Object Tracking이란?
- object detection + tracking
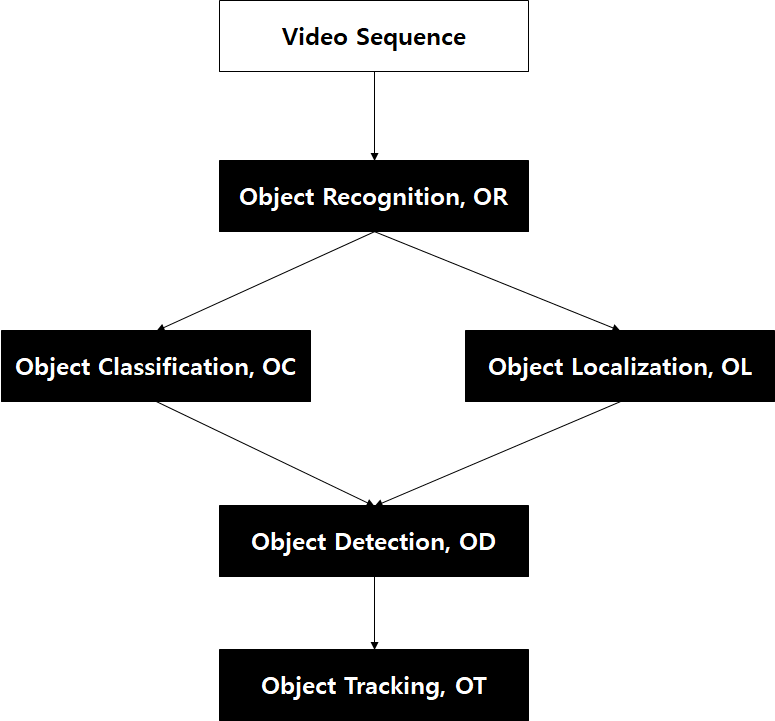
MOT의 목적은 연속적인 프레임에서 여러 관심 객체의 궤적을 추정하는 것이다.
Object Detection Model
- 영상에서 관심있는 경계 상자(Bounding Box) 영역의 위치를 추정
Association Model
-
각 경계 상자에 대한 Re-identification(이하 Re-ID) 특징을 추출하여 정의된 특정 메트릭에 따라 기존에 존재하는 트랙 중 하나에 연결시킴
-
장점
모델이 발전함에 따라 추적 성능이 향상됨
-
단점
각 모델의 두 단계 끼리 특징을 공유하지 않기 때문에 실시간 성능을 보장할 수 없다는 문제가 있음
-
결론
태스킹 학습 방식이 떠오름에 따라 객체를 탐지하고, Re-ID 특징까지 학습하는 One-Shot 방법을 사용.이러한 One-Shot 방법의 정확도는 Two-step 방법에 비해 현저히 떨어진다는 단점을 갖는다. 그래서 이 두 작업을 결합할 때, "어떠한 트릭"을 사용하여 정확도를 높이는 방식으로 학습해야한다.
-
MOT 정확도에 영향을 미치는 세 가지 중요한 요소
(1) Anchors don't fit Re-ID
현재 one-shot tracker 는 모두 객체 탐지기 기반이기 때문에 anchor 를 기반으로 하고있다. 그러나 anchor 는 Re-ID 특징을 학습하는데 적합하지 않다. 왜냐하면 서로 다른 이미지 패치에 해당하는 multiple anchors 가 동일한 객체의 identity 를 추정할 필요가 있는데, 이로 인해 신경망에 심각한 ambiguity 가 발생 하기 때문이다. 즉, 주변에 다른 객체를 나타내는 여러 anchor 들은 학습 시 모호성을 줄 수 있다. 또한 feature map은 일반적으로 정확도와 속도의 trade off 를 위해 8번씩 down-sampling 된다. 이는 객체 중심이 객체의 identity 를 예측하기 위해 coarse anchor 위치에서 추출된 특징과 align 되지 않을 수 있기 때문에 탐지에는 적합하지만, Re-ID 에는 너무 coarse 하다는 문제점을 가진다. 따라서 high-resolution feature map 의 top 에서 픽셀 방식의 keypoint estimation (object center) 추정 및 identity classification 를 통해 이러한 문제를 해결한다.
(2) Multi-Layer Feature Aggregation
Re-ID 특징은 small 및 large 객체들을 모두 accommodate 하기 위해 low-level 및 high-level 특징들을 모두 활용해야한다. 본 논문에서는 스케일 변화를 처리하는 능력을 향상 시켜 one-shot 방법 기반으로 identity high-resolution 를 줄였다. two-step 방법의 경우 cropping 및 resizing 작업 후 물체의 스케일이 비슷해진 채로 적용되기 때문에 스케일 문제를 개선 시킬 필요가 없다.
(3) Dimensionality of the ReID Features
이전의 Re-ID 방법들은 일반적으로 high dimensional feature 들을 학습하고, 벤치마크에서 좋은 결과를 얻어왔다. 하지만 본 논문에서는 Re-ID 보다 학습 이미지가 적기 때문에(Re-ID 데이터 세트는 잘린 이미지 만 제공하기 때문) lower-dimensional feature 가 MOT에 실제로 더 좋다는 사실을 발견하였다. 이러한 lower-dimensional feature 를 사용하면 small data 에 대한 overfitting 을 줄이고, tracking robustness 를 향상 시킬 수 있다.

Model Approach
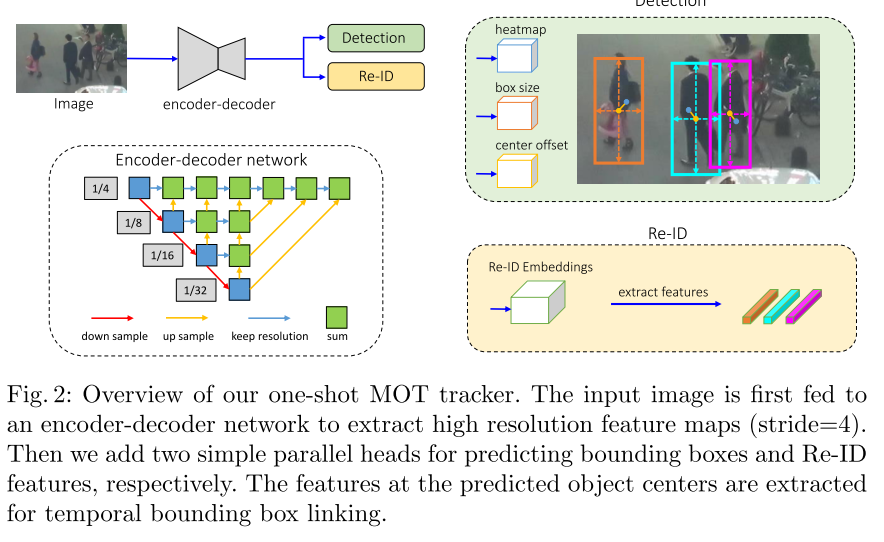
-
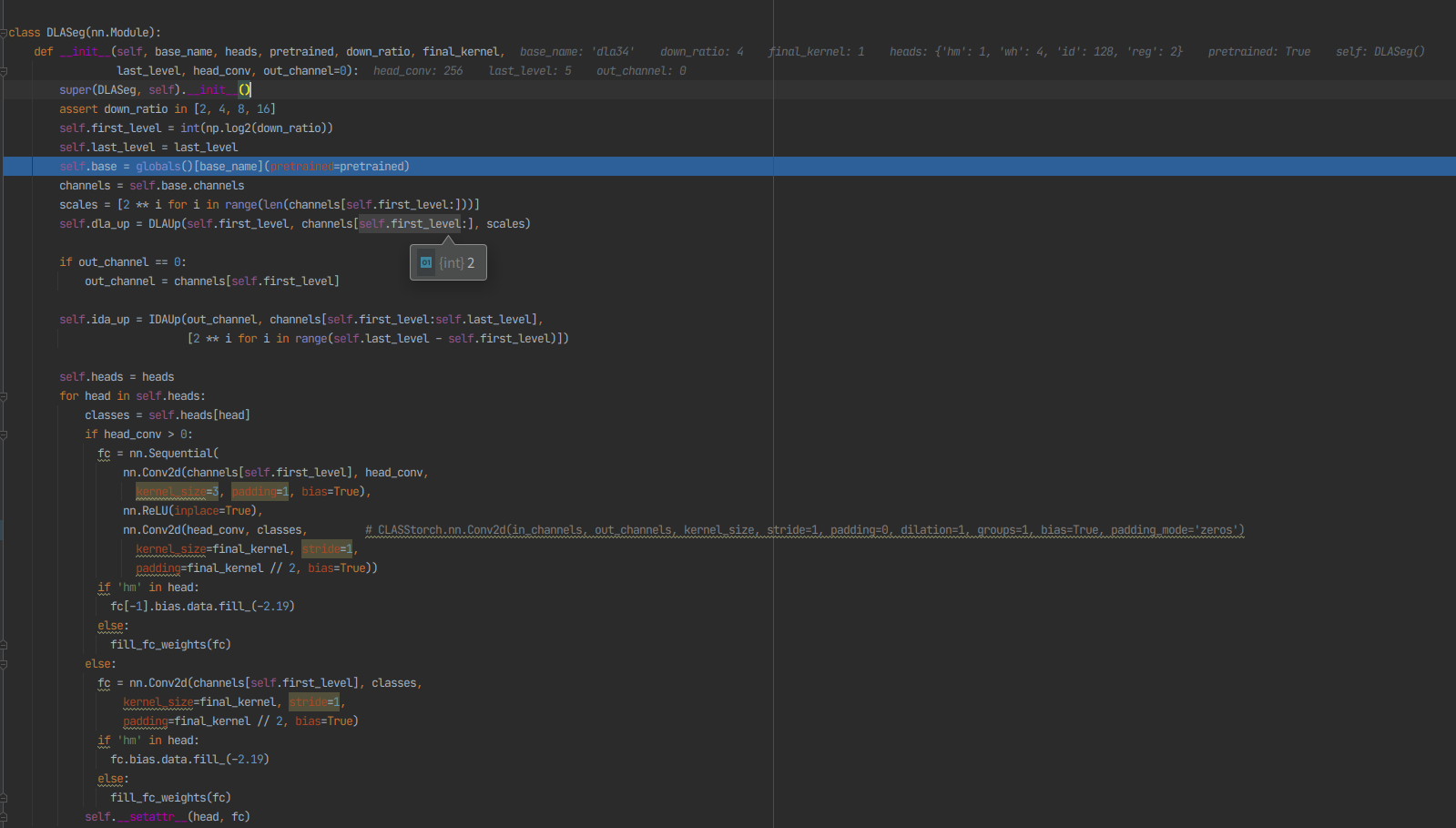
Backbone Network
정확도와 속도의 trade-off 를 위하여 ResNet-34 를 백본으로 설정하였다. 다양한 스케일의 객체를 수용하기 위해 Deep Layer Aggregation(DLA)이 백본에 적용된다. original DLA와는 달리, Feature Pyramid Network(FPN) 와 유사한 low-level 및 high-level feature 간에 더 많은 skip connection 이 존재한다. 또한 up-sampling 모듈의 모든 컨볼루션 레이어는 deformable convolution layer 로 대체되어 객체 스케일 및 포즈에 따라 receptive field 를 동적으로 조정할 수 있다. 이러한 변경 사항은 align 문제를 완화 하는데 도움을 줄 수 있다. 이 모델의 이름은 DLA-34 로 정한다. 입력 이미지의 크기를 H x W 라고 하면 output feature map 의 모양은 C x H' x W' 이며, 이 때 H' 는 H/4 이며, W'는 W/4 이다.
-
Object Detection Branch
객체 탐지는 high-resolution feature map 에서 center-based 의 bounding box regression task 를 수행한다. 특히 3개의 parallel regression head 가 백본 신경망에 추가되어 각각 heatmap, object center offset, bounding box size 를 추정한다. 각 head 는 3x3 conv(256 channel) 을 백본 신경망의 output feature map에 적용한 다음, final target 을 생성하는 1x1 conv 를 적용하여 구현된다.
- Heatmap Head
- 이 head 는 객체 중심의 위치를 추정한다. landmark point estimation task 의 표준인 heatmap 기반 representation 이 여기서 사용된다. 특히 heatmap 의 dimension 은 1 x H x W 이다. heatmap 의 위치에 대한 response 는 ground-truth object center 로 붕괴될 경우의 반응으로 예상된다. heatmap 의 위치와 object center 사이의 거리에 따라 response 는 기하 급수적으로 감소한다.
- Center Offset
- head 는 객체를 보다 정확하게 localization 한다. feature map 의 stride 는 non-negligible quantization error 를 유발할 수 있다. 객체 탐지의 성능의 이점은 미미할 수 있으나, Re-ID 의 특징은 정확하게 object center 에 따라 추출되어야 함으로 tracking 에서는 중요하다는 특징을 가진다. 실험에서 Re-ID 의 특징을 object center 와 carefull alignment 하는 것이 성능에 중요하다는 것을 발견하였다.
- Box Size Head
- 이는 각 anchor 위치에서 target bounding box 의 높이와 너비를 추정한다. 이 head 는 Re-ID 특징과는 직접적인 관련이 없지만, localization 정확도는 객체 탐지 성능 평가에 영향을 미친다 ****
-
Identity Embedding Branch
identity embedding branch 의 목표는 다른 객체와 구별할 수 있는 특징을 생성하는 것이다. 이상적으로는 서로 다른 객체 사이의 거리가 같은 객체 사이의 거리보다 커야한다. 즉, 같은 객체는 다른 프레임 상에서의 위치가 가까이 붙어있는 편이 이상적이다. 다른 객체와 구별할 수 있는 특징을 생성하기 위해 백본 특징 위에 128개의 커널이 포함된 conv layer 를 적용하여 각 위치에 대한 identity embedding feature 를 추출한다. output feature map 인 E 는 128 x W x H 영역에 포함되며, Re-ID feature 인 x, y 에서의 E 는 128에 속하고, 객체의 x, y 는 feature map 으로부터 추출된다.
-
Tracking Algorithm
-
칼만필터
-
칼만은 기존 추적하던 물체의 속도를 반영해서 다음 상황을 예측한다고 생각하면 쉽다.
-
과거의 값을 이용하여 현재값을 예측하고
-
예측값과 측정값에 각각 노이즈를 반영한 뒤, 실제값을 예측한다.
-
이 실제값을 다시 다음 측정에 사용한다.
( p.s 측정값을 그냥 쓰면 되는거 아니냐고 생각할 수 있지만 노이즈라는 개념이 들어가면 (원래 센서퓨전에 쓰려고 만든 알고리즘이므로) 측정값도 100% 신뢰할 수 없다는 것을 알 수 있다. )
-
-
-
헝가리안 알고리즘
-
최소값을 찾아준다
-
pose_dla_dcn.py
-
demo_track.py
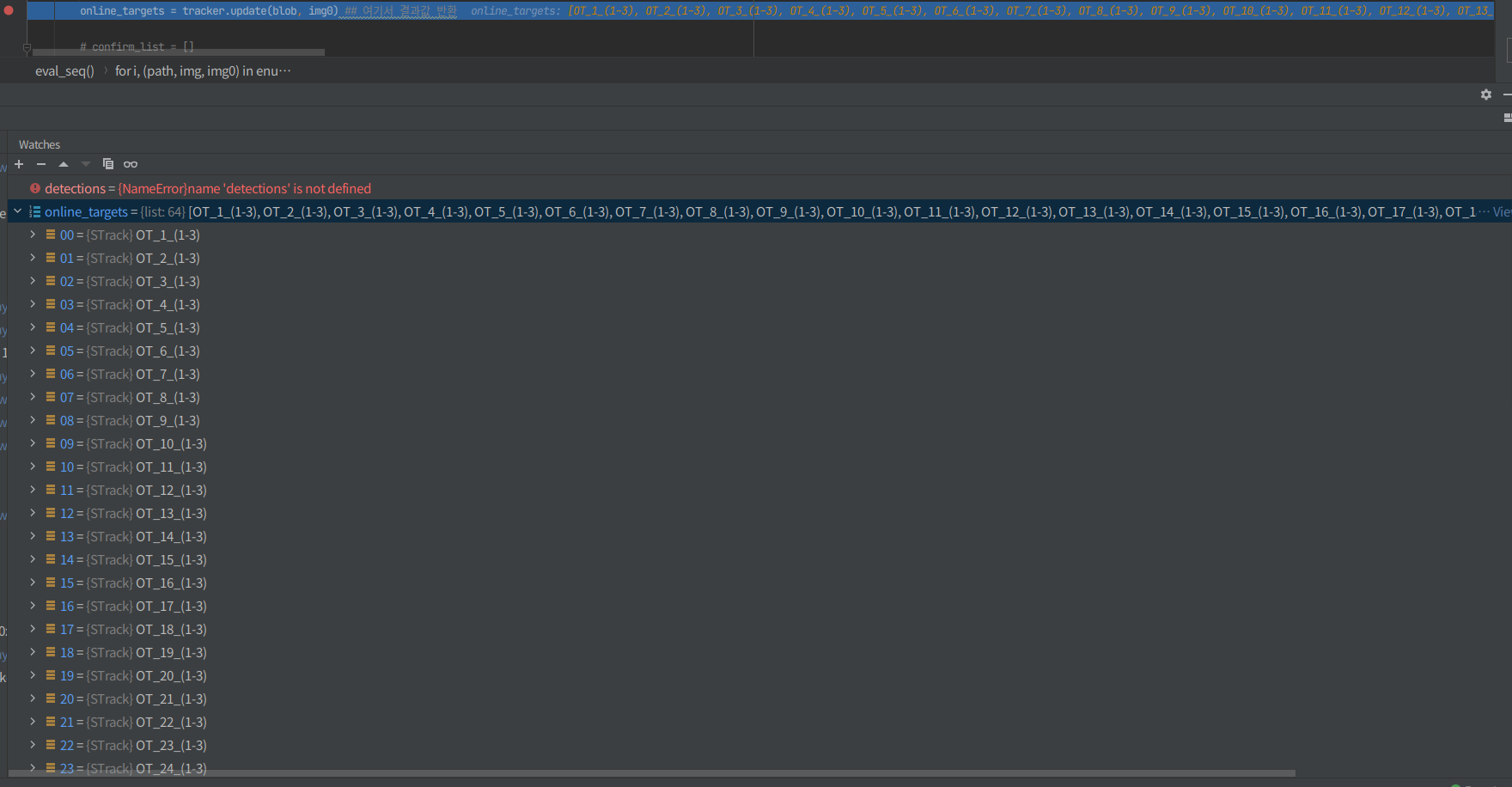
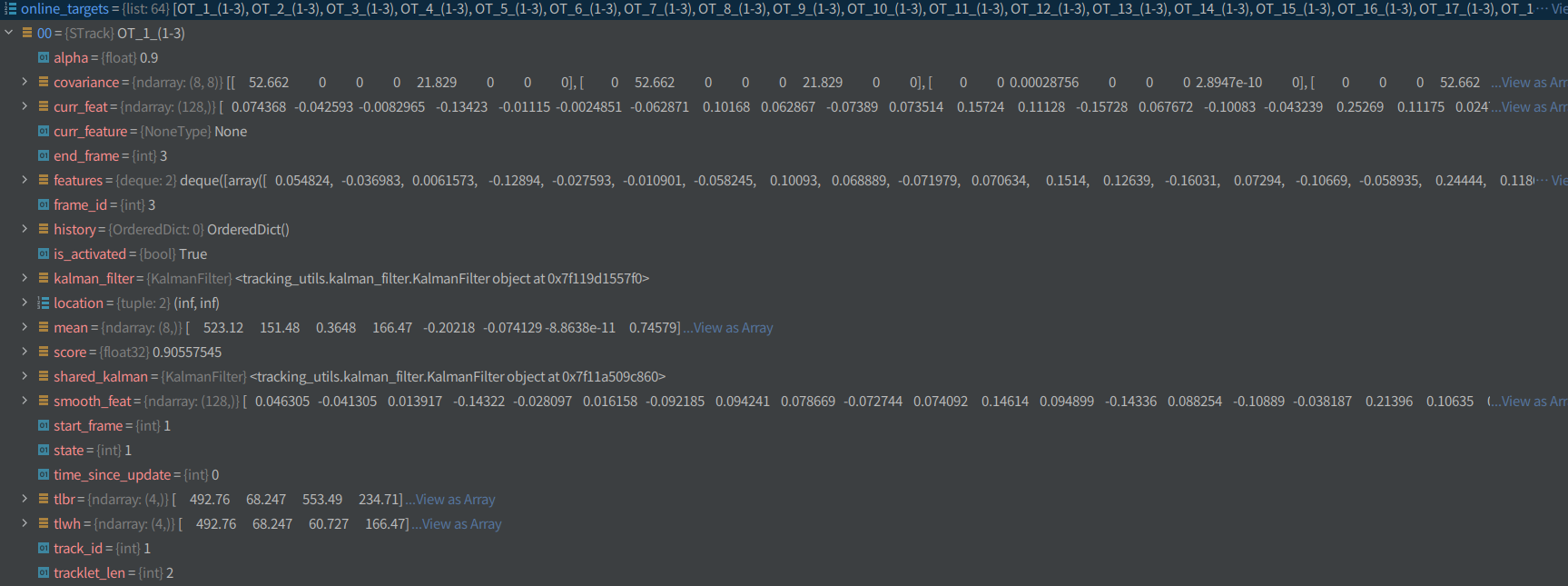
-
tracker.update(blob, img0) ## 여기서 결과값 반환
img0 : frame 이미지
blob : img0에서의 윤관값을 결정한 이후에 메모리의 연속 배열을 반환값을(C 순서) 255.0으로 나눈 값
STrack형태로 각각의 detection된 값들과 tracking 결과값이 반환됨

- 여기서 숫자 30이 frame 몇 개까지 비교할지 결정 (default buffer size값 30 )
-
embedding_distance 비교
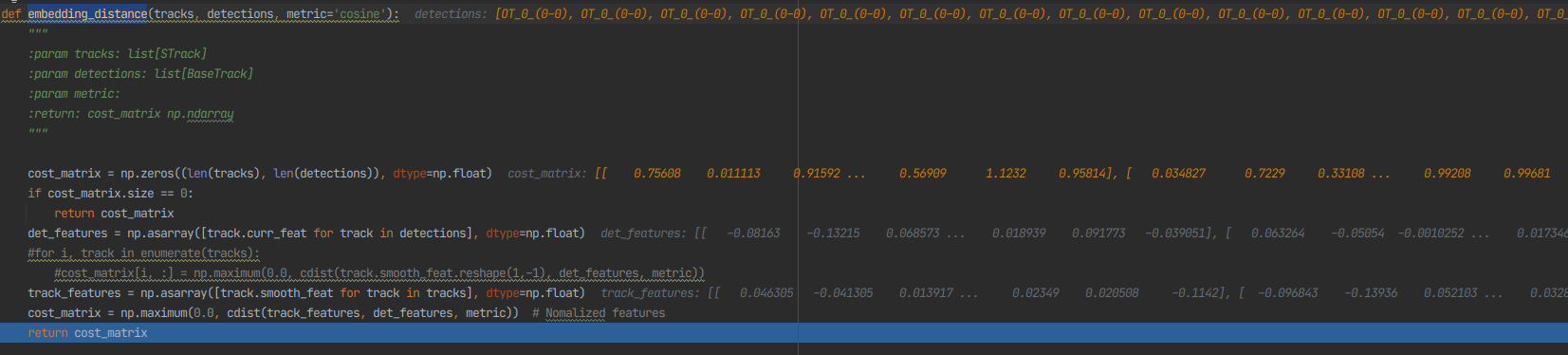
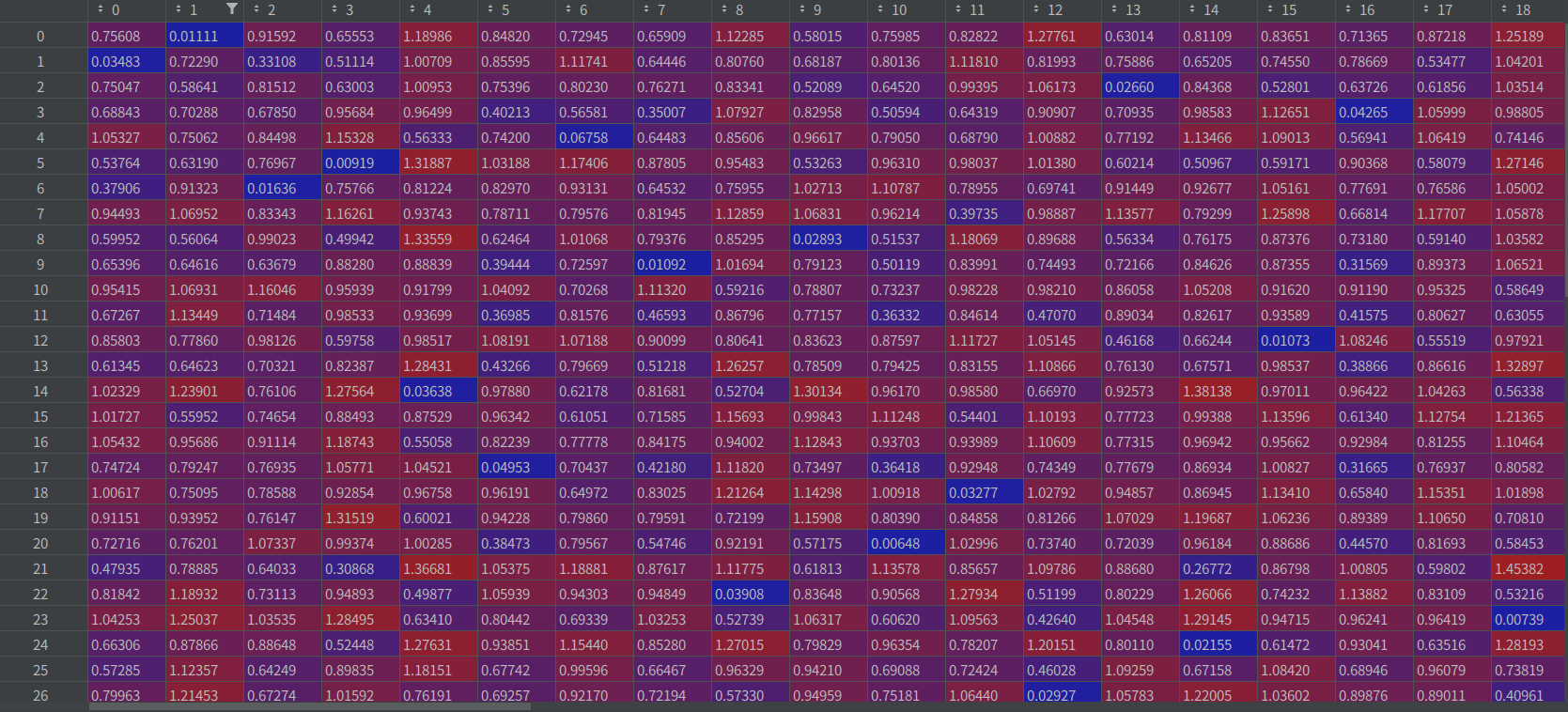
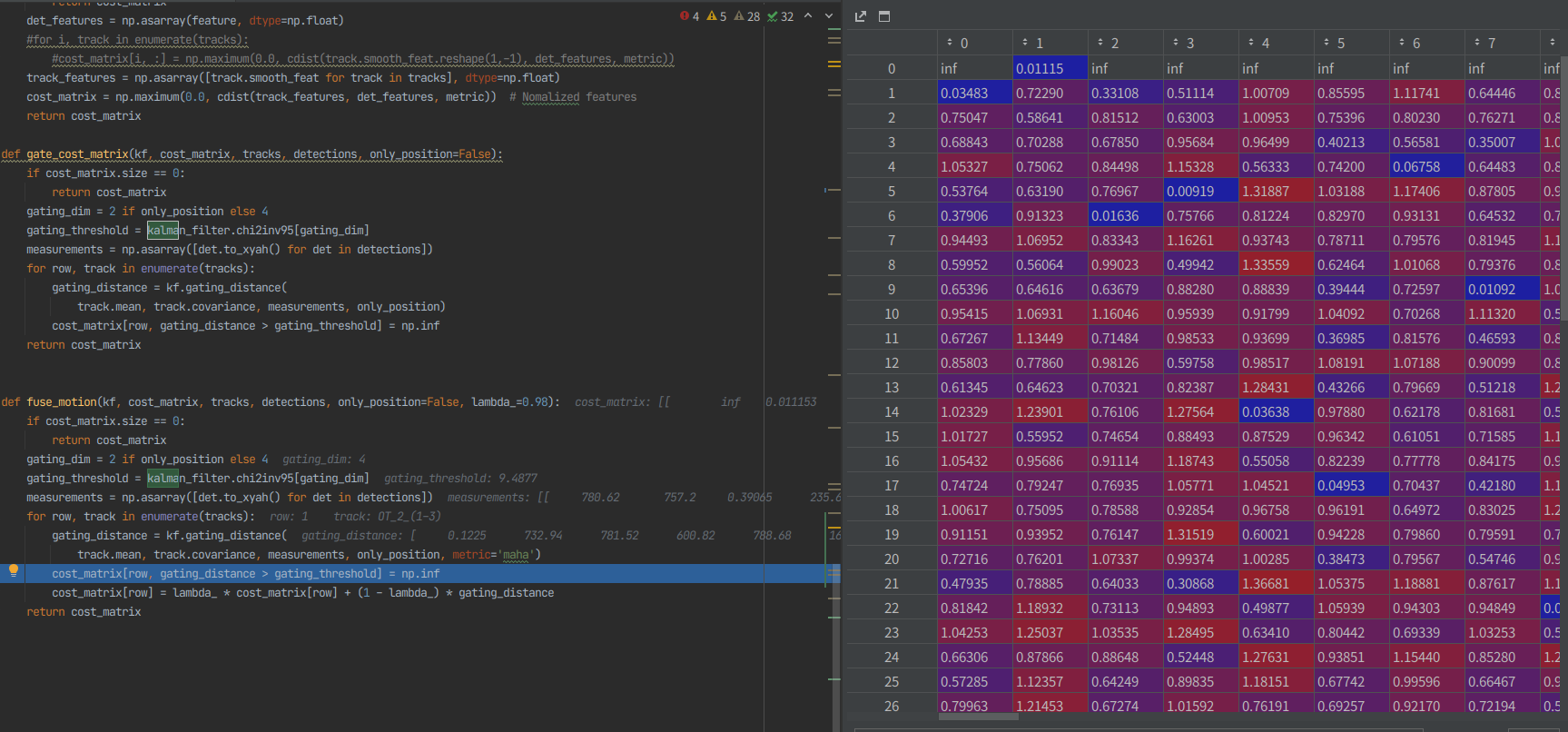
-
-
1. 이전에 나온 track_features와 현 frame의 det_features가지고 cost_matrix를 구현
2. cost_matrix에서 칼만필터를 적용 후에 자기 자신과의 거리가 먼 박스들의 값을 무한대로 보내버림
3. 이후에 새로운 id인지 그 이전 id인지 판단하는 과정을 거침
- FairMOT 설치과정
$ git clone [https://github.com/ifzhang/FairMOT](https://github.com/ifzhang/FairMOT)
$ conda create -n FairMOT python=3.6.9
$ pip3 install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f [https://download.pytorch.org/whl/torch_stable.html](https://download.pytorch.org/whl/torch_stable.html)
$ cd ${FAIRMOT_ROOT}
$ pip install cython
$ pip install -r requirements.txt
$ git clone [https://github.com/jinfagang/DCNv2_latest](https://github.com/jinfagang/DCNv2_latest)
$ cd DCNv2_latest
$ ./make.sh

나머지는 필요한 가중치를 다운받고 터미널이 아닌 파이참에서 돌리려면
Run>Run/Debug Configurations - Parmeters에서 터미널에서 줘야하는 파라미터들을 직접 적어주면 된다. 그렇게 하지 않으려면 paser에 직접 default값을 수정해주면 됨