저번 포스트에 이어 redis cluster의 장애 복구 시뮬레이션을 할 예정이다. Redis Gate를 참조하였다.
현재 클러스터 구성은 총 3개의 서버에 master 1개, slave 1개가 있으며, slave는 자신과 다른 서버에 위치한 master의 replica이다.
- 1번 서버 master - 2번 서버 slave
- 2번 서버 master - 3번 서버 slave
- 3번 서버 master - 1번 서버 slave
시뮬레이션 시나리오와 결과는 아래와 같다.
1. 마스터 노드 1개 다운: ok
2. 마스터 노드 2개 다운: ok
3. 마스터 노드 1개와 그의 replica slave 노드 1개 다운: fail
마스터 노드 1개 다운
다음과 같이 마스터 노드 3개, 복제 노드 3개 상황에서 1번 마스터를 kill -9로 다운시키면, 복제가 마스터로 승격되어 계속된다. 하지만 cluster-node-time 시간 (저번에 설정한 값은 5000)을 포함해서 정상으로 돌아오기까지 몇 초가 소요된다.
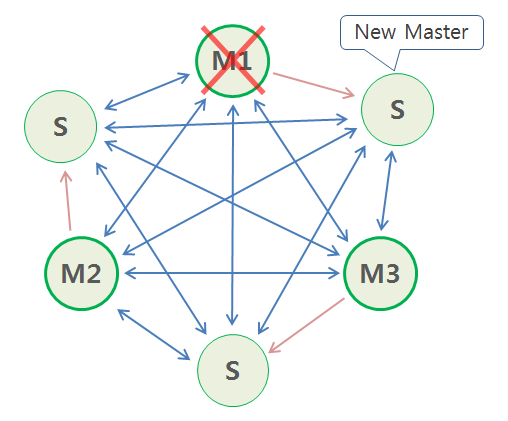
마스터 노드 1개 kill
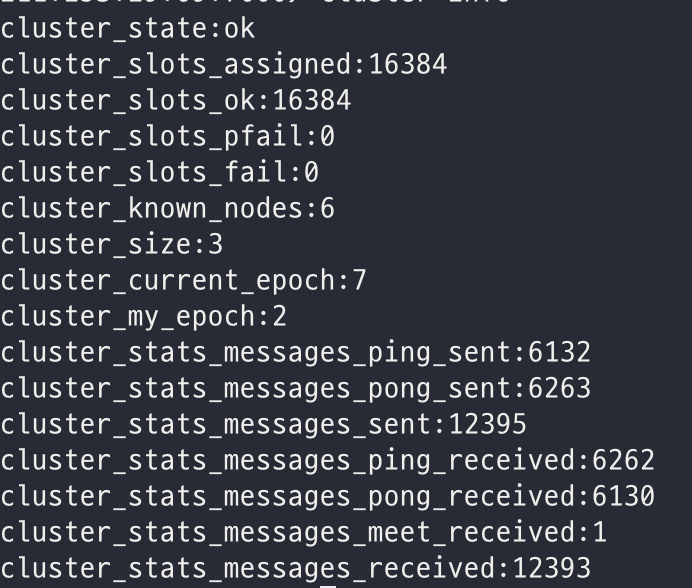
먼저 마스터 노드를 죽이기 이전 cluster의 상태는 아래와 같다. redis-cli -h [IP] -p 7000로 서버에 접근하여 cluster info로 확인할 수 있다.
1번 서버의 마스터 노드 프로세스를 죽이고, 1번 서버 master 노드의 복제인 2번 서버의 slave 노드를 죽여보도록 하겠다.
ps -ef | grep redis
kill -9 [pid]마스터 노드의 복제노드 로그 확인
1번 서버의 마스터 노드를 죽인 후, 2번 서버 slave 노드의 로그를 확인해보면 약 8초간 연결 시도를 하다가 failover election 후 master로 전환되는 것을 볼 수 있다.
31032:S 31 Oct 2021 18:23:08.007 # Connection with master lost.
31032:S 31 Oct 2021 18:23:08.007 * Caching the disconnected master state.
31032:S 31 Oct 2021 18:23:08.007 * Reconnecting to MASTER XXX:7000
31032:S 31 Oct 2021 18:23:08.007 * MASTER <-> REPLICA sync started
31032:S 31 Oct 2021 18:23:08.007 # Error condition on socket for SYNC: Connection refused
...
31032:S 31 Oct 2021 18:23:16.494 * Connecting to MASTER XXX:7000
31032:S 31 Oct 2021 18:23:16.494 * MASTER <-> REPLICA sync started
31032:S 31 Oct 2021 18:23:16.494 # Error condition on socket for SYNC: Connection refused
31032:S 31 Oct 2021 18:23:16.544 * FAIL message received from 37f48432681245759baba8edd10ef13e2b3737da about 3051d3d6b573d29fed02c1751bd9afbfdb40676a
31032:S 31 Oct 2021 18:23:16.544 # Cluster state changed: fail
31032:S 31 Oct 2021 18:23:16.595 # Start of election delayed for 778 milliseconds (rank #0, offset 4760).
31032:S 31 Oct 2021 18:23:17.401 # Starting a failover election for epoch 8.
31032:S 31 Oct 2021 18:23:17.407 # Failover election won: I'm the new master.
31032:S 31 Oct 2021 18:23:17.407 # configEpoch set to 8 after successful failover
31032:M 31 Oct 2021 18:23:17.407 * Discarding previously cached master state.
31032:M 31 Oct 2021 18:23:17.407 # Setting secondary replication ID to 09b834a376409ea3f0078113e0f344f61e93e8bf, valid up to offset: 4761. New replication ID is c9b1e46a9cd1a296cc76b5be77f4ab791181e7e7
31032:M 31 Oct 2021 18:23:17.408 # Cluster state changed: ok다른 마스터 노드 로그 확인
2번 서버의 마스터 노드 로그를 확인해보면, 1번 서버에 대한 FAIL 메시지를 받았고, cluster state가 FAIL로 변했다가 master가 변경된 후 ok 상태로 된 것을 볼 수 있다.
31075:M 31 Oct 2021 18:23:16.544 * FAIL message received from 37f48432681245759baba8edd10ef13e2b3737da about 3051d3d6b573d29fed02c1751bd9afbfdb40676a
31075:M 31 Oct 2021 18:23:16.544 # Cluster state changed: fail
31075:M 31 Oct 2021 18:23:17.404 # Failover auth granted to f2dcf94cf509e9a0acd7ed6cee6e0c3a1b19e55e for epoch 8
31075:M 31 Oct 2021 18:23:17.411 # Cluster state changed: ok
31075:M 31 Oct 2021 18:26:17.086 * 1 changes in 3600 seconds. Saving...
31075:M 31 Oct 2021 18:26:17.087 * Background saving started by pid 1247
1247:C 31 Oct 2021 18:26:17.090 * DB saved on disk
1247:C 31 Oct 2021 18:26:17.091 * RDB: 4 MB of memory used by copy-on-write
31075:M 31 Oct 2021 18:26:17.189 * Background saving terminated with successcluster info 확인
이후 서버에 접속해서 cluster info를 찍어보면 cluster_stats_messages_fail_received 1 필드가 새로 생긴 것을 볼 수 있다.
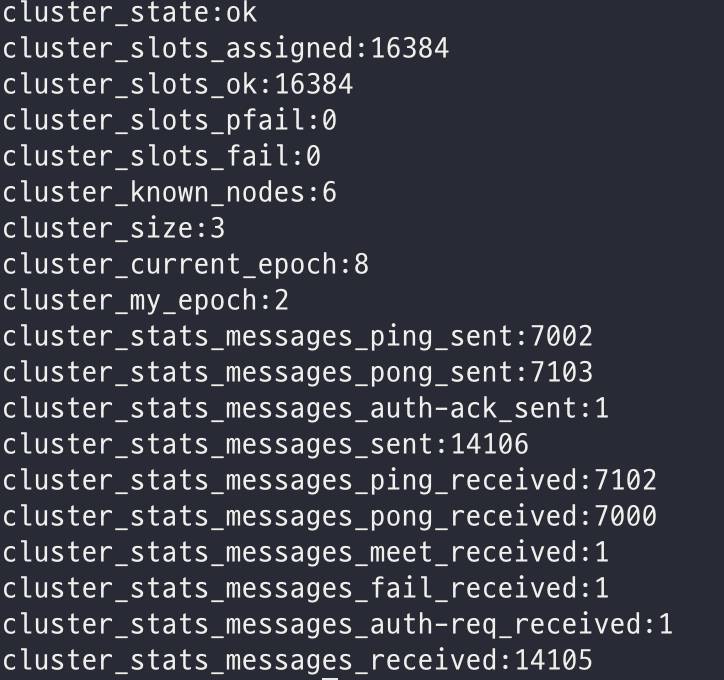
죽었던 마스터 노드 살리기
1번 서버에서 redis-server 7000/7000.conf로 방금 죽은 마스터 노드를 살려보았다.
죽었던 master 노드의 로그 확인
해당 노드의 로그는 아래와 같이 남는다.
로그 분석을 해보면, 죽었던 마스터 노드가 살아나면서 진행되는 작업은 아래와 같다.
1. 본인이 가지고 있던 master parameter 정보를 가지고 새로운 master와 synchronize할 수 있을지 판단한다.
2. 본인을 대신해 새로 master가 된 노드의 replica로 재설정된다.
3. 새로 master가 된 노드에 연결을 시도한다.
4. 새로운 master가 응답하며 replication을 진행하게 된다.
1945:C 31 Oct 2021 18:33:54.828 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1945:C 31 Oct 2021 18:33:54.828 # Redis version=6.2.6, bits=64, commit=00000000, modified=0, pid=1945, just started
1945:C 31 Oct 2021 18:33:54.828 # Configuration loaded
1945:M 31 Oct 2021 18:33:54.829 * Increased maximum number of open files to 10032 (it was originally set to 1024).
1945:M 31 Oct 2021 18:33:54.829 * monotonic clock: POSIX clock_gettime
1945:M 31 Oct 2021 18:33:54.830 * Node configuration loaded, I'm 3051d3d6b573d29fed02c1751bd9afbfdb40676a
1945:M 31 Oct 2021 18:33:54.830 * Running mode=cluster, port=7000.
1945:M 31 Oct 2021 18:33:54.830 # Server initialized
1945:M 31 Oct 2021 18:33:54.831 * Loading RDB produced by version 6.2.6
1945:M 31 Oct 2021 18:33:54.831 * RDB age 4060 seconds
1945:M 31 Oct 2021 18:33:54.831 * RDB memory usage when created 2.50 Mb
1945:M 31 Oct 2021 18:33:54.831 # Done loading RDB, keys loaded: 0, keys expired: 0.
1945:M 31 Oct 2021 18:33:54.831 * DB loaded from disk: 0.000 seconds
1945:M 31 Oct 2021 18:33:54.831 * Ready to accept connections
1945:M 31 Oct 2021 18:33:54.832 # Configuration change detected. Reconfiguring myself as a replica of f2dcf94cf509e9a0acd7ed6cee6e0c3a1b19e55e
1945:S 31 Oct 2021 18:33:54.832 * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
1945:S 31 Oct 2021 18:33:54.832 * Connecting to MASTER XXX:7001
1945:S 31 Oct 2021 18:33:54.832 * MASTER <-> REPLICA sync started
1945:S 31 Oct 2021 18:33:54.832 # Cluster state changed: ok
1945:S 31 Oct 2021 18:33:54.835 * Non blocking connect for SYNC fired the event.
1945:S 31 Oct 2021 18:33:54.835 * Master replied to PING, replication can continue...
1945:S 31 Oct 2021 18:33:54.836 * Trying a partial resynchronization (request c2e5f8cd7d3c33e8a3fe2c910de7b8f4bdbdf6c3:1).
1945:S 31 Oct 2021 18:33:54.837 * Full resync from master: c9b1e46a9cd1a296cc76b5be77f4ab791181e7e7:4760
1945:S 31 Oct 2021 18:33:54.837 * Discarding previously cached master state.죽은 노드를 대신해 새로 master 노드가 된 노드의 로그 확인
새로 master가 되었던 2번 서버의 구 slave 노드 로그를 확인해보면 아래와 같다.
replica(1번 서버의 구 master)가 synchronization을 요청했으며, 새로운 master 노드가 이를 승인하였고, 죽었던 노드에 대한 FAIL state를 청산했다는 내용이다.
31032:M 31 Oct 2021 18:33:54.836 * Replica XXX:7000 asks for synchronization
31032:M 31 Oct 2021 18:33:54.837 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'c2e5f8cd7d3c33e8a3fe2c910de7b8f4bdbdf6c3', my replication IDs are 'c9b1e46a9cd1a296cc76b5be77f4ab791181e7e7' and '09b834a376409ea3f0078113e0f344f61e93e8bf')
31032:M 31 Oct 2021 18:33:54.837 * Starting BGSAVE for SYNC with target: disk
31032:M 31 Oct 2021 18:33:54.837 * Background saving started by pid 1538
1538:C 31 Oct 2021 18:33:54.841 * DB saved on disk
1538:C 31 Oct 2021 18:33:54.841 * RDB: 4 MB of memory used by copy-on-write
31032:M 31 Oct 2021 18:33:54.883 * Background saving terminated with success
31032:M 31 Oct 2021 18:33:54.883 * Synchronization with replica XXX:7000 succeeded
31032:M 31 Oct 2021 18:33:54.887 * Clear FAIL state for node 3051d3d6b573d29fed02c1751bd9afbfdb40676a: master without slots is reachable again.마스터 노드 2개 다운
master 노드 2개 kill
클러스터 구성을 1, 2, 3번 서버에 각각 master-slave가 1개씩 있던 원래 구성으로 원복시킨 후 테스트를 할 것이다.
slave 노드 로그 확인
1번과 2번 서버의 master를 다운시킨 후 2번 서버의 slave인 3번 서버의 7001번 노드를 확인해보자. Failover election won: I'm the new master.라며 본인이 master가 되었다는 로그를 확인할 수 있다.
15476:S 01 Nov 2021 22:08:26.270 # Connection with master lost.
15476:S 01 Nov 2021 22:08:26.270 * Caching the disconnected master state.
15476:S 01 Nov 2021 22:08:26.271 * Reconnecting to MASTER XXX:7000
15476:S 01 Nov 2021 22:08:26.271 * MASTER <-> REPLICA sync started
15476:S 01 Nov 2021 22:08:26.271 # Error condition on socket for SYNC: Connection refused
...
15476:S 01 Nov 2021 22:08:33.378 * Connecting to MASTER XXX:7000
15476:S 01 Nov 2021 22:08:33.378 * MASTER <-> REPLICA sync started
15476:S 01 Nov 2021 22:08:33.379 # Error condition on socket for SYNC: Connection refused
15476:S 01 Nov 2021 22:08:34.166 * FAIL message received from f2dcf94cf509e9a0acd7ed6cee6e0c3a1b19e55e about 61e7e615c968e881656afb04b2557c1b63afbba4
15476:S 01 Nov 2021 22:08:34.166 # Cluster state changed: fail
15476:S 01 Nov 2021 22:08:34.184 # Start of election delayed for 542 milliseconds (rank #0, offset 39144).
15476:S 01 Nov 2021 22:08:34.386 * Connecting to MASTER XXX:7000
15476:S 01 Nov 2021 22:08:34.386 * MASTER <-> REPLICA sync started
15476:S 01 Nov 2021 22:08:34.386 # Error condition on socket for SYNC: Connection refused
15476:S 01 Nov 2021 22:08:34.789 # Starting a failover election for epoch 12.
15476:S 01 Nov 2021 22:08:34.795 # Failover election won: I'm the new master.
15476:S 01 Nov 2021 22:08:34.795 # configEpoch set to 12 after successful failover
15476:M 01 Nov 2021 22:08:34.795 * Discarding previously cached master state.
15476:M 01 Nov 2021 22:08:34.795 # Setting secondary replication ID to 592ce8fe532d7eb406af81c791c19e991951070c, valid up to offset: 39145. New replication ID is a938ae30867dad0674e1845a263091b0044e213a
15476:M 01 Nov 2021 22:08:34.795 # Cluster state changed: okcluster 상태 확인
redis-cli에 접속하여 클러스터 상태를 확인해보자.
XXX:7000> cluster nodes
f2dcf94cf509e9a0acd7ed6cee6e0c3a1b19e55e XXX-2:7001@17001 master - 0 1635772167599 11 connected 0-5460
6a181c8879484fc00c924f56b4b889a8f0eedc7f XXX-3:7000@17000 myself,master - 0 1635772166000 9 connected 10923-16383
3051d3d6b573d29fed02c1751bd9afbfdb40676a XXX-1:7000@17000 master,fail - 1635772094598 1635772092000 10 disconnected
61e7e615c968e881656afb04b2557c1b63afbba4 XXX-2:7000@17000 master,fail - 1635772108115 1635772106099 2 disconnected
f1ce03c8079e140026517eb050621ac866884bcf XXX-1:7001@17001 slave 6a181c8879484fc00c924f56b4b889a8f0eedc7f 0 1635772167095 9 connected
37f48432681245759baba8edd10ef13e2b3737da XXX-3:7001@17001 master - 0 1635772166087 12 connected 5461-109221번 서버의 master와 2번 서버의 master에서 fail이 발생하여, 2번 서버의 7001번 노드 (기존 1번 서버 master의 slave)가 다시 master가, 3번 서버의 7001번 노드도 slave에서 master로 바뀐 것을 볼 수 있다.
XXX:7000> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:12
cluster_my_epoch:9
cluster_stats_messages_ping_sent:51219
cluster_stats_messages_pong_sent:51266
cluster_stats_messages_meet_sent:1
cluster_stats_messages_fail_sent:3
cluster_stats_messages_auth-ack_sent:2
cluster_stats_messages_sent:102491
cluster_stats_messages_ping_received:51265
cluster_stats_messages_pong_received:51220
cluster_stats_messages_meet_received:1
cluster_stats_messages_fail_received:2
cluster_stats_messages_auth-req_received:2
cluster_stats_messages_received:102490cluster 상태는 ok 인 것을 확인할 수 있다.
마스터 노드 1개와 그의 replica slave 노드 1개 다운
위에서 죽인 master 노드 2개를 모두 살려놓고, 1, 2, 3번 서버에 각각 master-slave 구성을 기존처럼 원복하여 진행하자.
master 노드 1개와 그의 slave 노드를 kill하자
1번 서버의 master노드와 그의 replica인 2번 서버의 slave 노드를 모두 죽여보자.
slave 노드를 먼저 죽이고 master노드를 죽인다.
클러스터 상태 확인
1번 master의 slave까지 죽이고 나니, 기존 1번 서버의 master는 살아날 수가 없게 되어 cluster 상태가 fail이 된 것을 확인할 수 있다.
XXX:7000> cluster info
cluster_state:fail
cluster_slots_assigned:16384
cluster_slots_ok:10923
cluster_slots_pfail:0
cluster_slots_fail:5461
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:12
cluster_my_epoch:9
cluster_stats_messages_ping_sent:54021
cluster_stats_messages_pong_sent:54039
cluster_stats_messages_meet_sent:2
cluster_stats_messages_fail_sent:3
cluster_stats_messages_auth-ack_sent:2
cluster_stats_messages_sent:108067
cluster_stats_messages_ping_received:54037
cluster_stats_messages_pong_received:54021
cluster_stats_messages_meet_received:2
cluster_stats_messages_fail_received:7
cluster_stats_messages_auth-req_received:2
cluster_stats_messages_received:108069
안녕하세요 레디스 공부하고 있는 학생입니다.
혹시 레디스를 액티브 액티브로 설정해볼수는 없나요?
방법이 있다면 링크나 내용좀 부탁드립니다.
구글 검색해도 못찾겠어요;;;