BertGCN: Transductive Text Classification by Combining GCN and BERT
0. Abstract
본 연구에서는 BertGCN을 제안합니다. BertGCN은 large scale의 pretraining과 transductive 학습을 통해 text classification 문제를 해결합니다.
Dataset에 대해 그래프를 구성하고, 각각의 문서를 BERT representation을 통해 node로 나타냅니다. BERT와 GCN을 함께 훈련함으로써 방대한 양의 raw data와 label이 지정되지 않은 데이터를 함께 사용할 수 있다는 이점이 있습니다.
BertGCN은 당시 많은 텍스트 분류 문제에서 SOTA 성능을 달성하였습니다.
1. Introduction
텍스트 분류는 NLP분야의 핵심 과제 중 하나이며, 주로 스팸 탐지 및 opinion mining등이 연구되어왔습니다.
Transductive learning은 텍스트 분류에서 사용되는 기법으로, 훈련 과정에서 레이블이 있는 데이터와 없는 데이터를 모두 사용하도록 하는 method입니다.
Graph neural networks(GNN)는 이러한 transductive learning의 효과적인 접근법입니다. 그래프의 노드는 단어, 문서와 같은 텍스트 단위를 나타내고 엣지는 노드간의 의미적 유사성을 나타냄으로써 텍스트를 그래프로 표현합니다.
그런 다음 GNN을 그래프에 적용하여 노드 분류를 수행하는데, 본 논문의 저자는 이러한 GNN과 transductive learning의 장점을 아래 두 가지로 정리하였습니다.
- 의사결정(training과 test 모두)은 해당 노드에만 의존하는 것이 아니라, 이웃 노드에도 의존하게 됩니다. 이것은 데이터 이상치에 대해 모델이 더 내성을 갖도록 만듭니다.
- 훈련시 모델은 지도학습된 레이블을 엣지를 통해 훈련 및 테스트 데이터에 영향을 미치기 때문에 레이블이 지정되지 않은 데이터도 representation learning에 기여하여 더 높은 성능을 제공합니다.
따라서 본 논문에서는 pre-training과 transductive learning의 장점을 결합한 모델인 BertGCN을 제안합니다. BertGCN은 단어 또는 문서를 노드로 하며, 노드 임베딩은 사전훈련된 버트 representation으로 초기화됩니다. 그 후 분류를 위해 GCN모델을 사용합니다.
2. Related work
2.1 Graph neural networks(GNN)
Graph model은?
- 그래프 모델은, 그래프 데이터에 적용 가능한 모델을 의미합니다.
- 기존 머신러닝 모델은 데이터간의 독립을 가정합니다.
- 상호 연관을 나타내는 데이터는 기존의 알고리즘에 적합하지 않습니다.
- 그래프 데이터에 맞는 새로운 알고리즘이 필요합니다.
Graph model의 작동 원리
그래프 모델은 이웃 노드와의 messege passing을 통해 자신의 정보를 업데이트합니다.
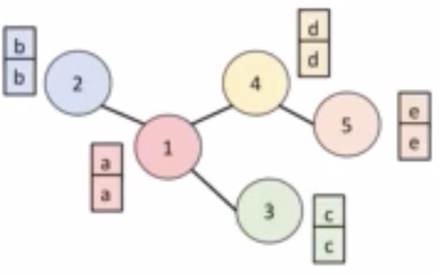
예를들어 위 그림에서는, 5개의 노드가 엣지로 연결이 되어있는데 2번 노드와 5번 노드는 직접적으로 연결되어있지는 않지만 학습을 진행하다 보면 서로 이웃노드의 영향을 주고받기 때문에 결국 2번노드 또한 5번노드의 영향을 받게 되는 것입니다.
Graph Convolutional Network(GCN)
GCN은 기본 cnn과 거의 비슷한 형식으로 학습이 진행됩니다. 연결된 이웃 노드의 feature vector의 summation을 target 노드의 representation으로 업데이트합니다. 학습 과정에서 Message passing을 통해 learnable parameter W행렬을 학습합니다.
2.2 BERT
BERT는 Bidirectional Encoder Representation from Transformers의 약자로 transformer의 encoder로 이루어진 layer를 통한 대규모 pre-training 모델 기반 NLP 알고리즘입니다.
버트는 두 가지 기법을 통해 사전훈련을 진행합니다.
- Masked Language Model : Masked token에 해당 단어를 예측하도록 함으로써 양방향으로 문맥 학습
- Next Sentence Prediction : 두 개의 corpus가 실제로 연결되는지 아닌지를 학습
3. Method
3.1 BertGCN
먼저, BERT로 텍스트 그래프의 노드를 임베딩하고 이를 document input vector로 사용합니다. Word input vector는 0벡터로 대체합니다. 이 input은 GCN의 입력으로 사용됩니다. 이를 통해 vector들을 그래프 구조를 기반으로 반복적으로 업데이트하고 그 출력은 문서 노드에 대한 최종 representation vector입니다. 이 값은 예측을 위해 softmax classifier로 전송됩니다. 이러한 방식으로 사전 훈련된 모델과 그래프 모델의 장점을 모두 활용할 수 있습니다.
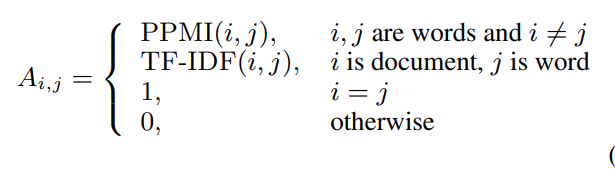
위 수식을 보면 A는 edge의 weight이며, PPMI는 단어와 단어간의 edge, TF-IDF는 단어와 문장간의 edge를 의미합니다. 동일한 노드의 가중치는 1이며 그 외에는 0입니다.
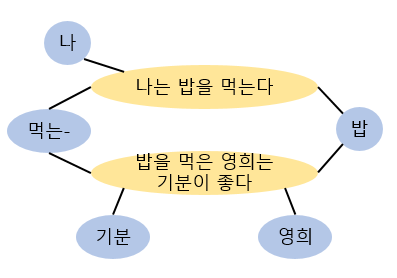
텍스트 네트워크를 구성하는 방식은 선행연구인 TextGCN(https://arxiv.org/pdf/1809.05679.pdf)의 방식을 참고하였습니다.
좀 더 이해하기 쉽도록 예를 들면, node는 위와 같이 document node와 word node로 구성되어있고, 각각의 문장 노드에 포함된 단어 노드들이 연결되어있습니다. '밥'이라는 단어는 두 문장 모두 포함되어있으므로, 두 문장 모두 연결이 되어 있는 것을 볼 수 있습니다. 이렇게 텍스트를 그래프의 형태로 표현하여 vector를 업데이트해나갑니다.
initial node features는 다음과 같이 나타냅니다.
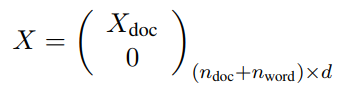
n_doc는 문서노드(document node)의 갯수를 의미하며 n_word는 단어노드(word node)의 갯수를 의미합니다. 또한 d는 embedding dimension을 나타냅니다. 이렇게 구한 X를 GCN(https://arxiv.org/pdf/1811.11103.pdf) layer에 input으로 투입합니다.
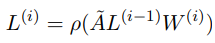
위 수식은 i번째 GCN layer의 output feature 계산을 나타낸 수식입니다. GCN layer는 메세지를 전파하며 벡터를 업데이트합니다. ρ는 활성화함수이고, A~는 조정된 matrix이며 W는 가중치 행렬입니다. 분류를 위해 이 값을 softmax layer에 통과시킵니다.

이 때 BERT와 GCN을 최적화시키기 위한 손실함수로는 레이블된 document node의 cross entropy loss를 사용합니다.
3.2 Interpolating BERT and GCN Predictions
최종적인 모델의 objective function은 아래 식과 같습니다.
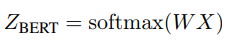
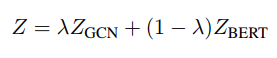
람다 파라미터가 새로 생긴것을 알 수 있습니다. 여기서 이 값은 BertGCN과 BERT모델의 비율을 조정합니다.
즉, 람다가 1이면 full BertGCN, 0이면 BERT인 모델입니다. 저자는 이렇게 두 모델의 예측 균형을 맞춤으로써 BertGCN모델을 더 잘 최적화할 수 있다고 말합니다. 이러한 방식이 GCN모델의 기울기 소실문제나 over-smoothing 문제를 극복하도록 합니다.
3.3 Optimization using Memory Bank
원래 GCN모델은 훈련할 때 full-batch gradient descent 방법을 사용하는데, full-batch는 BERT에 적용할 수 없기 때문에 본 논문에서 제시하는 BertGCN에는 적용이 어렵습니다.
따라서, 그래프 노드의 total number로부터 training batch size를 분리해내기 위해 모든 document embeddings를 저장하는 memory bank를 제안합니다.
훈련시 모든 document nodes의 input feature를 추적하는 memory bank를 유지합니다. 각 epoch가 시작될 때, 먼저 current BERT를 사용해서 모든 document embedding을 계산한 뒤 M(Memory)에 저장합니다.
그리고 각 iteration에서 레이블이 지정된 문서 노드와 지정되지 않은 문서 노드 모두에서 미니배치를 샘플링합니다.
메모리 뱅크를 사용하여 BERT 모듈을 포함하는 BertGCN 모델을 효율적으로 훈련할 수 있습니다. 하지만 훈련 중에 메모리 뱅크의 임베딩은 BERT 모듈을 사용하여 에포크의 다른 단계에서 계산되므로 일관성이 없습니다.
이 문제를 극복하기 위해 저장된 임베딩의 일관성을 향상시키기 위해 BERT 모듈에 대해 학습률을 작게 설정했습니다. 학습률이 낮으면 훈련에 시간이 더 오래 걸립니다. 훈련 속도를 높이기 위해 훈련이 시작되기 전에 대상 데이터 세트에서 BERT 모델을 미세 조정(RoBERTa)하고 이를 사용하여 BertGCN에서 BERT 파라미터를 초기화합니다.
4. Experiments
4.1 Experiment Setups
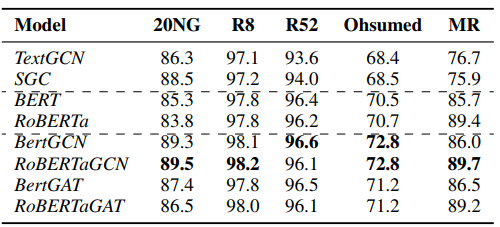
본 논문에서 제안된 BertGCN은 현재 SOTA 모델과 비교하였습니다. BertGCN은 사전학습된 Bert_base 모델과 2개의 GCN layer를 사용하였습니다.
4.2 Main Result
한가지 의아한 점은, GCN 모델을 사용한 결과가 GAT 모델을 사용한 것보다 좋은 성능을 보였다는 점입니다. GAT는 self-attention mechanism을 노드 임베딩에 사용한 모델로, Attention 개념을 Graph 구조의 데이터에 적용하였습니다. 이 모델은 Target Node의 근접 노드 hidden state값을 Key,Query,Value로 사용하여 유사도를 계산합니다. GAN은 다른 모델들 보다 성능이 더 뛰어나고 Attention Score를 통해서 설명이 가능한 장점이 있고, 연산이 비교적 간단하다는 장점이 있다고 알고 있었는데 GCN을 결합한 모델이 더 좋은 성능을 내는 것이 의외였습니다.
또한 결과를 보면, 20NG와 Ohsumed 데이터는 text의 길이가 긴 데이터입니다. 이런 데이터에서 버트와 BertGCN의 성능 차이가 더 많이 나는 것을 확인할 수 있습니다.
Data들의 average length
1. 20NG : 221.26
2. R8 : 65.72
3. R52 : 69.82
4. Ohsumed : 135.82
5. MR : 20.39
이는, BERT-GCN이 Bert에서 네트워크를 구축해서 새롭게 학습함을 통해 퍼포먼스를 향상시키는데, 텍스트의 길이가 짧아지면 엣지 갯수 또한 줄어듭니다. 그러면 애초에 엣지가 많지 않으므로 성능이 크게 향상되지는 않는 것 같습니다.
4.3 The Effect of λ
아래 그래프는 RoBERTa의 λ값에 따른 정확도이며 아래 점선은 RoBERTa Baseline을 의미합니다.
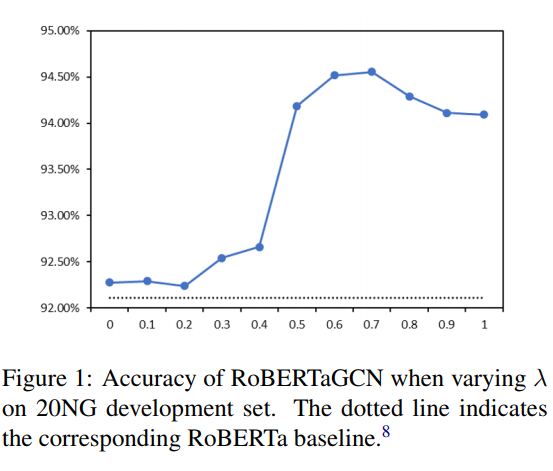
람다가 0.7일 때 가장 좋은 성능을 보였습니다. BERT를 30%정도, BertGCN을 70%정도 사용하는 것이 가장 적절한 비율인듯합니다.
4.4 The Effect of Strategies in Joint Training
아래 표는 20NG 데이터에서의 결과입니다.

BertGCN에서 아래 두 가지의 전략을 사용하거나, 사용하지 않고 실험을 진행했습니다.
1. fine-tuning 하기 (=RoBERTaGCN)
2. 학습률을 작게 하기
그 결과 두 가지 전략을 둘 다 사용하였을 때 좋은 성능을 보였습니다! (RoBERaGCN+small lr)
5. Conclusion and Future Work
본 연구에서는 대규모 사전학습과 transductive 학습을 함께 사용하여 텍스트를 분류하는 BertGCN을 제안하였습니다.
그러나 이 연구의 한계점은 document statistics를 사용하여 그래프를 그리기 때문에 자동으로 edge를 구성할 수 있는 모델이 더 좋은 방법일 수 있습니다. 이것을 향후 연구에 남겨놓는다는 말로 논문은 마무리됩니다! 개인적으로는 이 모델이 정확도 외에 속도 측면에서는 성능이 어떤지 궁금하였습니다..
본 글을 작성할 때 아래 링크의 유튜브를 참조하였습니다.
https://www.youtube.com/watch?v=X1u_65N0jXs
