보조기억장치는 메모리의 휘발성을 보완하는 동시에, 메모리보다 큰 저장 공간을 제공
RAID
데이터의 안전성과 성능을 확보하기 위해 여러 개의 독립적인 보조기억장치를 하나의 저장장치처럼 구성하는 기술
📌 보조기억장치
현대에 대중적으로 사용되는 보조기억장치는 하드디스크(HDD)와 플래시 메모리 기반 저장장치(SSD)로 크게 나뉨
-
하드디스크 (Hard Disk Drive, HDD)
- 자기적인 방식으로 데이터를 읽고 쓰는 저장장치
- 주요 구성 요소:- 플래터: 동그란 원판
- 헤드: 플래터 위에 위치하여 데이터를 읽고 쓰는 리더기
-
플래시 메모리 (Flash Memory)
- 전기적인 방식으로 데이터를 읽고 쓰는 반도체 기반 저장장치
- 대표적인 플래시 메모리 기반 저장장치:- USB 메모리
- SD 카드
- SSD(Solid-State Drive): 주요 보조기억장치로 활용됨
-
보조기억장치의 역할
- 데이터 안전 보관: 전원이 꺼져도 데이터를 안전하게 유지
- 데이터 전달 성능: CPU가 필요로 하는 정보를 메모리로 빠르게 전달
RAID 레벨별 구성과 특징
1️⃣ RAID0
- 구성 방식: 데이터를 여러 디스크에 분산 저장 (스트라이핑, Striping)
- 장점:
- 빠른 입출력 속도 (여러 디스크에서 데이터를 동시에 읽고 쓰기 가능)
- 이론적으로 단일 디스크 대비 속도가 구성된 디스크 개수만큼 향상 - 단점:
- 데이터 안전성 부족 (디스크 중 하나라도 손상되면 전체 데이터 손실)
스트라입: 분산되어 저장된 데이터
스트라이핑: 분산하여 저장하는 동작
2️⃣ RAID1
- 구성 방식: 데이터를 복사하여 저장 (미러링, Mirroring)
- 장점:
- 데이터 복구가 간단하며 높은 안전성 제공 - 단점:
- 저장 공간이 효율적이지 않음 (복사본 저장으로 사용 가능 용량 절반 감소)
- RAID0보다 쓰기 속도가 느림
3️⃣ RAID4
- 구성 방식: 패리티 정보를 별도의 디스크에 저장하여 오류를 검출
- 장점:
- RAID1보다 적은 디스크로 데이터 안전성 확보 가능 - 단점:
- 병목현상 발생: 패리티를 저장하는 디스크가 과도한 작업으로 성능 저하
패리티(Parities): 오류를 검출할 수 있는 정보
4️⃣ RAID5
- 구성 방식: 패리티 정보를 분산하여 저장
- 장점:
- RAID4의 병목현상 문제 해결
- 데이터 안전성과 성능 간 균형 제공
5️⃣ RAID6
- 구성 방식: 서로 다른 2개의 패리티를 저장
- 장점:
- RAID4와 RAID5보다 더 높은 안전성 제공 - 단점:
- 데이터를 저장할 때 패리티가 2개 생성되므로 쓰기 속도 저하
RAID 레벨은 각기 다른 장단점을 가지며, 최적의 RAID 레벨은 사용자가 성능, 안전성, 저장 공간 중 어떤 요소를 우선시하느냐에 따라 달라질 수 있음
Nested RADI: 여러 RAID 레벨을 혼합한 방식
입출력 기법
보조기억장치를 포함한 다양한 입출력 장치들이 컴퓨터 내부와 정보를 주고받는 방식을 의미
장치 컨트롤러 / 장치 드라이버
1️⃣ 장치 컨트롤러(Device Controller)
- 하드웨어로, CPU와 입출력 장치 간의 통신을 중개하는 역할
- 각 입출력 장치는 고유의 장치 컨트롤러를 통해 컴퓨터 내부와 연결
- 예) CPU가 직접 하드디스크를 작동시키지 않고, 장치 컨트롤러를 통해 명령을 전달
장치 컨트롤러에는 RAM과 같은 저장 장치가 포함된 경우가 많음
CPU와의 데이터 교환 과정에서 중간 데이터를 저장
작업 도중 장치를 안전하게 제거하지 않으면 데이터 문제가 발생할 수 있음
2️⃣ 장치 드라이버(Device Driver)
- 장치 컨트롤러와 통신하는 소프트웨어 프로그램
- 장치 컨트롤러의 동작을 알고, 컴퓨터 내부와 정보를 주고받을 수 있도록 지원
- CPU가 실행하는 프로그램 형태로 작동
- 운영체제와의 관계:
대중적인 드라이버는 윈도우, 맥OS 등 운영체제에 기본 포함되어 별도 설치 없이 사용 가능
특수 장치(예: 대형 프린터)는 별도의 드라이버 설치가 필요
프로그램 입출력
프로그램 입출력은 CPU가 명령어를 통해 입출력 작업을 수행하는 방식
- "프린터 컨트롤러의 상태를 확인하라"
- "하드디스크 컨트롤러에 데이터를 써라"
CPU는 이러한 입출력 명령어를 실행하여 장치 컨트롤러와 상호작용하며 입출력 작업을 수행
📌 프로그램 입출력의 두 가지 방식

인터럽트 기반 입출력: 다중 인터럽트
다중 인터럽트란 키보드, 마우스, 모니터, 스피커 등 여러 입출력 장치에서 동시에 인터럽트 요청이 발생하는 상황을 의미
CPU는 이러한 다중 인터럽트를 효율적으로 처리해야 함
- 순차적인 기본 인터럽트 서비스 루틴 ↓
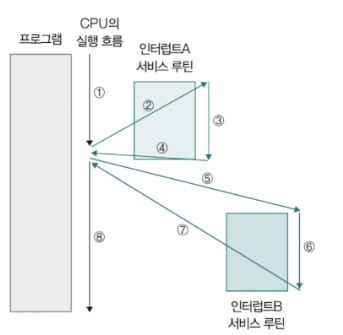
하지만 모든 인터럽트가 위 그림과 같이 처리되지 않음
📌 다중 인터럽트 처리 방식
1️⃣ 순차적 처리
- 플래그 레지스터의 인터럽트 비트가 비활성화된 경우, CPU는 발생한 인터럽트를 순서대로 처리
- 예: 인터럽트 A → B → C 순서로 처리
2️⃣ 우선순위 기반 처리
- 인터럽트의 우선순위에 따라 처리 순서를 결정
- 예:
- B의 우선순위 > A: CPU는 A를 중단하고 B를 먼저 처리
- A의 우선순위 > B: CPU는 A를 모두 처리한 후 B를 처리
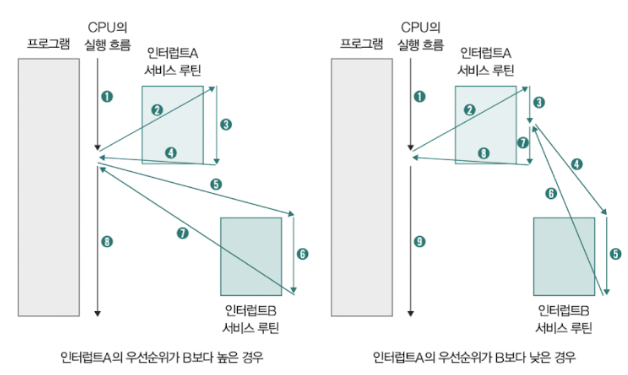
CPU는 플래그 레지스터 속 인터럽트 비트가 활성화되어 있는 경우, 혹은 인터럽트 비트를 비활성화해도 무시할 수 없는 인터럽트인 NMI가 발생한 경우, 이렇게 우선순위가 높은 인터럽트 부터 먼저 처리하게 됨
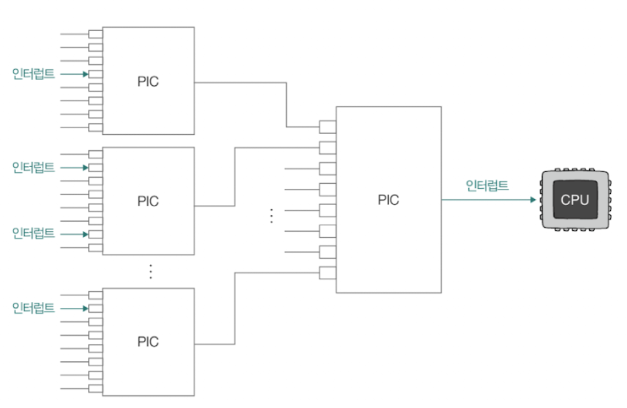
📌 우선순위 판별: 프로그래머블 인터럽트 컨트롤러 (PIC)
CPU와 장치 컨트롤러 사이에서 우선순위를 판별하고, 처리할 인터럽트를 CPU에 전달하는 하드웨어 장치
- PIC에는 여러 핀들이 있는데, 각 핀에 CPU에게 하드웨어 인터럽트 요청을 보낼 수 있도록 약속된 하드웨어가 연결되어 있음
- 예:
첫 번째 핀 → 타이머 인터럽트
두 번째 핀 → 키보드 인터럽트> 무시할 수 없는 인터럽트(NMI)는 PIC에서 판별하지 않음
일반적으로 PIC는 많은 하드웨어 인터럽트를 관리하기 위해 2개 이상의 계층으로 구성
DMA 입출력
📌 기존 입출력 방식의 한계
- 프로그램 기반 입출력과 인터럽트 기반 입출력은 모두 데이터 이동을 CPU가 주도
- 데이터가 메모리와 입출력 장치 간에 전송될 때 반드시 CPU를 거쳐야 함
- 예:
- CPU가 장치 컨트롤러에서 데이터를 읽어 레지스터에 적재
- 적재된 데이터를 메모리에 저장
- 반대의 경우도 동일한 방식으로 진행
- 예:
- 문제
- 모든 데이터 전송이 CPU를 거치므로, CPU의 부담이 커지고 성능 저하 발생
📌 DMA 의 등장
-
DMA(Direct Memory Access)
- 직접 메모리에 접근할 수 있는 입출력 기능
- DMA는 CPU를 거치지 않고, 입출력 장치와 메모리가 직접 데이터를 주고받을 수 있는 방식이다. -
구조
- DMA를 위해 DMA 컨트롤러라는 하드웨어가 필요
- DMA 컨트롤러는 시스템 버스에 연결되고, 입출력 장치의 장치 컨트롤러는 입출력 버스를 통해 DMA 컨트롤러와 연결
📌 DMA 입출력의 과정
1️⃣ CPU가 DMA 컨트롤러에게 입출력장치의 주소, 수행할 연산, 연산할 메모리 주소 등의 정보와 함께 입출력 작업을 명령
2️⃣ DMA 컨트롤러가 CPU 대신 장치 컨트롤러와 상호작용하며 입출력 작업을 수행. 이 때 DMA 컨트롤러는 필요한 경우 메모리에 직접 접근하여 정보를 읽거나 씀. 입출력장치와 메모리 사이에 주고 받을 데이터가 CPU를 거치지 않음
3️⃣ DMA 컨트롤러는 입출력 작업이 끝나면 CPU에게 인터럽트를 걸어 작업이 끝났음을 알림
- CPU 입장에서는 DMA 컨트롤러에게 입출력 작업 명령을 내리고, 입터럽트만 받으면 되기 때문에 입출력 부담을 크게 줄일 수 있음
📌 사이클 스틸링 (Cycle Stealing)
공용 자원인 시스템 버스의 특징
- 시스템 버스는 공용 자원이므로 동시에 여러 장치가 사용할 수 없음
- DMA 컨트롤러와 CPU는 시스템 버스를 번갈아 사용해야 함
- DMA 컨트롤러가 시스템 버스를 사용할 때, CPU가 버스 사용을 양보하거나 버스를 사용하지 않는 타이밍에 DMA가 버스를 사용하는 방식
- CPU 입장에서는 마치 버스 접근 사이클을 도둑맞는 것처럼 느껴진다는 점에서 "사이클 스틸링(Cycle Stealing)"이라는 이름이 붙음
📌 PCIe (Peripheral Component Interconnect Express)
PCI 버스의 발전된 형태로, 현대에 메인보드에서 가장 널리 사용되는 입출력 버스
PCIe 성능 관련 주요 개념
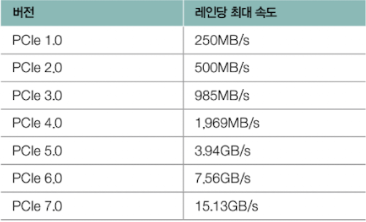
1️⃣ PCIe 버전
PCIe는 지속적으로 발전하고 있으며, 버전에 따라 지원되는 최대 속도가 다름
주요 버전과 한 레인당 최대 속도:
2️⃣ PCIe 레인 (Lane)
레인(Lane): PCIe 버스를 통해 데이터를 송수신하는 단위
레인의 수가 많아질수록 한 번에 처리할 수 있는 데이터 양이 증가
예:
PCIe 4.0 x1 → 1 레인 사용 (1,969 MB/s)
PCIe 4.0 x4 → 4 레인 사용 (1,969 MB/s × 4 = 7,876 MB/s)
추가 내용
GPU의 용도와 처리 방식
GPU (Graphic Processing Unit)
그래픽 처리 장치로로 화면에 그림을 그리는 등 대량의 그래픽 연산을 위한 장치
- 최근에는 그래픽 연산을 넘어 딥러닝, 가상화폐 채굴 등 다양한 범용 연산에도 활용
- GPGPU (General-purpose computing on Graphics Processing Units): GPU를 범용 연산에 사용하는 기술
📌 GPU의 특징
1️⃣ 다수의 코어로 병렬 처리
- GPU는 수백~수천 개의 코어를 포함 → 병렬 처리에 매우 적합
- 병렬 처리: 큰 문제를 여러 개의 작은 문제로 나누고 이를 동시에 처리하는 방식
2️⃣ 고성능 연산 처리
- 자체적으로 캐시 메모리와 대용량 메모리(최대 수십 GB)를 보유
- 산술 연산과 같은 단순 연산을 빠르게 처리
3️⃣ GPU는 CPU를 대체하지 않음
- GPU 개별 코어는 CPU 코어에 비해 성능이 떨어짐
- GPU는 복잡한 작업보다 단순한 작업을 병렬적으로 빠르게 수행
- GPU는 CPU의 보조 프로세서(co-processor)로서 산술 연산을 지원
📌 GPU의 활용: CUDA 프로그래밍
CUDA (Compute Unified Device Architecture):
엔비디아(NVIDIA)가 개발한 GPU 프로그래밍 모델
호스트 코드(CPU 실행 코드)와 디바이스 코드(GPU 실행 코드)로 구성
프로그래밍 언어를 통해 GPU의 병렬 연산 작업을 쉽게 구현 가능
CUDA 프로그램 예제:
#include <stdio.h>
__global__ void cuda_hello() {
printf("Hello World from GPU\n"); // GPU가 실행하는 코드
}
int main() {
cuda_hello<<<1, 1>>>(); // GPU로 디바이스 코드 실행 명령
cudaDeviceSynchronize(); // CPU가 GPU 작업 완료를 기다림
return 0;
}
GPU는 대량의 단순 연산을 빠르게 처리하며, 병렬 처리에 최적화된 장치
GPU: 단순 연산 병렬 처리
CPU: 복잡한 명령어와 시스템 관리
참고: 북스터디 - 이것이 취업을 위한 컴퓨터 과학이다 (Chapter 2-5)
