FCN (Fully-Convolution Network for semantic segmentation) 리뷰

FCN(Fully-Convolution Network for semantic segmentation) 리뷰
2021년 10월 기준으로 26376회의 인용. semantic segmentation의 포문을 연 논문이라고 할 수 있습니다.
뒤이어 등장하는 모델들도 FCN의 한계점을 지적하며 이를 보완한 모델을 제시하기 때문에 FCN을 이해하는 것이 매우 중요합니다.
Abstract
- fully convolutional network는 input size에 영향을 받지 않는다.
- image classification network를 fine-tuning하여 사용할 수 있다.
- skip connection 아키텍쳐를 추가했다.
abstract에서는 위의 3가지 정도의 요점을 이야기하고 있습니다.
앞으로는 FCN 구조의 핵심과 관련된 부분을 살펴보도록 하겠습니다.
Semantic Segmentation
semantic segmentation task를 우선 이해해봅시다.
semantic은 의미 segmentation은 분할입니다. 이미지의 물체 종류별로 구분짓는 것입니다.
아래는 segmentation이 된 예시입니다.

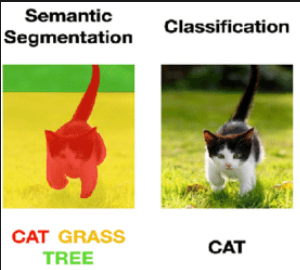
Image Classification이 이미지 전체를 분류하는 것이라면
semantic segmentation는 픽셀 단위로 분류하는 것입니다.
FCN의 구조


FCN은 Classification backbone + upsampling 이라고 간단하게 말할 수 있습니다.
기존의 image classificaiton model에서 classification을 하는 뒷단의 dense layer를 제거하고 upsampling을 하는 layer를 추가하여
input과 동일한 h, w를 가지고, 각 픽셀의 class를 나타내는 class 개수만큼의 채널을 가지는 ouput이 만들어집니다.
- input : (3, w, h)
- ouput : (class_num, w, h)
FC-layer vs Fully Conv layer
FCN에서 classification FC-layer를 Fully convolution layer으로 대체하였습니다.
.png)
이는 아래와 같은 장점을 가집니다.
- input size에 독립적이다.
- 공간 정보를 손실하지 않는다.
FC-layer는 input size에 따라 고정된 노드수를 갖기 때문에 input size가 변하면 network 구조도 변경되어야 합니다.
하지만 Fully convolution layer는 kernel을 이용하기 때문에 구조의 변경이 필요하지 않습니다.
위의 그림에서 FC-layer는 flatten을 하면서 공간정보를 잃어버리는 반면 Fully convolution layer는 1x1 conv를 사용하여 공간정보를 유지하면서 shape을 바꿀 수 있습니다.
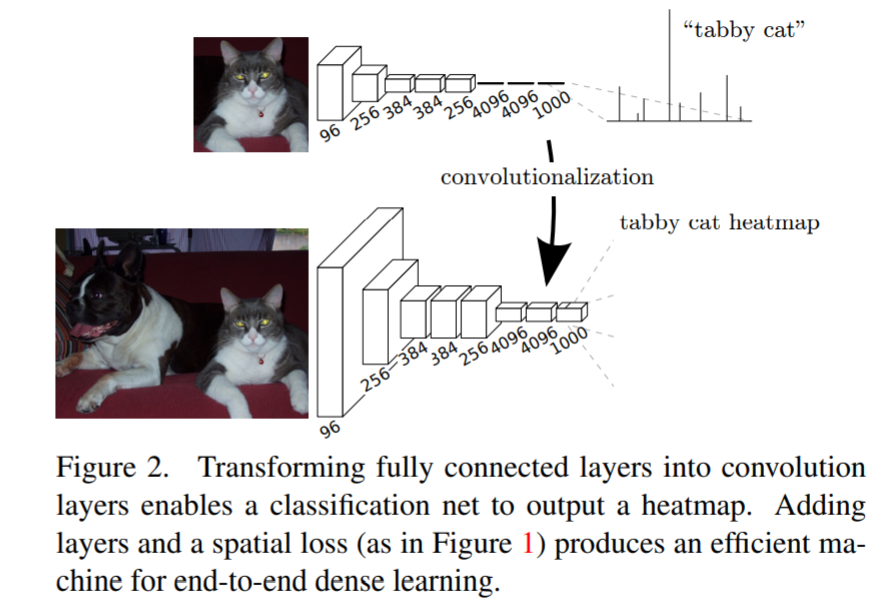
*논문의 Adapting classifiers for dense prediction 참고
Transposed convolution
Transposed convolution

출처
transposed convolution은 위와 같이 learnable한 kernel을 적용한 conv를 진행하여 upsampling을 하는 것입니다.
{kind=link}
Transposed convolution과 deconvolution
많은 논문에서 deconvolution를 transposed convolution과 동일하게 사용하는데, 이는 엄밀히 말하면 틀린 표현입니다.
두 연산을 아래와 같은 차이점을 가집니다.
- transposed convolution은 input을 그대로 복원하지 않습니다.
- kernel이 학습됩니다.
convolution의 역연산을 뜻하는 deconvolution과 다릅니다.
transposed라는 이름이 붙은 이유가 존재합니다.
input : 4x4, output : 2x2, kernel : 3x3 , stride = 1, padding = 0인 convolution연산을 행렬로 나타내면 아래와 같습니다.
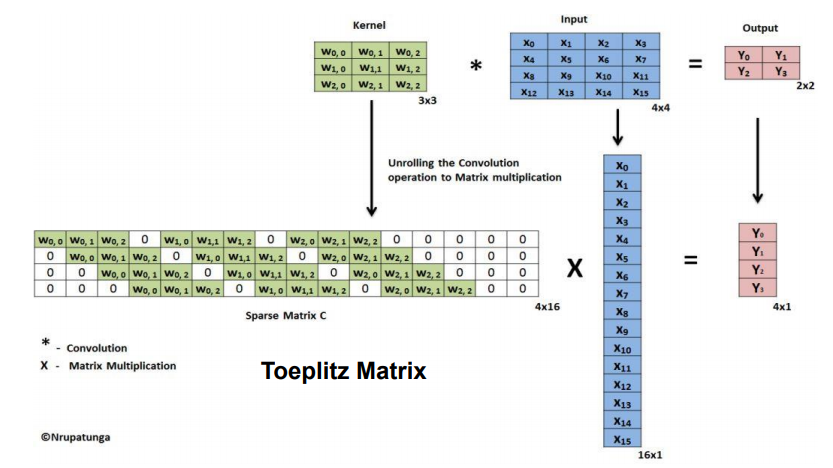
convolution matrix를 transposed해서 원래의 output과 곱해주면 원래의 input size크기의 output이 나오게됩니다.
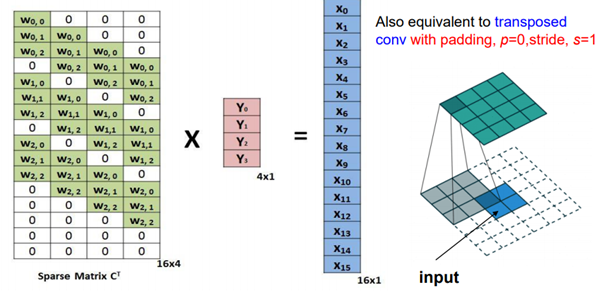
이때 transposed convolution의 output은 원래의 input과 동일하지 않습니다.
*논문의 Upsampling is backwards strided convolution부분 참고
Skip connection
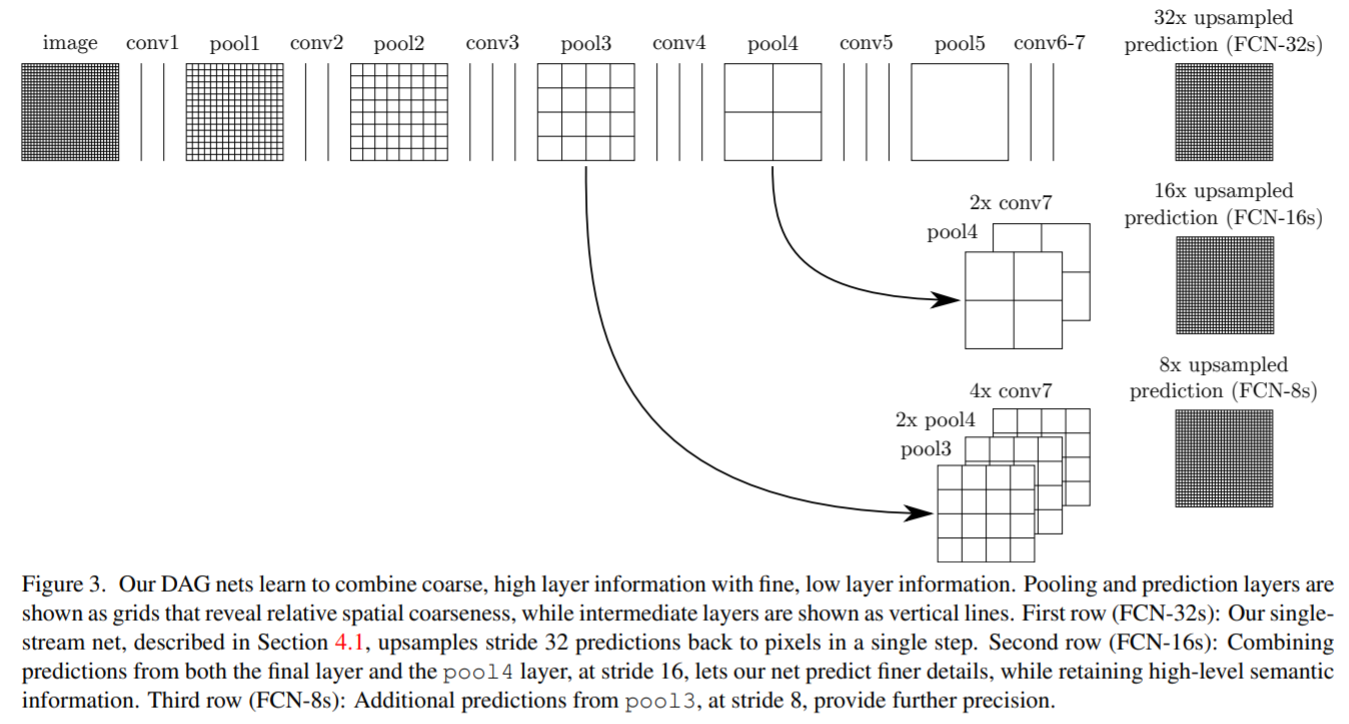
본 논문에서는 앞단에서의 여러번 pooling이 적용되기 전의 정보를 뒷단에 더해줍니다.
pooling layer를 5번 거친 마지막 feature map의 2배 키워서
pool4의 feature map과 더한 후 (1/16)
이를 2배 키워서 pool3의 feature map과 더합니다.(1/8)
원래의 사이즈로 복원해야하므로 이를 다시 8배 키워줍니다.
정보의 손실이 있기전의 정보를 뒷단에 더해줌으로써 성능의 향상을 이룰 수 있었습니다.
성능
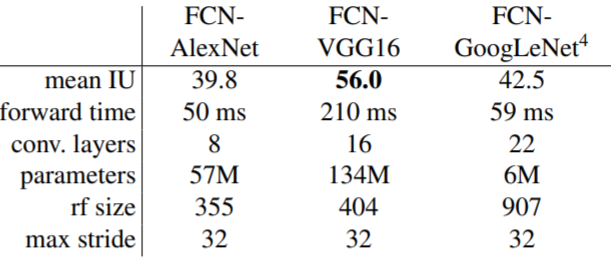
VGG backbone의 성능이 가장 좋았다고 합니다.
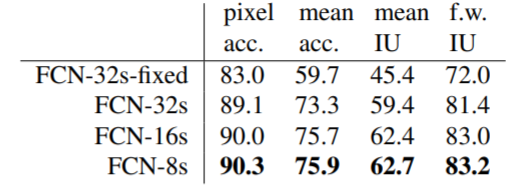
skip connection을 적용한 결과이고, 8s가 가장 좋음을 볼 수 있습니다.
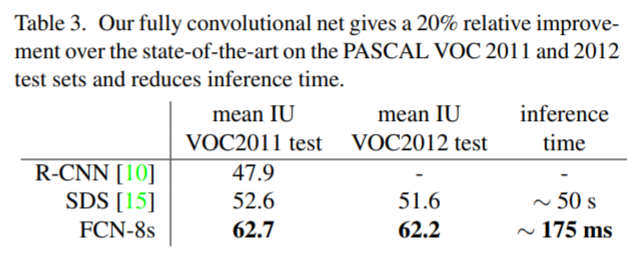
당시 SOTA모델에 비해 20%정도의 성능 향상을 이뤘습니다.

4개의 댓글

안녕하세요 투빅스 16기 전민진입니다.
- FCN은 sematic segmentation의 task에 큰 영향을 끼친 논문입니다.
- semantic segmentation은 픽셀 단위로 분류하는 task입니다.
- FCN은 기존의 CNN구조에 원래의 input size로 up-sampling과정을 더한 모델이라고 할 수 있습니다.
- up-sampling을 해줌으로써 input size에 독립적이고, 공간 정보를 손실하지 않는다는 장점을 가집니다.
- 또한 본 논문에서는 앞단의 정보를 skip connection을 통해 뒷단에 전달해줍니다. 정보 손실이 있기 전의 정보를 뒷단에 더해줌으로써 성능 향상에 기여할 수 있었습니다.

16기 김경준입니다.
FCN에 대한 정리를 블로그에 올렸습니다.
https://velog.io/@kimkj38/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-FCN-Fully-Convolutional-Networks-for-Semantic-Segmentation
15기 이윤정입니다.