
🍴 개념
🥛 K-Nearest Neighbors (K-NN) 알고리즘이란?
K-Nearest Neighbors(K-NN)은 K-최근접 이웃 알고리즘이라고도 한다. K-NN은 지도 학습(Supervised Learning) 알고리즘 중 하나로, 데이터 간 거리를 기반으로 분류(Classification)나 회귀(Regression) 문제를 해결하는 데 사용된다. 이 알고리즘은 간단하고 직관적인 방법으로 데이터를 분류하거나 예측하는 데 효과적이다.
🥛 작동 원리
K-NN은 간단한 아이디어를 기반으로 한다.
K-최근접 이웃 알고리즘이라는 단어에서 알 수 있듯이, KNN은 서로 가까이 있는 모든 데이터 포인트가 동일한 클래스에 속한다는 원칙에 따라 작동하는 지도 학습 알고리즘이다. 여기서 기본 가정은 서로 가까이 있는 것들은 서로 같다는 것이다.
주요 개념
- 거리 측정 방법: K-NN은 데이터 간 거리를 측정하여 이웃을 찾는다. 유클리디안 거리(Euclidean distance)가 일반적으로 사용되지만, 맨하탄 거리(Manhattan distance)나 코사인 유사도(Cosine similarity) 등 다양한 거리 측정 방법을 사용할 수 있다.
- 이웃의 수(K): K-NN에서는 새로운 데이터 포인트 주변의 K개의 이웃을 선택한다. K의 값에 따라 모델의 성능이 달라질 수 있으며, 적절한 K 값을 선택하는 것이 중요하다.
- 가중치: 이웃 데이터 포인트의 거리에 따라 가중치를 부여하여 예측을 수행할 수 있다. 가중치를 사용하면 가까운 이웃의 의견에 더 큰 영향을 받게 된다.
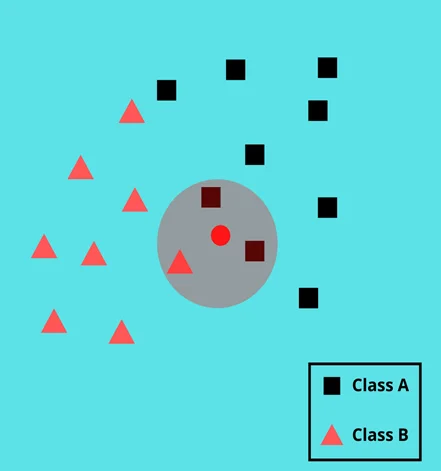
KNN의 가장 중요한 단계는 Nearest Neighbors의 수를 나타내는 'K' 값을 정의하는 것이다.
위 사진과 같이 데이터셋 내의 각각의 데이터는 특성 공간상의 점으로 나타낼 수 있다. 만약, K값이 3이라면 그 주변의 3개의 가장 가까운 이웃 데이터들을 찾아서 데이터들의 레이블을 분류하거나 예측하는 방법이다.
🥛 장단점
장점
- 간단하고 이해하기 쉬운 알고리즘이다.
- 훈련 과정이 없어 새로운 데이터에 대한 예측이 빠르다.
- 다목적으로 사용될 수 있으며, 회귀와 분류 모두에 적용 가능하다.
- 데이터에 대한 가정이 없다. 추가 가정을 하거나 모델을 구축할 필요가 없다.
단점
- 대규모 데이터셋에 대해 계산 비용이 많이 들 수 있다.
- 특성이 많거나 스케일이 다른 경우에는 성능이 저하될 수 있다.
🥛 적용 분야
- 이미지 분류
- 추천 시스템
- 의료 진단
- 텍스트 분류
- 사용자 행동 인식 (Activity Recognition)
- 자율 주행 자동차
- 보안 및 침입 탐지
- 환경 모니터링
- 자원 할당 및 예측
- 유전자 분류 및 유전체 학습
K-NN은 다양한 분야에서 사용되며, 그 유연성과 단순함으로 인해 많은 문제에 적용될 수 있다. 이 알고리즘은 특히 작은 데이터셋에서 효과적이며, 유사성에 기반하여 패턴을 찾고 분류하는 데 강점을 보인다.
🥩 실습
아래는 K-NN 알고리즘을 사용하여 Iris 데이터셋을 분류하고 시각화하는 예제 코드이다.이 코드를 통해 데이터 분포와 K-NN의 작동 방식을 시각적으로 확인해볼 수 있다.
🧂 코드 예제
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
# 데이터 로드
iris = load_iris()
X = iris.data[:, :2] # 처음 두 개의 특성만 사용 (시각화를 위해)
y = iris.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 모델 초기화 및 학습
knn = KNeighborsClassifier(n_neighbors=3) # 이웃의 수 K를 3으로 설정
knn.fit(X_train, y_train)
# 예측
y_pred = knn.predict(X_test)
# 평가
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f'정확도: {accuracy:.4f}')
print('분류 보고서:\n', report)
# 시각화를 위한 그리드 생성
h = 0.02 # 메쉬의 단위
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# 결정 경계 시각화
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(8, 6))
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
# 훈련 데이터와 테스트 데이터 그리기
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cmap_bold, edgecolor='k', s=60)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cmap_bold, marker='x', s=80)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("3-Class classification (k = 3)")
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.show()🧂 코드 리뷰
- Iris 데이터셋을 로드하고, 처음 두 개의 특성만을 사용하여 데이터를 준비한다. (2차원 시각화를 위해)
KNeighborsClassifier를 사용하여 K-NN 분류기를 초기화하고 학습시킨다. 여기서는 이웃의 수 K를 3으로 설정한다.predict()함수를 사용하여 테스트 데이터에 대한 예측을 수행하고,accuracy_score()와classification_report()함수를 사용하여 모델의 성능을 평가한다.matplotlib을 사용하여 결정 경계를 시각화하고, 훈련 데이터와 테스트 데이터를 플롯한다. 이를 통해 모델이 어떻게 분류하는지 시각적으로 확인할 수 있다.
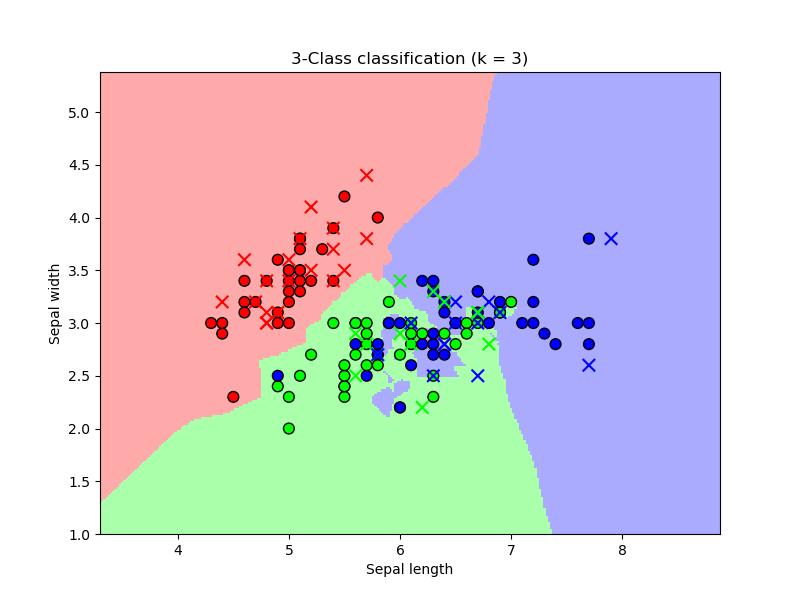
결정 경계를 통해 각 클래스의 분포와 K-NN 알고리즘이 어떻게 데이터를 분류하는지 시각적으로 확인할 수 있다. 이를 통해 K-NN의 작동 방식을 더 잘 이해할 수 있다.
K-NN 알고리즘은 간단하면서도 유용한 알고리즘이지만, 데이터의 특성과 문제에 따라 성능이 달라질 수 있다. 적절한 K 값을 선택하고 데이터를 잘 이해하여 사용하는 것이 중요하다.
