One-Stage keypoint-based detector
Object Detection은 대부분 여러 경계박스(anchor)들을 이미지에 뿌려서, anchor들이 오브젝트와 걸쳐진 영역(IoU)이 일정 숫자보다 높으면 오브젝트가 anchor를 positive로 인식하고 이를 이용해 최종 경계박스를 유추한다. 이는 정확도는 좋겠지만, 많은 anchor box를 사용하다보니 training 속도도 늦추게 되고, anchor box들 사이의 간격, 사이즈를 고를 수 있다보니, 수 많은 선택지를 만들게 된다.
이에 CenterNet은 keypoint 방식으로 두가지 키포인트로 object detection을 하는 CornerNet을 보완해, 총 3개의 keypoint로 object detection을 한다.
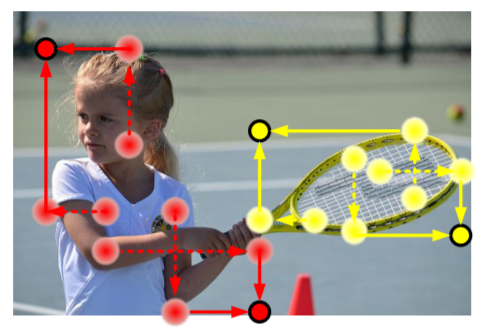
CornerNet은 왼쪽 위, 오른쪽 아래, 두개의 모서리를 인식하여 경계박스를 얻어낸다. 이 같은 경우 object의 경계선을 인식하는데 뛰어나지만, 안에 있는 물체의 전체적인 정보가 부족해, 경계선의 어디까지가 오브젝트인지 인식을 잘 못하는 경우가 발생해, 잘못된 경계박스를 만들어내기도 한다.
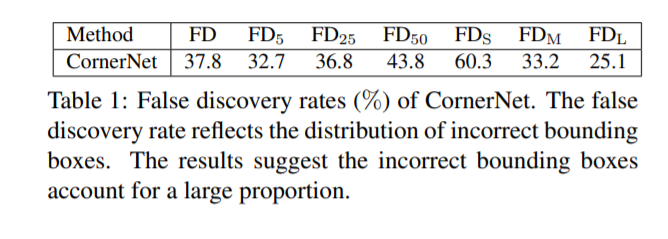
위 테이블은 MS-COCO 데이터셋에 CornerNet의 False discovery(FD) rate이다. IoU threshold가 0.05인데도 32.7%, 즉 평균 100개의 경계박스중 32.7개가 0.05보다 작은 IoU를 가진다. 그리고 더 작은 object는 60.3%이라는 엄청 높은 FD rate을 보여준다.
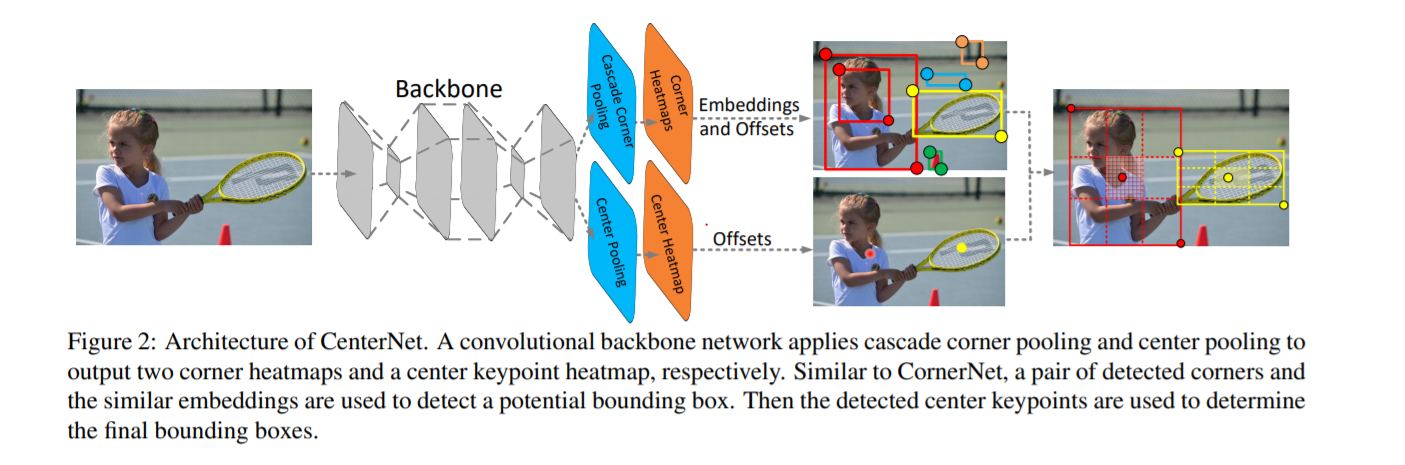
전반적인 CenterNet의 아키텍쳐이다. Backbone으로 hourglass Network를 사용한다.
Hourglass Network?
Hourglass network는 모래시계처럼 생겨서 부쳐진 이름인데, down sampling을 통해 feature맵을 뽑은다음, skip layer를 이용해서, upsampling을해 pixel wise output을 한다. 사람의 자세를 예측하는걸로 처음 쓰였는데, 피사체의 전체 및 부분을 detect하는데 탁월하다.
CenterNet은 이문제를 이렇게 해결한다: 만약 두 코너지점으로 만들어진 경계박스가 진짜 object이면, 경계박스의 중심영역안에 object의 중심 keypoint가 있을것이다. center point와 2개의 corner point를 이용하면 정확한 object detection이 가능할것이다.
그래서 이 keypoint들을 어떻게 찾을 수 있을까?
Center Pooling
Object의 Center point의 visual pattern은 상당히 적은 편이다. 예를 들어서 사람의 얼굴은 강한 visual pattern이 있지만, 사람의 중심 부인 몸은 딱히 visual pattern이 없다.
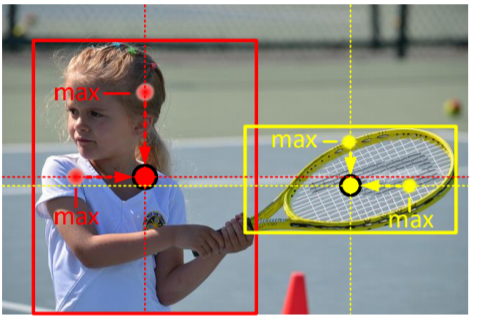
Center point의 예측을 강화하기 위해 새로운 pooling method를 제시했다. Hourglass backbone에서 나온 feature map의 pixel이 center keypoint인지 확인하려면, 세로와 가로방향의 maximum value를 더해서 center keypoint를 찾는다.
- Center Pooling
Cascade Corner Pooling
기본 Corner Pooling은 object의 경계선 방향의 maximum value를 가지고 측정한다.
- Corner Pooling

이렇게 되면 corner가 edge에 의해서 영향을 많이 받는 상황이 생기고, 경계박스가 엉뚱하게 만들어질수도 있다. 그래서 cascade corner pooling은 먼저 똑같이 경계선쪽에 maximum value를 찾은뒤, 최대 경계값의 위치를 따라 안쪽의 internal maximum value를 찾은뒤 maximum value들을 합쳐서 corner들이 경계박스와, 안에 있는 object의 information까지 다 얻을 수 있어서, 정확한 경계박스를 추론할 수 있다.
- Cascade Corner Pooling
Result
- 다른 State-of-the-art 모델들과 비교
Hourglass-52, Hourglass-104는 네트워크의 depth를 말하는것이다. input image는 511x511이고 AP는 Average Precision, AR은 Maximum Recall rate를 뜻한다. Single scale은 original resolution image를 넣은거고, multiscale은 0.6, 1, 1.2, 1.5 그리고 1.8 resoultion의 이미지들을 input로 넣었다. AP옆에 있는 숫자들은 IoU Threshold이고, AR 옆에 있는 숫자는 한 이미지에 fixed number of detection을 의미한다.
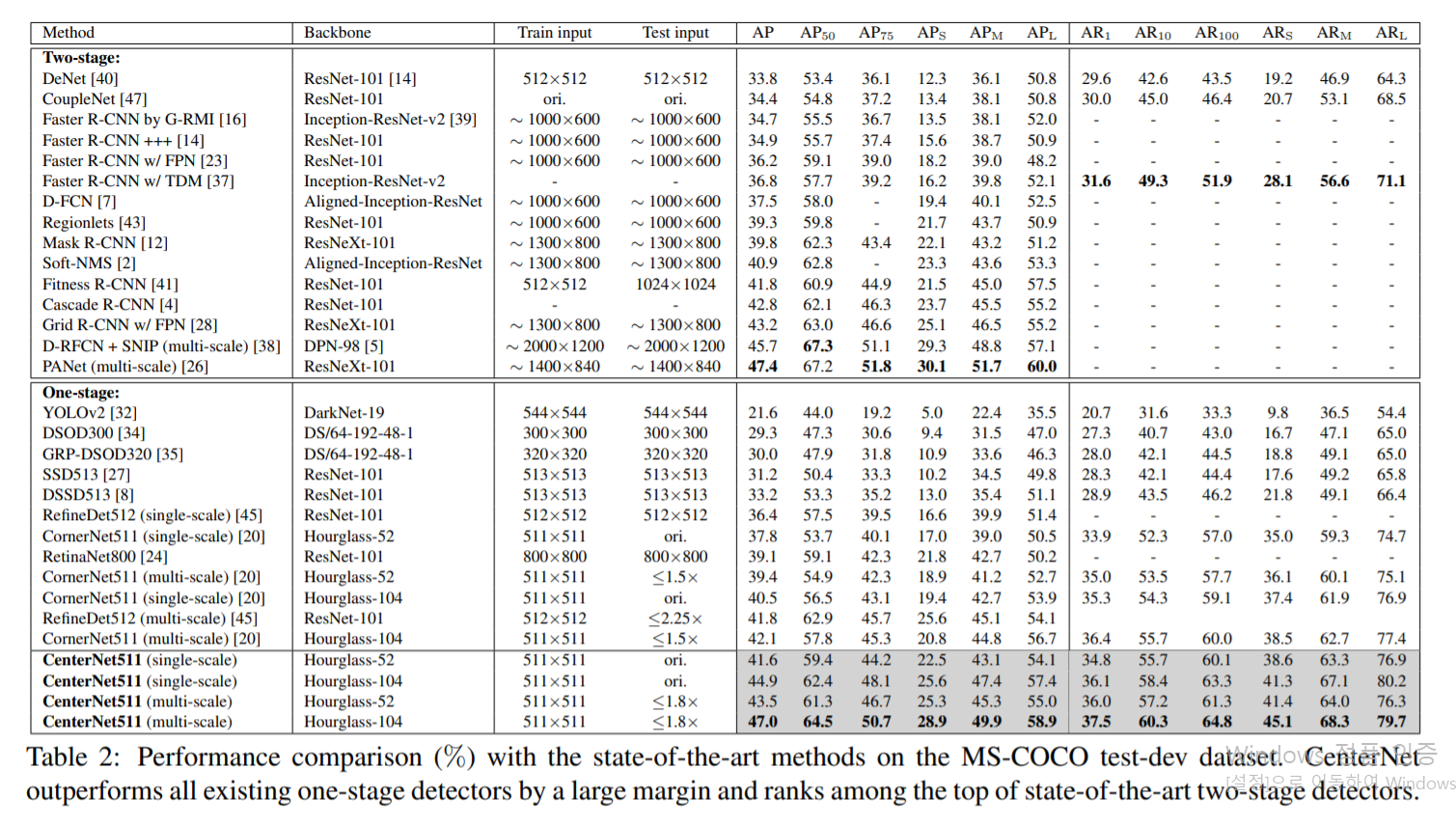
Result를 보면 CenterNet의 base라고 할 수 있는 CornerNet과 비교 했을때 CenterNet511-52(single-scale)의 AP가 41.6%, CornerNet511-52(single-scale)이 37.8%로 3.8% 차이가 나고, Hourglass-104를 쓴 케이스도 더 좋은 결과를 나타내는것을 확인 할 수 있다.
다른 One-stage detector들과 비교했을때도, 더 깊은 모델을쓴 RetinaNet800이나 RefineDet보다 더 좋은 성능을 보여주고, two-stage detector들과도 경쟁력있는 성능을 보여준다.
- Incorrect Bounding Box Reduction
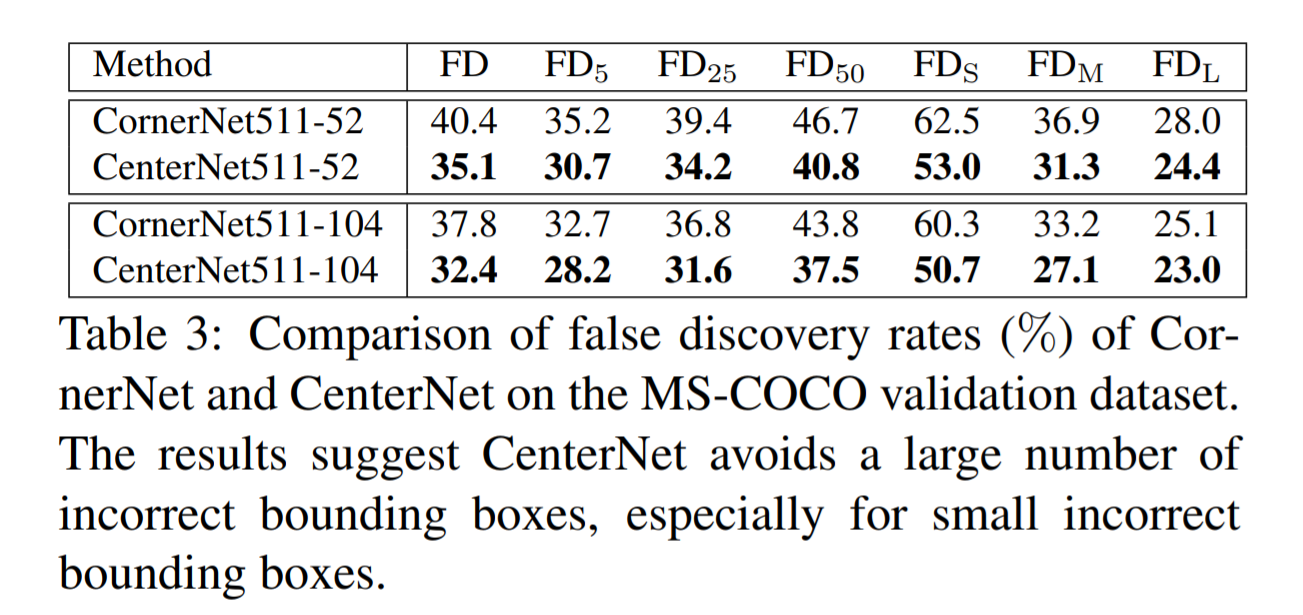
위 테이블에서 볼 수 있듯이, false discovery rate가 CornerNet보다 훨씬 줄어든것을 볼 수 있다. IoU Threshold가 0.05일때 CornerNet보다 더 작은 bounding box를 만드는것을 확인 할 수 있다.
- Inference Speed
CenterNet511-104는 한 이미지당 평균 340ms inference time이 걸리고, CenterNet511-52는 평균 270ms가 걸린다.
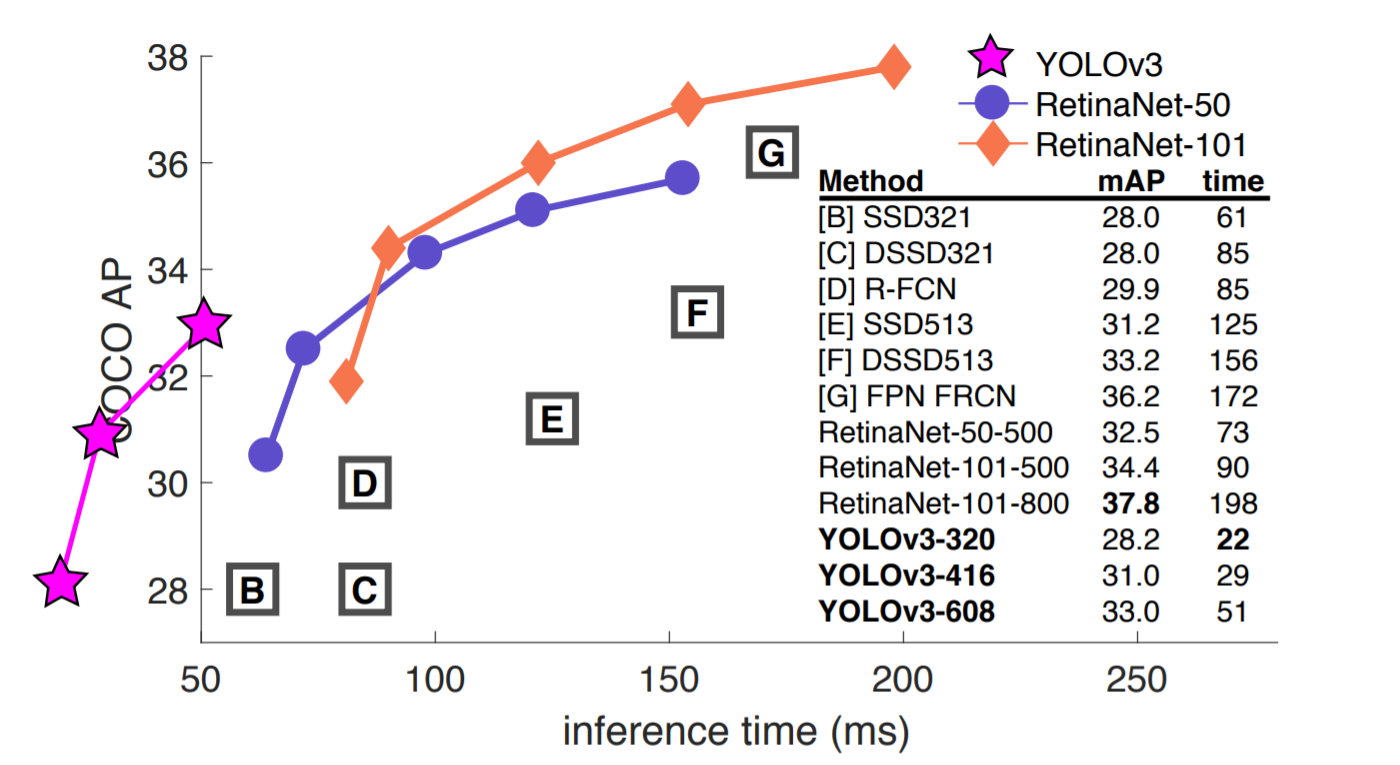
다른 detector들의 성능과 비교했을때 엄청 빠르지는 않는거 같지만, 정확도가 더 높으니까...(이용한 GPU와 이런게 달라서 조금 차이날 수 있을꺼 같다)
Error Analysis
- GroundTruth와 비교
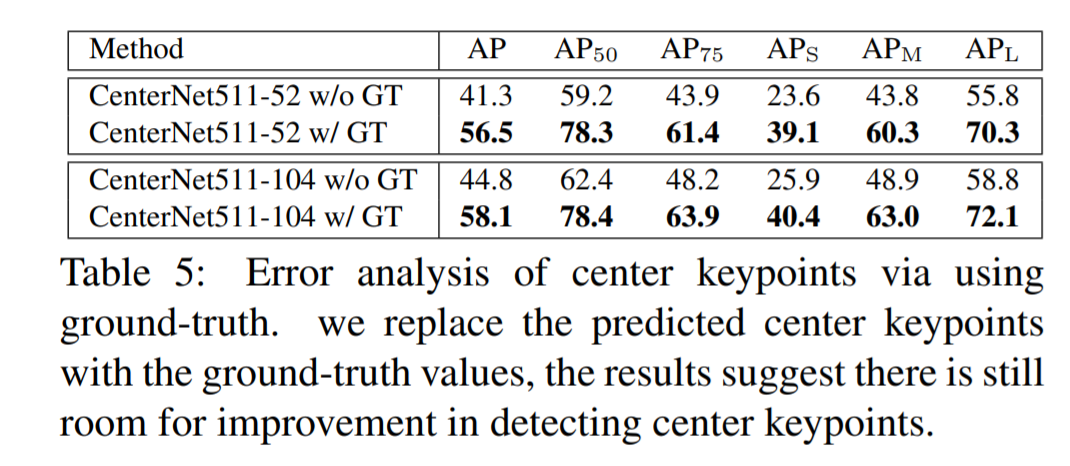
한마디로 말해서, center point예측이 빗나가면, accuracy가 엄청 떨어진다. 위 테이블에선 center point prediction과, center point를 진짜 ground truth value를 넣어서 accuracy를 비교한건데 엄청 차이는 것을 볼 수 있다.
Conclusion
One Staged Detector with the ability of two-stage approaches.
One Staged Detector이지만, ROI를 찾고, classify를 하는 행위는 two staged detector와 비슷한 성격을 가지고 있는 모델이라고 할 수 있다. 저자는 center keypoint를 다른 one-staged detector에도 쓸 수 있을거라고 생각하고, 좀 더 좋은 training 기법으로 CenterNet의 성능을 끌어 올릴 수 있다고 말한다.
