Lecture 1 - Introduction and Word Vectors

작성자 : 서울여자대학교 정보보호학과 강의정
CS224n
Lecture 1 - Introduction and Word Vectors
Lecture Plan
- The course
- Human language and word meaning
- Word2vec introduction
- Word2vec objective function gradients
- Optimization basics
- Looking at word vectors
Human Language

- 언어는 불확실한 시스템이며 담고 있는 의미도 많지만 우리는 어느정도 의사소통을 잘 할 수 있다.
- Yann Le Cun, "오랑우탄과 인간의 지능은 비슷하다"
- 하지만 오랑우탄은 인간처럼 행동할 수 없다.
- 인간에게는 Language가 있다.
- Language는 약 100,000년전 발명된 것으로 예측되고 있다.
- Writing은 약 5,000년 전에 발명된 것으로 예측되고 있다.
- Language는 우리의 뇌에 압축되어 들어갈 수 있다.
So that's why language is good!!
How do we represent the meaning of a word
meaning
- the idea that is represented by a word, phrase, etc
- the idea that a person wants to express by using
words, signs, etc - the idea that is expressed in a work of writing, art, etc.
Commonest linguistic way of thinking of meaning:
denotational semantics
signifier (symbol) ⟺ signified (idea or thing)
How do we have usable meaning in a computer?
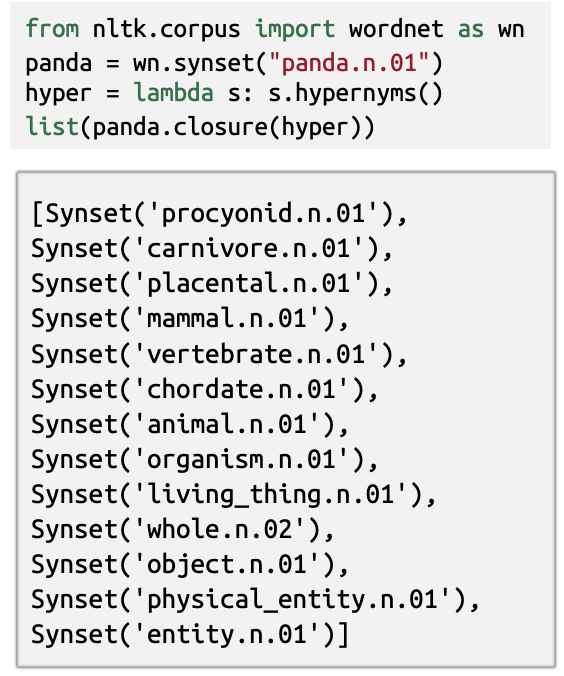
WordNet
: a thesaurus containing lists of synonym sets and hypernyms
- synonym sets containing "good"

- hypernyms of "panda"
Problems with resources like WordNet
- Great as a resource but missing nuance
- e.g. "proficient" is listed as a synonym for "good".
This is only correct in some contexts.
- e.g. "proficient" is listed as a synonym for "good".
- Missing new meanings of words
- e.g., wicked, badass, nifty, wizard, genius, ninja, bombest
- Impossible to keep up-to-date!
- Subjective
- Requires human labor to create and adapt
- Can’t compute accurate word similarity
One Hot Vector
- Traditional NLP (약 2012년까지)

Vector dimension = number of words in vocabulary (e.g., 500,000)
Problem:
- Vector Dimension
- similarity
Solution:
- Could try to rely on WordNet’s list of synonyms to get similarity?
- But it is well-known to fail badly: incompleteness, etc.
- Instead: learn to encode similarity in the vectors themselves
Distributional Semantics
- One of the most successful ideas of modern statistical NLP
- When a word w appears in a text, its context is the set of words that appear nearby (within a fixed-size window)

Word Vector
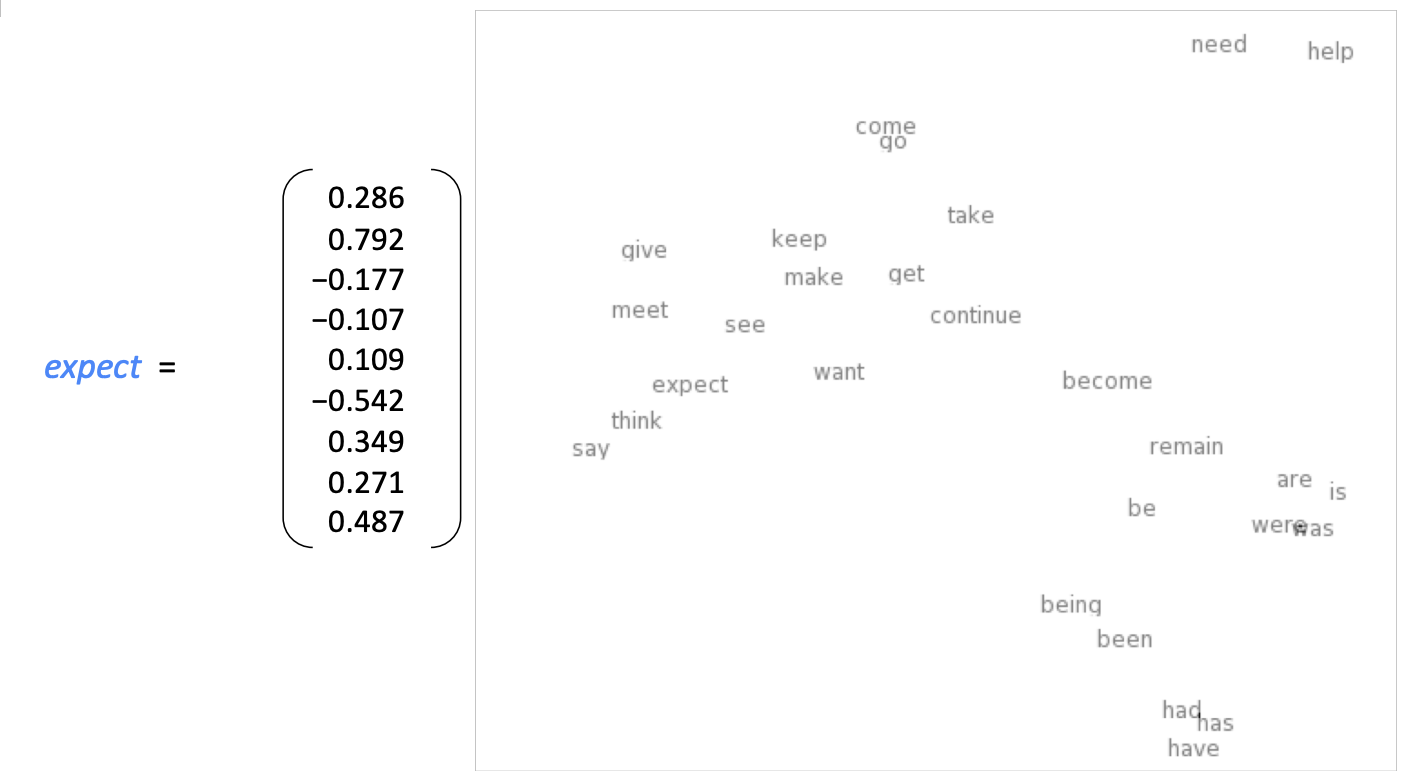
- word embeddings or word representations
- Vector의 크기는 최소 30이며 크게는 1,000 ~ 4,000 정도이다.
- vector space : word를 배치한 공간
Word2Vec
: Word2vec (Mikolov et al. 2013) is a framework for learning word vectors
Idea
- We have a large corpus of text
- Every word in a fixed vocabulary is represented by a vector
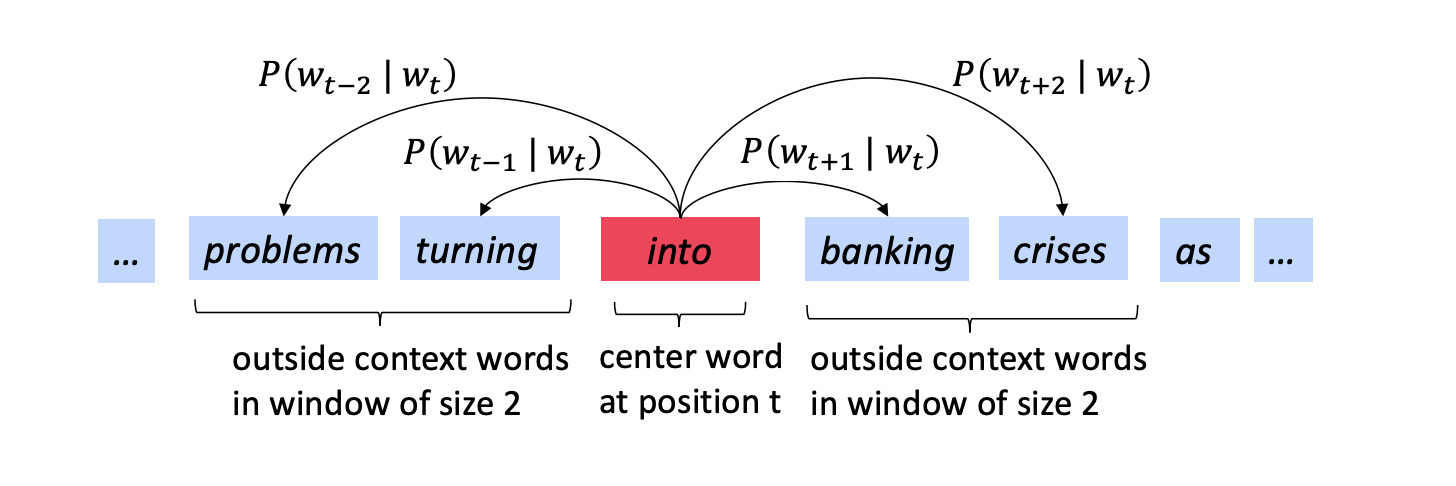
- Go through each position t in the text, which has a center word c and context ("outside") words o
- Use the similarity of the word vectors for c and o to calculate the probability of o given c (or vice versa)
- Keep adjusting the word vectors to maximize this probability
Example windows and process for computing
Next..
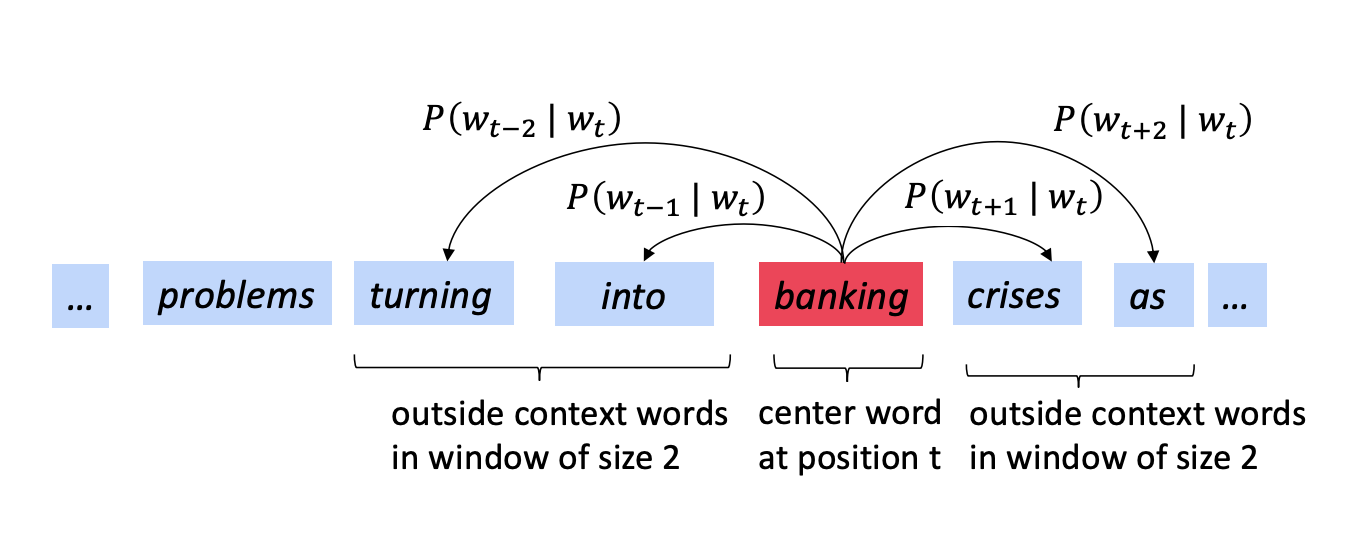
Likelihood
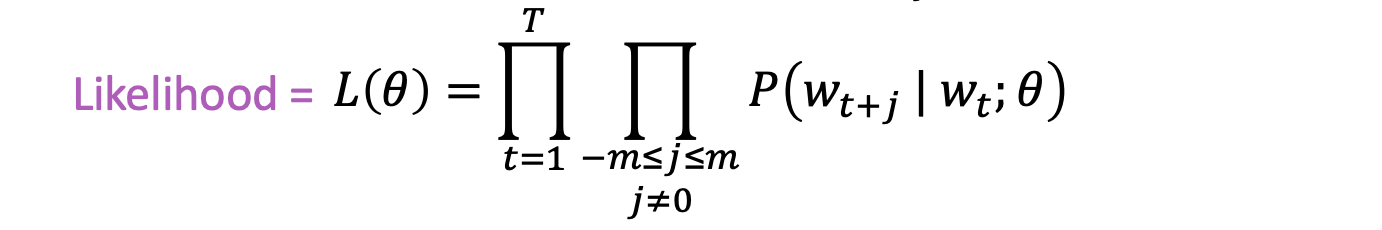
- For each position t = 1, … , T, predict context words within a window of fixed size m, given center word Wj
- 유일한 매개 변수는 단어들의 벡터이다.
Objective function
: objective function is the (average) negative log likelihood
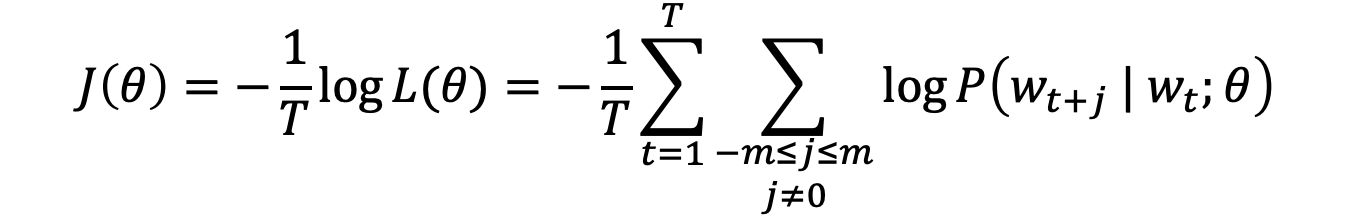
- 마이너스를 붙여 Minimize하는 방향으로 바꾼다.
- 1/T를 곱하여 평균을 계산한다.
- 추후 곱셈을 덧셈으로 바꾸기 위해 log를 붙인다.
Minimizing objective function ⟺ Maximizing predictive accuracy
계산
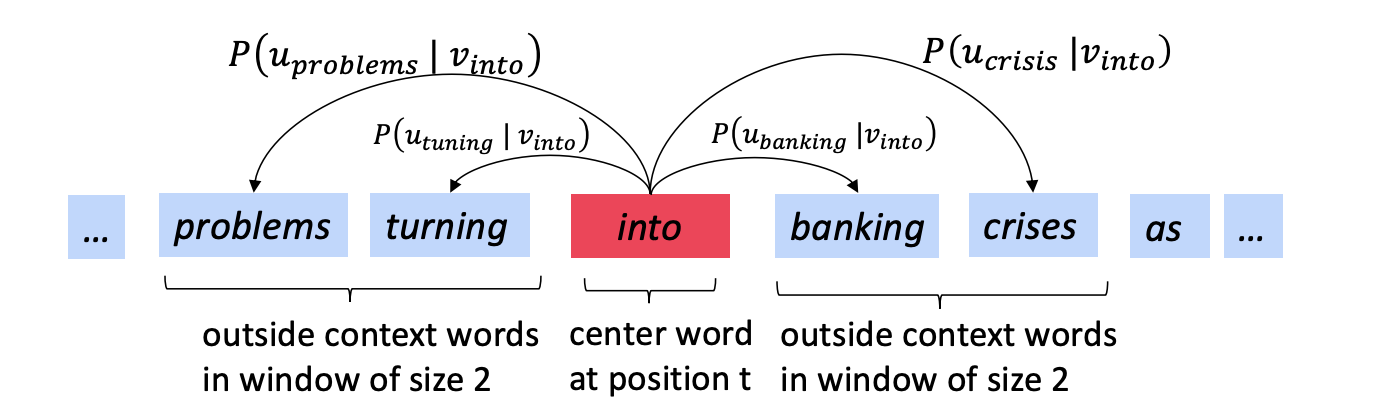
- 중심 단어를 기준으로 해당 맥락에서 예측될 확률을 구합니다.
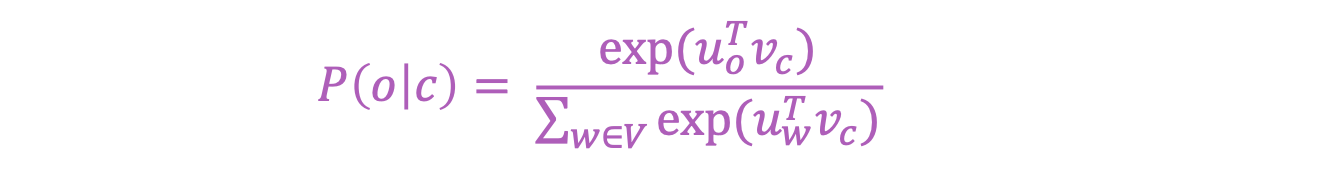
- C : Center Word, O : context Word
- exponential을 사용하여 양수 표현
- Vector 간의 dot product로,두 Vector 간의 유사도 측정
Optimization
Object Function을 최소화 하는 를 찾는다.
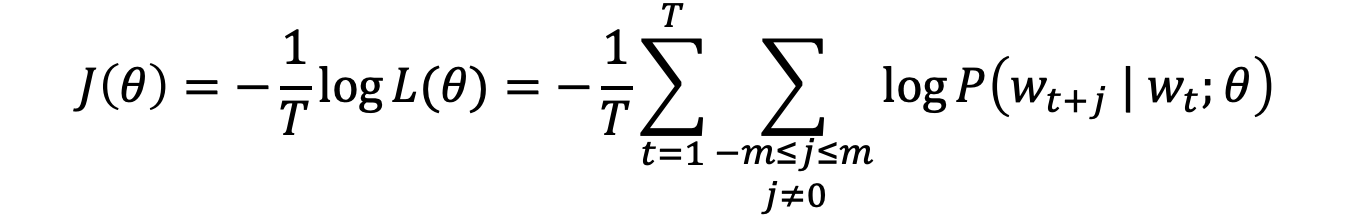
𝜽
- V개의 단어, d차원, u와 v를 갖으므로 2dV차원이다.
- 각 벡터들은 Random Value로 시작한다.
Word2vec derivations of gradient
Object Function 최소화를 위해 center word, context word로 각각 미분

gradient descent를 활용하여 예측율을 올릴 수 있다!
Reference
CS224n 2019 - lecture01. Introduction and Word Vector (slides)(https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture01-wordvecs1.pdf)

12개의 댓글

투빅스 14기 한유진
- WordNet(단어사전) : 유의어, 상위어의 집합입니다. 단어에 대한 의미 차이, 신조어 반영 X, 단어 간의 유사도를 계산할 수 없다는 단점이 있습니다.
- One-Hot vector : 단어를 벡터로 표현할 수 있는 가장 간단한 방법으로 이 방법 역시 단어 간의 유사도를 계산할 수 없고 단어가 많아질수록 차원이 커지게됩니다.
- Word2Vec : 위의 방법들을 보완하기 위해 등장한 개념입니다. 비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다는 word embedding방식을 기반으로 한 방법(word vector를 학습하는 framework)입니다. Word2Vec의 object function은 center word가 주어졌을때, window 내의 context word가 해당 위치에 나타날 확률의 곱 L(𝜽)를 T(window size)로 나눠 평균을 계산하여 minimize하는 것입니다.
human language부터 시작해서 Word2Vec까지의 기초를 잘 설명해주셔서 좋았습니다. 좋은 강의 감사합니다!

word2vec의 목적함수 미분이 잘 이해가 가지 않았는데, 한눈에 보기 쉽게 써주셔서 이해하기 쉬웠던 것 같습니다.
- word2vec 목적함수 미분의 마지막을 보면 가 있습니다. 이 식이 의미하는 것이 중심단어 벡터 와 주변 단어가 등장했을 때 등장할 단어의 기대값(혹은 주변단어가 등장했을 때 등장할 법한 단어 벡터)의 차이입니다. 그래디언트 디센트는 해당 식을 최소화하고자 하기 때문에, 주변 단어가 등장 했을 때 등장할 단어의 기대값(혹은 기대 벡터?)와 중심단어 벡터의 차이를 줄이고자 합니다. 이는 주변단어 c가 등장했을 때 중심단어가 등장하도록 파라미터를 업데이트하는 식이라고 할 수 있습니다.
word2vec에 대해 자세히 살펴볼 기회가 되어서 정말 좋았던 것 같습니다. 감사합니다.

- One-hot-vector : 모든 단어에 대해 0/1로 표현하는 방법은 단어 벡터들이 Orthogonal 하기 때문에 단어간 유사도를 계산할 수 없고, 차원이 무한하게 되므로 사용되지 않는다.
(Word2Vec의 초기 시작벡터로는 활용됨) - Word2Vec : 따라서 단어의 의미를 문맥을 통하여 결정하는 Distributional Semantics 방법을 활용하자는 아이디어가 나오고 대표적으로 Word2Vec이 있다.
- CBOW : CBOW는 주변단어에서 중심단어를 유추하는 방법이다.
- Skip-gram : 중심단어에서 주변단어를 유추하는 방법이다.
- CBOW가 주변단어가 여러개이고 유추해야할 단어가 하나이기 때문에 더욱 성능이 좋을 것이라고 예상했지만 실제로는 Skip-gram이 성능이 대체적으로 훌룡하다. 그 이유는 실제 학습과정을 살펴보면 CBOW는 업데이트 과정을 한번 가지지만, Skip-gram은 업데이트 과정을 Window-size의 두배만큼 가지기 때문에 실제로 휙득하는 정보량이 더 많기 때문이다.
NLP 공부를 위한 기초를 잘 다질 수 있었습니다. 감사합니다 :)

투빅스 14기 정재윤
투빅스 14기 강의정님께서 cs224n의 lecture 1에 대해서 발표해주셨습니다.
- 전통적인 NLP 방식에서는 One Hot Encoding 방식을 사용했다. 하지만 이 방법을 사용하면 차원이 너무 많이 늘어나면서 연산량이 기하급수적으로 늘어나가 되면서 다른 방식을 모색하기 시작했다.
- 이를 보완하기 위한 방법 중 하나가 바로 Word2vec으로 window에 해당하는 주변 단어들을 바탕으로 target 단어가 나올 확률을 구한 뒤, 가장 확률이 높은 단어를 예측하는 방식이다. 최종적으로 softmax를 구하는 방식과 큰 차이가 없다.
word2vec의 gradients를 구하는 방식을 수식으로 상세하게 설명해주신 점이 인상깊었습니다. 감사합니다.

투빅스 14기 이정은
- 초기에는 One-hot vector를 사용하여 단어를 vector로 표현하고, 유의어와 상위 의미가 포함된 사전인 WordNet으로 단어 간의 similarity를 계산해냈다. 이는 단어가 많아질수록 차원이 커지는 문제가 발생합니다.
- 이를 해결하기 위해 등장한 Word2vec는 word vector를 학습하는 프레임워크 중 하나로, 중심 단어(center word)가 주어지면 주변 단어(context word)와의 similarity를 이용해 주변 단어가 해당 위치에 올 확률이 최대가 될 수 있게 학습을 진행합니다.
특히 word2vec의 목적함수의 미분 계산 과정을 자세히 설명해주신 점이 좋았습니다. 감사합니다 : )

투빅스 15기 이윤정
- 전통적인 NLP에서 사용된 wordnet과 one hot vector의 경우 각각 뉘앙스나 신조어를 파악할 수 없다는 것과 유사도를 계산할 수 없다는 단점이 있습니다.
- 이러한 방법론을 보완하기 위한 워드 임베딩 방법론 중의 하나인 word2Vec은 주변어와 중심어 벡터의 내적이 코사인 유사도가 되도록 단어 벡터를 벡터공간에 임베딩하는 알고리즘이라고 볼 수 있습니다. word2Vec은 중심어를 통해 주변어를 맞추거나(Skip-gram), 주변어를 통해 중심어를 맞추기 위해(CBOW) 학습이 이루어지는 구조입니다.
앞으로 텍스트 세미나를 진행하면서 필요할 공부의 기초를 자세하게 배울 수 있어 좋았습니다. 특히, word2Vec의 gradient descent 부분의 수식 부분을 자세히 알려주신 부분이 좋았습니다. 감사합니다.

투빅스 15기 조효원
nlp의 목표는 사실상 컴퓨터로 하여금 언어의 의미를 이해하도록 하는 것이다. 하지만 컴퓨터는 연산 도구에 불과하기에 숫자의 형태로 단어를 바꾸어줘야 한다. 이를 위해 tree형태의 단어 사전은 wordnet, 즉 시소러스 방식이 빈번하게 사용되었다. 하지만 이는 업데이트의 비용이 굉장히 비싸고 주관적이라는 단점이 있다. 따라서, 인간이 직접 관여하지 않는 방식을 생각했는데, 가장 간단한 방식은 one-hot encoding 방식이다. 그러나 이 방식은 단어의 의미를 나타낼 수 없고 차원이 지나치게 커진다는 단점이 있었다. 즉, one-hot의 큰 차원과 의미정보를 담지 못한다는 단점을 해결한 것이 바로 embedding 기법이며, 대표적으로 word2vec이 있다. 이는 분포의미론에 기반을 한 임베딩 기법으로, 주변 단어를 통해 중심단어를 예측하는 CBOW와 중심단어를 통해 주변 단어를 예측하는 SKIP_GRAM 모델로 나누어진다.
강의를 보았을 때, 빠르게 지나가 완벽하게 이해하기 어려웠던 목적함수의 미분 부분을 잘 정리해주셔서 너무 좋았습니다. 감사합니다!
투빅스 15기 이수민
- WordNet과 같이 유의어(synonym)과 상위어(hypernym)을 사용하는 것: WordNet을 사용하면 단어와 단어 간의 관계, 즉 유사도(similarity)를 계산할 수 없다는 문제점이 있다.
- 단어를 컴퓨터가 이해할 수 있도록 표현할 수 있는 가장 간단한 방법인 one-hot vector 또한 단어 간 유사도를 계산할 수 없으며 단어의 개수가 많아질수록 차원이 커지며 sparse해지게 되는 문제점이 있다.
- 단어를 벡터로 표현하는 또 다른 방법인 distributional semantics을 이용한 단어 표현: Distributional semantics는 동일한 문맥에서 사용되는 단어는 비슷한 의미를 가지는 경향이 있다는 것을 의미한다. 즉, 단어 w가 출현할 때 window-size 내의 단어들의 집합인 w의 context는 주변에 나타난다는 것. 단어 w의 많은 context를 사용하여 w의 표현(representation)을 생성한다.
- 위 문제점을 해결하기 위해 Word2Vec 등장: 해당 단어가 context에 있을 확률을 계산. 이 확률을 최대화하기 위해 단어 벡터를 계속 조정하는 과정을 반복한다.
수식 부분을 자세하게 설명해 주셔서 이해하는 데에 도움이 많이 되었습니다. 감사합니다 😊

투빅스 15기 김동현
-
예전에는 One-hot vector를 사용하여 단어 간의 유사도를 계산했다. 하지만 단어가 많아질수록 차원이 커져 비용이 많이드는 단점이 있다.
-
이를 보완하기 위해 등장한 Word2vec은 문맥을 통해 결정하는 방법으로 중심단어와 주변단어를 활용하여 word vector를 학습하는 방법이다.
-
CBOW는 주변단어로 중심단어를 유추하고, Skip-gram은 중심단어로 주변단어를 유추하는 방법이다.
word2vec의 기초를 살표볼 수 있어 좋았고, 수식을 자세히 설명해주셔서 이해가 잘되었습니다. 감사합니다 :)

투빅스 15기 조준혁
- NLP 강의에 대한 전반적인 소개가 있었습니다. 언어란 인간만의 고유한 소통 수단으로 이를 분석하고 처리하는것은 엄청나게 가치가 있을것입니다.
- 기존의 Sparse한 onehot vector와 달리 단어의 고유한 의미를 고려한 Word2Vec의 개념을 확실히 할 수 있어 좋았습니다.

투빅스 14기 박준영
투빅스 14기 강의정님께서 cs225n의 lecture 1에 대해서 발표해주셨습니다.
- onehot encoding은 벡터의 단어가 늘어날 수록 연산량이 늘어나는 단점이 있었습니다.
- 그래서 word2vec을 고안했는데, word2vec은 중심단어와 주변단어를 벡터로 표현하고 벡터의 내적이 코사인 유사도가 되도록 단어벡터를 임베딩하는 방법입니다.
Word2Vec의 목적함수와 최적화 방법을 수식적으로 잘 풀어주셔서 유익한 강의였습니다!
감사합니다
NLP 공부를 시작하는 데에 있어서 잡고 가면 좋을 언어에 대한 접근을 들을 수 있어 좋았습니다.
Word2Vec의 목적함수 수식도 잘 풀어 설명해주신 것 같았습니다. 감사합니다 :)