이미지 유사도를 분석하는 방법
- Feature Matching
- 히스토그램
- MSE(mean square error)
- Autoencoder
1. Feature Matching
두 개의 이미지에서 동일한 특징점을 찾아 매칭해 주는 방법을 사용했습니다. OpenCV에서는 이런 특징점 매칭을 Brute-Force 매칭이라고 하는데... 이는 하나의 이미지에서 발견한 특징점을 다른 또 하나의 이미지의 모든 특징점과 비교해 가장 유사한 것이 동일한 특징점이라고 판별하는... 단순하지만 다소 효율적이지 못한 방식이기 때문입니다. 이미지에서 사용하는 feature들을 그리드 서치마냥 비교하기 때문인 듯... (이것을 사용한 이유는 threshold값으로 비교를 할 수 있기 때문인데 확인결과 결과값이 좋진 않아서 사용하지 못함...)
Brute-Force 매칭을 위한, 즉 BF Matcher는 cv2.BFMatcher 함수를 통해 생성합니다. 이 함수는 2개의 선택적 인자를 받는데, 첫번째는 normType이며 거리 측정 방식을 지정합니다. 기본적으로는 cv2.NORM_L2이며 cv2.NORM_L1과 함께 키포인트와 특징점 기술자를 연산 방식인 SIFT, SURF에 좋습니다. ORB와 BRIEF, BRISK와 같은 2진 문자열 기반의 방식에서는 cv2.NORM_HAMMING가 사용되어져야 합니다. 만약 ORB가 VTA_K == 3 또는 4일 때, cv2.NORMHAMMING2가 사용되어져야 합니다. 두번재 인자는 crossCheck라는 Boolean 타입의 인자입니다. 기본값은 false이며 만약 True로 지정하면 A라는 이미지의 어떤 하나의 특징점을 B라는 이미지의 모든 특징점과 비교하는 것에서 끝나지 않고, 다시 B라는 이미지에서 찾은 가장 유사한 특징점을 A라는 모든 특징점과 비교하여 그 결과가 같은지를 검사하라는 옵션입니다. 보다 정확한 동일 특징점을 추출하고자 한다면 True를 지정하면 됩니다.
일반 BF Matcher 객체가 생성되면 match()와 knnMatch()라는 함수를 사용합니다. 첫번째는 가장 좋은 매칭 결과를 반환하고, 두번째 함수는 사용자가 지정한 k개의 가장 좋은 매칭 결과를 반환합니다. 특징점을 표시하는 cv2.drawKeypoints()와 같이, 2개의 이미지 간의 동일 특징점을 선으로 연결에 표시해 주는 cv2.drawMatches() 함수와 cv2.drawMatchesKnn() 함수가 있습니다.
이제 실제 예제 코드를 살펴 보겠습니다. 첫번째는 ORB 기술자를 사용한 특징점 비교, 두번째는 SIFT 기술자를 사용한 특징점 비교, 끝으로 세번째는 FLANN 방식의 특징점 비교입니다.
먼저 첫번째로 ORB 기술자를 사용한 특징점 비교에 대한 예제입니다.
import numpy as np
import cv2
from matplotlib import pyplot as plt
import glob
import os
img_list = glob.glob('/home/john/PycharmProjects/MOT_test/person_frame/train/*.jpg')
# dir_img_list = glob.glob('/home/john/PycharmProjects/MOT_test/person_frame/*.jpg')
for i in range(len(img_list[:20])):
img1 = cv2.imread(f'{img_list[7]}',0) # queryImage
img2 = cv2.imread(f'{img_list[i]}',0) # trainImage
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
try:
matches = bf.match(des1,des2)
matches = sorted(matches, key = lambda x:x.distance)
img3 = cv2.drawMatches(img1,kp1,img2,kp2,matches[:10],None,flags=2)
plt.imshow(img3),plt.show()
except:
print('유사점이 없누')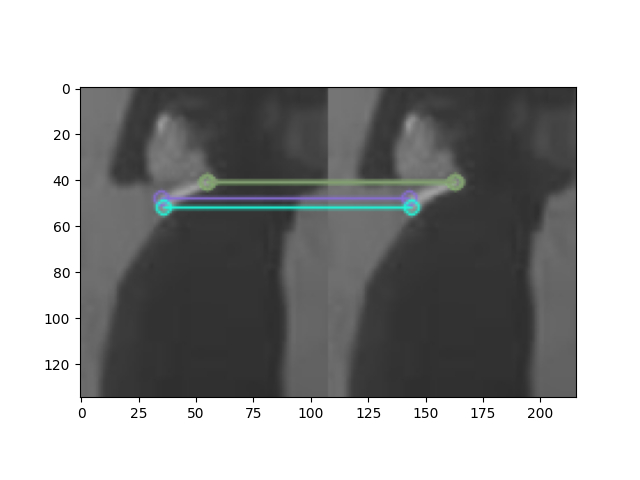
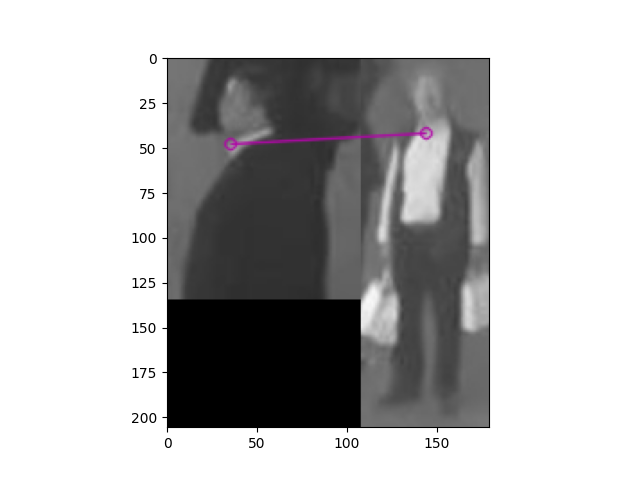
위의 두 그림을 보면서 알 수 있듯이 그림의 유사점 즉 카라티의 흰 부분을 가지고 같은 지점을 찾아냈지만 사물이 아닌 사람을 비교하기에는 역부족(사람자체도 비교하기 힘들지만 옷이 바뀔경우도 생각해야 함)
코드에서 BF Matcher 객체를 생성하고 있는데, ORB를 사용하므로 cv2.NORM_HAMMING를 지정하고 있습니다. 17번에서는 매칭 결과에서 거리에 따로 오름차순으로 정렬하였습니다. 거리값이 작을수록 더 좋은 결과입니다. 코드에서는 이렇게 정렬된 것 중 10개만을 화면에 표시하고 있습니다.
BF Matcher의 match() 함수의 결과는 DMatch 객체의 리스트입니다. 이 객체는 다음과 같은 속성을 갖습니다.
DMatch.distance : 기술자(Descriptor) 간의 거리로써, 작을수록 더 좋은 결과임
DMatch.trainIdx : 연습 기술자 리스트에 저장된 인덱스(위 예제에서 img1에서 추출한 기술자가 연습 기술자임)
DMatch.queryIdx : 조회 기술자 리스트에 저장된 인덱스(위 예제에서 img2에서 추출한 기술자가 조회 기술자임)
DMatch.imgIdx : 연습 이미지의 인덱스
두번째 예제는 SIFT 기술자를 이용한 특징점 비교입니다.
import numpy as np
import cv2
from matplotlib import pyplot as plt
import glob
import os
img_list = glob.glob('/home/john/PycharmProjects/MOT_test/person_frame/train/*.jpg')
# dir_img_list = glob.glob('/home/john/PycharmProjects/MOT_test/person_frame/*.jpg')
for i in range(len(img_list)):
img1 = cv2.imread(f'{img_list[0]}',0) # queryImage
img2 = cv2.imread(f'{img_list[i]}',0) # trainImage
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1,des2, k=2)
good = []
for m,n in matches:
# if m.distance < 0.3*n.distance:
if m.distance < n.distance:
good.append([m])
print('same_good', good)
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2)
plt.imshow(img3),plt.show()
cv2.imshow("comapre", img3)
cv2.waitKey(1)
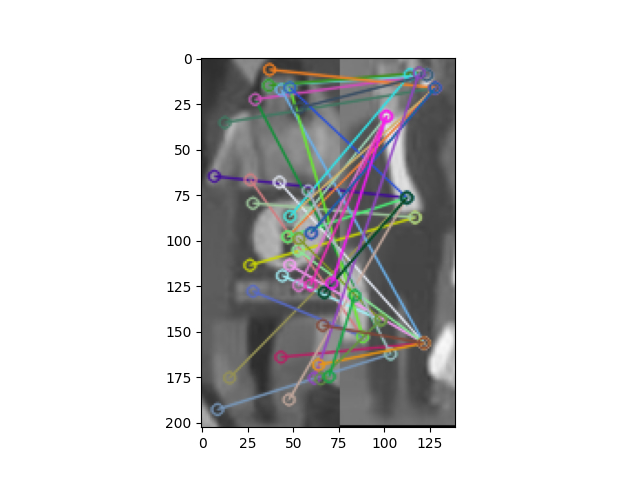
# if m.distance < 0.3*n.distance: if m.distance < n.distance: 이 부분으 코드를 거리 조절을 하면서 저 겹치는 선들을 조절할 수 있다. ( 이미지 벡터상의 거리로 계산하고 있기 때문에 유사도에 대한 정확성이 부족함 사물이면 어느정도 가능하겠지만 사람의 경우 보증하지 못함)
2. 히스토그램
Histogram을 이용한 이미지 유사도 측정:
Evaluating image similarity using histogram
히스토그램 (histogram)을 이용하면 사진들이 서로 얼마나 비슷한지 측정할 수 있다. 히스토그램간의 유사도를 측정하면 된다. OpenCV는 이러한 측정을 위해 함수 compareHist( )를 제공한다. 비교대상인 두 개의 히스토그램을 인자로 전달하면 유사도를 수치로 반환한다. 비교방식은 7가지가 있는데, 주로 사용되는 것은 correlation, chi-square, intersection과 Bhattachayya가 있다.
img_list = glob.glob('/home/john/PycharmProjects/MOT_test/person_frame/train/*.jpg')
img_list = img_list[:10]
imgs = []
for i in range(len(img_list)):
imgs.append(cv2.imread(img_list[i]))
hists = []
for i, img in enumerate(imgs) :
#---① 각 이미지를 HSV로 변환
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
#---② H,S 채널에 대한 히스토그램 계산
hist = cv2.calcHist([hsv], [0,1], None, [180,256], [0,180,0, 256])
#---③ 0~1로 정규화
cv2.normalize(hist, hist, 0, 1, cv2.NORM_MINMAX)
hists.append(hist)
methods = {'CORREL' :cv2.HISTCMP_CORREL, # cv2.HISTCMP_CORREL: 상관관계 (1: 완전 일치, -1: 완전 불일치, 0: 무관계)
'CHISQR':cv2.HISTCMP_CHISQR, # cv2.HISTCMP_CHISQR: 카이제곱 (0: 완전 일치, 무한대: 완전 불일치)
'INTERSECT':cv2.HISTCMP_INTERSECT, # cv2.HISTCMP_INTERSECT: 교차 (1: 완전 일치, 0: 완전 불일치 - 1로 정규화한 경우)
'BHATTACHARYYA':cv2.HISTCMP_BHATTACHARYYA} # cv2.HISTCMP_BHATTACHARYYA 값이 작을수록 유사한 것으로 판단
all_compare = []
for l in range(len(hists)):
query = hists[l]
part_compare = []
for j, (name, flag) in enumerate(methods.items()):
print('%-10s'%name, end='\t')
feat_compare = []
for i, (hist, img) in enumerate(zip(hists, imgs)):
#---④ 각 메서드에 따라 img1과 각 이미지의 히스토그램 비교
ret = cv2.compareHist(query, hist, flag)
if flag == cv2.HISTCMP_INTERSECT: #교차 분석인 경우
ret = ret/np.sum(query) #비교대상으로 나누어 1로 정규화
print("img%d_%d:%7.2f"% (l,i+1 , ret), end='\t')
feat_compare.append(ret)
part_compare.append(feat_compare)
print()
all_compare.append(part_compare)
print(all_compare[0][0])
print(np.array(all_compare).shape)CORREL img0_1: 1.00 img0_2: 0.11 img0_3: 0.41 img0_4: 0.08 img0_5: 0.21 img0_6: 0.18 img0_7: 0.22 img0_8: 0.06 img0_9: 0.33 img0_10: 0.19
CHISQR img0_1: 0.00 img0_2: 105.58 img0_3: 145.11 img0_4: 127.19 img0_5: 683.00 img0_6: 704.54 img0_7: 301.46 img0_8: 456.56 img0_9: 165.95 img0_10: 744.59
INTERSECT img0_1: 1.00 img0_2: 0.11 img0_3: 0.31 img0_4: 0.08 img0_5: 0.22 img0_6: 0.18 img0_7: 0.25 img0_8: 0.07 img0_9: 0.23 img0_10: 0.25
BHATTACHARYYA img0_1: 0.00 img0_2: 0.83 img0_3: 0.66 img0_4: 0.83 img0_5: 0.80 img0_6: 0.81 img0_7: 0.73 img0_8: 0.88 img0_9: 0.68 img0_10: 0.77
CORREL img1_1: 0.11 img1_2: 1.00 img1_3: 0.02 img1_4: 0.03 img1_5: -0.00 img1_6: -0.00 img1_7: 0.33 img1_8: 0.14 img1_9: 0.10 img1_10: 0.13
CHISQR img1_1: 79.45 img1_2: 0.00 img1_3: 75.60 img1_4: 348.06 img1_5: 21.52 img1_6: 24.09 img1_7: 326.27 img1_8: 452.71 img1_9: 504.69 img1_10:1013.10
INTERSECT img1_1: 0.30 img1_2: 1.00 img1_3: 0.06 img1_4: 0.08 img1_5: 0.00 img1_6: 0.00 img1_7: 0.30 img1_8: 0.21 img1_9: 0.15 img1_10: 0.28
BHATTACHARYYA img1_1: 0.83 img1_2: 0.00 img1_3: 0.95 img1_4: 0.90 img1_5: 1.00 img1_6: 1.00 img1_7: 0.81 img1_8: 0.77 img1_9: 0.89 img1_10: 0.83
CORREL img2_1: 0.41 img2_2: 0.02 img2_3: 1.00 img2_4: 0.16 img2_5: 0.12 img2_6: 0.14 img2_7: 0.15 img2_8: 0.02 img2_9: 0.29 img2_10: 0.20
CHISQR img2_1: 78.21 img2_2: 146.71 img2_3: 0.00 img2_4: 101.46 img2_5: 469.38 img2_6: 641.18 img2_7: 837.70 img2_8: 588.50 img2_9: 84.34 img2_10: 132.22
INTERSECT img2_1: 0.44 img2_2: 0.03 img2_3: 1.00 img2_4: 0.10 img2_5: 0.19 img2_6: 0.21 img2_7: 0.18 img2_8: 0.05 img2_9: 0.28 img2_10: 0.24
BHATTACHARYYA img2_1: 0.66 img2_2: 0.95 img2_3: 0.00 img2_4: 0.80 img2_5: 0.86 img2_6: 0.82 img2_7: 0.82 img2_8: 0.92 img2_9: 0.69 img2_10: 0.82
CORREL img3_1: 0.08 img3_2: 0.03 img3_3: 0.16 img3_4: 1.00 img3_5: 0.03 img3_6: 0.03
[1.0, 0.11254707740358484, 0.41059503682238463, 0.08169912344136684, 0.2125769928896957, 0.18249743328962928, 0.22241949544186934, 0.05880447747060161, 0.32704140432116596, 0.19288010608979267]
(10, 4, 10)
3. MSE
각각의 피쳐들의 거리의 오차를 구해서 일정 값 이하는 같은 이미지로 판단하는것
(cosine similarity와 비슷하지 않나...)
4. Auto encoder
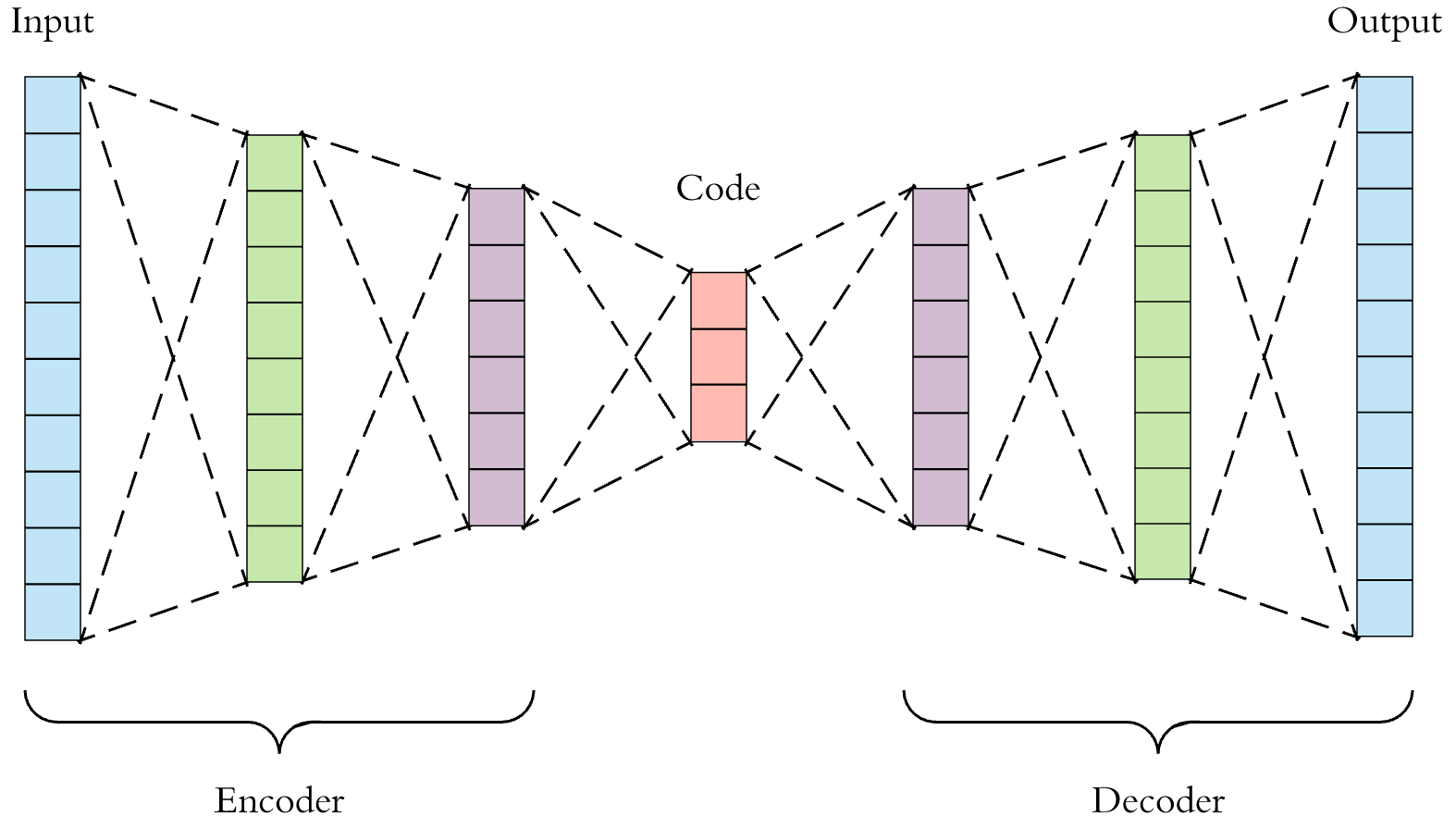
위 그림에서 encoder를 거친 latency vector를 이용할 예정이다. latency vector의 차원을 조정해서 적당히 잘 훈련된 값들에서 각각의 vector들을 cosine similarity로 비교하는 과정을 거칠 예정 밑의 코드는 간단하게 mnist로 잘 되는지 확인하기 위해서 작성하고 확인함. mnist에서는 잘 되나 실제 사람 이미지로도 잘 되는지는 확인해야 함.
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.init as init
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import logging
import sys
flag = 0 # if 1 train 0 test
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
logger.addHandler(logging.StreamHandler(sys.stdout))
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
mnist_train = dset.MNIST("./", train=True, transform=transforms.ToTensor(), target_transform=None, download=True)
mnist_test = dset.MNIST("./", train=False, transform=transforms.ToTensor(), target_transform=None, download=True)
class Encoder(nn.Module):
def __init__(self, latency_num):
super(Encoder, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, 3, padding=1), # batch x 16 x 28 x 28
nn.ReLU(),
nn.BatchNorm2d(16),
nn.Conv2d(16, 32, 3, padding=1), # batch x 32 x 28 x 28
nn.ReLU(),
nn.BatchNorm2d(32),
nn.Conv2d(32, 64, 3, padding=1), # batch x 64 x 28 x 28
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(2, 2) # batch x 64 x 14 x 14
)
self.layer2 = nn.Sequential(
nn.Conv2d(64, 128, 3, padding=1), # batch x 128 x 14 x 14
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, 3, padding=1), # batch x 256 x 7 x 7
nn.ReLU()
)
self.fc1 = nn.Linear(256 * 7 * 7, latency_num)
self.hidden2mu = nn.Linear(1024,1024)
self.hidden2log_var = nn.Linear(1024,1024)
self.relu = nn.ReLU()
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(batch_size, -1)
out = self.fc1(out)
# mu = self.hidden2mu(out)
# mu = self.relu(mu)
# log_var = self.hidden2log_var(out)
# log_var = self.relu(log_var)
#
# std = torch.exp(0.5*log_var)
# eps = torch.randn_like(std)
#out = mu + eps*std
return out
class Decoder(nn.Module):
def __init__(self,latency_num):
super(Decoder, self).__init__()
self.layer1 = nn.Sequential(
nn.ConvTranspose2d(256, 128, 3, 2, 1, 1), # batch x 128 x 14 x 14
nn.ReLU(),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 64, 3, 1, 1), # batch x 64 x 14 x 14
nn.ReLU(),
nn.BatchNorm2d(64)
)
self.layer2 = nn.Sequential(
nn.ConvTranspose2d(64, 16, 3, 1, 1), # batch x 16 x 14 x 14
nn.ReLU(),
nn.BatchNorm2d(16),
nn.ConvTranspose2d(16, 1, 3, 2, 1, 1), # batch x 1 x 28 x 28
nn.ReLU()
)
self.fc1 = nn.Linear(latency_num, 256 * 7 * 7)
def forward(self, x):
out = self.fc1(x)
out = out.view(batch_size, 256, 7, 7)
out = self.layer1(out)
out = self.layer2(out)
return out
def cosin_metric(x1, x2):
return np.dot(x1, x2) / (np.linalg.norm(x1) * np.linalg.norm(x2))
def loss_function(recon_x, x, mu, logvar):
BCE = nn.functional.binary_cross_entropy(recon_x, x)
# see Appendix B from VAE paper:
# Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014
# https://arxiv.org/abs/1312.6114
# 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
#kl_loss = - 0.5 * K.mean(1 + z_log_sigma - K.square(z_mean) - K.exp(z_log_sigma), axis=-1)
return BCE + KLD
def discrete_cmap(N, base_cmap=None):
"""Create an N-bin discrete colormap from the specified input map"""
# Note that if base_cmap is a string or None, you can simply do
# return plt.cm.get_cmap(base_cmap, N)
# The following works for string, None, or a colormap instance:
base = plt.cm.get_cmap(base_cmap)
color_list = base(np.linspace(0, 1, N))
cmap_name = base.name + str(N)
return base.from_list(cmap_name, color_list, N)
if __name__ == "__main__":
avg_list = []
min_list=[]
max_list = []
var_list=[]
for latency_num in range(2,20):
learning_rate = 0.0002
num_epoch = 5
batch_size = 256
train_loader = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=2,
drop_last=True)
# loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, num_workers=0)
test_loader = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=2,
drop_last=True)
encoder = Encoder(latency_num=latency_num).to(device)
decoder = Decoder(latency_num=latency_num).to(device)
#train
if flag==1:
# 인코더 디코더의 파라미터를 동시에 학습시키기 위해
parameters = list(encoder.parameters()) + list(decoder.parameters())
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(parameters, lr=learning_rate)
for epoch in range(num_epoch):
train_loss = 0
for batch_idx, [image, label] in enumerate(train_loader):
optimizer.zero_grad()
image = image.to(device)
output= encoder(image)
output = decoder(output)
loss = loss_func(output, image)
loss.backward()
train_loss += loss.item()
optimizer.step()
if batch_idx % 10 == 0:
logger.info('Train Epoch: {}/{} [{}/{} ({:.0f}%)] Loss: {:.6f}'.format(
epoch,num_epoch, batch_idx * len(image), len(train_loader.sampler),
100. * batch_idx / len(train_loader), loss.item()))
print('====> Epoch: {} Average loss: {:.4f}'.format(
epoch, train_loss / len(train_loader.dataset)))
# out_img = torch.squeeze(output.cpu().data)
# print(out_img.size())
# plt.subplot(1, 2, 1)
# plt.imshow(torch.squeeze(image[0]).cpu().numpy(), cmap='gray')
# plt.subplot(1, 2, 2)
# plt.imshow(out_img[0].numpy(), cmap='gray')
# plt.show()
torch.save(encoder.cpu().state_dict(), f'./encoder_model/{latency_num}_encoder.pt')
torch.save(decoder.cpu().state_dict(), f'./encoder_model/{latency_num}_decoder.pt')
# train 결과 체크
# test
if flag==0 :
tt = []
all = []
encoder.load_state_dict(torch.load(f'./encoder_model/{latency_num}_encoder.pt'))
decoder.load_state_dict(torch.load(f'./encoder_model/{latency_num}_decoder.pt'))
encoder.eval()
decoder.eval()
with torch.no_grad():
for j, [image, label] in enumerate(test_loader):
image = image.to(device)
outputs = encoder(image)
output = decoder(outputs)
out_img = torch.squeeze(output.cpu().data)
# plt.subplot(1, 2, 1)
# plt.imshow(torch.squeeze(image[0]).cpu().numpy(), cmap='gray')
# plt.subplot(1, 2, 2)
# plt.imshow(out_img[0].numpy(), cmap='gray')
# plt.show()
N = 10
plt.figure(figsize=(6, 6))
plt.scatter(outputs[:, 0].cpu().numpy(), outputs[:, 1].cpu().numpy(), c=label, marker='o',
edgecolor='none', cmap=discrete_cmap(N, 'jet'))
plt.colorbar(ticks=range(N))
plt.show()
for idx, la in enumerate(label) :
if la == 1:
latent_ = outputs[idx].view(-1).cpu().numpy()
tt.append(latent_)
else :
latent_s = outputs[idx].view(-1).cpu().numpy()
all.append(latent_s)
tot = []
for tt_idx in range(len(tt)-1):
temp = cosin_metric(tt[0],tt[tt_idx+1])
tot.append(temp)
print(temp)
print("avg = ",sum(tot, 0.0)/len(tot))
print("min = ",min(tot))
print("max = ",max(tot))
print("total = ",len(tot))
avg_list.append(sum(tot, 0.0)/len(tot))
min_list.append(min(tot))
max_list.append(max(tot))
var_list.append(np.var(tot))
print(avg_list.index(max(avg_list)))
print(avg_list.index(min(avg_list)))
print(min_list.index(min(avg_list)))
print(max_list.index(max(avg_list)))
print(var_list.index(max(avg_list)))
# with open('./latent_v', 'wb') as f:
# f.write(tt)
