
냠냠냠🧑🍳 다들 식당 많이 예약해서 가시나요?
데브코스를 들으면서 진행했던 팀 활동에서 캐치테이블을 클론하는 프로젝트를 진행한 적이 있었는데요, 이때 시간도 좀 많이 적었고, 다같이 컨벤션을 맞추어 가면서 협업을 해본 경험이 다들 처음이었어서, 특히 개발이 좀 오래 걸렸었습니다.
그래서 딱 식당에 예약을 생성하는 단순한 로직만 개발되고 종료되었습니다. 그게 되게 아쉬움으로 많이 남았어서 이번에 리팩토링을 해보자! 라고 생각하고 시작하게 되었습니다.
이번에 적어볼 이야기는 예약의 동시성 문제를 해결하기 위해 시도했던 여러 이야기를 한번 해볼까 합니다!
그럼 시작해볼게요!
인기있는 식당은 예약이 분명 몰릴거야 🖋️
요즘 오마카세, 파인다이닝 등등 인기있는 식당들은 예약 오픈과 동시에 예약이 마감되는 곳들이 많은데, 이러한 상황을 가정해서 우선 테스트를 해보기로 했습니다.
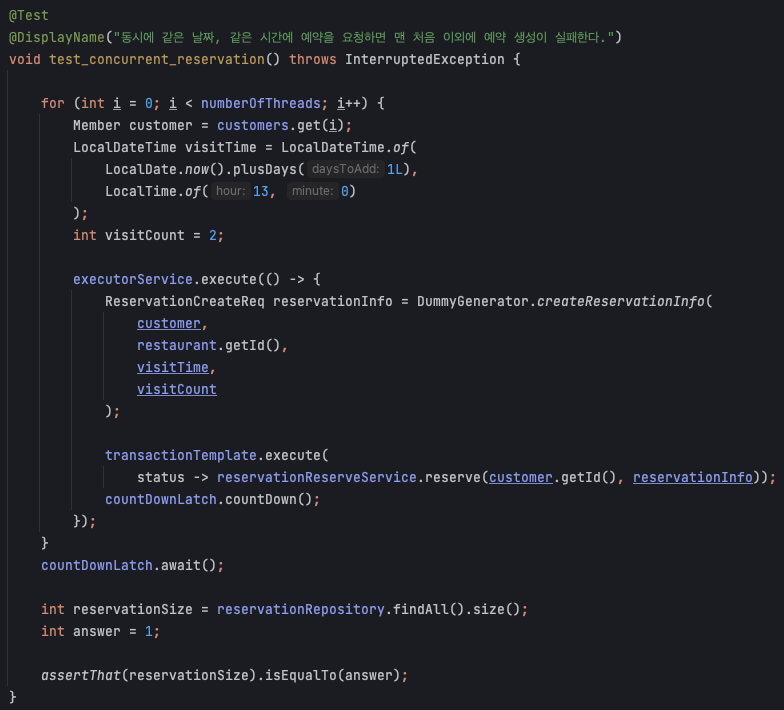
현재 가정한 상황은 레스토랑 A의 한 시간대에 총 가용 인원수가 2명이며, 2명씩 2개의 예약, 즉 총 4명이 예약을 동시에 신청하는 상황입니다.
따라서, 가장 처음에 요청된 예약만 성공하고, 그 뒤에 요청된 예약은 실패해서 예외가 발생하는 것이 정상적인 상황이죠.
결과는??
역시나 예상대로 총 2개의 예약이 모두 성공하여 생성되는 것을 확인했습니다. (해결하기 전에 실패한 이미지를 남겨놓는 걸 까먹었네요...🤨)
자, 그러면 이제 동시 요청 문제를 해결해보도록 하겠습니다 !

동시성? DB 락 쓰면 되는거 아니야? 🤨
처음에는 이전에 좋아요 동시성을 해결해보면서 얻었던 지식들을 바탕으로 아, 이번에는 진짜 DB 락 쓰면 딱이다! 라고 생각하고 바아로 적용해보았습니다.
특정 레스토랑에 예약을 생성하는 것이니까.. 예약을 위해 조회할 때 락을 걸면 되겠다! 라고 생각하고 적용한 뒤 테스트를 돌렸는데.....
결과는?
예약이 모두 다 성공했다? 
어라라? 분명히 Lock을 걸었는데, 왜 예약이 모두 성공하는거지?? 🤨
왜 제대로 락이 작동하지 않는 것일까 생각해봤는데, 현재 레스토랑 데이터에 Lock이 걸리는 것이지, 정작 예약 데이터에 Lock이 걸리는 것이 아니기 때문에 예약이 가득 차도 계속 업데이트 된 데이터를 읽어오지 않아 동시성 문제가 발생한 것이었습니다.
예약 가능 여부를 가지는 테이블을 분리하자.
현재는 예약 데이터를 계속 조건에 맞게 찾아와서 모두 카운트하고 예약 가능 여부를 판단하는 방식으로 구현했는데, 예약 도메인과 식당 도메인의 순환 참조 문제 등 너무 강하게 결합되어 있어 이를 분리하고자 했습니다.
예약 도메인에서도, 식당 도메인에서도 모두 예약 가능 여부를 가져오는 기능이 필요했기 때문에 순환 참조가 발생할 수 밖에 없었던 것이죠.
그래서 중간 테이블인 예약 현황 테이블을 두고 특정 날짜, 시간에 예약 가능한지, 총 몇 명이 예약할 수 있는지를 가지는 BookingSchedule이라는 테이블을 두기로 결정했습니다.
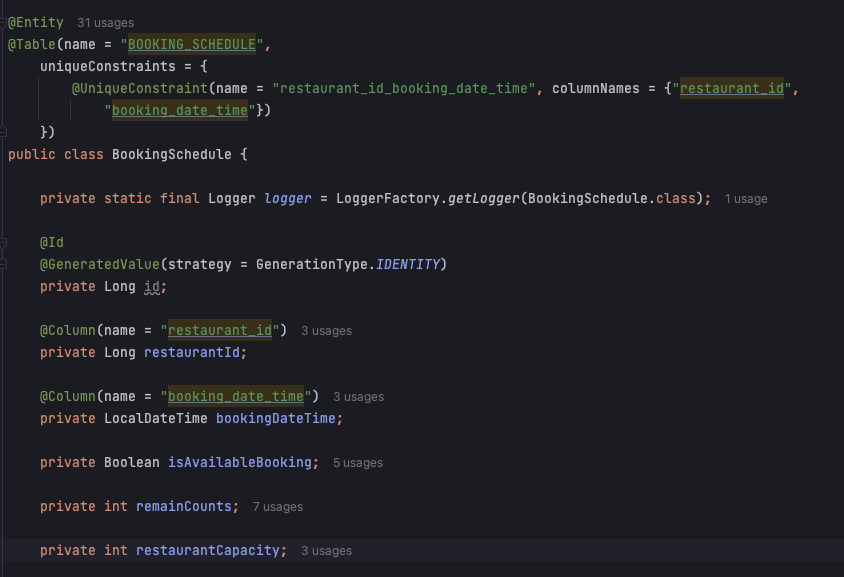
어떤 레스토랑의, 어떤 날짜, 시간에 예약이 가능한지, 몇 자리가 남아있는지를 가지고 있고, 사용자가 지정한 날짜 및 시간에 예약 가능한 여부 조회 시 해당 테이블의 로우만 찾아올 수 있도록 하여 성능을 높이고자 하는 것이 목표였습니다.
그리고 이것과 더불어 식당 도메인과 예약 도메인 사이에 인터페이스 참조와 DTO 사용으로 의존관계를 더욱 가볍게, 응집도가 높도록 변경해 주었습니다. ( 이 이야기도 흥미로우니 작성해보도록 하겠습니다! )
특정 날짜와 시간에 대한 데이터를 언제 생성해주어야 할까?
중간 테이블을 만든 후에 하기 시작한 고민은 이것이었어요. 특정 날짜와 시간에 대한 예약 여부 데이터를 언제 생성해줘야 할까?
미리 정해진 범위의 날짜와 운영 시간에 맞추어 데이터를 넣어놔야 할지, 아니면 그 날짜의 그 시간에 예약이 생성될 때 데이터를 생성해야 할 지 고민이었습니다.
미리 생성할 경우 모든 식당에 대해 데이터가 의미 없이 많이 쌓일 것 같고, 그 날짜의 그 시간에 예약이 최초로 생성될 때 데이터를 생성하기에는 동시 생성 문제가 발생하기 때문에 선택의 갈래에서 고민을 계속 이어나갔습니다. 🤔
좋아! 결정했어 !! 😎
미리 데이터를 생성해주기에는 요구사항과 맞지 않기도 하고 쓸데없는 데이터가 계속해서 쌓이는 것 같아, 동시 생성 문제를 해결해보기로 결정했습니다!!
그래서! 예약 현황 데이터는 그 날짜, 시간에 예약이 발생하면 생성해주기로 한 것!
만약 그 날짜, 시간에 데이터가 없다면 예약이 없는 것이니 가능한 것이라고 간단하게 판단하기로 하고 넘어갔습니다.
이때 발생하는 동시 생성 문제는 동일한 날짜와 시간에 대해 로우 생성 요청을 보내면 동일한 데이터가 생성되어버리는 문제였습니다.
위의 이미지에서 복합 유니크 컬럼을 사용한 것을 볼 수 있는데, 바로 저것이 동시 생성을 해결하기 위해 사용한 것이죠.
자, 사실 이제 여기서 문제가 시작됩니다. 복합 유니크 컬럼을 사용하여 동시 생성은 막았지만, 이를 어플리케이션에서 처리해주면서 문제를 만나게 되었습니다.
저는 단순히 이 예외가 발생하면 이것을 catch한 후, 이미 로우가 존재하니까 그럼 찾아와서 판단해 라고 하면 깔끔하게 처리될 것이라고 예상했었습니다.
하지만 예상과 다르게, 예외는 잘 catch 했지만 이후에 설정한 비즈니스 로직이 잘 수행되지 않았죠..
문제 1. org.hibernate.AssertionFailure: null id
유니크 제약 조건에 의한 DataIntegrityViolationException이 잘 발생하고 이를 잘 잡긴 했지만, DB에서 이를 찾아오는 순간 해당 오류가 발생하면서 터져버렸습니다.
도대체 이 오류는 무엇인지 찾아봤더니, 데이터를 생성하여 저장하는 과정에서 요청이 실패된 후 동일한 데이터를 찾아오는 과정에서 발생하는 오류라고 합니다.
분명 DB에는 잘 저장이 되었기 때문에 해당 에러가 발생한 것이고, 이제 잘 찾아와야 하는거 아닌가? 라고 생각하고 이것저것 찾아봤는데, 두 가지 이유가 있었어요.
영속성 컨텍스트
코드를 사용하면서 설명을 해보자면,
@Service
@Transactional(readOnly=true)
public BookingScheduleService {
@Transactional
public BookingSchedule generateSchdule(LocalDateTime visitDateTime){
try {
return bookingScheduleRepository.save(newSchedule);
} catch (DataIntegrityViolationException exception){
return this.findSchedule(visitDateTime); // 생성하다가 오류 발생하면 DB에서 찾아오기
}
}
public BookingSchdule findSchedule(LocalDateTime visitDateTime){
return bookingSchduleRepository.findScheduleByDateTime(visitDateTime).get();
}
위와 같이 코드를 작성했었는데, 주석에도 적어놓은 것처럼 생성 오류가 발생하면 찾아오는 순서를 만들었습니다. 하지만 이것의 결과는 위에서 말한 에러가 발생하는 것....
이것은 JPA의 영속성 컨텍스트에 의한 것인데, 위에서 살펴보면 save 메소드를 호출하는 순간 newSchedule 객체는 영속성 컨텍스트에 영속화됩니다. 그리고 엔티티의 ID 전략이 Identity 이기 때문에 아마 insert 쿼리가 바로 DB로 전송되어 실행될 것이죠.
하지만 실행해보니 에러가 발생하여 DB에는 저장이 안되어서 돌아오게 되는데, 여기서 중요합니다 !! ⭐️
앞서 이 트랜잭션은 DB에 데이터가 없다고 판단하였기 때문에 생성 요청을 하였고, 그 생성 요청은 제대로 처리되지 않았어요. 이 트랜잭션, 이 스레드는 newSchedule은 현재 영속성 컨텍스트에 영속화는 되었지만 DB에서 생성 요청이 처리되지 못한 엔티티가 되어 남아있게 되죠. 생성 요청이 처리되지 않았다는 것은 DB에서 PK를 받아오지 못했다는 것과 같습니다.
즉, DB에는 데이터가 없다고 알고 있고, (새롭게 DB를 찔러서 확인하지 않기 때문에) 데이터를 찾아오라는 다음 요청에는 영속성 컨텍스트에 남아있는 바로 그 엔티티가 반환되는 것입니다.
그렇기 때문에 영속화는 되었지만 ID 값을 DB로부터 받아오지 못해 null로 채워져있게 되고, AssertionFailure 오류가 발생하게 되는 것입니다.
제대로 DB에 저장이 되지 않은 상태의 엔티티에 접근하려고 했기 때문에 이러한 오류를 발생시키는 것이라고 생각했어요.
그러면 영속성 컨텍스트에서 찾아오지 못하도록 하면 잘 찾아올 것이라고 생각하여 find를 하기 전에 영속성 컨텍스트를 한번 비워보았는데요. entityManager.clear() 를 한번 호출한 후 다시 테스트 해보니 해당 오류는 발생하지 않는 것을 확인했습니다.
트랜잭션 프록시
물론 해결방법을 찾긴 했지만 엔티티 매니저를 호출하여 강제로 영속성 컨텍스트를 비워버리는 것이 옳을까? 라는 생각을 했습니다. 분명 이를 트랜잭션을 통해 해결할 수 있을 것 같다는 느낌! 이 들었어요.
그래서 영속성 컨텍스트가 하나의 트랜잭션과 동일한 세션으로 진행되기 때문에 찾아오는 트랜잭션을 분리해주면 될 것이라고 생각하고 다음과 같이 코드를 수정했습니다.
@Service
@Transactional(readOnly=true)
public BookingScheduleService {
@Transactional
public BookingSchedule generateSchdule(LocalDateTime visitDateTime){
try {
return bookingScheduleRepository.save(newSchedule);
} catch (DataIntegrityViolationException exception){
return this.findSchedule(visitDateTime); // 생성하다가 오류 발생하면 DB에서 찾아오기
}
}
@Transactional(readOnly=true, propagation=Propagation.REQUIRES_NEW)
public BookingSchdule findSchedule(LocalDateTime visitDateTime){
return bookingSchduleRepository.findScheduleByDateTime(visitDateTime).get();
} 바로 전파속성을 통해 새로운 트랜잭션 내에서 작동하도록 해주었습니다. 새로운 트랜잭션이니까 새로운 영속성 컨텍스트를 가지고 찾아오지 않나?? 라고 생각했던 것이었죠.
하지만 역시나 제가 생각한 것은 아니었고,,, 왜 그런지 또 엄청 구글링하면서 트랜잭션에 대해 찾아봤는데, 선언적 트랜잭션을 사용하면 트랜잭션 프록시가 객체를 기준으로 만들어지기 때문에 동일한 빈 내부에서 메소드를 호출하는 것으로 새로운 트랜잭션이 생성되지 않는 것이 포인트였습니다.
트랜잭션 매니저는 트랜잭션 프록시에 의해 객체 하나당 하나만 존재하며, 자기 자신이 호출하는 메소드에 대해서는 트랜잭션 분리가 적용되지 않는다.
그래서 제가 생각했던 것처럼 분리되어 단독으로 작동하지 않는 것이었고, 외부에서 다르게 호출해야하는 것을 알게 되었습니다.
문제 2. 트랜잭션 롤백전략
위에서 발생한 문제를 해결하기 위해 예약 현황 데이터 생성과 데이터 조회를 완전히 분리했습니다.
그러면 앞서 고민했던 생성 시점 또한 변경이 용이해지고, 확장성이 더욱 커질 수 있고, 트랜잭션이 분리되지 않는 문제도 해결할 수 있었죠.
하지만 이렇게 쉽게 해결되지 않았던 또 하나의 원인은 바로 트랜잭션의 기본 롤백 전략이었습니다.
테스트를 돌려보니 예약이 제대로 생성되지 않고 모두 롤백되어버리는 문제가 발생했습니다. 설마설마설마 😨 DataIntegrityViolationException 에러가 나서...? 이거 때문에 롤백이 되는건가...? 라고 생각하고 트랜잭션이 롤백하는 타이밍에 대해 찾아보았습니다.
우아한 형제들 기술 블로그에 이에 대해 잘 정리해주신 분이 계시는데, 이 문제의 핵심은 트랜잭션의 기본 롤백 전략에 있었습니다.
트랜잭션은 상위 트랜잭션에 포함된 하위 트랜잭션에서 UncheckedException이 발생하면 rollback이 마킹되고, 상위 트랜잭션이 이를 확인하고 롤백을 하는 것이 기본 전략입니다.
hibernate가 전달하는 DataIntegrityViolationException은 UncheckedException 이었고, 그래서 롤백으로 마킹되어 예약 생성 로직이 모두 롤백되어 정상적으로 처리가 되지 않고 있던 것이었죠.
이를 해결할 수 있는 방법이 두가지가 있었는데, 한 가지는 해당 트랜잭션에서 예외가 발생해도 롤백하지 않도록 설정하는 것이고, 나머지 한 가지는 트랜잭션을 REQUIRES_NEW 전파 속성을 통해 분리해주는 방식입니다.
저는 후자의 방법을 선택했습니다!
그리고 동일한 기술 블로그의 글에서 말한 것처럼 예외가 발생한 상황에서 다음 비즈니스 로직을 선언해놓지 않고, 비즈니스 로직으로 변경하여 던진 후에 다른 곳에서 해당 예외를 잡아서 처리하도록 만들었습니다.
@Transactional(propagation = Propagation.REQUIRES_NEW)
public BookingSchedule generate(Long restaurantId, LocalDateTime bookingDateTime, int restaurantCapacity) {
BookingSchedule schedule = new BookingSchedule(restaurantId, bookingDateTime, restaurantCapacity);
try {
return bookingScheduleRepository.save(schedule);
} catch (DataIntegrityViolationException dataIntegrityViolationException) {
String errorMessage = MessageFormat.format("{0}번 레스토랑의 {1}의 예약 현황 로우가 이미 생성되었기 때문에 찾아옵니다.",
restaurantId, bookingDateTime);
throw new DuplicatedException(errorMessage);
}
}이렇게 하여 트랜잭션도 분리하고 롤백이 비즈니스 로직에 영향이 가지 않도록 만들어 예약하는 것까지 모두 롤백되지 않도록 만들었고, 이렇게 동시 생성 문제는 해결이 되었습니다 !!!! 🥳
문제 3. 데드락 발생
사실 데드락이 발생하는 것도 위에서 말한 트랜잭션 전파속성으로 해결했는데, 한번 언급하면 좋을 것 같아서 이야기해보려고 합니다!
 진짜 너무너무 어려웠고 이유를 알아내는데 힘들었는데 잘 풀어보도록 하겠습니다! (짤로 대변해보는 제 과거의 심정...)
진짜 너무너무 어려웠고 이유를 알아내는데 힘들었는데 잘 풀어보도록 하겠습니다! (짤로 대변해보는 제 과거의 심정...)
우선 데드락이 무엇이고, 현재 어떤 상황에 의해서 데드락이 발생한 것인지 먼저 알아봐보겠습니다!
데드락이란
데드락은 서로 다른 두 개의 트랜잭션이 자신이 사용하기 위해 특정 자원을 점유한 상태에서 서로 다른 트랜잭션이 점유한 자원을 기다리다가 무한 대기 상태에 빠지는 경우 발생하는 것입니다.
즉, 서로 자원을 점유한 상태에서 상대가 점유한 자원을 모두 기다리다가 결국 얻지 못해 무한으로 대기하는 상황에 빠지게 되는 것이지요.
어떠한 상황에서 데드락이 발생한거야?? 🤨
그러면 현재 코드에서 어떤 부분에서 데드락이 발생하는지를 한번 살펴볼게요.
데드락이 발생하는 코드는 바로 위의 트랜잭션 전파레벨을 적용한 것과 동일한 부분입니다. 저는 위에서 후자의 방법을 선택했다고 말씀을 드렸는데, 후자의 방법이 아닌 롤백이 되지 않도록 설정해주는 방식을 사용했을 경우에 데드락이 발생하게 되는 것인데요.
바로 이렇게요.
@Transactional(noRollbackFor = DataIntegrityViolationException.class)
public BookingSchedule generate(Long restaurantId, LocalDateTime bookingDateTime, int restaurantCapacity) {
BookingSchedule schedule = new BookingSchedule(restaurantId, bookingDateTime, restaurantCapacity);
try {
BookingSchedule savedSchedule = bookingScheduleRepository.save(schedule);
logger.warn("예약 현황 생성에 성공하였습니다.");
return savedSchedule;
} catch (DataIntegrityViolationException dataIntegrityViolationException) {
logger.warn("{}번 레스토랑의 {}의 예약 현황 로우가 이미 생성되었기 때문에 생성할 수 없습니다.", restaurantId, bookingDateTime);
String errorMessage = MessageFormat.format("{0}번 레스토랑의 {1}의 예약 현황 로우가 이미 생성되었기 때문에 찾아옵니다.",
restaurantId, bookingDateTime);
throw new BookingScheduleDuplicateException(errorMessage);
}
}유니크 제약 조건에 의해 생성이 성공되지 않고 실패되는 경우 롤백하지 마! 라고 설정을 해준 겁니다. 이렇게 되면 DB의 유니크에 의한 예약 롤백은 이루어지지 않게 됩니다.
하지만 그래도 여전히 테스트에서 롤백이 이루어지는 것을 볼 수 있는데요, 그 이유가 바로 MySQL이 자동으로 데드락 상태에서 빠져나오기 위해서 강제로 롤백하기 때문입니다.
일반적인 DBMS (Database Management System)에서는 데드락 탐지(Deadlock detection) 기능을 제공하기 때문에 데드락이 발견되면 자동으로 해소시켜준다
그러면 이 데드락이 왜 발생하는지 분석해보겠습니다.
데드락이 발생했던 로그가 DB에 남아있게 되는데 바로 이렇게요.
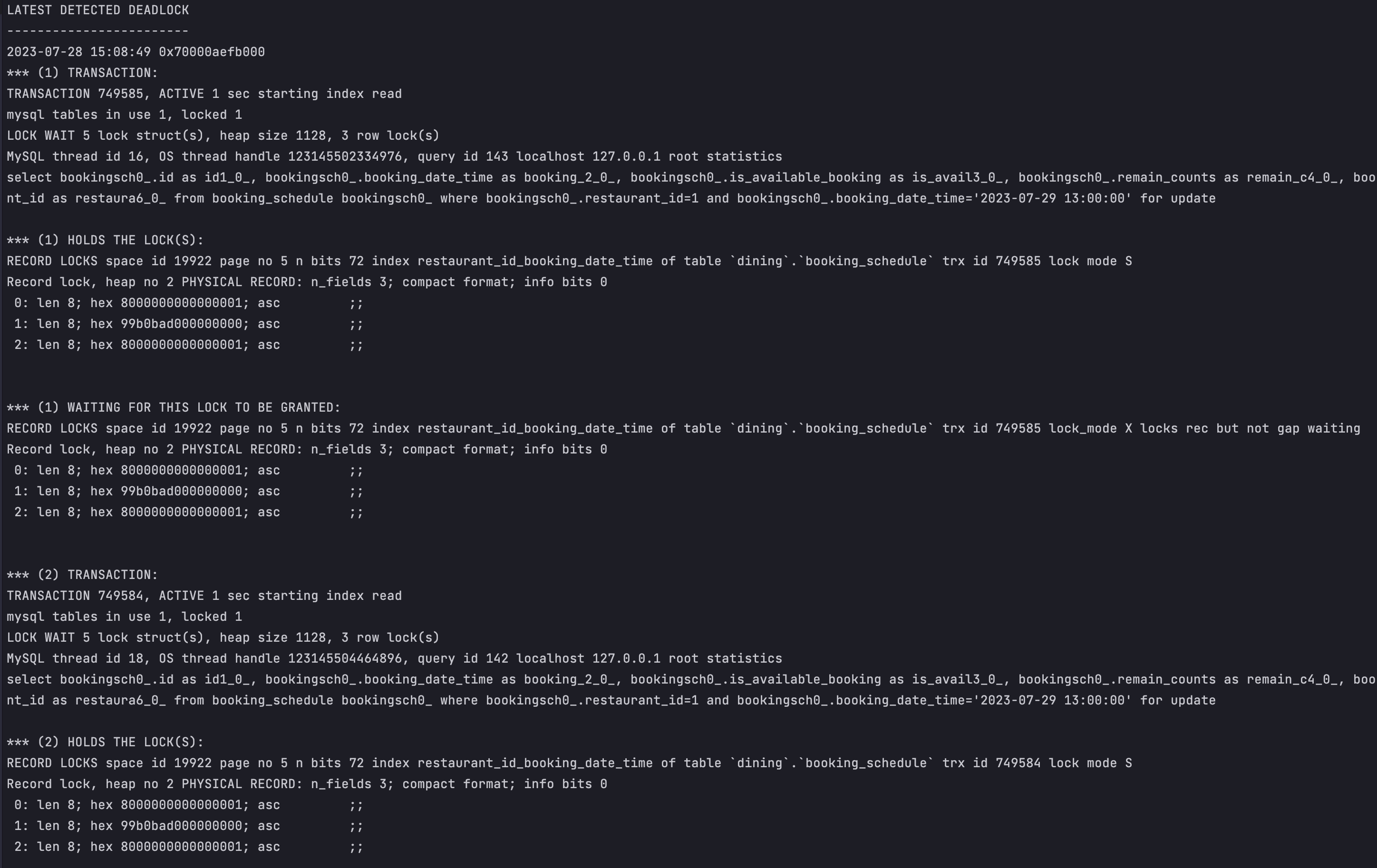
데드락이 발생하는 코드는 예약 현환을 생성하는 부분에서 발생합니다. 사실 저는 비관적 Lock을 사용하는 부분에서 데드락이 발생할 것이라고 예상했지만 아니었죠.
왜 insert를 하는 부분에서 lock이 발생하는거야? 라고 생각하고 MySQL의 데드락에 대해 공부해보기 시작했습니다.
근데 바로 MySQL에서 insert를 할 때 데드락이 발생할 수 있다고 해요. (출처: 링크)
insert 경쟁
트랜잭션 A,B,C 가 동시에 같은 key를 가진 데이터를 insert하려고 시도합니다. (바로 지금 제 상황이랑 동일합니다!)
이때 A는 DB에 동일한 Key를 가진 데이터가 없기 때문에 생성에 성공하죠.
이후 B와 C도 동일하게 insert 쿼리를 통해 생성을 시도할 텐데, 이때 MySQL에서는 insert에서 duplicated key error가 발생하면 해당 인덱스 레코드에 대해 일단 shared lock을 획득 시도합니다.
즉, B와 C가 shared lock을 획득하게 되고, 이후 롤백이 되지 않기 때문에 계속해서 트랜잭션이 수행되게 됩니다.
이제 이어서 이후 로직을 수행하는데, B와 C 트랜잭션이 이번에는 select 경쟁을 하게 됩니다.
이제는 DB에 존재하기 때문에 잘 가져와서 예약 로직을 수행하면 되는데, 앞서 트랜잭션이 종료되지 않고 shared lock을 획득한 채로 남아있었죠?
그래서 이후 update를 위해 select ... for update를 하기 위해 exclusive lock을 획득 시도하면서 결국 lock을 획득하지 못해 데드락이 발생하게 되는 겁니다. (exclusive lock은 shared lock이 있으면 획득하지 못하고 대기합니다.)
왜 트랜잭션 전파 속성을 REQUIRES_NEW로 하면 데드락이 발생하지 않았지? 😲
사실 이 데드락 문제는 해결법은 알고 있었지만 왜 해결되는지를 파악하지 못해 분석해본 것인데요.
전파 속성을 REQUIRES_NEW로 해주게 되면 insert가 이루어질 때 shared lock이 걸렸던 부분이 트랜잭션이 분리되어 따로 존재하고 종료되기 때문에 메소드 종료 시에 함께 lock도 해제되게 됩니다.
그래서 이후 select를 할 때 lock을 잘 소유하고 해제하는 순서가 잘 보장이 되게 되는 것이죠!!

드디어 모든 문제가 파악되어 해결이 되었습니다 !!!!!
이제 동시 예약 요청을 처리해보자.
이제 동시 생성에 대한 문제는 잡았기 때문에 반대로 로우가 이미 존재할 때 동시 요청이 잘 처리되는지 테스트를 먼저 했습니다. 하지만 역시나 update 되는 것이 반영이 잘 되지 않고 요청의 흐름대로 로직이 수행되지 않아 모든 예약이 여전히 성공하고 있었습니다...
그래서 예약이 가능한지 조회할 때 비관적 락을 걸어 예약 여부 조회부터 예약 성공까지 Lock을 사용하고, 예약이 성공되면 Lock이 반납되도록 동시성 문제를 해결했습니다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
@QueryHints(value = {@QueryHint(name = FLUSH_MODE, value = "COMMIT")})
BookingSchedule getByRestaurantIdAndAndBookingDateTime(Long restaurantId, LocalDateTime bookingDateTime);예약이 성공하면 해당 예약 현황 데이터에서 예약된 인원수 만큼 남은 좌석이 빠지고, 남은 좌석이 0이라면 해당 날짜와 시간에는 예약이 불가능하다는 상태로 변경되는 로직이 존재합니다.
public BookingSchedule booking(int bookingCounts) {
int result = this.remainCounts - bookingCounts;
if (result < 0) {
throw new IllegalArgumentException("예약 허용 인원수 초과");
}
this.remainCounts = result;
isAvailableBooking = isOverThanRemainCounts(); // 남은 좌석 수 가 0보다 큰지 판단
return this;
}(위의 코드가 예약 현황을 수정하는 로직입니다!)
그래서 비관적 락을 사용하는 것이 맞다고 생각하였고, 충분히 예약은 트랜잭션 충돌에 의한 문제가 확실하다고 생각이 들어 이렇게 마무리하기로 했습니다.
다양한 갯수의 스레드, 허용 인원수로 테스트를 해도 모두 잘 작동하는 것을 확인하고 진짜로 동시성 문제 트러블 슈팅을 마쳤습니다!!
이번 리팩토링을 통해 트랜잭션에 대해서도 깊게 알게 되었고, JPA에 대해서도 좀 더 활용 능력이 늘어난 것 같아서 뿌듯하네요!! 인과관계를 따져가면서 하나씩 해결해나가는 과정이 바로 제가 개발을 계속할 수 있는 원동력이 아닐까 싶습니다 ㅎㅎ
참고
https://jsonobject.tistory.com/614
https://velog.io/@chullll/Transactional-%EA%B3%BC-PROXY
https://escapefromcoding.tistory.com/734
https://techblog.woowahan.com/2606/
