
🥄 로지스틱 회귀란?
로지스틱 회귀(Logistic Regression)란, 주로 분류 문제에 사용되는 회귀 알고리즘 중 하나이다. 이름은 회귀라는 단어가 포함되어 있지만, 실제로는 분류 알고리즘과 더 가깝다고 할 수 있다. 실제로 결과 값을 예측하는 것이 아니라 값을 분류하는데 쓰이기 때문이다.
로지스틱 회귀는 주로 이진 분류(binary classification)에 사용되며, 예측하려는 대상이 두 개의 클래스 중 하나에 속하는지를 예측한다. 하지만 여러 개의 클래스를 분류하는 다중 클래스(multiclass) 로지스틱 회귀도 있다.
딥러닝 알고리즘에서 로지스틱을 쓰고있기 때문에 로지스틱은 중요한 개념이다.
🍱 로지스틱 회귀 이해 해보기
로지스틱은 Odds Ratio(오즈비) -> Logit 변환 -> Sigmoid 함수 -> Logistic 함수 라는 과정을 거치며 설명된다.
1. Odds Ratio(오즈비)
오즈비란, 특정 사건이 발생할 확률과 발생하지 않을 확률의 비율을 나타내는 통계적 지표이다. 오즈비는 승산비라고 불리기도 한다. 오즈비를 통해 성공확률이 실패확률에 비해 몇배 더 높은가를 나타낼 수 있다. 오즈비는 오즈와 정규분포를 연결하는 연결고리가 된다.
오즈비의 수식은 다음과 같다.
확률과 오즈의 관계
| p | 0% | 10% | 50% | 90% | 100% |
|---|---|---|---|---|---|
| odds | 0 | 0.11 | 1 | 9 | ∞ |
오즈비는 각 독립 변수의 계수(coefficients)에 대응되며, 이 계수들은 오즈비의 변화와 관련된다. 로지스틱 회귀의 결과를 해석할 때, 독립 변수의 계수들은 해당 변수가 결과에 미치는 영향의 크기와 방향을 보여준다.
2. Logit 변환
오즈비를 확률로 변환하기 위해 Logit 변환이 사용된다. logit변환이란, 오즈비에 로그를 씌우 것이다. logit변환을 하면, 오즈비가 정규분포 형태의 값이 나와서 크기를 판단할 수 있게 된다.
이 변환을 통해 선형 회귀 모델처럼 수식을 통해 예측을 할 수 있게 된다.
원하는 비율 0 0.5 1(근사)
오즈(p/1-p) 0 1 무한대
로그오즈비 -무한대 0 무한대
| 원하는 비율 | 0 | 0.5 | 1(근사) |
|---|---|---|---|
| 오즈 | 0 | 1 | ∞ |
| 로그오즈비 | -∞ | 0 | ∞ |
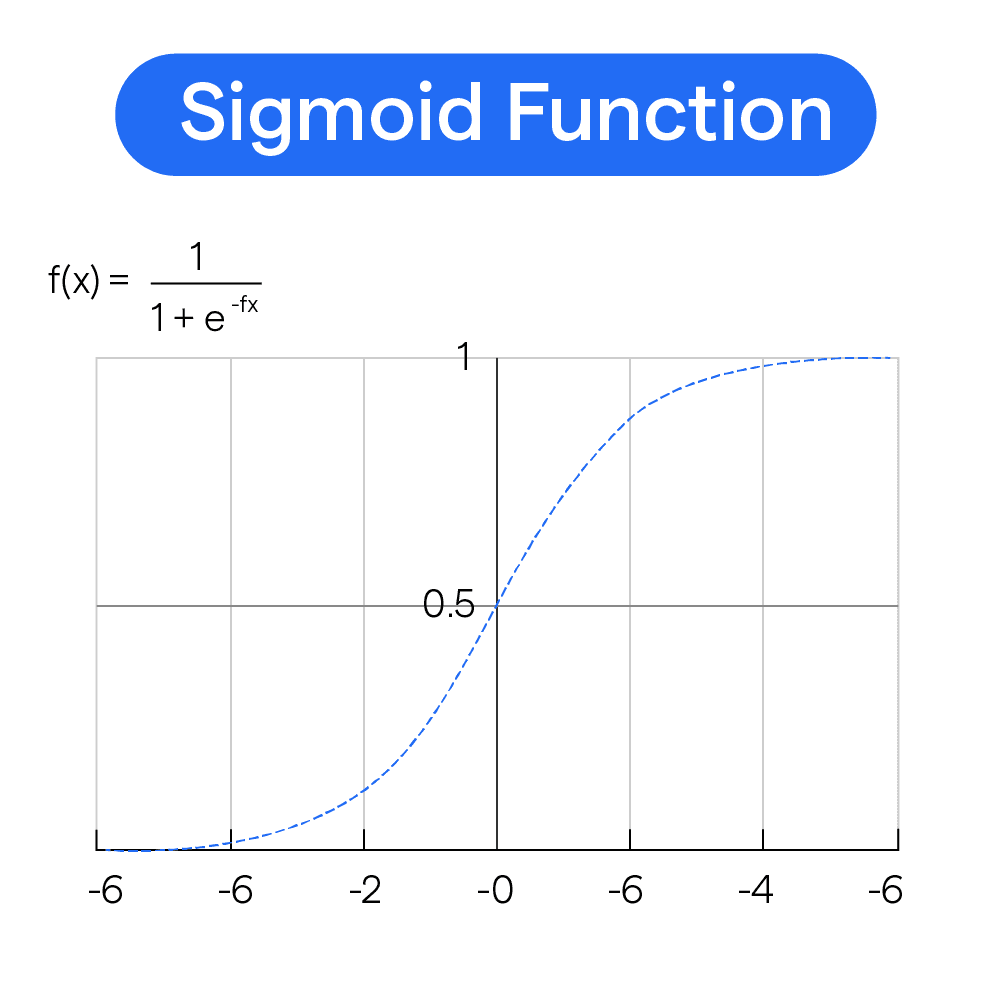
3. Sigmoid 함수
Sigmoid 함수란, S자 형태의 곡선이다. sigmoid라는 단어 자체가 S자 모양을 뜻한다. 거의 평탄한 기울기를 지니고, 양 끝에서 중심으로 올수록 기울기가 가팔라지는 특징이 있다. 0.5를 기준으로 커브를 그린다.
Logit 변환된 값(로그오즈비)은 선형적인 값을 가진다. 이를 다시 원래의 확률 값으로 변환하기 위해 Sigmoid 함수를 사용한다. 이 함수는 로 표현되며, 입력된 값을 0과 1 사이의 값으로 압축하여 이진 분류를 위한 확률로 해석할 수 있게 한다.
y축은 주어진 입력에 대해 모델이 해당 클래스에 속할 확률을 나타내는 것으로 해석될 수 있다.
함수 값이 0에 가까워질수록 해당 모델이 해당 클래스에 속할 확률이 낮아지고, 1에 가까워질수록 해당 클래스에 속할 확률이 높아진다. 예를 들어, 이진 분류에서 시그모이드 함수를 사용하면 0에 가까운 값은 '클래스 0에 속할 확률이 낮다'는 것을 의미하고, 1에 가까운 값은 '클래스 1에 속할 확률이 높다'는 것을 나타낸다.
따라서 시그모이드 함수의 출력값이 0에 가까워지거나 1에 가까워질수록 모델이 분류를 더 확신하고 있다고 생각할 수 있습니다.
4. Logistic 함수
Sigmoid 함수와 동일한 역할을 하는 함수이다. 이 함수는 종종 로지스틱 회귀 모델의 출력을 나타내는데 사용된다. 예측된 값은 해당 클래스에 속할 확률로 해석될 수 있다.
로지스틱 회귀는 주로 이러한 과정을 거쳐 확률 값을 예측하고, 이진 분류 문제에 적용된다. 이러한 변환 과정을 통해 선형 회귀 모델을 확률 값을 출력할 수 있는 이진 분류 모델로 변환하는 것이 로지스틱 회귀의 핵심 아이디어 중 하나이다.
🧃 로지스틱 실습하기
1. 이항 분류
🔎 코드 예제
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 데이터 불러오기
iris = load_iris()
X = iris.data
y = iris.target
# 이진 분류를 위해 클래스 0과 나머지 클래스를 결합
y_binary = (y != 0) * 1
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y_binary, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 생성
model = LogisticRegression()
# 모델 훈련
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 정확도 평가
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 분류 보고서 출력
print(classification_report(y_test, y_pred))🔎 코드 리뷰
1. 데이터 불러오기 및 전처리 : Iris 데이터를 불러온 후, 이진 분류를 위해 클래스 0과 나머지 클래스를 결합하여 새로운 이진 분류 데이터를 만들었습니다.
2. 데이터 분할 : train_test_split 함수를 사용하여 데이터를 훈련 및 테스트 세트로 분할한다.
3. 로지스틱 회귀 모델 생성 : LogisticRegression 클래스를 사용하여 로지스틱 회귀 모델을 정의한다.
4. 모델 훈련 : fit 메서드를 사용하여 모델을 훈련시킨다.
5. 예측 및 성능 평가 : predict 메서드를 사용하여 테스트 데이터에 대한 예측을 수행하고, accuracy_score 함수를 사용하여 정확도를 계산한다. 또한, classification_report 함수를 사용하여 분류 보고서를 출력한다.
⭐ 분류 보고서를 통해 각 클래스의 정밀도(precision), 재현율(recall), F1-점수 등을 확인할 수 있다.
2. 다항 분류
로지스틱 회귀를 사용한 다중 클래스(다항) 분류 코드 예제를 작성해보겠습니다.
🔎 코드 예제
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 데이터 불러오기
iris = load_iris()
X = iris.data
y = iris.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 생성
model = LogisticRegression(multi_class='multinomial', solver='lbfgs', max_iter=1000)
# 모델 훈련
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 정확도 평가
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 분류 보고서 출력
print(classification_report(y_test, y_pred))🔎 코드 리뷰
-
데이터 불러오기: Iris 데이터를 로드하고, 특징 데이터(X)와 레이블(y)로 분할한다.
-
데이터 분할:
train_test_split함수를 사용하여 데이터를 훈련 및 테스트 세트로 분할한다. -
로지스틱 회귀 모델 생성:
LogisticRegression클래스를 사용하여 로지스틱 회귀 모델을 생성한다.multi_class매개변수는 다항 분류를 사용하기 위해 'multinomial'로 설정하고,solver매개변수는 'lbfgs'를 사용하여 최적화 알고리즘을 선택한다.max_iter는 반복 횟수를 설정한 것이다. -
모델 훈련:
fit메서드를 사용하여 모델을 훈련시킨다. -
예측 및 성능 평가:
predict메서드를 사용하여 테스트 데이터에 대한 예측을 수행하고,accuracy_score함수를 사용하여 정확도를 계산한다. 또한,classification_report함수를 사용하여 분류 보고서를 출력한다.
sklearn은 클래스명만 바꿔가면서 어떤 알고리즘을 쓸지 결정할 수 있어서 편하게 사용할 수 있다.
