
[Intro]
❕What is Computer Vision?
: 시각적 세계를 해석하고 이해하도록 컴퓨터를 학습시키는 인공 지능 분야
• OCR (Optical Character Recognition) : 문서의 텍스트를 인식하고 식별.
• Vision Biometrics : 홍채 패턴 인식을 통해 사람들을 구분합니다.
• Object Recognition : 실시간의 이미지나 스캔 입력을 가지고 제품을 분류합니다.
• Special Effects : 모션 캡처 및 모양 캡처, 영화에서의 CGI.
• 3-D Printing and Image Capture : 영화, 건축 구조 등에 사용됩니다.
• Sports : 경기에서 필드에 추가 라인을 그리거나 이를 기반으로 영상 판독을 합니다.
• Social Media : 얼굴 모양에 맞추어 착용되는 이미지.
• Smart Cars : 사물과 사람을 인지할 수 있습니다.
• Medical Imaging : 3D 이미징 및 이미지 유도 수술.
본 것을 이해하는 것 = 컴퓨터 비전 연구
- 인식 능력 필요
- 사진을 찍는 것과 보는 것은 다름
- 컴퓨터에게 보는 법을 가르쳐 옴
- 세살 아이보다 인식 능력이 떨어짐
- 아이는 세 살까지 수억장의 현실세계 사진을 봄
=> 문제는 알고리즘이 아니라 데이터다.
데이터 문제의 핵심
1. 데이터의 양이 많아야 한다.
2. 데이터의 레이블이 잘 되어있어야 한다.
by 페이페이리
❕이미지 인식 발전 과정
1960’s : 간단한 Block으로 구성된 이미지를 해석
1970’s : 이미지 선택 기술과 선택된 이미지의 해석 기술 진전
- 컴퓨터에게 사물간 “계층(Layer)”을 이해시킴
- 컴퓨터에게 사물의 움직임을 이해시킴
- 컴퓨터에게 사물의 스케일을 이해시킴
2000’s : Feature의 등장
- 컴퓨터가 “특정 이미지 조각”을 가지고 분류할 수 있게 됨
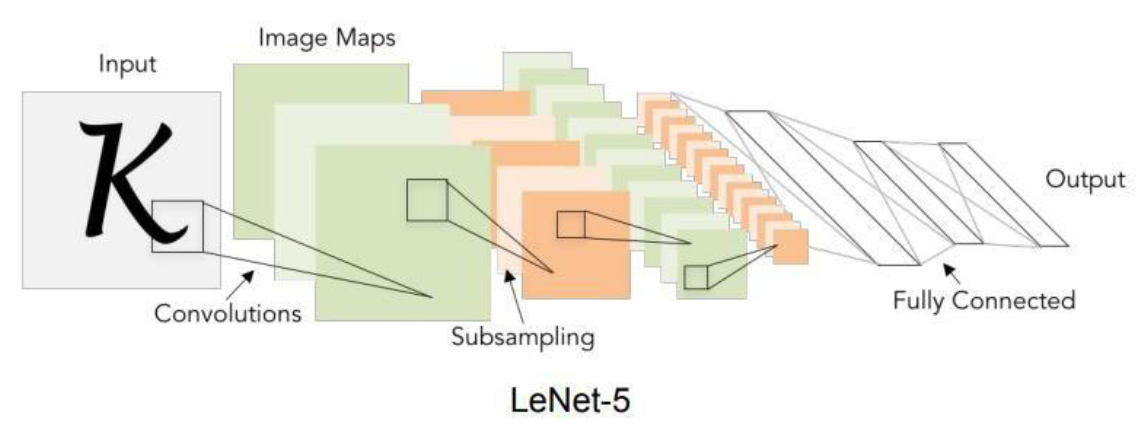
컴퓨터는 어디까지 볼 수 있게 되었나?
Convolutional Neural Network
[Key Ideas of CNN]
❕Filter & Feature map
💫필터 (Feature Map): 이미지 처리에서 사용되는 작은 행렬
-
이미지를 스캔하면서 각 부분을 계산하는 데 사용
-
필터의 크기는 일반적으로 정사각형이며, 가로와 세로의 차원을 갖는다.
ex) 3x3 or 5x5 -
이미지의 작은 영역을 탐지하고 다양한 특징을 추출하는 역할
ex) 가장자리, 질감, 색상 변화 인식 -
각 필터는 학습 과정에서 가중치가 조정되며, 이를 통해 모델은 데이터의 특징을 더 잘 이해하고 추출
💫피처 맵 (Feature Map): 필터가 이미지를 스캔하면서 계산한 출력
-
필터는 입력 이미지에 대해 슬라이딩하면서 특징을 추출하고, 이러한 작업을 모든 위치에서 수행하여 피처 맵 생성
-
각 필터마다 하나의 피처 맵이 생성되며, 입력 이미지의 특정 특징에 대한 반응을 나타냄
-
여러 개의 필터를 사용하면 여러 개의 피처 맵 생성
-
이때, 각 피처 맵은 입력 이미지에서 서로 다른 특징을 추출
-
피처 맵은 입력 이미지의 공간적 구조를 보존하면서, 더 높은 수준의 특징을 추출하기 위해 사용함
필터는 입력 이미지에서 특정 패턴을 감지하고, 각 필터마다 피처 맵을 생성하여 각 특징의 위치 정보 보존
❕모델링 구조
Input Layer()
Conv2D()
- filters: 내가 만들려는 feature map의 개수 or 서로 다른 필터 수
- kernal_size: 필터의 가로 세로 크기
- strides: 필터의 이동 보폭
- padding: 1.이전 feature Map 사이즈 유지 | 2.외곽 정보 더 반영
- activation: 활성화 함수
Maxpool2D()
- Pool_size: 폴링 필터의 가로 세로 사이즈
- strides: 이동 보폭 (None: Pool_size 따라감)
BatchNormalization() : 정규화
DropOut() : 데이터 비활성화
Flatten(): feature map을 1D 벡터로 변환
Dense Layer() : 위에서 convolutinal Layer를 통해 위치정보 특징이 추출됐음 -> 이제 분류를 위한 특징 추출하기 위한 레이어
Output Layer()
❕왜 마지막에 Flatten을 하는가?
Convolutional 레이어를 여러 개 쌓아서 특징을 추출하는 모델을 만들 때, 마지막에 Flatten을 하는 이유는 다음과 같습니다:
공간 정보를 유지하면서 특징 추출:
초기의 Convolutional 레이어들은 이미지의 공간 정보를 유지하면서 다양한 특징들을 추출합니다.
이러한 특징들은 이후 Dense 레이어에서 분류를 위해 활용됩니다.
Dense 레이어에 연결:
Dense 레이어는 1D 벡터를 입력으로 받습니다. 그래서 Flatten 레이어를 통해 2D 행렬 형태의 feature map을 1D 벡터로 변환하여 Dense 레이어에 연결할 수 있습니다.
따라서 Flatten 레이어는 CNN과 Dense 레이어를 효과적으로 결합하여 이미지 분류 문제를 해결하는 데 필요한 중간 과정입니다
결론: CNN은 flatten구조와 비교해서 데이터의 위치정보를 보존하여 새로운 feature를 추출하는 것
[ Let's Practice! ]
📚딥러닝 공부사이트
: 앤드류응 교수
- DeepLearning.AI
https://www.deeplearning.ai/
- edwith
https://www.edwith.org/search/show?searchQuery=andrew&MAX=20
(한글 자막 제공)
-
밑바닥부터 시작하는 딥러닝 (책)1,2,3
-
딥러닝 텐서플로 교과서
-
비전 시스템을 위한 딥러닝
(비전 입문 서적)
