ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
1. Introduction
최근 자연어처리 분야에서는 BERT와 같은 pre-trained language representation이 좋은 성능을 보이고 있고 일반적으로 크기가 커질수록 성능이 향상된다. 그리고 network의 성능 개선을 위해 큰 model을 훈련하고 작은 model로 distill 하는 방법이 있다. 본 논문에서는 큰 model을 학습 하지않고 바로 작은 model로 학습하면 되지 않을까?라는 의문을 제기했다.
큰 model를 train하는데 있어 memory limitation problem이 존재하고 train 시간이 너무 오래걸린다. Model parallelization(Shoeybi et al., 2019)과 clever memory management(Chen et al., 2016; Gomez et al., 2017)으로 memory limitation problem을 해결할 수 있지만, communication overhead와 model degradation problem을 해결할 수 없다.
본 논문에서는 ALBERT의 두가지 parameter reduction 기법을 소개한다.
- embedding parameter factorize
- cross layer parameter sharing
두 개의 기법 모두 성능은 크게 저하되지 않으면서 기존 BERT의 parameter를 reduction하여 parameter의 효율성을 크게 올려준다.
다음으로는 ALBERT에서는 NSP(Next Sentence Prediction)가 아닌 SOP(Sentence-Order Prediction)이라는 self-supervised loss를 제안했다. 이러한 방법으로 train을 진행하여 문장간의 coherence(일관성)을 효율적으로 학습시켰다.
결과적으로 ALBERT는 더 적은 parameter의 수로 BERT의 large size보다 더 좋은 성능을 보여줬고 GLUE, SQuAD, RACE benchmark에서 SOTA를 달성했다.
2. Related Work
2.1 Scaling up Representation Learning for Natural Language
기존 NLP 분야에서는 word embedding을 통해 pre-training 하는 것에서 전체 network를 pre-training하고 이후 특정 task에 맞춰서 fine-tuning하는 방법으로 바뀌어 왔다. BERT를 포함한 여러 pretrained LM은 size가 커질수록 성능이 좋아진다는 결과가 많았지만, 논문에서 BERT는 1024 hidden size까지만 확인을 했으며, 2048로 늘리면 오히려 성능이 저하된다고 지적하고 있다. 또한 size가 큰 model들은 parameter의 수가 너무 많아 금방 GPU/TPU memory 한계에 도달하게 된다.
2.2 Cross-Layer Parameter Sharing
기존 transformer 구조에서도 parameter를 sharing하는 아이디어를 엿볼 수 있다. Encoder의 최종 output을 decoder의 multi-head attention의 key, value로 넘기는것에서 확인할 수 있다.
Dehghani et al., (2018)의 Universal transformers 논문에 따르면 cross-layer parameter sharing을 통해 기존 transformer보다 더 좋은 성능을 보여줬다.
아래 그림처럼 각 layer의 output이 input으로 들어가는 마치 RNN과 같은 형태를 가지고 있다.
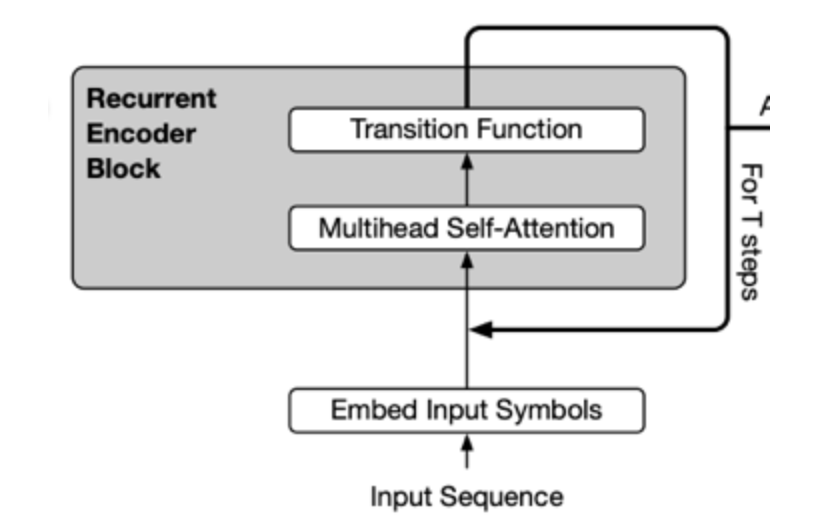
또한 Deep Equilibrium Model(DQE) 논문에서는 input embedding과 output embedding이 평형을 이룰수 있다는것을 보여줬다.
2.3 Sentence Ordering Objectives
ALBERT에서는 기존 BERT에서 사용하는 NSP 방식이 아닌 SOP 방식을 사용한다. SOP(Sentence-Order Prediction)는 두개의 text의 순서를 예측하여 loss를 이용하고 NSP에 비해서 더 어려운 task라고 논문에서는 소개하고 있다. 그리고 특정 task에 대해서 더 좋은 성능을 보여준다고 한다.
3. ALBERT
ALBERT의 구조는 BERT와 마찬가지로 transformer의 encoder를 사용하고 GLEU 함수를 사용한다. 그리고 다음과 같이 정의한다.
- : 단어의 embedding size
- : encoder의 layer 개수
- : hidden size
Feed-forward와 filter size를 4로 사용하고 attention heads도 / 64로 사용한다.
3.1 Factorized embedding parameterization
기존 BERT에서는 와 를 같게 설정했다. 하지만 논문에서는 modeling 관점에서는 좋지 않다고 지적을 했다. Modeling 관점에서 보면, word-Piece embedding은 context-independent representation을 학습하고 hidden-layer의 embedding은 context-dependent representation을 학습을 하기 때문이다. Hidden layer에서 나온 output은 token의 문맥까지 학습된 embedding으로 word embedding보다 중요 정보를 더 많이 담고 있기 때문에 ALBERT에서는 를 보다 더 크게 설정했다.
실용적인 측면에서 보면 최근에 vocab의 size가 점점 커지고 있는데, 와 를 같게 설정하면 embedding matrix인 또한 같이 증가하게 된다. 결국 model의 parameter가 너무 많아지는 결과가 초래된다. 그리하여 ALBERT에서는 factorization of embedding parameters를 사용한다. 기존 BERT에서는 one-hot vector들을 hidden space에 바로 projection 했는데 ALBERT에서는 one-hot vector를 보다 많이 작은 의 embedding space에 projection하고 그 다음 hidden space에 projection한다. 그렇게 되면 기존 parameter 개수를 x에서 ( x + x )로 줄일 수 있다.
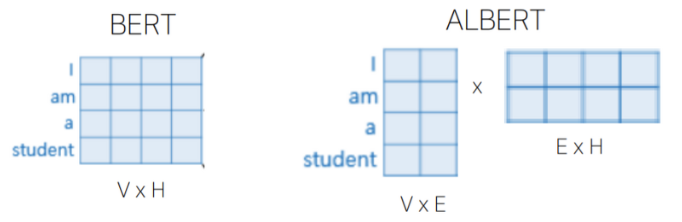
3.2 Cross-Layer parameter sharing
ALBERT에서는 parameter를 공유하는 cross-layer parameter sharing을 사용했다. 기존에는 feed-foward network의 parameter layer에서 공유하거나 attention parameter만 공유하는 방법들이 있었다. 그러나 ALBERT에서 default decision은 모든 parameter를 공유하는것이다.
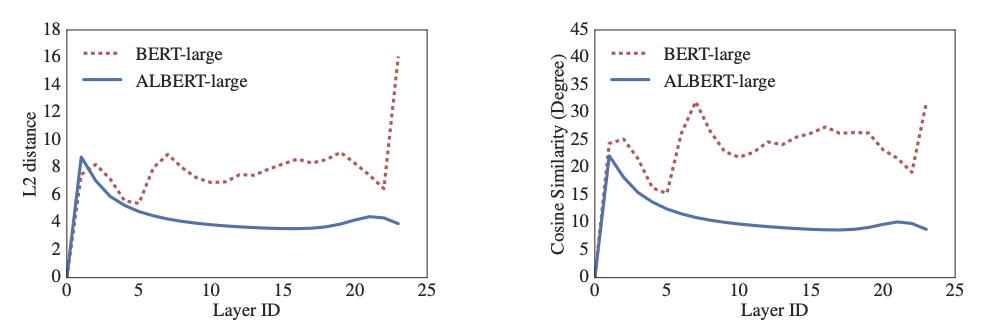
아래의 그래프를 보면 input embedding과 output embedding의 L2 distance와 cosine similarity를 보여주고 있다. ALBERT의 embedding은 수렴하고 있고 BERT의 embedding은 진동하고 있는것을 확인할 수 있다. 논문에서는 layer에서 layer로의 전이가 BERT보다 ALBERT에서 훨씬 더 부드럽다는것을 확인할 수 있었다. 그러므로 parameter sharing을 통해 network parameter를 안정시킬 수 있다고 볼 수 있다. (input과 output의 유사도가 수렴한다는것이 weight sharing이 안정화에 기여한다고 이해했다.)
3.3 Inter-sentence coherence loss
기존 BERT에서는 MLM(Masked Language Modeling) loss와 더불어서 NSP(Next-Sentence Prediction) loss를 사용했다. NSP는 두개의 문장이 연속인지 아닌지를 예측하는 binary classification에 가까웠다. 하지만 추후에 논문에서 NSP의 영향이 좋지 않다는 분석이 많았고 이를 제거했을 때, 특정 task에서 더 좋은 성능을 얻을 수 있었다고 한다.
본 논문에서는 NSP의 가장 큰 문제점으로는 MLM과 비교했을 때 너무 쉽다는것이다. 또한, NSP는 topic prediction과 coherence prediction을 단일 task에 포함하고 있는데 topic prediction은 너무 쉬운 task이기 때문이라고 추측한다.
ALBERT에서는 위의 task를 제거하는것이 아닌 coherence를 학습하는데 중점을 두었다. 그렇게 SOP(Sentence-Order Prediction) loss를 도입했는데, SOP는 동일한 document에서 두개의 연속 sentence를 positive sample로 사용했고, 두개의 sentence의 순서가 바뀐것은 negative sample로 사용했다. 이는 해당 loss가 topic을 예측하는것보다 sentence간의 coherence를 예측하게 한다. SOP는 50%의 확률로 순서를 그대로 넣거나 순서를 반대로 섞어서 넣는다. 결과적으로 NSP task로는 SOP task를 전부 풀지 못하지만, SOP task로는 NSP task를 모두 풀 수 있다고 했다.
3.4 Model Setup
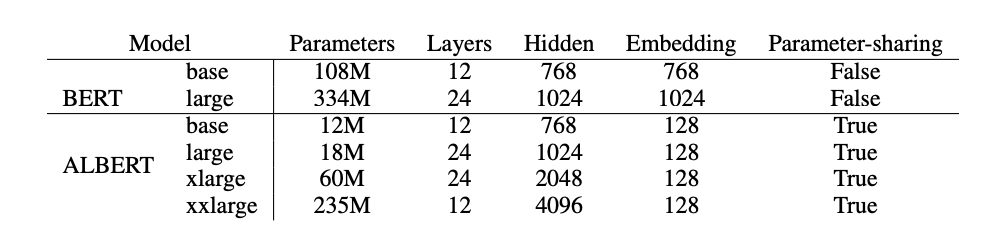
위의 표는 BERT와 ALBERT 모델의 hyper parameter의 차이를 보여준다. ALBERT-large는 기존 BERT-large보다 18배 적은 parameter를 사용한다. 그리고 ALBERT-xxlarge의 embedding size는 4096으로 BERT-large에 비해 약 4배 크지만, parameter의 개수는 70%정도 밖에 되지 않는다.
4. Experimental Results
4.1 Experimental Setup
- 기존 BERT와 같이 BookCorpus & Wikipedia (16GB)
- 최대 길이는 512, 입력 시퀀스를 10%확률로 512보다 짧게 만듬
- 기존 BERT와 같이 vocab size는 30000
- SentencePiece사용
- n-gram masking을 사용, n-gram masking의 길이를 random하게 선택, 길이 n의 확률은
- n-gram의 최대 길이는 3
- batch size 4096
- optimizer는 Lamb optimizer를 사용
- learning rate는 0.00176
4.3 Overall Comparison between BERT and ALBERT
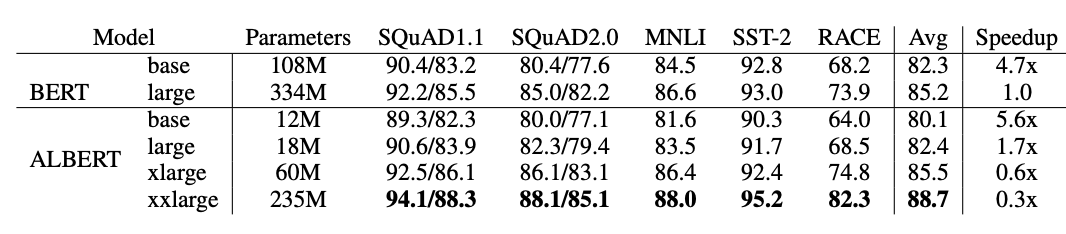
위는 BERT와 ALBERT의 각종 benchmark에 대한 결과를 비교하는 표이다.
-
ALBERT-xlarge는 BERT-large보다 더 적은 parameter 개수로 거의 비슷한 결과를 얻었음.
-
ALBERT-xxlarge는 BERT-large에 비해 70%정도의 parameter로 BERT-large의 모든 점수를 넘었음
-
ALBERT-xxlarge는 적은 parameter로 성능은 좋아졌지만, 계산은 더 많아지고 속도는 BERT-large에 비해 줄었음
4.4 Factorized Embedding Parameterization
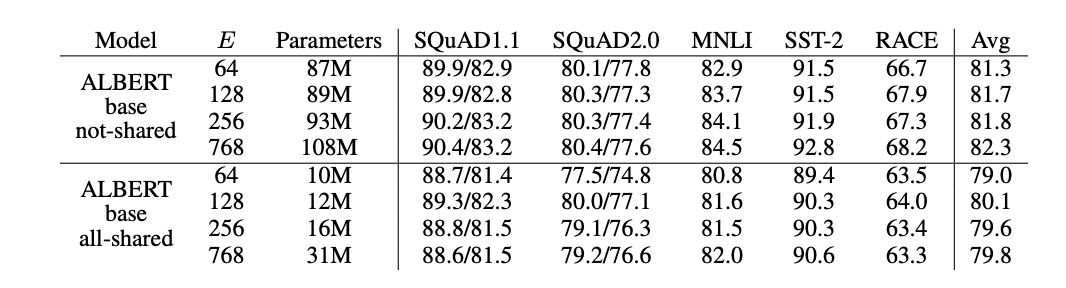
위의 표는 여러 downstream task에서 ALBERT를 사용하여 embedding size를 변경한 결과를 보여준다.
- not-shared ALBERT에서는 embedding size가 클수록 성능이 좋아지지만 미미함
- all-shared ALBERT에서는 128 size가 가장 성능이 좋음
그래서 모든 실험에서 embedding size를 128로 잡았다.
4.5 Cross-layer parameter sharing
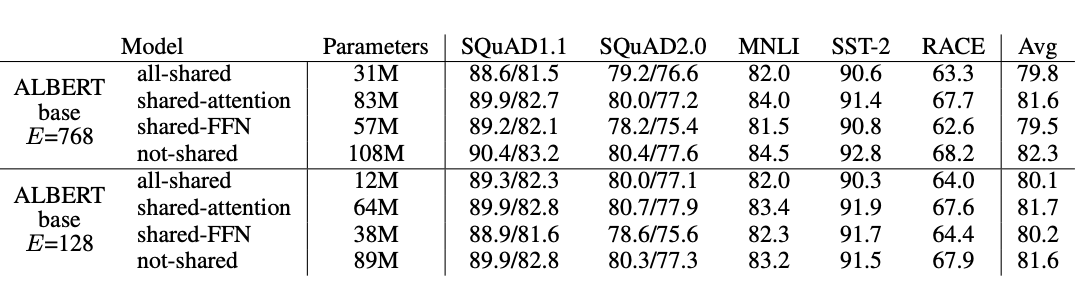
위 표는 두가지의 embedding size 768, 128를 가진 ALBERT의 성능을 all-shared stategy(ALBERT-style), non-shared strategy(BERT-style) 및 only the attention parameter share, FFN parameter share로 나누어 비교했다.
- all-shared strategy에서는 모두 성능이 저하됨
- 대부분 성능의 저하는 FFN layer에서 sharing하는것에서 나타남
- attention parameter를 sharing하면 128에서 저하가 없고 768에서는 조금의 저하가 발생
4.6 Sentence order prediction (SOP)
다음은 SOP에 대한 실험을 head-to-head로 비교했다. None은 XLNet과 RoBERTa, NSP는 BERT, SOP는 ALBERT이다.

- NSP가 52%의 정확도로 SOP task를 수행하지 못함
- 반대로 SOP는 NSP task에서 78%의 정확도로 잘 수행함
- SOP loss는 multi-sentence encoding task에서 성능 향상을 보임
4.7 EFFECT OF NETWORK DEPTH AND WIDTH
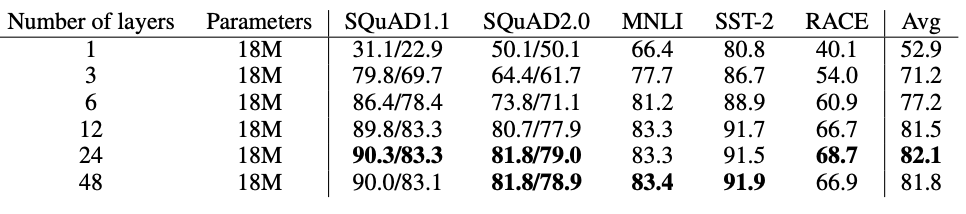
위의 표는 깊이(number of layers)가 ALBERT의 성능에 미치는 영향을 보여준다. 층을 높게 쌓을수록 성능은 증가하지만 일정 층을 넘어가면 성능이 저하되는것을 보여준다.
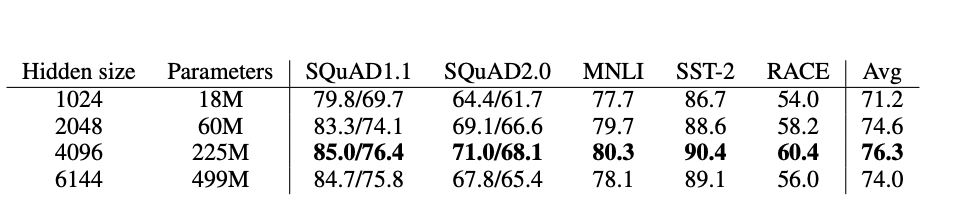
위의 표는 너비(hidden size)가 ALBERT의 성능에 미치는 영향을 보여준다. 위의 결과와 비슷하게 hidden size가 커질수록 성능이 증가하지만 size가 너무 크면 오히려 성능이 감소한다. 또한 저자들은 위 model 중 어느 것도 overfitting하지 않았다고 했다.
4.8 What if we train for the same amount of time?

위 표를 보면, BERT-large model과 ALBERT-xxlarge model의 학습시간은 거의 비슷하다. 그러나 성능은 ALBERT-xxlarge가 더 좋은것을 확인할 수 있다.
4.9 Additional training data and dropout effects
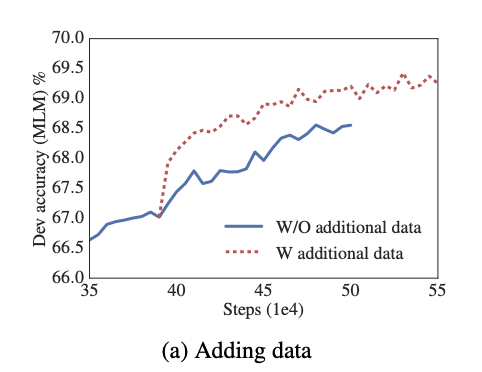
위의 그래프는 additional data가 존재할때와 존재하지 않을때의 MLM accuracy를 비교했으며 additional data가 있을 때, 성능이 향상되었다.

또한 downstream task에서도 성능향상을 확인할 수 있다.
논문에서는 1M step을 training 했을때, 가장 큰 model도 overfit되지 않아서 dropout을 제거했다.
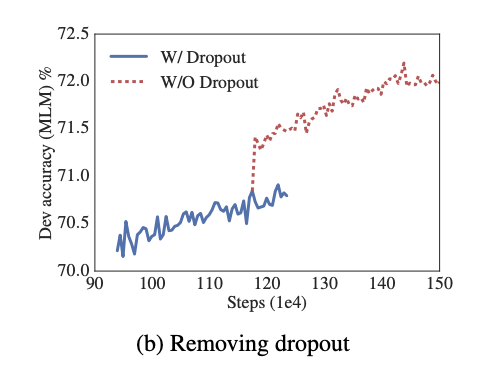
위의 그래프를 통해 dropout이 제거했을 때, MLM accuracy가 크게 향상된것을 알 수 있다.

위 표를 보면 dropout을 제거했을 때, downstream task에서도 성능이 향상된것을 볼 수 있다. 결론적으로 dropout이 성능을 저하시킬 수 있음을 논문에서는 얘기한다.
5. Conclusion
- ALBERT-xxlarge는 BERT-large보다 더 적은 parameter로 더 좋은 성능을 보여줬지만 structure가 더 크기 때문에 계산비용이 더 큼
- 다음 단계로는 ALBERT의 train 속도와 inference 속도를 높이는것
- Model의 성능이 향상된것도 중요하지만 model의 크기가 줄어 memory limitation 문제도 해결
- SOP가 NSP보다 좋다는 것을 보여줌
