보다 효율적으로 데이터베이스에 질의할 수 있는 다양한 방법
서브 쿼리와 조인
서브 쿼리
- 서브 쿼리: SQL문 안에 포함된 또 다른 SELECT문을 의미
- MySQL 공식 문서 기준으로는 소괄호
()로 감싸진 SELECT문을 말함 - 서브 쿼리는 SELECT / INSERT / UPDATE / DELETE 문 안에 포함될 수 있음
- 서브 쿼리는 중첩도 가능 즉, 서브 쿼리 안에 또 다른 서브 쿼리를 포함할 수 있음
📌 서브 쿼리 예제
SELECT문 안에 SELECT문이 포함된 서브 쿼리
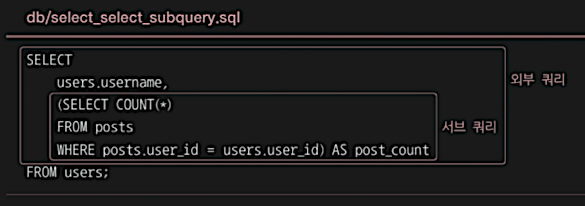
외부 쿼리는 users 테이블에서 username과 서브 쿼리의 결과를 조회
그리고 서브 쿼리의 결과를 post_count라고 간주함(AS post_count),
서브 쿼리는 posts 테이블의 user_id와 users 테이블의 user_id가 같은 posts 테이블의 레코드 수를 조회
즉, 사용자별로 작성한 글의 개수를 조회하는 SQL문
DELETE문 안에 DELETE문이 포함된 서브 쿼리
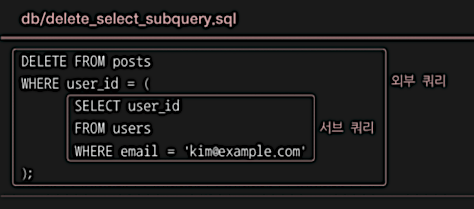
외부 쿼리는 posts 테이블에서 user_id가 서브 쿼리의 결과와 같은 레코드를 삭제
그리고 서브 쿼리는 users 테이블에서 email이 kim@example.com인 레코드를 조회
즉, email이 kim@example.com인 사용자의 글을 삭제하는 SQL문
조인
- 조인: 여러 테이블을 하나로 논리적으로 합쳐서 조회하는 방법
- INNER JOIN: 양쪽 테이블에 모두 존재하는 데이터만 반환
- OUTER JOIN:
- LEFT OUTER JOIN: 왼쪽 테이블은 모두, 오른쪽은 일치하는 것만
- RIGHT OUTER JOIN: 오른쪽 테이블은 모두, 왼쪽은 일치하는 것만
- FULL OUTER JOIN: 양쪽 테이블 모두 포함 (MySQL은 직접 지원하지 않음, UNION으로 구현 가능)

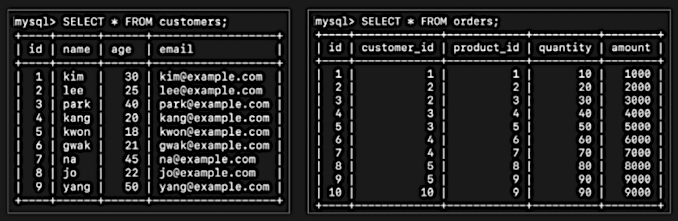
📌 테이블/레코드 생성 예제
📌 INNER 조인
가장 일반적인 조인으로 보통 '조인'이라 하면 INNER 조인을 의미하는 경우가 많음
orders.customer_id와 customers.id를 기준으로 INNER 조인
SELECT customer.name, customer.age, customer.email, order.id,
orders.product_id, orders.quantity, orders.amount
FROM customers
INNER JOIN orders ON customer.id = orders.customer_id;이 SQL문의 결과는 customers 테이블의 name, age, email 필드와 orders 테이블의 id, product_id, quantity, amount가 필드로 구성된 하나의 테이블 형태로 조회됨
조인 결과에 대해 WHERE절을 추가하면 조건에 따라 레코드를 필터링하여 조회할 수도 있음
SELECT customers.name, customers.age, customers.email,
orders.id, orders.product_id, orders.quantity, orders.amount
FROM customers
INNER JOIN orders ON customers.id = orders.customer_id
WHERE orders.amount >= 5000;📌 LEFT OUTER JOIN
customers 테이블과 orders 테이블의 LEFT OUTER 조인 결과
customers 테이블의 모든 항목을 선택하고, 이를 기준으로 orders 테이블의 레코드를 합치되,
customers 테이블의 레코드 중 orders 테이블의 레코드에 대응되는 레코드가 없는 경우 NULL이 채워짐
SELECT customer.name, orders.id AS order_id, orders.product_id,
orders.quantity, orders.amount
FROM customers
LEFT OUTER JOIN orders ON customers.id = orders.customer_id;📌 RIGHT OUTER JOIN
RIGHT OUTER 조인은 LEFT OUTER JOIN과 정확하게 반대
customers 테이블과 orders 테이블의 RIGHT OUTER 조인 결과
orders테이블의 모든 항목을 선택하고, 이를 기준으로 customers 테이블의 레코드를 합치되,
orders 테이블 레코드 중 customers 테이블의 레코드에 대응되는 레코드가 없는 경우 NULL이 채워짐
SELECT customer.name, orders.id AS order_id, orders.product_id,
orders.quantity, orders.amount
FROM customers
RIGHT OUTER JOIN orders ON customers.id = orders.customer_id;📌 FULL OUTER JOIN
MySQL을 포함한 많은 RDBMS에서는 FULL OUTER 조인 문법을 따로 지원하지 않음
그러나 FULL OUTER 조인 문법을 명시적으로 지원하지 않더라도 LEFT OUTER 조인과 RIGHT OUTER 조인의 결과를 하나로 합치면 FULL OUTER 조인을 구현할 수 있음
이 과정에서 여러 SQL문을 결합하는 키워드인 UNION이 사용될 수 있음
customers 테이블과 orders 테이블을 각각 LEFT OUTER 조인, RIGHT OUTER 조인한 뒤,
그 결과를 하나로 합친 형태로 구현
SELECT customer.name, orders.id AS order_id, orders.product_id,
orders.quantity, orders.amount
FROM customers
LEFT OUTER JOIN orders ON customers.id = orders.customer_id;
UNION
SELECT customer.name, orders.id AS order_id, orders.product_id,
orders.quantity, orders.amount
FROM customers
RIGHT OUTER JOIN orders ON customers.id = orders.customer_id;products 테이블에 없는 customers 테이블의 레코드가 NULL로 채워지고,
customers 테이블에 없는 products 테이블의 레코드가 NULL로 채워짐
뷰
- 뷰: SELECT문의 결과로 만들어진 가상의 테이블
- 물리적으로 데이터를 저장하지 않음, 쿼리 결과를 재사용 가능
-- 생성
CREATE VIEW 뷰_이름 AS SELECT문;
-- 삭제
DROP VIEW 뷰_이름;예시
CREATE VIEW myview AS
SELECT users.username, user.email, posts.title
FROM users, posts
WHERE users.user_id = posts.user_id;myview뷰는 마치 하나의 논리적인 테이블처럼 활용할 수 있음- 복잡한 조인 또는 조건식을 단순화하여 재사용할 수 있음
- 권한 관리에도 사용 가능: 특정 사용자에게 일부 컬럼만 노출하는 뷰 제공 가능
- 뷰는 조회는 자유롭지만, 삽입/수정/삭제는 제한이 있을 수 있음
- 특정 사용자에게 권한 부여 시 GRANT 명령 사용
인덱스
- 검색 성능을 향상시키기 위한 테이블 필드의 자료구조
- 대표 구조: B-Tree, 해시 테이블
- MySQL 기준:
- 클러스터형 인덱스: 기본 키 인덱스 (테이블당 1개)
- 세컨더리 인덱스: 일반 인덱스 (여러 개 가능)
클러스터형 인덱스: 테이블당 하나씩 만들 수 있는 인덱스
우리가 이미 접해 본 적이 있는 유형의 인덱스(기본 키)
세컨더리 인덱스: 클러스터형 인덱스가 아닌 인덱스. 논클러스터형 인덱스라고도 부름
테이블당 여러 개가 존재할 수 있지만 클러스터형 인덱스를 활용한 검색보다 일반적으로 느림
-- '테이블_이름'의 '필드'에 세컨더리 인덱스인 '인덱스_이름'을 생성
CREATE INDEX 인덱스_이름 ON 테이블_이름 (필드);
-- 인덱스 조회
SHOW INDEX FROM 테이블_이름;
-- 인덱스 삭제
DROP INDEX 인덱스_이름 FROM 테이블_이름;인덱스로 사용되는 대표적인 자료구조는 해시 테이블과 B 트리
📌 인덱스를 모든 필드에 생성하지 않는 이유
- 인덱스 생성에는 부작용이 따름
- 저장 공간과 생성 시간도 필요
- 인덱스도 자료구조이므로, 데이터가 많을수록 부하가 큼
- 조회(SELECT) 성능은 향상되지만 그 외의 작업(삽입, 수정, 삭제)에는 오히려 성능 저하 발생
- 데이터를 조작할 때 인덱스도 함께 갱신해야 하므로, 추가 자원과 연산이 필요함
-
인덱스 활용 상황
- 데이터가 충분히 많은 테이블
- 조회가 자주 이루어지는 테이블
- 특히 JOIN, WHERE, ORDER BY에 자주 사용되는 필드에 적절함 -
중복값이 많은 필드는 인덱스 효과가 떨어짐
-
인덱스 개수는 3개 이하가 일반적인 권장 기준
참고: 북스터디 - 이것이 취업을 위한 컴퓨터 과학이다 (Chapter 6-4)
