원시 자료형과 참조 자료형
원시 자료형 깊게 이해하기
자바스크립트에서 원시 타입의 데이터(primitive data types; 원시 자료형)는 객체가 아니면서 method를 가지지 않는 6 가지의 타입
string, number,bigint, boolean, undefined, symbol, (null)
원시자료형이라고 부르는 이유
'string', 42, true, false, undefined // 데이터가 "하나"의 정보를 담고 있습니다.원시 자료형은 모두 "하나"의 정보, 즉, 데이터를 담고 있습니다. 옛날에 어떻게 코드를 작성했는지를 돌아보면, 왜 이런 단순한 데이터가 "원시적인" 데이터라고 이야기 하는지 조금은 더 쉽게 이해할 수 있습니다. 그 때는 데이터 저장소(메모리)의 용량이 제한되어 변수 하나에 데이터 용량이 제한된 하나의 원시 자료형 밖에 담을 수 밖에 없었기 때문입니다.
반면 참조타입은
const colors = ['Blue', 'Green', 'Red', 'Pink']; // 사용될 수 있는 색의 종류를 담고 있습니다.
const archer = {
name: 'tyrande',
race: 'night elf',
str: 29,
dex: 49,
// ...
} // 특정 게임의 궁수(archer)의 정보를 담고 있습니다.참조 자료형은 딱 봐도 하나의 주제는 있지만 분명 서로 다르고, 여러 개의 데이터를 가지고 있는 것을 확인 할 수 있습니다.
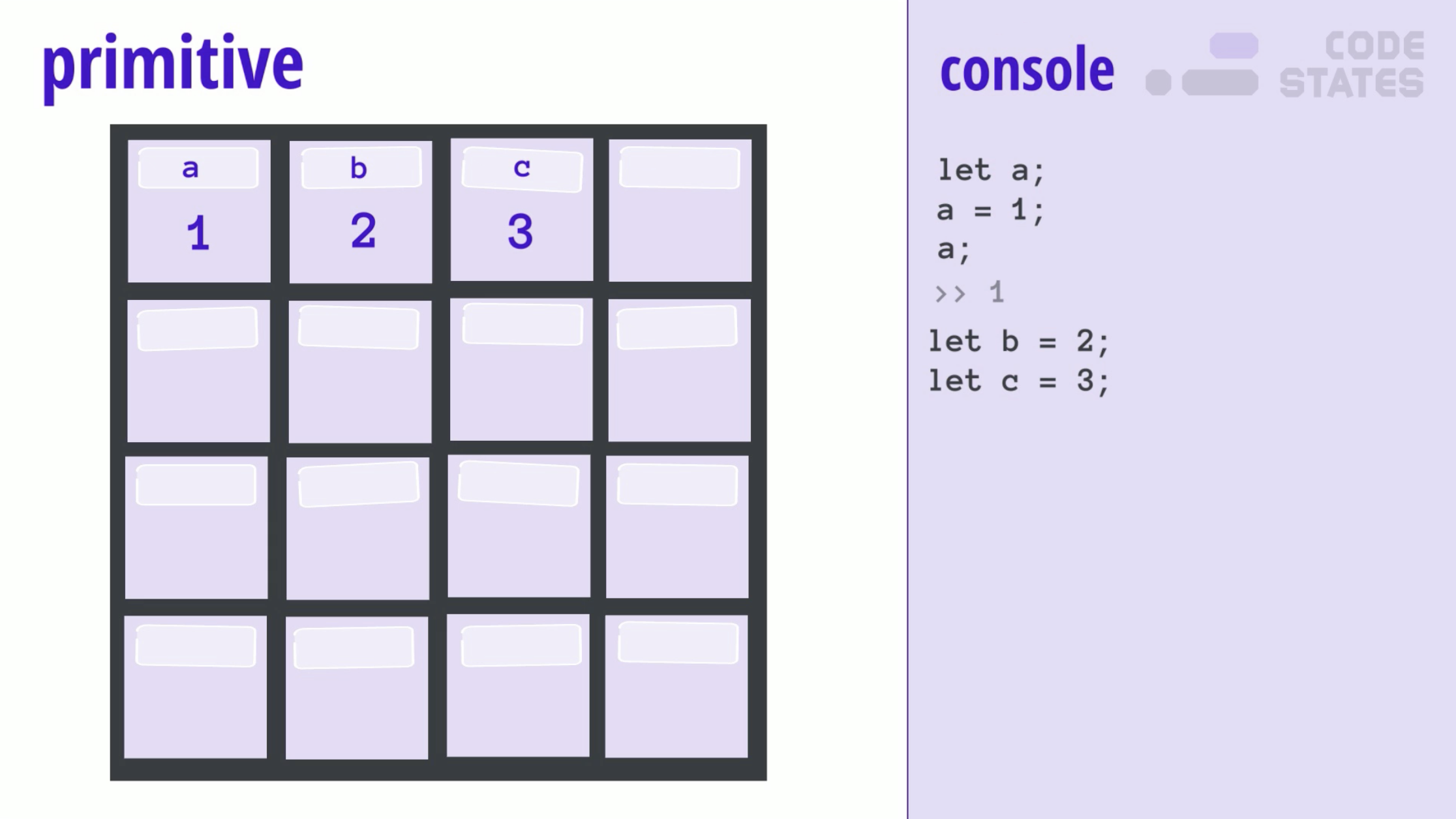 원시 자료형의 보관함인 변수에는 하나의 원시 자료형만 담을 수 있습니다. 이 특징은 참조 자료형이 보관되는 특별한 보관함과는 구분됩니다. 우리가 배웠던 참조 자료형(배열, 객체...)는 어떻게 코드를 작성하느냐에 따라 보관되는 데이터의 양이 천 개, 만 개가 될 수 있습니다. 반면에, 원시 자료형은 "하나"의 의미를 가지는 데이터임에는 변함이 없습니다. 그렇기 때문에 원시 자료형이 담기는 보관함의 크기는 고정하는 것이 합당합니다. 어느정도 일정한 크기의 데이터가 온다고 예상할 수 있기 때문입니다.
원시 자료형의 보관함인 변수에는 하나의 원시 자료형만 담을 수 있습니다. 이 특징은 참조 자료형이 보관되는 특별한 보관함과는 구분됩니다. 우리가 배웠던 참조 자료형(배열, 객체...)는 어떻게 코드를 작성하느냐에 따라 보관되는 데이터의 양이 천 개, 만 개가 될 수 있습니다. 반면에, 원시 자료형은 "하나"의 의미를 가지는 데이터임에는 변함이 없습니다. 그렇기 때문에 원시 자료형이 담기는 보관함의 크기는 고정하는 것이 합당합니다. 어느정도 일정한 크기의 데이터가 온다고 예상할 수 있기 때문입니다.
const num1 = 123;
const num2 = 123456789;이렇게 변수에는 데이터의 크기와는 관계 없이 하나의 데이터만 담을 수 있습니다.
원시 자료형은 값 자체에 대한 변경이 불가능(immutable)하지만, 변수에 다른 데이터를 할당할 수는 있습니다.
"hello world!"
"hello codestates!"
// "hello world!" 와 "hello codestates!"는 모두 변경할 수 없는 고정된 값입니다.
let word = "hello world!"
word = "hello codestates!"
// 하지만, word라는 변수에 재할당을 하여 변수에 담긴 내용을 변경은 가능합니다.
const num1 = 123;
num1 = 123456789; // 에러 발생
// const 키워드로 선언하면, 재할당은 불가합니다.그런데 변수에는 하나의 데이터만 담습니다.라는 표현은 우리가 지금까지 배운 내용과 다른 점이 있습니다.
'배열과 객체를 담았을 때는, 여러 데이터가 들어갔다가 나갔다가 하지 않았나? 하나만 못 담는데...'
참조 자료형을 변수에 할당할 때는 변수에 값이 아닌 주소를 저장합니다. 그리고 이 주소 자체와, 주소가 할당되는 과정을 우리가 눈으로 확인할 수 없기 때문에 이해하기 어렵습니다. 하지만 꼭 이해해야 합니다.
참조 자료형 깊게 이해하기
자바스크립트에서 원시 자료형이 아닌 모든 것은 참조 자료형입니다. 배열([])과 객체({}), 함수(function(){})가 대표적입니다. 이런 자료형을 자바스크립트에서는 참조 자료형(reference data type; 참조 타입)이라고도 부릅니다.
컴퓨터가 처음 사용되던 시절에는 배열, 즉 리스트라는 개념을 구현하기가 어려웠습니다. 그래서 띄어쓰기, 탭, 쉼표 등으로 데이터를 구분하여 배열과 비슷한 형태로 자료 구조를 구현하기 시작했습니다. 이 흔적은 csv에서도 찾아볼 수 있습니다. 쉼표로 구분된 데이터(comma-separated values)라는 의미죠.
10,20,30,40,50,60
이렇게 하나의 스트링을 split 하던 형식으로 사용되던 배열이 매우 자주 사용됨으로써 이제 대부분의 컴퓨터 언어에는 자바스크립트 처럼 배열(혹은 비슷한)이라는 자료 구조가 구현이 되어 있습니다. 요소의 추가, 삭제, 변경정도만 알면 쉽게 배열을 다룰 수 있게 되었습니다. 왜 따로 자료 구조를 구현해야만 했을까요? 변수에 넣을 수 있는 데이터 크기가 제한되기 때문입니다.
문자열의 길이가 100 이상인 경우 변수에 저장할 수 없다고 가정을 한다면, 위와 같은 배열의 요소는 34개 이상이 될 수 없습니다. 34개 이상인 경우 또 새로운 array를 만들고... 그 array의 맨 끝까지 찾으면 다시 다음 array를 찾고... 아주 번거로운 작업이 되었습니다. 이후에 linked list 자료구조에 대해서 공부하게 되신다면, 실제 push, pop, indexOf 와 같은 작업이 얼마나 귀찮은 작업인지 몸소 느끼게 됩니다.
 이런 이유로 "데이터의 크기가 동적으로 변하는" 특별한 데이터 보관함이 필요해졌습니다.
이런 이유로 "데이터의 크기가 동적으로 변하는" 특별한 데이터 보관함이 필요해졌습니다.
참조 자료형이 저장되는 특별한 데이터 보관함
참조 자료형에는 하나의 데이터가 아닌 여러 데이터가 담기게 됩니다. 그래서 참조 자료형의 데이터 자체는 지금까지 배웠던 원시 자료형이 보관되는 데이터 보관함이 아닌 특별한 데이터 보관함에 저장됩니다. 이 데이터가 위치한 곳(메모리 상 주소)을 가리키는 주소가 변수에 저장됩니다. 즉, 변수에는 특별한 데이터 보관함을 찾아갈 수 있는 주소가 담겨있고, 이 주소를 따라가보면 특별한 데이터 보관함을 찾을 수 있는데, 이 특별한 데이터 보관함에서는 자기 마음대로 사이즈를 늘렸다가 줄였다가 합니다. ("동적(dynamic)으로 변한다"라고 하기도 합니다.) 이처럼 데이터는 별도로 관리되고, 우리가 직접 다루는 변수에는 주소가 저장되기 때문에 reference type이라고 불립니다. 이런 특별한 데이터 보관함을 heap이라고도 부릅니다.
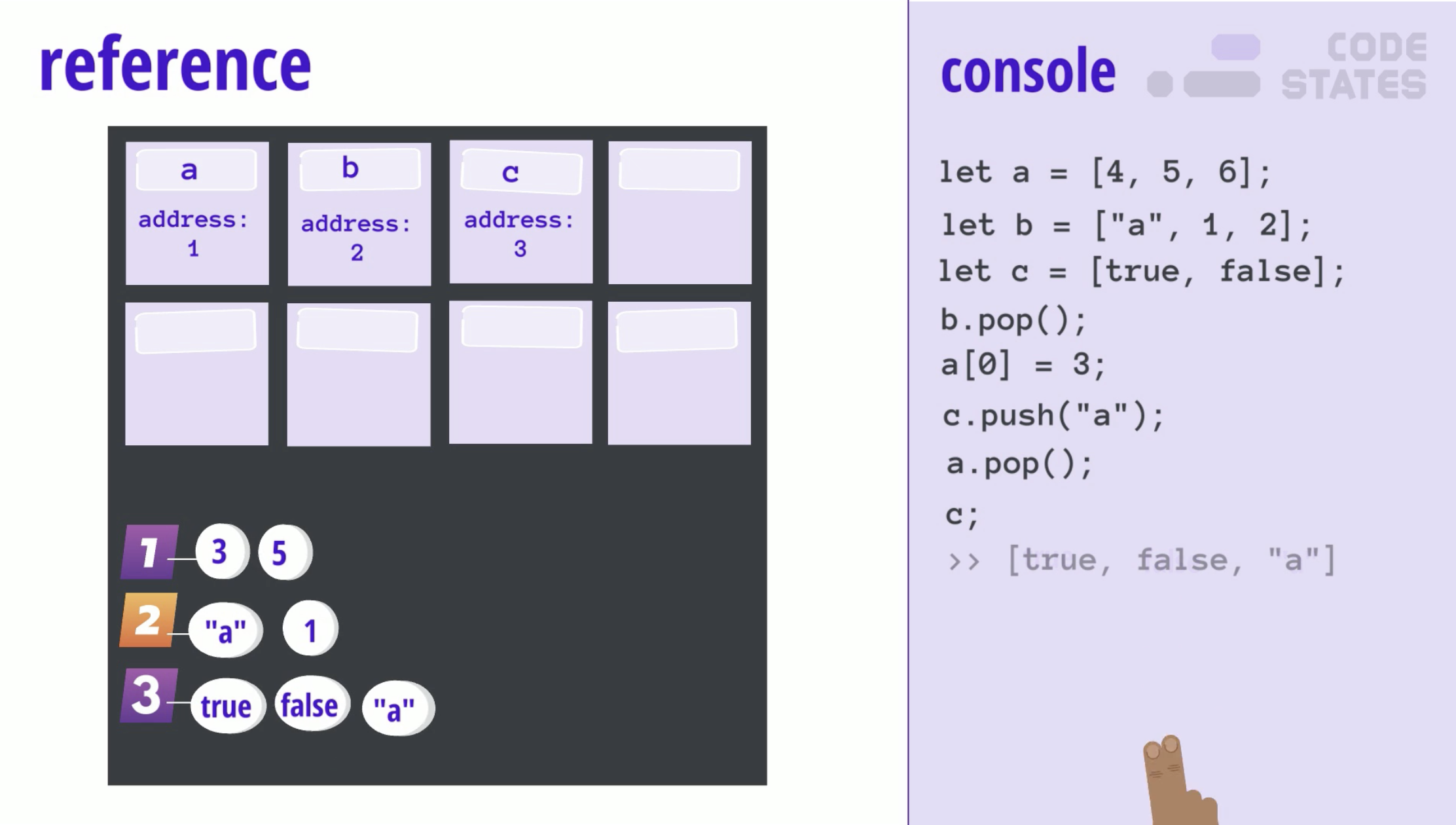 우리가 흔히 참고자료를 찾을 때, 레퍼런스(reference)를 찾는다고 종종 이야기합니다. 이 레퍼런스라는 단어는 본래 참조할 만한 자료라는 영어 단어로 실생활에서 자주 쓰이지만, 컴퓨터 공학에서는 변수가 가리키고(refer)있는 데이터의 참조한다는 의미로 사용됩니다. 읽는 것이 아니라, 그 변수의 주소를 "참조"하여 실제 변수가 있는 장소에 어떤 데이터가 있는지 도착하고 나서야 비로소 "읽을 수" 있기 때문입니다.
우리가 흔히 참고자료를 찾을 때, 레퍼런스(reference)를 찾는다고 종종 이야기합니다. 이 레퍼런스라는 단어는 본래 참조할 만한 자료라는 영어 단어로 실생활에서 자주 쓰이지만, 컴퓨터 공학에서는 변수가 가리키고(refer)있는 데이터의 참조한다는 의미로 사용됩니다. 읽는 것이 아니라, 그 변수의 주소를 "참조"하여 실제 변수가 있는 장소에 어떤 데이터가 있는지 도착하고 나서야 비로소 "읽을 수" 있기 때문입니다.
특별한 데이터 보관함이 동적으로 크기가 변하게 되는 이유
배열과 객체는 대량의 데이터를 쉽게 다루기 위해서 사용됩니다. 쉽게 사용할 수 있는 이유는 크기가 고정되어 있지 않고 우리가 데이터를 추가하고 삭제하는 것에 따라서 크기가 달라지기 때문입니다. 그렇다면, 100만개의 데이터가 들어올 수 있는 상황에서 고정된 데이터 공간을 사용하는 것이 합당할까요? 아닙니다. 대량의 데이터가 들어오는 경우는 동영상에서 설명드린 바와 같이, 고정된 데이터 공간을 사용하는 것이 비효율적입니다.
 그렇기 때문에, 크기가 상황에 따라서 커졌다가 작아지는 특별한 데이터 저장소를 만들어 사용하기로 합의했습니다. 데이터가 언제 늘어나고 줄어들지 모르기 때문에 별도의 저장공간을 마련하여 따로 관리하는 것입니다. 변수에는 원시값 혹은 주소만 지정할 수 있고, 주소는 크기가 변하는 특별한 데이터 저장소를 참조하게 되는 것이죠.
그렇기 때문에, 크기가 상황에 따라서 커졌다가 작아지는 특별한 데이터 저장소를 만들어 사용하기로 합의했습니다. 데이터가 언제 늘어나고 줄어들지 모르기 때문에 별도의 저장공간을 마련하여 따로 관리하는 것입니다. 변수에는 원시값 혹은 주소만 지정할 수 있고, 주소는 크기가 변하는 특별한 데이터 저장소를 참조하게 되는 것이죠.
스코프
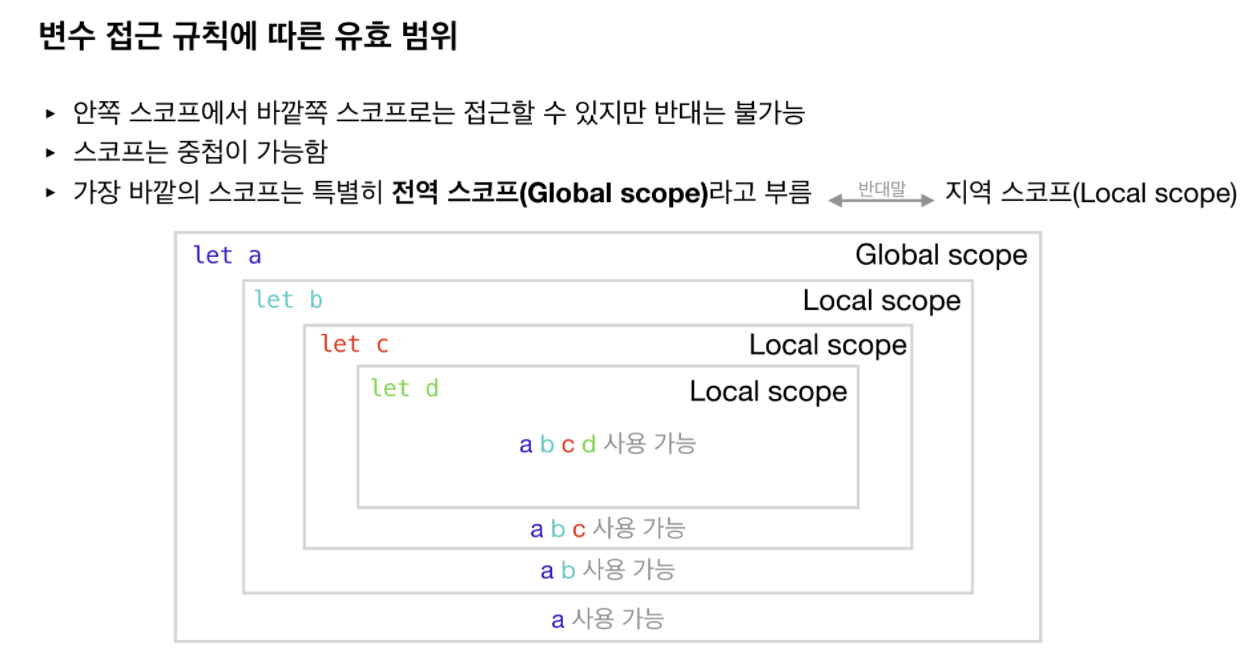
Scope는 무엇일까요? 원래 영어 단어 자체는 범위라는 의미를 가집니다. 컴퓨터 공학, 그리고 자바스크립트에서의 스코프도 "범위"의 의미를 가지고 있습니다. 더 자세하게는 "변수의 유효범위"로 사용됩니다.
변수 접근 범위


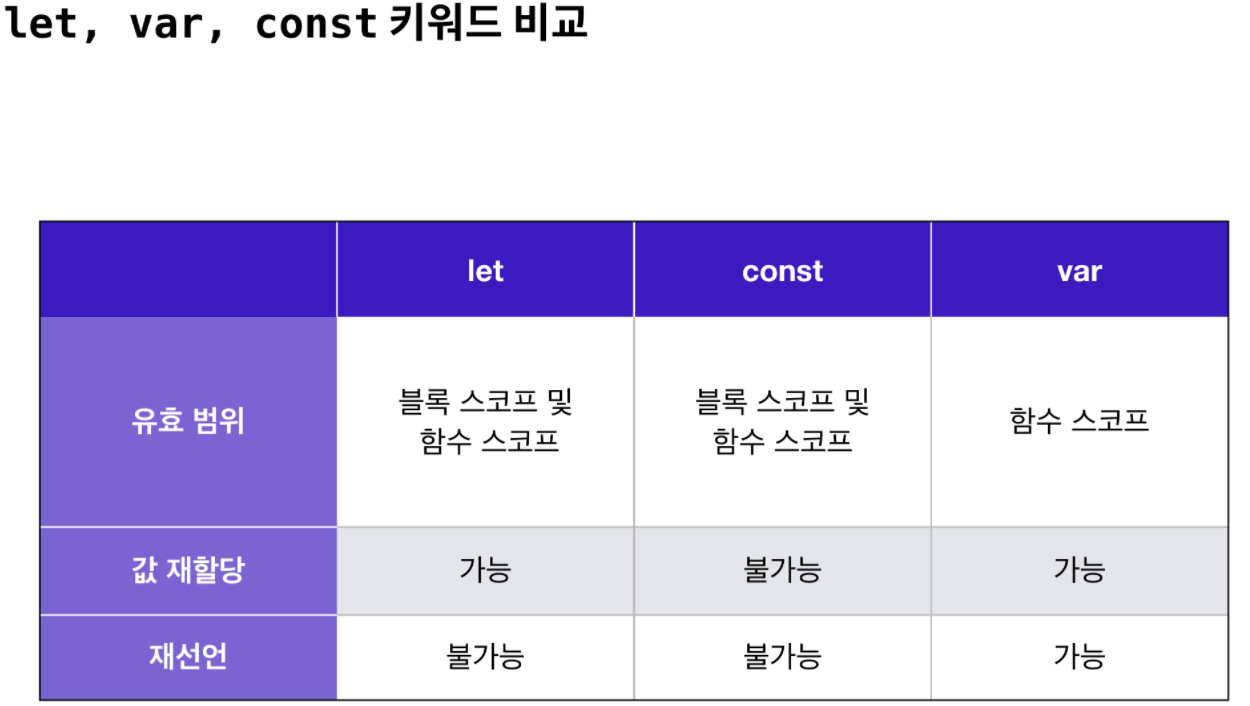
스코프의 종류와 let, const, var 키워드
 먼저 스코프는 두 가지 종류가 있습니다. 하나는 블록 스코프(block scope)라고 부르며, 중괄호를 기준으로 범위가 구분됩니다.
먼저 스코프는 두 가지 종류가 있습니다. 하나는 블록 스코프(block scope)라고 부르며, 중괄호를 기준으로 범위가 구분됩니다.
 또 다른 스코프 종류로는 함수 스코프(function scope)가 있습니다. function 키워드가 등장하는 함수 선언식 및 함수 표현식은 함수 스코프를 만듭니다.
또 다른 스코프 종류로는 함수 스코프(function scope)가 있습니다. function 키워드가 등장하는 함수 선언식 및 함수 표현식은 함수 스코프를 만듭니다.
 여기서 한가지 유의해야 할 점이 있습니다.
여기서 한가지 유의해야 할 점이 있습니다.
화살표 함수는 블록 스코프로 취급됩니다. 함수 스코프가 아닙니다.
함수 스코프와 블록 스코프는 논리적인 구분 외에도 코드를 작성할 때 기억해야 할 다른 점이 몇 가지 존재합니다.
 변수를 정의하는 방법은 let 외에도 var 키워드를 사용하는 방법이 있습니다.
변수를 정의하는 방법은 let 외에도 var 키워드를 사용하는 방법이 있습니다.
var 키워드로 정의한 변수는 블록 스코프를 무시하고, 함수 스코프만 따릅니다. 그러나, 모든 블록 스코프를 무시하는 건 아닙니다. 화살표 함수의 블록 스코프는 무시하지 않습니다.
함수 스코프는 함수의 실행부터 종료까지이고, var 선언은 함수 스코프의 최상단에 선언됩니다.선언 키워드 없는 선언은 최고 스코프에 선언됩니다.
함수 내에서 선언 키워드 없는 선언은, 함수의 실행 전까지 선언되지 않은 것으로 취급합니다.
보통 코드를 작성할 때 블록은 들여쓰기가 적용되고, 그 구분이 시각적으로 분명합니다. 따라서 많은 사람들은 블록 스코프를 기준으로 코드를 작성하고, 생각하기 마련입니다. 그러나 var는 이 규칙을 무시하므로, 코드를 작성하는 사람이 블록 스코프/함수 스코프에 대한 이해가 없으면 코드가 다소 혼란스러울 수 있습니다.
따라서, var 보다는 let 으로 변수 선언을 하는 것을 권장합니다.
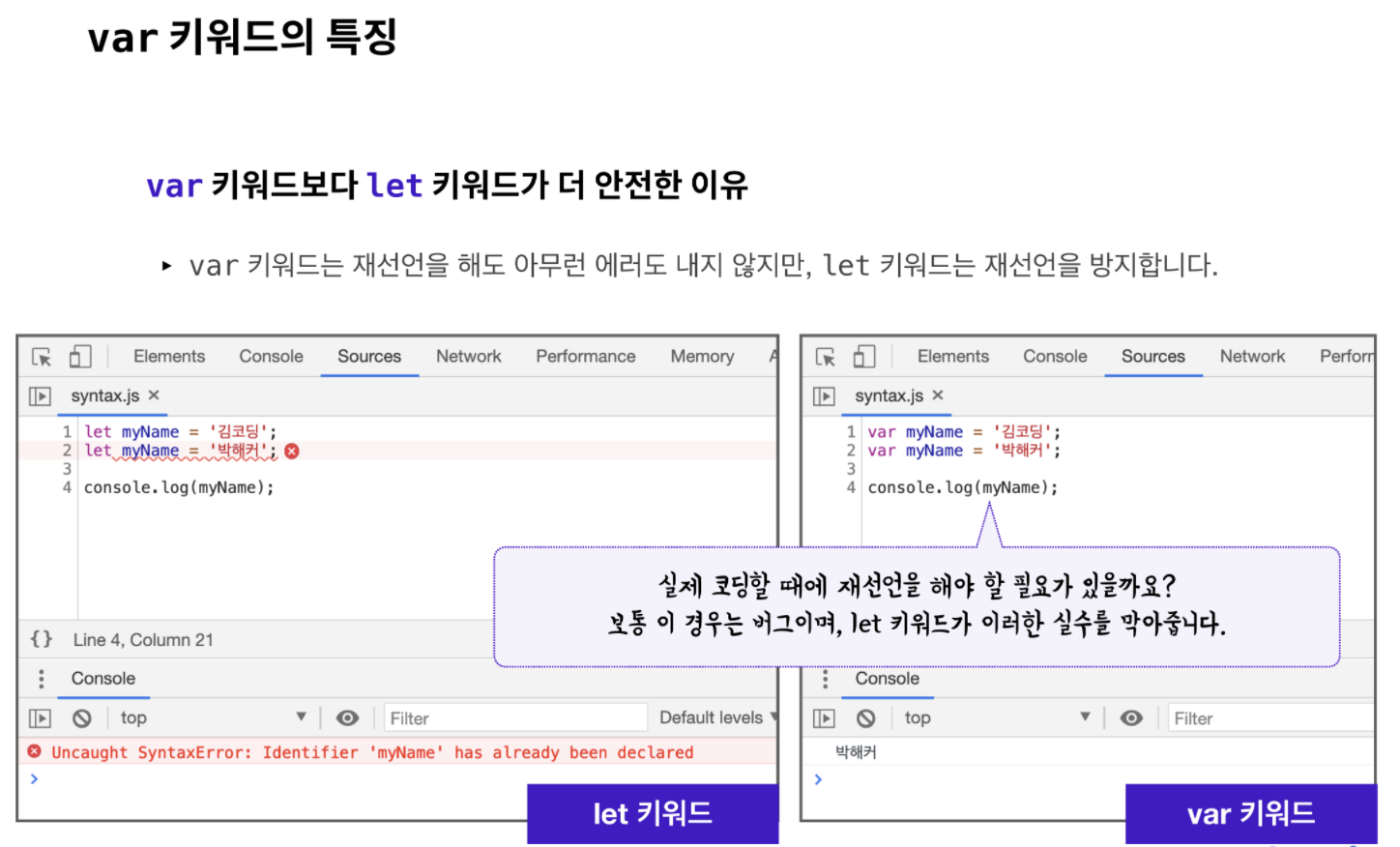 var 키워드보다 let 키워드가 안전한 이유는 또 있습니다.
var 키워드보다 let 키워드가 안전한 이유는 또 있습니다.
let 키워드는 재선언을 방지합니다. 실제로 코딩할 때에 변수를 재선언해야 할 필요가 있을까요? 대부분 이런 경우는 버그입니다.
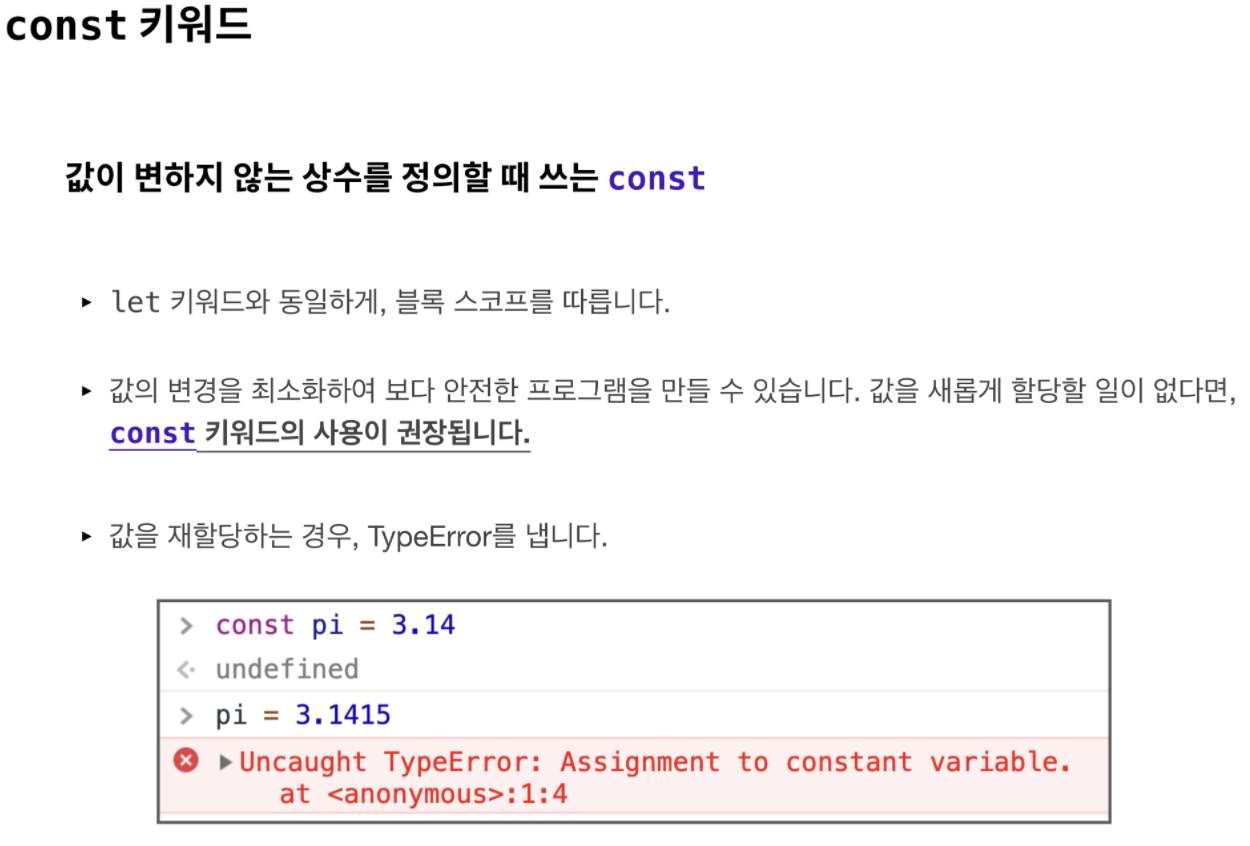 const 라는 키워드도 있습니다. 변하지 않는 값, 곧 상수(constant)를 정의할 때에는 const를 이용합니다.
const 라는 키워드도 있습니다. 변하지 않는 값, 곧 상수(constant)를 정의할 때에는 const를 이용합니다.
const는 값의 재할당이 불가능합니다. 값을 재할당할 경우 TypeError를 내므로, 의도하지 않은 값의 변경을 막을 수 있습니다.
클로저
자바스크립트에서는 다른 컴퓨터 언어와는 조금 다른 특성을 종종 가지고 있습니다. 그 중 종종 사용되는 클로저라는 개념에 대해서 알아보겠습니다. MDN에서의 클로저 정의에 따르면, 다음과 같습니다.
"함수와 함수가 선언된 어휘적(lexical) 환경의 조합을 말한다. 이 환경은 클로저가 생성된 시점의 유효 범위 내에 있는 모든 지역 변수로 구성된다."
여기서 주목할 만한 키워드는 "함수가 선언"된 "어휘적(lexical) 환경"입니다. 특이하게도 자바스크립트는 함수가 호출되는 환경과 별개로, 기존에 선언되어 있던 환경 - 어휘적 환경 - 을 기준으로 변수를 조회하려고 합니다. "외부함수의 변수에 접근할 수 있는 내부함수"를 클로저 함수로 부르는 이유도 그렇습니다.
 클로저 함수는 위와 비슷한 모양을 갖고 있습니다. 이를 통해 알아볼 수 있는 첫번째 특징은, 클로저 함수는 "함수를 리턴하는 함수" 라는 점입니다. 함수를 리턴하는 함수가 클로저의 형태를 만듭니다.
클로저 함수는 위와 비슷한 모양을 갖고 있습니다. 이를 통해 알아볼 수 있는 첫번째 특징은, 클로저 함수는 "함수를 리턴하는 함수" 라는 점입니다. 함수를 리턴하는 함수가 클로저의 형태를 만듭니다.
 클로저는 리턴하는 함수에 의해 스코프(변수의 접근 범위)가 구분됩니다. 클로저의 핵심은 스코프를 이용해서, 변수의 접근 범위를 닫는(closure; 폐쇄) 데에 있습니다. 따라서, 함수를 리턴하는 것만큼이나, 변수가 선언된 곳이 중요합니다.
클로저는 리턴하는 함수에 의해 스코프(변수의 접근 범위)가 구분됩니다. 클로저의 핵심은 스코프를 이용해서, 변수의 접근 범위를 닫는(closure; 폐쇄) 데에 있습니다. 따라서, 함수를 리턴하는 것만큼이나, 변수가 선언된 곳이 중요합니다.
 앞서 본 예제에서는 변수 x와 y가 선언된 곳이 각기 다릅니다. x가 선언된 함수는 바깥쪽에 있으니 '외부 함수'라고 부릅시다.
앞서 본 예제에서는 변수 x와 y가 선언된 곳이 각기 다릅니다. x가 선언된 함수는 바깥쪽에 있으니 '외부 함수'라고 부릅시다.
 그리고 y가 선언된 함수는 보다 안쪽에 있으니 '내부 함수'라고 부릅시다. 따라서, 이 클로저 함수는 스코프가 분리되어 있습니다.
그리고 y가 선언된 함수는 보다 안쪽에 있으니 '내부 함수'라고 부릅시다. 따라서, 이 클로저 함수는 스코프가 분리되어 있습니다.

 이를 통해 알아볼 수 있는 클로저 함수의 두번째 특징은 "내부 함수는 외부 함수에 선언된 변수에 접근 가능하다"는 점입니다.
이를 통해 알아볼 수 있는 클로저 함수의 두번째 특징은 "내부 함수는 외부 함수에 선언된 변수에 접근 가능하다"는 점입니다.
클로저의 활용
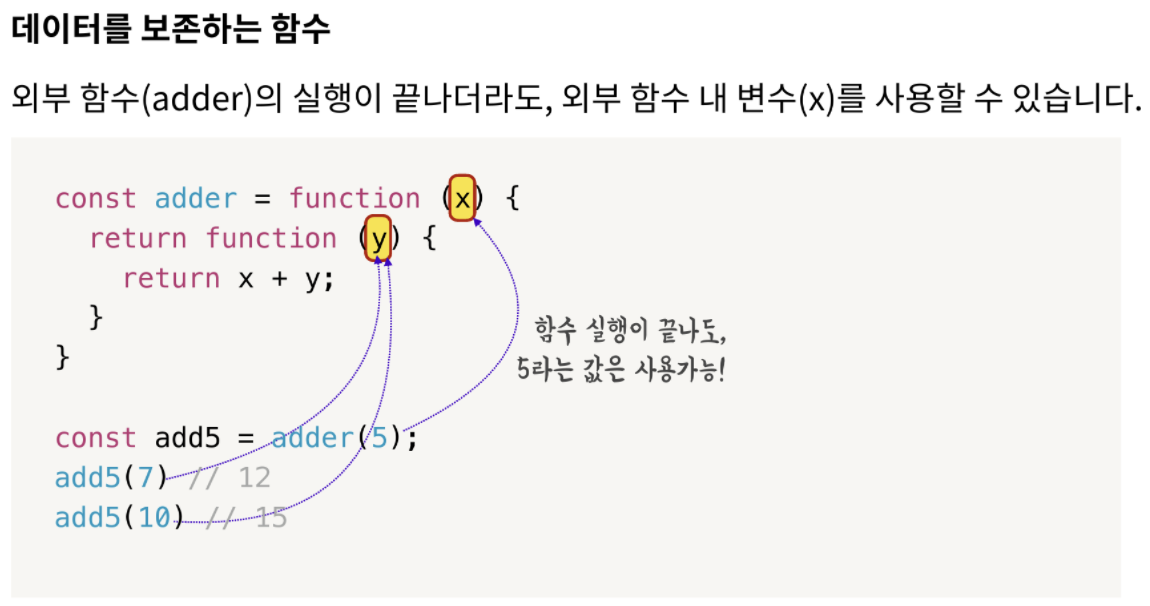
 일반적인 함수는, 함수 실행이 끝나고 나면 함수 내부의 변수를 사용할 수 없습니다. 이와 다르게, 클로저는 외부 함수의 실행이 끝나더라도, 외부 함수 내 변수가 메모리 상에 저장됩니다. (어휘적 환경을 메모리에 저장하기 때문에 가능한 일입니다)
일반적인 함수는, 함수 실행이 끝나고 나면 함수 내부의 변수를 사용할 수 없습니다. 이와 다르게, 클로저는 외부 함수의 실행이 끝나더라도, 외부 함수 내 변수가 메모리 상에 저장됩니다. (어휘적 환경을 메모리에 저장하기 때문에 가능한 일입니다)
변수 add5 에는 클로저를 통해 리턴한 함수가 담겨 있습니다. add5 는 재미있게도, adder함수에서 인자로 넘긴 5라는 값을 x 변수에 계속 담은 채로 남아있습니다. 외부 함수의 실행이 끝났음에도 말이죠.
 다음은 클로저를 이용해 HTML 문자열을 만드는 예제입니다.
다음은 클로저를 이용해 HTML 문자열을 만드는 예제입니다.
예제에서 divMaker 함수는 'div'라는 문자열을 tag 라는 변수에 담아두고 있으며, anchorMaker 함수는 'a'라는 문자열을 tag에 담아두고 있습니다.
클로저는 이처럼 특정 데이터를 스코프 안에 가두어 둔 채로 계속 사용할 수 있게 해줍니다.
 다음은 '클로저 모듈 패턴'이라고 불리는 아주 유용한 패턴입니다.
다음은 '클로저 모듈 패턴'이라고 불리는 아주 유용한 패턴입니다.
 makeCounter 함수는 increase, decrease, getValue메소드를 포함한 객체 하나를 리턴합니다. 따라서, counter1은 객체입니다.
makeCounter 함수는 increase, decrease, getValue메소드를 포함한 객체 하나를 리턴합니다. 따라서, counter1은 객체입니다.
 이것이 바로 정보의 접근 제한 (캡슐화) 입니다.
이것이 바로 정보의 접근 제한 (캡슐화) 입니다.
왜 이렇게 하는 것일까요? 만일 스코프로 value 값을 감싸지 않았더라면, value 값은 전역 변수여야만 했을 것입니다. 하지만 makeCounter라는 함수가 value 값을 보존하고 있기 때문에, 전역 변수로 따로 만들 필요가 없습니다.
전역 변수가 좋지 않은 이유는, 전역 변수는 다른 함수 혹은 로직 등에 의해 의도되지 않은 변경을 초래하기 때문입니다. 이를 side effect라고 합니다. side effect를 최소화하면, 의도되지 않은 변경을 줄일 수 있습니다. 따라서 이에 따른 오류로부터 보다 안전하게 값을 보호할 수 있습니다.
클로저를 통해 불필요한 전역 변수 사용을 줄이고, 스코프를 이용해 값을 보다 안전하게 다룰 수 있습니다.
 이와 같이 함수 재사용성을 극대화하여, 함수 하나를 완전히 독립적인 부품 형태로 분리하는 것을 모듈화라고 합니다.
이와 같이 함수 재사용성을 극대화하여, 함수 하나를 완전히 독립적인 부품 형태로 분리하는 것을 모듈화라고 합니다.
클로저를 통해 데이터와 메소드를 같이 묶어서 다룰 수 있습니다. 즉, 클로저는 모듈화에 유리합니다.
