
중간 발표

중간 발표 D-day! 오전에 시스템 아키텍처를 한 번 더 수정하고, 오후에 각 팀별 중간 발표를 들었다. 다른 팀의 현재 진행 상황도 보고, 심사위원 분들의 피드백도 들을 수 있었던 귀한 시간이었다.

탄탄한 우리 팀 발표 목차 👍🏼✨

동욱 오빠 로봇 캐릭터만 고퀄이라서 너무 웃김
범석 오빠 캐릭터는 노진구 같아 킥킥
수민 동체 시력 사건: 앞에서 다른 팀원이 피피티 슉슉 넘기다가 팀 소개 페이지에 오타가 있는 걸 순간 포착한 사건이다.. 짱이죠? 😉
주제 선정 배경.. 현재 우리 팀의 어리바리 막내인 나는 너무 공감이 간다... 🥲 모르는 게 잘못은 아니지만, 팀원들에게 계속 물어보면 너무 미안하고.. 스스로에게 아쉬운 마음만 들어요 ㅠㅠ

'navigator'의 앞 네 글자를 따 'NAVI'라는 이름을 가지게 된 우리의 프로젝트 🦋 사내 임직원이 일일이 문서를 찾아봐도 되지 않게 업무를 지원해 주는 챗봇을 만드는 것이 우리의 목표이다!

기술 스택! 나의 업무는 RAG 기반 챗봇 모델 구현과 관리자 화면 구현이라, 주로 DB와 Frontend 쪽 기술 스택을 많이 사용한다.
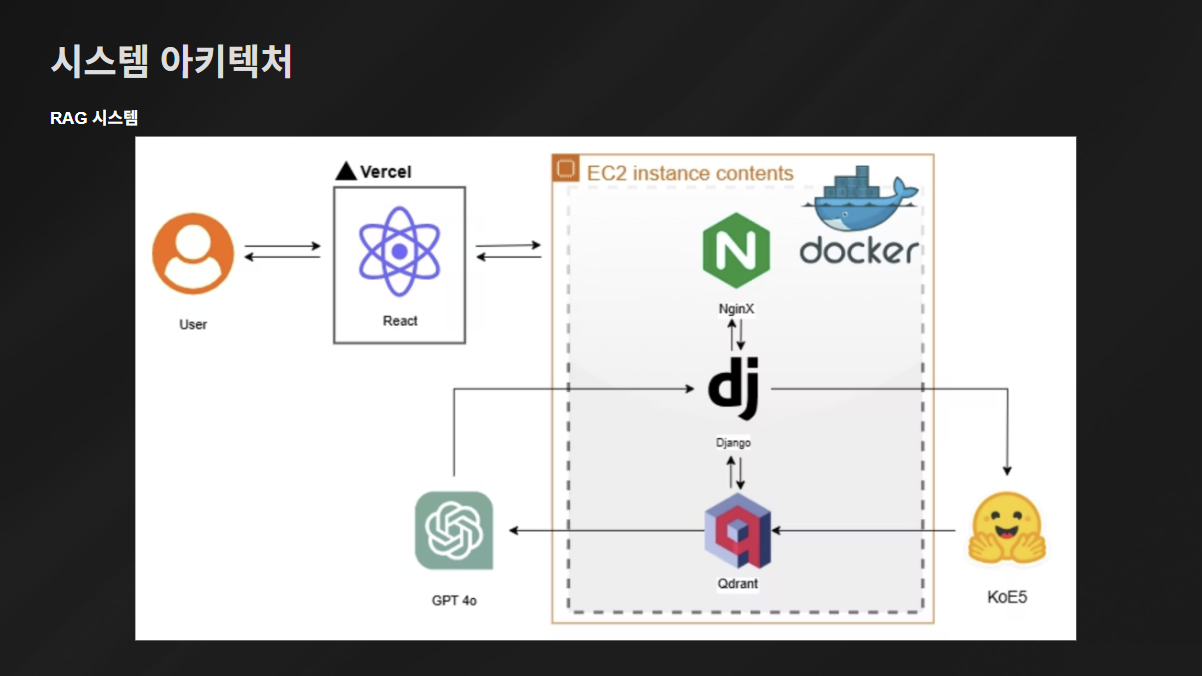
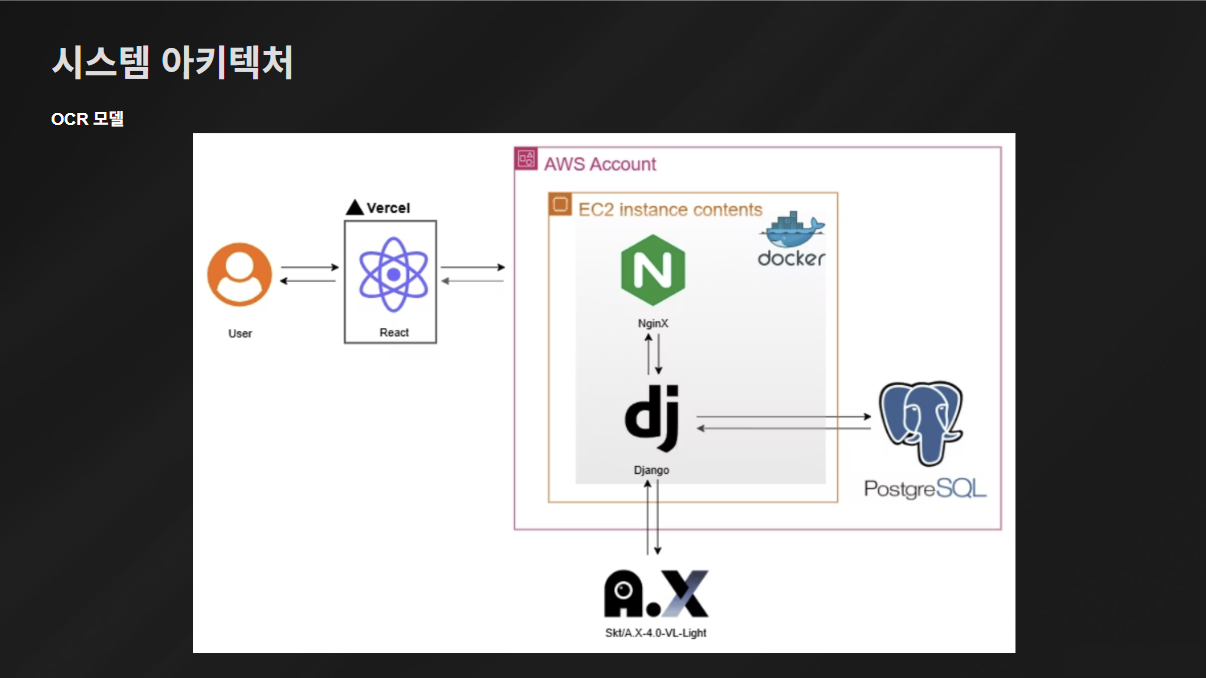
시.아.텍 ✨ 오전에 한 번 더 수정했다 ㅋㅋㅋㅋㅠㅠ GPT나 A.X같은 모델들을 AWS 외부로 뺐다!


데이터 수집 및 전처리 방식 소개! 발표자료 내가 적었다 😉👍🏼
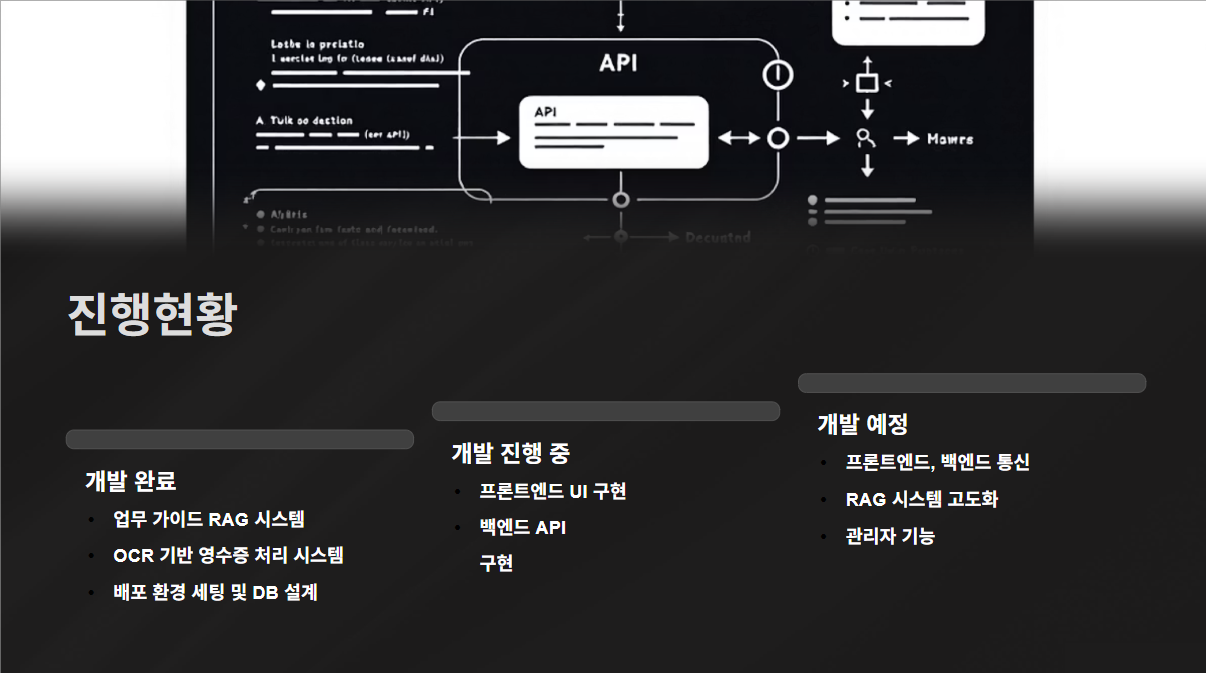
진행 현황! 해온 것들과 앞으로 할 것들을 소개했다!


이슈 및 트러블 슈팅 1: RAG 시스템 최적화
저걸 하면서 메타데이터를 열심히 수정했던 기억이 나네요...
결국 카테고리를 사용한 필터링을 제거하고 전체 문서에서 유사도 검색을 수행하는 걸로 갔지만, 차후에 카테고리를 더 세분화 해서 성능을 더 개선시켜볼 계획이다!
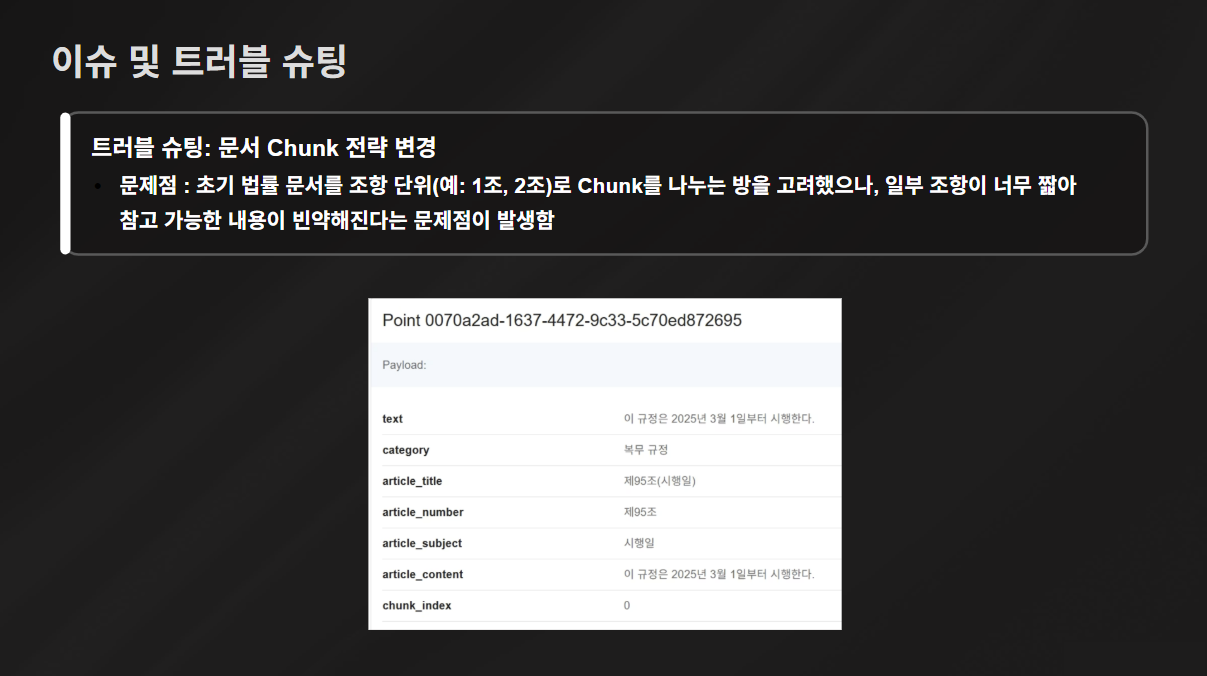
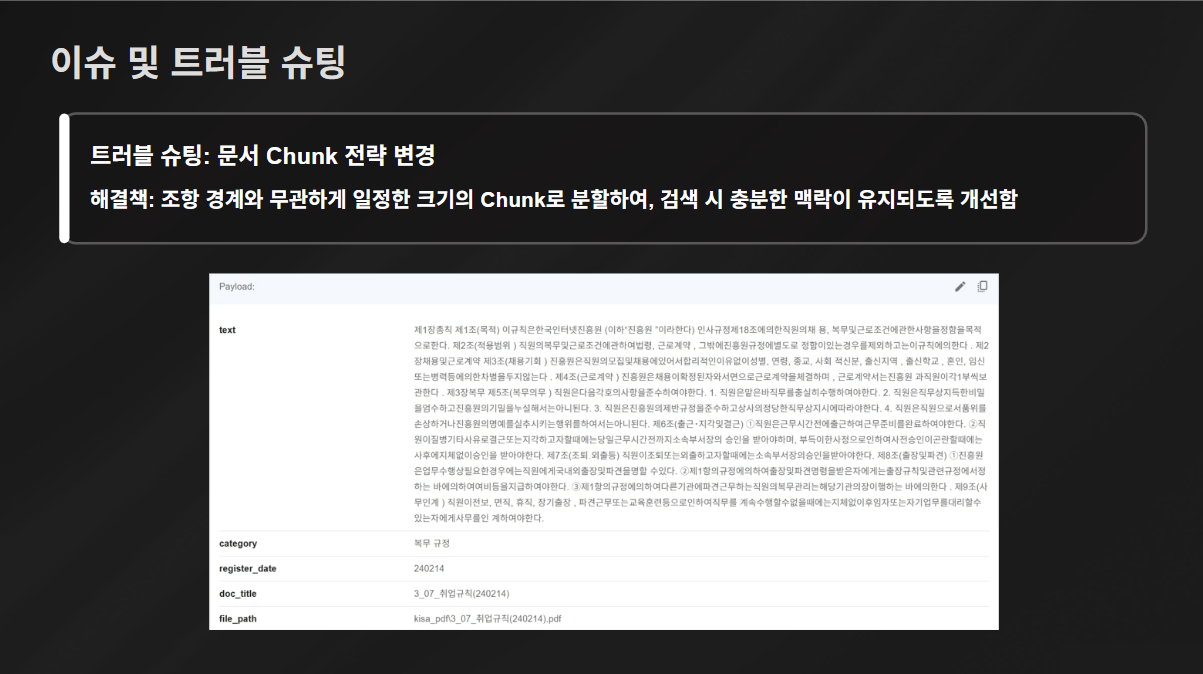
이슈 및 트러블 슈팅 2: 문서 Chunk 전략 변경
원래 나는 강경 '청크를 조항 단위로 나눠야 한다' 주의였으나, 일부 조항이 너무 짧아 참고 가능한 내용이 빈약해진다는 것을 확인했다.
내가 문서를 찾는다면 당연히 조항 단위로 찾는 게 효율적이겠다만, 컴퓨터가 일하는 방식은 나와 달라야 할 수도 있겠구나 깨달았다.
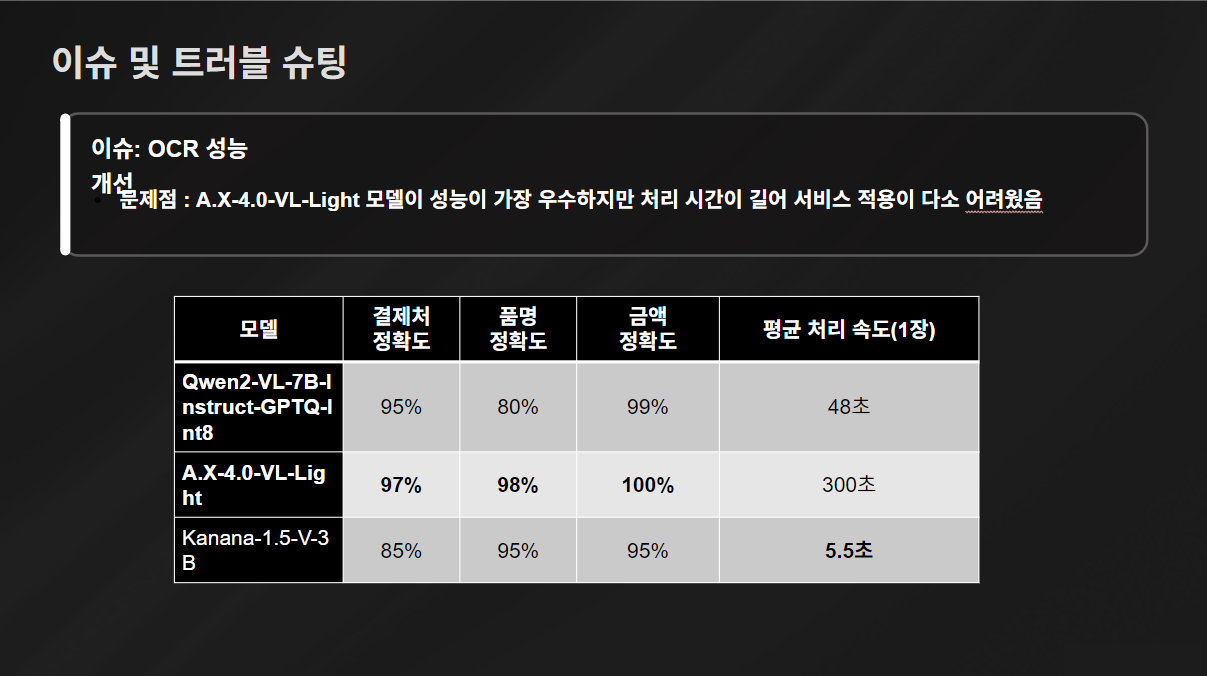
이슈 및 트러블 슈팅 3: OCR 모델 성능 개선
A.X-4.0-VL-Light 모델이 정확도 면에서 성능이 가장 우수하지만, 데이터 처리 속도가 너무 느려 서비스에 적용 시키기는 어렵다고 판단했다.

근데 A.X가 성능이 확실히 뛰어남..
위에 보면 Qwen 모델은 '딱새우사시미'를 '막새우사시미'라고 읽었고, Kanana 모델은 카드 번호를 잘못 읽었다... 그에 비해 A.X 모델은 뛰어난 성능을 자랑했다.
그럼 데이터 처리 시간을 줄일 수 있는 방법이 없을까? 이걸 형우 오빠가 해냄 🫢
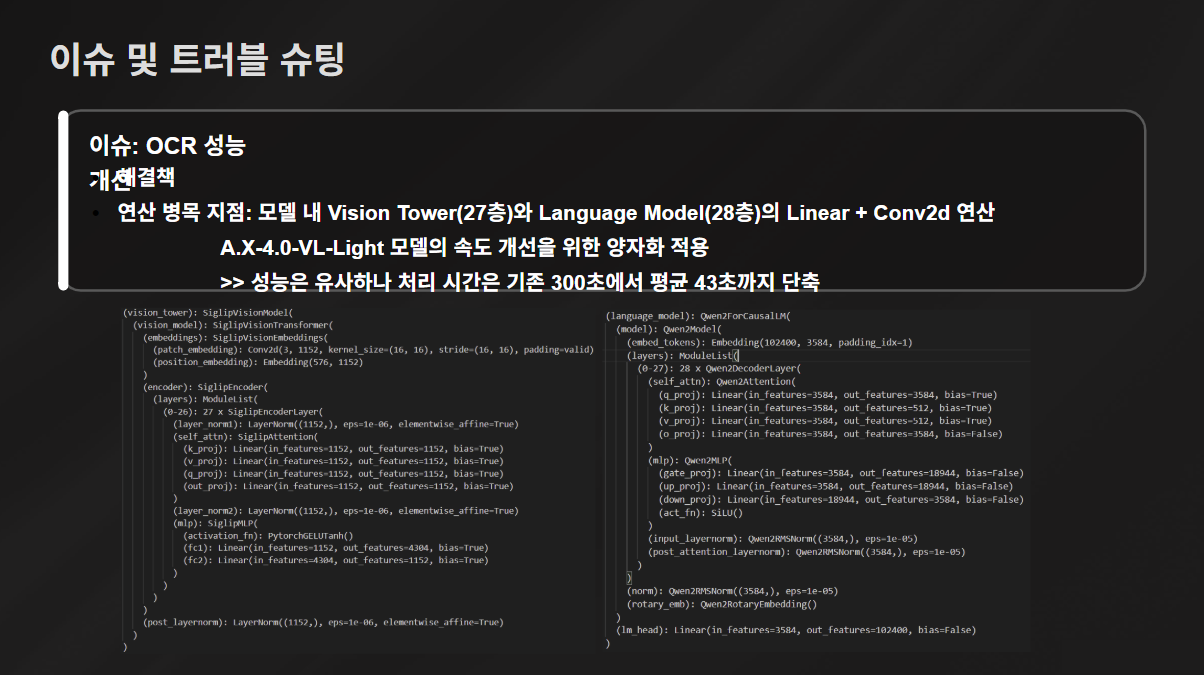
모델 끝부분 양자화를 통해 처리 시간을 300초에서 43초까지 줄였다네요.. ✨ 대단하다~!~!

시연 영상! 챗봇 화면 구현한 걸 보여주었다.

향후 목표~ 앞으로 남은 4주도 힘내봅시다 😉

발표는 끝!
발표 피드백
1. 데이터셋 및 접근 제어
-
부서별 데이터셋 분리
- 각 부서별로 별도의 데이터셋 구성 필요
-
권한 구분
- C-level 임원 전용 문서와 일반 직원 문서를 구분
- 일반 직원은 권한이 없는 문서에 접근할 수 없도록 설계
2. 모델 및 비용 고려
- GPT-5 활용 가능성
- 현재 GPT-5가 더 저렴하므로 활용 고려
3. 임베딩 및 전처리 전략
-
청크 전략 개선
- 단순 청크 사이즈 기준 분할과 특정 용어(예: 장, 조, 특수 기호) 기준 분할, 두 가지를 합치는 방안도 고려
-
전처리 시 표 처리
- 현재 목차·표·이미지 데이터는 제외했으나, 추후 포함 예정
-
OCR 모델 선택 이유
- A.X 모델 채택 사유: 기업 환경에서는 정확도가 가장 중요
- 영수증 처리 사례: 업스테이지 OCR 모델 참고 가능
- Key Expression(키-값 쌍 추출) 기술도 검토
4. 출력 포맷 및 UX
-
Stream 출력 유지
- 답변 출력 시 스트리밍 방식 유지
-
마크다운 처리 적용
- 볼드체(
**) 문제 해결 가능 - 표 출력 지원 가능
- 볼드체(
5. 참고 기술 자료
업스테이지 (Upstage)
- B2B AI 전문기업, OCR + LLM(‘SOLAR’) 결합한 풀스택 솔루션 제공
- 보험·영수증 처리에서 95% 이상 인식률 달성 (삼성생명 적용 사례)
- 다양한 문서 처리 API 제공
Key Expression
- Key-Value Pair Extraction과 유사 개념
- OCR 결과에서 특정 키(예: "청구번호")와 대응 값(예: "12345")을 추출하여 구조화
- 문서 자동화·정보 검색 효율 향상
