질의하는 것이 아니라 AP서버 내부에 캐시로 저장해 두었다가 반환할 수 있다.
AP서버 -> DB서버
- AP서버로부터 요청이 도착한다.
- 프로세스가 요청을 접수하고 캐시가 존재하는지 확인한다.
- 캐시에 없으면 디스크를 엑세스한다.
- 디스크가 데이터를 반환한다.
- 데이터를 캐시에 저장한다.
- 결과를 AP서버에 반환한다.
각 서버의 동작은 다르지만 다음과 같은 공통점이 있다.
- 프로세스나 스레드가 요청을 받는다.
- 도착한 요청을 파악해서 필요에 따라 별도 서버로 요청을 보낸다.
- 도착한 요청에 대해 응답한다.
- 자신이 할수 없는 처리는 다음 서버에게 그 역할을 떠넘긴다.
실제로는 3계층보다 많은 계층을 이용하는 경우가 대부분이다.
