
네이버 데이터사이언스 코칭스터디의 리드부스터로 활동했었고 얼마전 수료했다.
4주간 리더로 팀원들을 이끌면서 미션도 해결하고 데이터사이언스분야 현직자인 코치님의 피드백도 받고 매주 성장하는 나날을 보냈다.
여기서 피드백을 받던중 가장 놀랐던거는 inplace=True 를 비추한다는 것이었다.
그래서 오늘은 inplace=True 에 대해 한번 얘기해보려고 한다.
https://stackoverflow.com/questions/43893457/understanding-inplace-true-in-pandas 의 내용을 많이 참조했으므로 영어에 익숙한 분들은 이걸로 읽어봤으면 좋겠다. 이게 훨씬 정확하다.
inplace=True란 무엇일까?
우선 in place의 뜻을 알아보면 제자리에 있는, 준비가 되어있는 이라는 의미를 가진다.
따라서 inplace=True 란 데이터프레임을 가공 및 변경할 때, 즉 rename, drop 등의 메서드를 사용할 때 값을 저장할 목적으로 이용한다.
이렇게만 설명하면 무슨말인지 잘 모를테니 예시를 들어 설명하겠다.
예시
df = pd.DataFrame(data = np.array([[1,2,3],[4,5,6],[7,8,9]]), columns =['A','B','C'])
df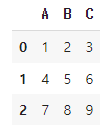
위 데이터프레임에서 A칼럼을 삭제하고 싶다.
inplace=True를 했을 경우
df.drop('A', axis=1, inplace=True)
df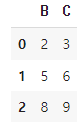
inplace=False를 했을 경우
df.drop('A', axis=1, inplace=False)
df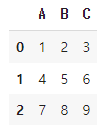
차이를 알겠는가?
데이터 프레임을 가공한 것이 메모리에 그대로 적용이 된다.
쉽게 말하면 inplace=True 적용전 데이터프레임으로 되돌릴 수가 없다.
데이터 프레임의 기본구조를 변경하는 것이기 때문이다.
아, 참고로 inplace=False 가 기본값이다.
추천하는 방식
따라서 데이터프레임에서 A칼럼을 날려버리고 싶을 때
# A 칼럼을 다시 쓰지 않아도 될 때
df = df.drop('A', axis = 1)
# A 칼럼을 다시 써야할 때
df_drop_A = df.drop('A', axis = 1)
df_drop_Ainplace=True 를 쓰지말고 위와 같은 방법을 사용하도록 하자.
❓ 의문점
df = df.drop('A', axis = 1)
df.drop('A', axis = 1, inplace=True)여기서 분명 의문점이 들것이다.
위 두 코드는 같은 결과를 불러오는거 아닌가요?
왜 굳이 전자를 사용해야하는거죠?
나도 처음에 위와 같은 의문이 들었다. 왜 굳이 데이터프레임을 새로 할당해야하는지 모르겠어서다.
코치님에게 문의하니 참고할만한 링크를 알려주셔서 이해한대로 한번 설명해보도록 하겠다.
inplace=True를 추천하지 않는 진짜 이유는 ?
간단하게 말하면 아무 이점이 없다. 굳이 사용할 이유가 없다는 것이다.
pandas 공식문서에서도 메모리누수 등의 이유로 inplace=True 를 사용하지말것을 권고하고 있다.
1. inplace=True는 복사본이 생성되는 것을 막을 수 없으며, 성능 이점이 거의 없다.
inplace=True는 효율적이고 최적의 코드를 만들어 줄거라고 생각하지만 그것은 큰 오산이다.
(일부 드문 예외 케이스가 있다고는 하지만) inplace=True 는 성능상의 이점이 없다.
또한 inplace=True 는 메모리에 있는 데이터를 삭제함으로써 복사본을 생성하지 않는 것으로 알려져있다. 그러나 상식과는 다르게 자동으로 복사본을 할당한다.
이게 무슨말이냐면 inplace = False 의 경우는
df_drop_A = df.drop('A', axis = 1, inplace=False)위 예시처럼 df_drop_A 에 데이터프레임을 할당하는 구조라면 inplace = True 는
df.drop('A', axis = 1, inplace=True)의 형태이기 때문에 새로운 변수에 데이터프레임을 할당하지 않아도 된다.
그래서 inplace=True 는 복사본을 생성하지 않는다고 알고있지만 그것은 큰 착각이며 자동으로 복사본을 할당하므로 복사본이 생성되는 것을 막을 수 없다.
2. inplace=True는 메서드체이닝(method chaining)에서 작동하지 않는다.
메서드체이닝(method chaining) 도 예시로 한번 살펴보자
- 메서드 체이닝을 사용하지 않은 코드
temp = df[df['A']>=4]
temp.reset_index(inplace=True)
result = temp.B
result- 메서드 체이닝을 사용한 코드
result = df[df['A']>=4].reset_index().B
result메서드 체이닝에 대한 이해가 좀 가는가?
메서드 체이닝을 사용한 코드가 더 간결하며 가독성이 좋다. 임시변수를 할당할 필요도 없다.
그러나 inplace=True 는 메서드체이닝에서 사용할 수 없다.
3. inplace=True를 데이터프레임 칼럼에 사용할 경우 SettingWithCopyWarning이 발생할 수 있으며 디버깅하기 어려운 오류가 발생할 수 있다.
우선 SettingWithCopyWarning 이 생기는 경우를 보자.
df = pd.DataFrame(data = np.array([[1,2,3],[4,5,6],[7,8,9]]), columns =['A','B','C'])
df1 = df[df.A >= 4]
display(df, df1)
df1 의 B 칼럼의 5를 모두 10으로 바꾸고 싶을 때
df1['B'].replace({5:10}, inplace=True)
SettingWithCopyWarning 경고를 볼 수 있다.
이 경고가 생기는 이유는 df 가 아닌 df1 에 값을 적용했기 때문에 df1['B'] 의 값은 변하지만 df['B'] 의 값은 변하지 않기때문에 이를 경고해주기 위해서다.
추후 디버깅이 어려워지기 때문에 경고하는 것이다.
결론
따라서 inplace=True 를 쓰지 않는것이 좋다. 혹시 이해가 가지 않는다면 그냥 inplace=True 를 아예 쓰지 않도록 하자. 사실 나도 아직 이해가 안가는 부분이 많다.
조금 더 공부해보고 추가할 내용이 있다면 덧붙이도록 하겠다. 틀린 부분이 있다면 꼭 알려주셨으면 좋겠다.
📌 참조
Tistory, 파이썬 판다스 inplace 옵션, https://story-opinion.tistory.com/25, (2022-12-22)
Tistory, [python] pandas Dataframe inplace 옵션 예제, https://log-laboratory.tistory.com/339, (2022-12-22)
Medium, Why You Should Probably Never Use pandas inplace=True, https://towardsdatascience.com/why-you-should-probably-never-use-pandas-inplace-true-9f9f211849e4, (2022-12-22)
Stackoverflow, Understanding inplace=True in pandas, https://stackoverflow.com/questions/43893457/understanding-inplace-true-in-pandas, (2022-12-23)

3개의 댓글

This is very annoying, but you still have to solve.
오 메서드체이닝 안되는건 처음알았어요..! 감사합니다