[Paper Review] (2017, Huifeng Guo) DeepFM : A Factorization-Machine based Neural Network for CTR
Recommender_System

작성자 : 권오현
Abstract
- 추천 시스템에서 CTR을 최대화 하기 위해서는 유저 행동에 숨겨진 복잡한 상호관계(feature interaction)을 학습하는 것이 중요하다.
-
기존의 방법론은 낮은 차원의 상호관계(low-order interactions)나 높은 차원의 상호관계(High-order interactions)에 치우쳐 학습을 하거나, 전문가의 feature engineering이 필요하다.
-
논문 저자는 낮은 차원(low-order), 고차원(high-order)의 feature interactions을 End-to-End 모델로 학습할 수 있음을 보여준다.
-
DeepFM은 Factorization machines이 가지는 장점과 Deep Learning이 가지는 장점을 결합한 새로운 Neural Network 구조이다.
[참고]
-
CTR (Click-Through Rate) 이란
클릭률(CTR)은 광고를 본 사용자가 해당 광고를 클릭하는 빈도의 비율입니다. 클릭률(CTR)을 사용하면 키워드와 광고, 무료 제품 목록의 실적을 파악할 수 있습니다.(클릭수 ÷ 노출수 = CTR) -Google Ads
-
Factorization Machines :
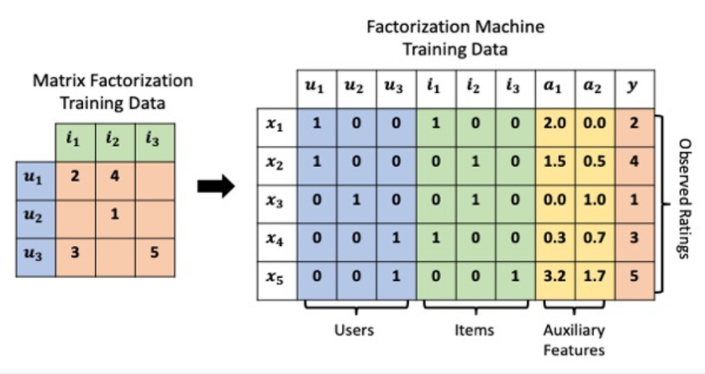 Linear Regression : 유저와 아이템에 대한 평가를 예측하는 문제라고 생각하면 추천시스템은 선형 회귀식에서 시작 되었다.
Linear Regression : 유저와 아이템에 대한 평가를 예측하는 문제라고 생각하면 추천시스템은 선형 회귀식에서 시작 되었다.
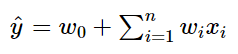 Polynomial Model : 추천 시스템의 데이터는 categorical type 변수가 많고 one-hot-encoding 값이 많아 데이터의 차원이 크고 Sparse하다. 이를 위해 각 변수 간의 interaction을 고려한 모델이 제안되었다.
Polynomial Model : 추천 시스템의 데이터는 categorical type 변수가 많고 one-hot-encoding 값이 많아 데이터의 차원이 크고 Sparse하다. 이를 위해 각 변수 간의 interaction을 고려한 모델이 제안되었다.
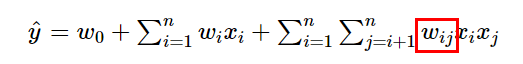
이러한 모델링은 Linear Regression의 한계를 극복 가능 하지만 Parameter 수가 증가 하기 때문에 연산이 복잡, Factorization Machines는 feature interaction vector를 저차원으로 factorize하여 이를 해결함
Factorization Machines : Polynomial model에서 interaction weight인 가 두 벡터 의 내적으로 factorize 되었다. 이 두 벡터는 interaction의 latent vector로 표현함으로써 latent space내에서 interaction을 보다 더 잘 잡아낼 수 있다.
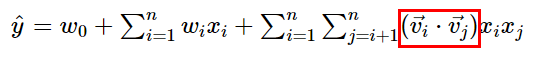
Introduction
Click-Through Rate Prediction for recommendation
- The task of predicting the likelihood that something to website(such as an advisement) will be checked
- CTR Prediction은 User가 추천 아이템을 클릭할 확률을 추정하는 것으로 유저에게 추천될 아이템의 순위를 매길 수 있다. 또한 온라인 광고 같은 시나리오에서도 수입을 증가시킬 수 있다.
CTR을 정확하게 추정하는 것이 핵심이다. - CTR Prediction은 User click 행동에 존재하는 implicit feature interactions를 학습하는 것이 중요하다.
- 일반적으로 User click 행동의 interactions는 매우 복잡하고 low-order, high-order interaction이 중요한 역할을 한다.
Example
- 식사시간에 배달앱 다운로드 하는 경우 많음 -> "app category"와 "time-stamp"의 interaction (order-2)
- 10대 남자들은 Shooting games & RPG games 좋아함 -> "app category"와 "gender", "age"의 interaction (order-3)
- Association rule에 의해 발견된 '기저기와 맥주'의 interaction (order-2)
- 예시 1,2 와 같이 쉽게 어떠한 feature interactions는 쉽게 이해할 수 있지만, 대부분의 feature interactions는 데이터 속에 숨겨 있고 prior 정보 만으로 알기 어려워 machine learning에 의해 auto-matically하게 포착되어야 한다.(예시 3)
Previous Approaches
-
Generalized Linear Model FTRL [McMahan et al. 2013] :
선형 모델은 feature interaction을 학습하기에 부족하며 pairwise feature interactions을 직접 feature vector로 넣어준다.
이러한 방법은 High-order feature interactions 학습하기 어렵고 cold start 문제가 존재함.
-
Factorization Machine (FM) [Rendle, 2010] :
pairwise feature interactions을 feature 간의 inner product를 통해 모델링 하였다.
High-order feature interaction을 모델링 할 수 있지만 High Complexity로 인해 order-2 feature interaction만 고려한다.
-
Factorization-machine supported Neural Network (FNN) [Zhang et al., 2016] :
Deep Neural Network에 적용하기 전에 FM으로 pre-trains 하여 feature embeddings의 가중치를 초기화 하여 학습을 한다.
DNN에 적용하기 전에 FM을 pre-train 하기 때문에 FM에 의해 성능이 제한된다.
-
Product-based Neural Network (PNN) [Qu et al., 2016] :
Feature interactions에 대해 Embedding layer와 fully-connected 사이에 product layer를 도입하였다.
FNN과 PNN은 다른 DNN 처럼 CTR Prediction에 필수적인 low-order feature interactions를 거의 포착하지 못한다.
-
Wide & Deep learning for Recommender Systems (Wide & Deep) [Cheng et al., 2016] :
low order & high-order interactions를 모델링하기 위해 linear("wide") model과 DNN ("deep") 을 결합한 Wide & Deep 모델을 제시하였다.
Wide & Deep은 두 개의 다른 input(wide part, deep part)을 필요로 하는데 wide part input은 feature engineering이 필요함
wide part input은 designed pairwise feature interaction이기 때문에 입력 vector가 굉장히 커져 Complexity를 증가시킨다.
Problem
- low-order or high-order feature interaction, feature engineering을 모델링 하는데 치우쳐 저 있다.
- feature engineering 없이 low order, high-order feature interactions를 End-to-End 방식의 모델을 제안함
Model Structure
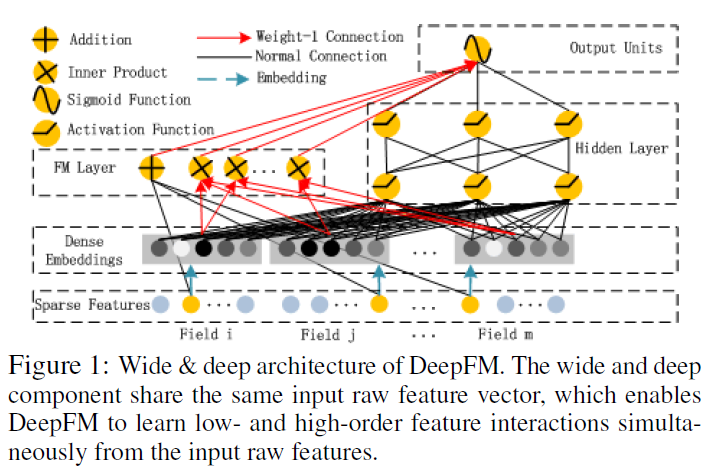

- Factorization Machines(FM)과 Deep Neural Network(DNN)의 구조를 결합한 새로운 NN모델인 DeepFM을 제시한다.
- Wide & Deep 모델과 다르게 같은 input, embedding layer를 공유하기 때문에 효율적으로 학습할 수 있다.
- Benchmark data와 commercial data에 평가한 결과 다른 CTR Prediction 모델 보다 일관적으로 향상된 결과를 보였다.
Our Approach
Traning Dataset
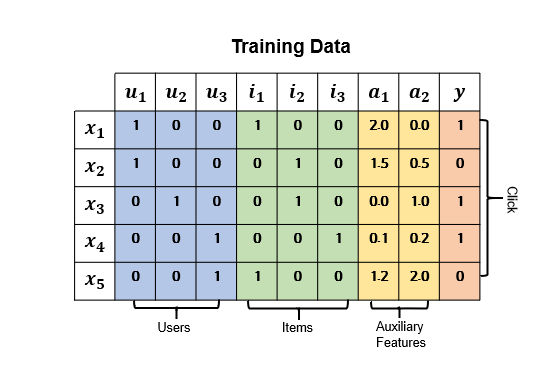
-
n개의 데이터가 구성되어 있다. 는 User, Item pair m-fields 구성되어 있다.
Categorical fields (e.g., gender, location): one-hot encoding
Continuous fields (e.g., age) : value, Discretization & one-hot encoding -
CTR Prediction 모델의 목적은 context가 주어졌을 때 특정 앱을 클릭할 확률을 추정하는 모델을 만드는 것이다.
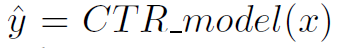
DeepFM
-
DeepFM은 같은 input을 통해 FM Component(low-order feature interaction)와 Deep Component(high-order feature interaction)을 학습하는 것을 목표로 한다.
-
FM Component와 Deep Componet가 같은 Embedding 벡터를 공유한다. 이러한 구조는 두 가지 장점을 가진다.
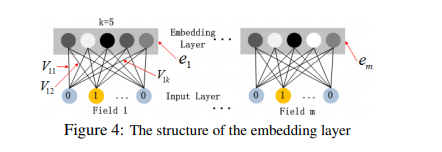
1) 의 크기가 다를 수 있지만 로 인해 같은 크기(k=5)를 가진다.Gender의 경우 크기가 2인 이지만 국적이나 나이의 경우 Gender보다 더 큰 벡터를 가지게 된다. 하지만 결과적으로 으로 Embedding된다.
2) (FNN) [Zhang et al., 2016] 에서는 가 FM에 의해 pre-trained 한 feature embeddings의 가중치를 초기화하여 학습하지만 DeepFM은 pre-trained할 필요가 없고 End-to-End로 학습을 할 수 있게 된다.
-
결과적으로 는 FM, DNN의 예측값의 합을 를 적용한다.

FM Component
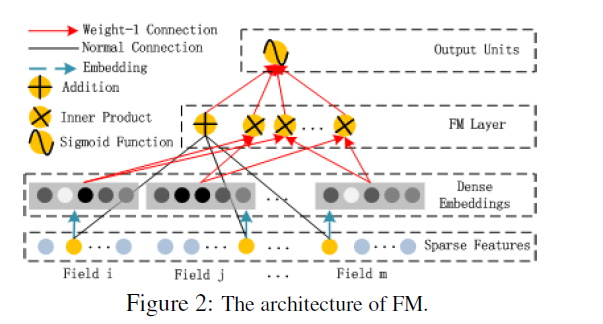
- FM Component는 (FNN) [Zhang et al., 2016] 에서 제안된 feature interaction을 학습하기 위한 Factorization machines 이다.
- FM은 각각 feature latent vector의 inner product (order-2)로 feature interaction을 모델링한다.
-
FM의 Output은 Addition Unit과 Inner Product Unit의 합으로 다음과 같이 표현된다.
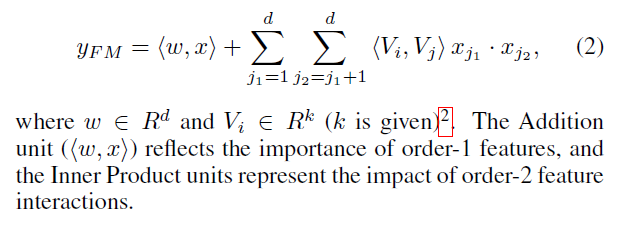
Deep Component
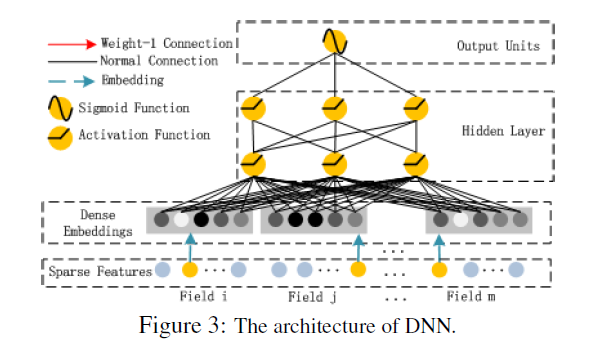
- Deep Component는 high-order feature interaction을 학습하기 위한 Feed-Forward Neural Network이다.
-
CTR prediction 모델의 Input data는 굉장히 Sparse하고 super high-demensional하다.
를 통해 Input vector를 low-order dense한 vector로 압축되어 NN에 입력된다.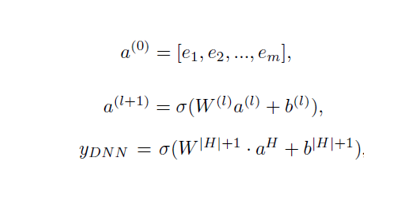
Relationshop with the other Neural Networks
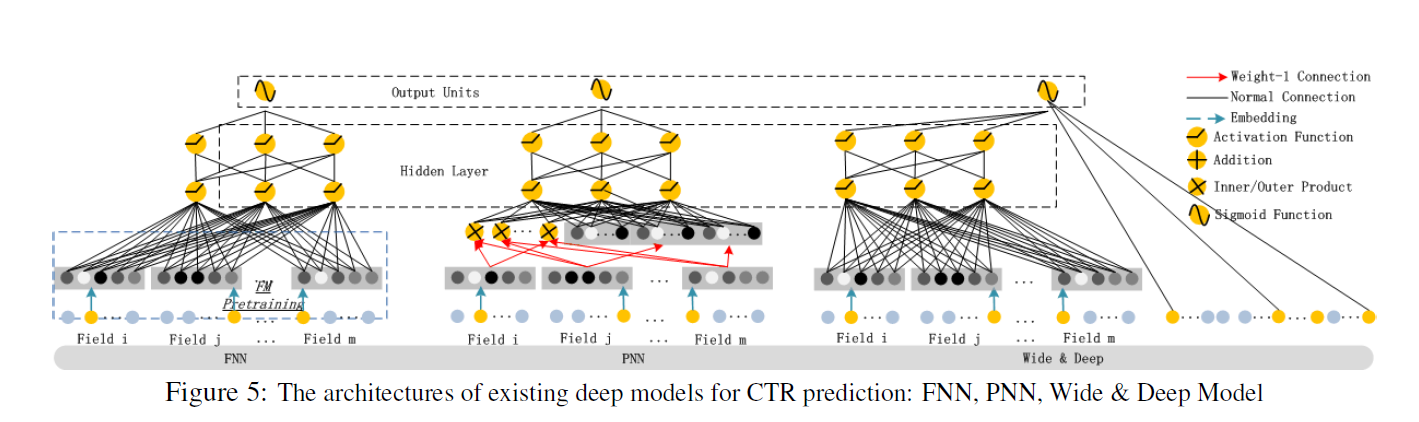
-
FNN [Zhang et al., 2016] : feature embeddings의 가중치를 FM에 의해 pre-trained 값을 initialization하기 때문에 두 가지 제한점을 가진다.
1) Embedding 파라미터가 FM의 영향을 받을 수 있다.
2) Pre_trained에서 도입된 Overhead로 효율성이 저하된다.
High-order feature interaction은 학습할 수 있지만 low order feature interaction은 학습 불가능 하다
DeepFM의 경우 사전 훈련이 불 필요하며, low & high order feature interaction 학습 가능하다. -
PNN [Qu et al., 2016] :
High order feature interaction을 포착하기 위해 와 사이에 를 추가한 모델이다. (내적), (외적), (내적 ,외적)계산을 효율적으로 하기 위해 (내적)을 할 경우 뉴런을 제거하고 (외적)을 할 때 차원을 압축하여 근사적으로 계산한다.
1) (내적)을 할 경우 reliable하지만 이후에 의 모든 neuron에 연결도기 때문에 High Computational Complexity가 요구된다.
2) (외적)을 할 경우 unstable하고 feature의 정보를 잃어 버린다.
3) 저차원 feature interaction이 무시된다.
DeepFM의 FM Component는 마지막 에만 연결된다.
-
Wide & Deep [Cheng et al., 2016] :
DeepFM과 다르게 Wide Part의 Input을 직접 feature engineering 해야한다.이 모델의 Linear Regression(LR)을 FM으로 바꾸면 DeepFM과 비슷하지만 DeepFM은 Feature Embedding을 share한다.
Embedding share 하는 방식은 low & high-order feature interaction을 표현하는 feature representation에 영향을 미쳐 더욱 정교하게 학습을 한다.(back-propagate manner)
DeepFM은 사전 훈련과 Feature engineering 없이 low & high-order feature interaction을 포착할 수 있다.
Experiments
Experiment Setup
DataSets :
1) Criteo DataSet : 4,500만 명의 유저 클릭을 포함한, 13개의 continuous feature과 26개의 categorical feature가 있다.
2) Company Dataset(아마 Huawei) :
- 실제 산업의 CTR prediction을 평가하기 위해 회사 데이터에서 실험을 해 보았다. 회사의 App store에서 연속된 7일의 유저 클릭 기록을 사용하여 다음 하루치를 evaluate 하였다.
- 10억개 가량의 기록, app과 관련된 feature(identification, category and etc)와 user feature(유저가 다운로드한 앱), context feature(operation time and etc)가 있다.
Evaluation Metrics :
1) Logloss
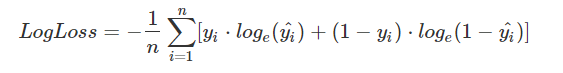
2) AUC Score
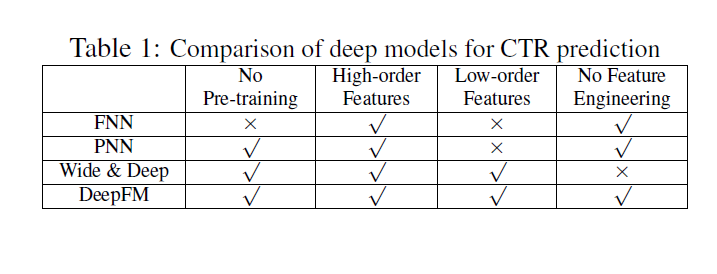
Model Comparison
- 9개의 모델 실험 비교
- LR, FM, FNN, PNN, Wide & Deep (Wide - LR & FM) , DeepFM
Performance Evaluation
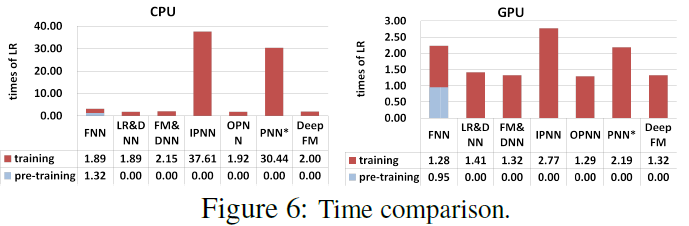
Effciency Comparison
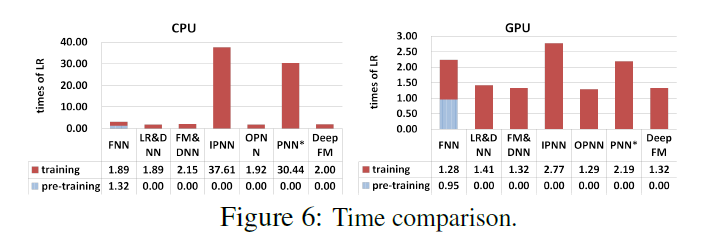
- LR 대비 학습시간에 걸린 시간을 나타내는 그래프
- FNN은 DeepFM에 비해 오래 걸린다. Pre-training에 시간을 많이 씀
- IPNN, PNN의 경우 Inner Product의 학습 속도가 굉장히 느려지는 걸 확인할 수 있다.
- Wide & Deep 모델보다는 살짝 느리지만 준수함
Effectiveness Comparison
-
Feature interaction이 표현되지 않은 LR보다 interaction을 표현하는 다른 모델들이 성능이 더 좋다.
-
Low-order & High-order feature interaction을 같이 학습하는 모델인 DeepFM과 Wide & Deep 모델이 다른 모델보다 성능이 좋다.
-
Feature embedding을 share하는 DeepFM이 성능이 더 좋다.
결과적으로 Wide & Deep 보다 AUC와 LogLoss 측면에서 각각 0.37% point, 0.42% point 성능이 좋아 졌다. 근소한 차이지만 Wide & Deep 논문에 의하면 Offline에서 0.275% 포인트 차이가 Online CTR에서는 3.9% point 차이로 이어졌다. 회사 AppStore에서 일일 전환율이 수백만 달러이기 때문에 작은 비율 상승은 년간 수 백만 달러의 추가 이익을 가져온다. 성능 향상이 효과적임을 확인할 수 있다. -Wide & Deep [Cheng et al., 2016]
Conclusions
-
이번 논문에서는 기존의 CTR예측 SOTA 모델의 단점을 극복하고 더 좋은 성능을 보인 모델인 FM기반 신경망 모델 DeepFM을 제시했다. DeepFM은 Deep Component와 FM Component를 jointly 학습한다. 이런 방식은 세 가지 장점이 있다.
1) pre-training이 필요하지 않다.
2) 높은 차원과 낮은 차원의 피쳐 상호작용을 같이 학습한다.
3) Feature Engineering이 필요 없도록 feature embedding을 공유하는 전략을 사용한다.
두 개의 real-word datasets 상에서 effectiveness측면이나 efficiency 측면을 다른 SOTA 모델과 비교했다. 실험 결과는 1) DeepFM이 AUC와 Logloss 지표에서 SOTA모델을 앞질렀고 2) 제일 efficient한 모델과 비교할 만큼 성능이 좋았다.
-
두 가지 후속 연구 방향이 있다. 하나는 높은 차원의 피쳐 상호작용을 강화하는 방법(예를 들면 pooling layer를 도입)을 탐색해보는 것이고 다른 하나는 GPU cluster상에서 large-scale problem을 DeepFM에서 학습하는 것이다.
참고 자료

5개의 댓글

[15기 장아연]
추천시스템에서는 유저의 행동에 대한 복잡한 상호관계를 익히는 것이 매우 중요함. 기존에는 낮거나 높은 상호관계 중 한 쪽에 치우져 학습하거나 따로 feature engineering이 요구된다는 한계점이 있음.
해당 논문은 낮은 차원(low-order), 고차원(high-order)의 feature interactions을 End-to-End 모델로 학습할 수 있음을 보임. 바로 feature latent vector의 inner product (order-2)로 feature interaction을 모델링하는 Factorization Machines(FM)와 high-order feature interaction을 학습하기 위한 Feed-Forward Neural Network인 Deep Neural Network(DNN)의 구조를 결합한 새로운 NN모델인 DeepFM을 제시함. FM에서는 낮은 차원(low-order)의 feature interactions에 대한 학습이 이루어지는 부분으로 feature latent vector inner product가 이루어짐. Deep Component는 고차원(high-order)의 feature interactions에 대한 학습이 이루어지는 부분으로 data의 Sparsity 문제로 인해 Embedding layer를 거쳐 low dimensional 하고 dense하도록 변환함.
이 모델은 pre-training이 불필요하고 높은 차원과 낮은 차원의 피쳐 상호작용을 같이 학습하고 feature embedding을 공유해 Feature Engineering이 불필요하다는 장점을 가지고 있음.

[Paper Review] (2017, Huifeng Guo) DeepFM : A Factorization-Machine based Neural Network for CTR
15 류채은
요약:
추천 시스템에서 CTR을 최대화 하기 위해서는 유저 행동에 숨겨진 복잡한 상호관계(feature interaction)을 학습하는 것이 중요하다.
[정의]
클릭률(CTR): 광고를 본 사용자가 해당 광고를 클릭하는 빈도의 비율
CTR Prediction-> User가 추천 아이템을 클릭할 확률을 추정하는 것으로 유저에게 추천될 아이템의 순위를 매길 수 있다.
**implicit feature interactions을 학습하는 것이 중요
[모델]
- Deep Fm(Factorization Machine+Deep Neural Network)
- 같은 input을 통해 FM Component(low-order feature interaction)와 Deep Component(high-order feature interaction)을 학습하는 것을 목표
- FM Component(feature interaction을 학습하기 위한 Factorization machines)
- Deep Component( high-order feature interaction을 학습하기 위한 Feed-Forward Neural Network)
[성능]
- Feature embedding을 share하는 DeepFM이 성능이 더 좋다.
- 성능 향상이 다른 모델에 비해 효과적이었다.
[의의]
1. pre-training이 필요하지 않다.
2. 높은 차원과 낮은 차원의 피쳐 상호작용을 같이 학습한다.
3. Feature Engineering이 필요 없도록 feature embedding을 공유하는 전략을 사용한다.

[15기 강지우]
- 모델의 목표는 유저와 아이템간의 관계만을 보는 것에서 벗어나 여러 요소의 관계성을 파악해서 CTR을 예측하는 것.
- input : 유저, 아이템 원핫벡터, 성별, 나이와 같은 여러 요소(이를 원핫인코딩할 수도 있다.)
- output : 해당 유저가 해당 아이템을 클릭할 확률
- DeepFM 구조
x의 각 field의 길이가 다르고, sparse하고 차원이 크기때문에 모든 field의 차원을 동일하게 임베딩한다.
임베딩 벡터들을 FM에서는 low order feature interection을 포착하고(FM은 두개의 요소의 관련성만 볼 수 있기 때문에), DNN에서는 high order feature interection을 포착한다.
이러한 구조는
1) pre-training이 필요하지 않다.
2) 높은 차원과 낮은 차원의 피쳐 상호작용을 같이 학습한다.
3) Feature Engineering이 필요 없도록 feature embedding을 공유하는 전략을 사용한다.
위 3가지 장점을 가질 수 있었다.
MF와 DNN의 결합이라는 점에서 NCF모델과 비슷하다는 느낌을 받았다. 그러난 NCF와 비교되는 점은 유저와 아이템간의 상호작용뿐만 아니라 여러특성들을 고려해서 예측할 수 있다는 점이었다.
14기 박지은
DeepFM은 CTR을 예측하기 위한 모델로 factorization machine의 장점과 deep learning의 장점을 결합한 새로운 neural network 기반 모델입니다. Factorization machine에서는 low-order의 feature interaction을, deep learning에서는 high-order feature interaction을 다루는데, 이 때 input과 embedding layer를 서로 공유하기 때문에 효율적 학습이 가능하다고 합니다. 입력은 연속형 변수와 범주형 변수가 모두 함께 들어갈 수 있는데, embedding layer에서 범주형 변수는 원핫벡터로 인코딩해줍니다. 다음으로, FM component는 feature interaction을 학습하기 위한 factorization machine으로 각각 feature latent vector의 내적으로 feature interaction을 모델링합니다. Deep component는 high-order feature interaction을 학습하는 feed-forward neural network로 각각 나온 output을 더하여 시그모이드 함수를 취해주면 최종 출력이 나옵니다. 별도의 feature engineering 없이 높은 차원과 낮은 차원의 feature의 상호작용을 같이 end-to-end로 학습할 수 있는 신기한 모델이었습니다. 좋은 강의 감사합니다.
[15기 이성범]
추천 시스템에서 모델의 성능을 최대화 하기 위해서는 유저 행동에 숨겨진 복잡한 feature interaction을 학습하는 것이 매우 중요하다. 본 논문에서 제시한 DeepFM 이전의 모델들은 대부분 고차원 또는 저차원의 feature interaction에 치우쳐 학습하거나 전문가의 feature engineering이 필요했다. 그러나 본 논문에서 제시한 DeepFM 모델은 feature engineering 없이 저차원과 고차원의 feature interaction을 End-to-End 모델로 학습할 수 있다. 따라서 DeepFM 모델은 Factorization machines이 기지는 장점과 Deep Learning이 가지는 장점을 결합했다고 볼 수 있다.
DeepFM 모델은 Wide & Deep 모델을 발전시킨 모델로 볼 수 있다. 기존의 Wide & Deep 모델은 Wide 부분을 학습시키기 위해서 feature engineering이 필요했지만 DeepFM의 FM Component와 Deep Component가 같은 Embedding Layer를 공유하기 때문에 feature engineering이 필요 없으며, 가중치 초기화 없이 End-to-End 방식으로 학습이 가능하다.
DeepFM 모델은 FM Component와 Deep Component로 이루어져 있다. FM Component는 저차원의 feature interaction을 학습시키는 부분으로 input에 대한 각각의 feature latent vector의 내적으로 feature interaction을 학습한다. Deep Component는 고차원의 feature interaction을 학습시키는 부분으로 매우 sparse한 input data를 Embedding Layer를 통해서 저차원의 dense한 Vector로 압축하여 feature interaction을 학습한다.
DeepFM 모델은 기존의 CTR예측 SOTA 모델의 단점을 극복하고 더 좋은 성능을 보인 모델이며, pre-training이 필요하지 않고, 고차원과 저차원의 feature interaction을 같이 학습하고, feature embedding을 공유하여 feature engineering이 필요 없도록 했다는 장점을 가진다.