
연결리스트란?
이전에 올렸던 포스팅에서 배열의 자료구조에 대해서 알아봤었습니다.
배열은 초기 선언 당시에 배열의 크기를 정확히 모르면 메모리가 낭비될 수 있다는 단점이 있습니다.
이 단점을 해결하기 위해 저장하려는 데이터들을 메모리 공간에 분산해서 할당하고 분산된 데이터들을 연결해주면 해결됩니다.
연결리스트를 만들 때 노드(Node)라는 것을 만들어서 분산된 데이터를 연결 해주게 됩니다.

이미지 출처: 인프런 '감자'님의 그림으로 쉽게 배우는 자료구조와 알고리즘(기본편)
이 노드라는 것은 구조가 매우 단순합니다. 노드는 데이터를 담는 변수 하나와 다음 데이터를 가리키는 변수 하나를 가지고 있습니다.
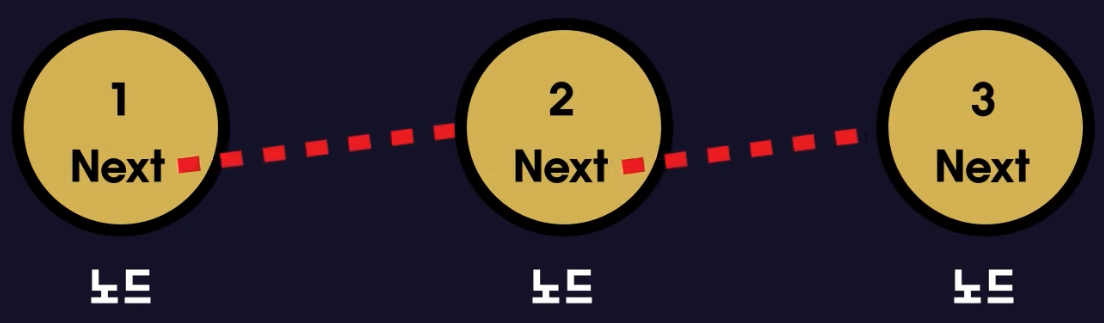
이미지 출처: 인프런 '감자'님의 그림으로 쉽게 배우는 자료구조와 알고리즘(기본편)
데이터가 필요할 때 연결리스트를 사용해서 자료구조를 짠다면 필요한 데이터만큼 노드를 만들어 데이터를 저장하고 노드 안에 있는 다음 데이터를 가리키는 변수를 통해 각 노드들을 연결하면 됩니다. 이러한 구조를 가지고 있기 때문에 연결리스트(Linked List)라고 부릅니다. 위의 이미지를 참고하시면 더욱 이해하기 쉽습니다.
연결리스트와 배열의 비교
연결리스트는 첫 노드의 주소만 알고 있으면 다른 모든 노드에 접근할 수 있습니다. 또한 연결이라는 특성 때문에 배열과는 다른 장단점을 가지고 있습니다.
- 연결리스트 장점
중간에 데이터를 추가할 때 빈 메모리 공간 아무 곳에 데이터를 생성하고 다음 가리키는 노드만 바꿔주면 되기 때문에 간단하게 작업이 가능하고 데이터의 삭제도 동일합니다. - 연결리스트 단점
연결리스트는 데이터들이 전부 떨어져 있기 때문에 바로 접근이 불가능합니다. 찾고자 하는 데이터의 위치까지 게속 타고 들어가야 하기 때문에 참조의 성능은 낮습니다.
- 배열 장점
배열은 메모리 내에서 연속된 공간안에 할당되어 있기 때문에 메모리의 시작 주소만 알면 그 뒤에 있는 데이터들을 참조하는 것이 굉장히 쉽습니다. - 배열 단점
초기에 데이터를 추가할 때 초기 크기를 알아야 하거나 배열 중간에 데이터를 추가하려면 삽입하려는 데이터 뒤에 있는 데이터들은 모두 뒤로 밀려나기 때문에 오버헤드가 많이 듭니다.
장점과 단점을 간단한 표로 정리한다면 아래와 같습니다.
| 배열 | 연결리스트 | |
|---|---|---|
| 크기 | 고정(자바스크립트는 제외) | 동적 |
| 주소 | 연속 | 불연속 |
| 데이터 참조 | O(1) | O(n) |
| 삽입과 삭제 | O(n) | O(n) |
위의 배열과 연결리스트를 비교한 내용을 토대로 항상 상황에 맞게 자료 구조를 선택해야 합니다.
예를 들어 데이터의 참조가 자주 일어나는 상황이라면 배열을 사용하면 되고, 데이터의 삽입과 삭제가 자주 일어난다면 연결리스트를 사용하는 것이 훨씬 효율적 일 것 입니다.
위의 내용은 데이터의 양이 작을 때는 차이가 많이 안 나겠지만 데이터의 양이 많아지면 많아질수록 성능의 차이는 많이 나게 됩니다.
