
🎩 개요
Next.js를 사용하면서 정적인 페이지 위주로 만들다보니 pre-redering 시 데이터를 요청해야할 시 서버컴포넌트에서 DB에 데이터를 요청해 내려주는 방식을 사용했었다. 이는 컴포넌트의 깊이가 깊지 않은 페이지를 다룰땐 편리한 방법이었지만 서버에서 렌더링한 데이터를 재활용하기에는 쉽지 않은 방식이었다. 컴포넌트의 깊이가 깊어질수록 Props를 넘겨주는 횟수가 많아지고 결국 React-Query를 통해 클라이언트에서 서버상태관리를 하기로 결정했다.
SSR에서 React-Query가 어떻게 사용되는지 공식문서와 블로그를 참고하며 이해를 할 수 있었다. 이 중에는 hydration이라는 사전지식이 필요했다.
💦Hydration 이란?
보통 hydration 단어를 처음보면 해석된 뜻을 보아도 이해가 안된다. 수화(水和)라는 뜻으로 전기용어사전에선 "이온이 수용액 안에서 그 주위에 여러 개의 물 분자를 끌어 당겨서 결합하여 하나의 분자군을 형성하는 현상을 수화라 한다" 라고 설명한다.
예를 든다면 사용자가 웹페이지를 요청했을때 서버에서 미리 렌더링된 HTML인 이온을 먼저 다운받으면 JS가 없더라도 출력된 화면을 볼 수 있다. 그 후 여러 개의 물 분자 역할을 하는 JS가 모두 다운받아지면 합쳐저 클릭이벤트 등 동적인 기능을 실행시킬 수 있다고 볼 수 있다.
SPA의 단점인 빈 HTML을 다운받아 비교적 큰 사이즈인 JS를 모두 다운받고 실행시켜서 렌더링할때까지 빈 화면만 보는 단점과 SEO가 어려운점을 해결한 방법이라고 볼 수 있다. 하지만 사용자가 렌더링된 페이지를 빨리 볼 수 있다곤 하지만 JS가 다운받아지지 않아 인터렉션이 불가능하면 오히려 실망할 수 있다. 이런점을 개선하기 위해 React는 18버전에 HTML Streaming과 점진적인 Hydration을 도입했다. 이 주제는 해당 포스트의 주제와 다르기 때문에 넘어가도록하자.
✨ SSR에서 React-Query
그럼 왜 hydration이라는 단어를 소개했을까? React-Query의 공식문서에서 SSR 환경에서 사용될때 두가지 방법을 이야기하는데 첫번째는 서버에서 pre-fetching 후 Props로 내려주어 useQuery등 훅의 옵션인 initialData에 데이터를 넣어주는 방식이다. 이 방식은 간단하지만 깊이가 깊어지고 복잡할수록 번거로워지는 단점이 있다. 그리고 서버에서 쿼리를 가져온 시간을 알 수 있는 방법이 없으므로 쿼리를 다시 가져와야 하는지 여부를 페이지가 로드된 시간에 따라 결정됩니다.
export async function getStaticProps() {
const posts = await getPosts() // post에 대한 데이터를 서버에서 받아온다
return { props: { posts } } // 그리고 컴포넌트의 props로 전달한다.
}
function Posts(props) {
const { data } = useQuery({
queryKey: ['posts'],
queryFn: getPosts,
initialData: props.posts, // props로 전달된 데이터를 초기데이터로 넣어준다.
})
// ...
}두번째 방법은 Hydration을 사용하는 방법이다. Next12 버전에서 사용하는 방법과 App 디렉토리 즉 서버 컴포넌트와 클라이언트 컴포넌트에서 사용하는 방법이 나누어져 있지만 이번 포스팅에서는 App 디렉토리에서 다루는 방법을 서술한다.
처음 QueryClientProvider 를 감싸서 queryClient 를 하위 컴포넌트들에게 전달해주는 Setup 과정이 필요하다. App 디렉토리 바로 아래있는 layout.tsx가 모든 컴포넌트를 감싸는 RootLayout이 된다.
// app/providers.jsx
'use client'
import { QueryClient, QueryClientProvider } from '@tanstack/react-query'
export default function Providers({ children }) {
const [queryClient] = React.useState(() => new QueryClient())
return (
<QueryClientProvider client={queryClient}>{children}</QueryClientProvider>
)
}// app/layout.jsx
import Providers from './providers'
export default function RootLayout({ children }) {
return (
<html lang="en">
<head />
<body>
<Providers>{children}</Providers>
</body>
</html>
)
}원하는 곳에서 QueryClient 가져올 수 있도록 getQueryClient 함수를 작성한다. 이때 react cache를 활용하면 같은 인자로 호출된 함수의 반환값을 기억할 수 있어 동일한 client를 제공할 수 있다.
// app/getQueryClient.jsx
import { QueryClient } from '@tanstack/react-query'
import { cache } from 'react'
const getQueryClient = cache(() => new QueryClient()) // QueryClient caching
export default getQueryClient// app/hydratedPosts.jsx
import { dehydrate, Hydrate } from '@tanstack/react-query'
import getQueryClient from './getQueryClient'
export default async function HydratedPosts() {
const queryClient = getQueryClient()
// prefetchQuery를 통해 데이터를 요청하고 queryClient에 담는다.
await queryClient.prefetchQuery(['posts'], getPosts)
// dehydrate 함수를 활용해 dehydrate한다.
const dehydratedState = dehydrate(queryClient)
return (
<Hydrate state={dehydratedState}> // Posts 컴포넌트로 내려줄땐 다시 Hydrate한다.
<Posts />
</Hydrate>
)
}실제 클라이언트 컴포넌트에서 사용될때는 아래와 같이 사용될 수 있다.
"use client";
import { useQuery, useQueryClient } from "@tanstack/react-query";
import { getPosts } from "./HydratedPosts";
export default function Posts() {
// useQuery를 사용했지만 서버에서 전달된 캐싱된 데이터가 있기 때문에 중복해서 요청하지않는다.
const { data } = useQuery(["posts"], getPosts);
// 제대로 pre-fetching이 되었는지 확인하려면 useQuery를 잠시 주석처리하고 getQueryCache 메소드를 통해 캐싱된 쿼리가 있는지 확인해볼 수 있다.
const queryClient = useQueryClient();
console.log(queryClient.getQueryCache());
return <div>test</div>;
}
위 코드들은 React-Query 의 공식문서에서 인용한 코드들이다. 위 코드들을 따라하면 서버 컴포넌트에서 pre-fetching 하여 초기 렌더링 시 HTML에 데이터를 넣어서 렌더링할 수 있다. 또한 클라이언트의 QueryClient에서 해당 데이터를 캐시로 보유하고 있기 때문에 가공하여 사용할 수 있다.
📚 React-Query Hydrate 동작방식

그렇다면 어떤 방식으로 동작하는 것일까? 일단 전체적인 순서를 보자면 아래와 같다.
1. getQueryClient를 사용해 QueryClient를 가져온다.
react cache를 활용하여 동일한 QueryClient를 넘겨준다.
2. QueryClient의 prefetchQuery 메소드를 사용하여 데이터를 프리페치하고 완료될 때까지 기다린다.
queryClient.prefetchQuery를 하면 QueryClient에는 queryCache에 해당 쿼리 결과를 배열로 저장하게 된다.
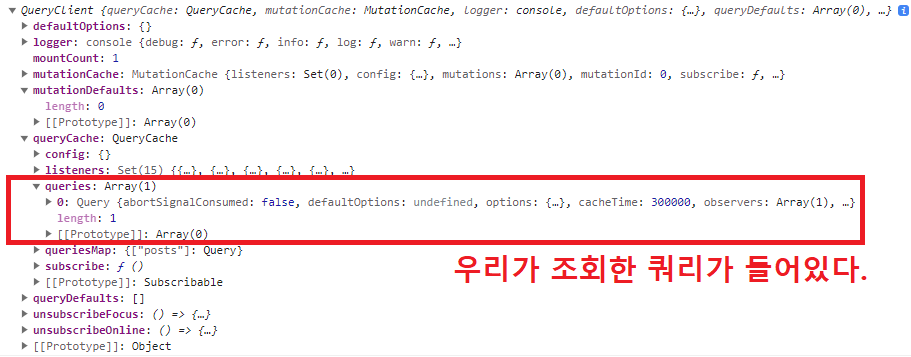
위 로직은 서버에서 동작하지만 편의상 클라이언트에서 조회한 QueryClient를 첨부하였습니다.
3. QueryClient를 dehydrate 메소드를 활용하여 dehydrate 한다.
React-Query의 dehydrate 메소드 코드는 아래와 같은데, mutations 와 queries으로 나누어져있지만 queries의 내용만 본다면 QueryCache 데이터를 모두 가져와 query마다 dehydrateQuery 메소드를 적용하고 queries 배열에 push하는것을 볼 수 있다. dehydrateQuery 는 query에서 state ,queryKey ,queryHash 만 추출하여 객체로 만들어서 리턴한다.
export function dehydrate(
client: QueryClient,
options: DehydrateOptions = {},
): DehydratedState {
const mutations: DehydratedMutation[] = []
const queries: DehydratedQuery[] = []
if (options.dehydrateMutations !== false) {
// (...생략)
}
if (options.dehydrateQueries !== false) {
const shouldDehydrateQuery =
options.shouldDehydrateQuery || defaultShouldDehydrateQuery
client // QueryCache 데이터를 모두 가져와 query마다 dehydrateQuery 메소드를 적용
.getQueryCache()
.getAll()
.forEach((query) => {
if (shouldDehydrateQuery(query)) {
queries.push(dehydrateQuery(query))
}
})
}
return { mutations, queries }
}function dehydrateQuery(query: Query): DehydratedQuery {
return {
state: query.state,
queryKey: query.queryKey,
queryHash: query.queryHash,
}
}4. 데이터를 사용할 컴포넌트마다 <Hydrate>로 랩핑하고 dehydrate된 상태값을 props로 넘겨준다.
<Hydrate> 컴포넌트에서는 dehydrate된 상태값을 state props로 받아 처리한다.
// dehydrate된 queryClient
{
mutations: [],
queries: [ { state: [Object], queryKey: [Array], queryHash: '["posts"]' } ]
}5. js가 실행되면서 <Hydrate> 컴포넌트가 실행되고 클라이언트의 QueryClient에 dehydrate된 상태값을 다시 넣어 hydrate 한다. 즉 클라이언트에서도 서버에서 pre-fetching 한 데이터가 QueryClient안에 캐싱되게 된다.
<Hydrate> 컴포넌트부터는 클라이언트 컴포넌트로 동작하며 Hydrate를 컴포넌트로 만든 이유는 내부적으로 useHydrate 라는 커스텀 훅을 사용하고 커스텀 훅 내부에는 useRef와useQueryClient 을 사용하기 때문에 컴포넌트로 만든것으로 생각된다.
// Hydrate
export const Hydrate = ({ children, options, state }: HydrateProps) => {
useHydrate(state, options)
return children as React.ReactElement
}// useHydrate
export function useHydrate(
state: unknown,
options: HydrateOptions & ContextOptions = {},
) {
const queryClient = useQueryClient({ context: options.context })
const optionsRef = React.useRef(options)
optionsRef.current = options
React.useMemo(() => {
if (state) {
hydrate(queryClient, state, optionsRef.current) // state가 있다면 hydrate한다.
}
}, [queryClient, state])
}핵심은 hydrate 메소드인데 dehydratedState를 받아 반복문을 돌면서 현재 클라이언트에 캐싱되어있는 쿼리를 queryHash로 가져와서 dataUpdatedAt 즉 언제 업데이트되었는지 비교하고
dehydratedState 된 데이터가 더 최신이라면 query의 setState 메소드로 상태를 업데이트한다. dehydratedQueryState객체에 fetchStatus속성을 idle로 하여 hydration 시 쿼리가 fetching state에서 멈추는 것을 방지한다.
export function hydrate(
client: QueryClient,
dehydratedState: unknown,
options?: HydrateOptions,
): void {
if (typeof dehydratedState !== 'object' || dehydratedState === null) {
return
}
const mutationCache = client.getMutationCache()
const queryCache = client.getQueryCache()
const mutations = (dehydratedState as DehydratedState).mutations || []
const queries = (dehydratedState as DehydratedState).queries || []
mutations.forEach((dehydratedMutation) => {
// (...생략)
})
queries.forEach((dehydratedQuery) => {
const query = queryCache.get(dehydratedQuery.queryHash)
// fetchStatus 상태 idle 변경
const dehydratedQueryState = {
...dehydratedQuery.state,
fetchStatus: 'idle' as const,
}
if (query) {
if (query.state.dataUpdatedAt < dehydratedQueryState.dataUpdatedAt) {
query.setState(dehydratedQueryState) // 최신데이터로 쿼리 상태 업데이트
}
return // 클라이언트에 캐싱된 쿼리를 갱신했으니 함수 종료
}
// 클라이언트에 캐싱된 쿼리가 없으니 queryCache.build 메소드로 cache 생성
queryCache.build( // build 메소드는 QueryCache class에 새로운 쿼리를 만들어 저장한다.
client,
{
...options?.defaultOptions?.queries,
queryKey: dehydratedQuery.queryKey,
queryHash: dehydratedQuery.queryHash,
},
dehydratedQueryState,
)
})
}이런 과정을 통해서 클라이언트에서는 서버에서 pre-fetching 된 데이터를 클라이언트 사이드 QueryClient에서도 캐싱상태로 가지고 있을 수 있는 것이다.

🎩 맺음말
공식문서만 봤을때 사용법에 대해서는 이해가 갔지만 왜 hydrate과 dehydrate라는 단어를 사용하는지 이해가 되지 않았다. 코드를 확인하면서 React-Query에서도 서버사이드에서 데이터를 분해하여 클라이언트에서 다시 결합시키는 방법을 사용했기 때문이라고 생각하게 되었다. hydrate과 dehydrate에 관련된 코드를 확인하면서 느낀건데 이해하기 쉽게 잘 작성된 코드였던것 같다.
혹시라도 동작원리에 대해 잘못된 포스팅을 하였다면 댓글로 도움을 주시면 감사하겠습니다.

감사합니다.