[CS224N] Lecture 11 - Question Answering
Goal of QA
질문에 natural language로 자동으로 답하는 시스템 구축하는 것
문제에는 굉장히 다양한 유형이 있으며, QA를 통해 우리는 실생활에서 굉장히 유용한 어플리케이션을 사용할 수 있습니다.
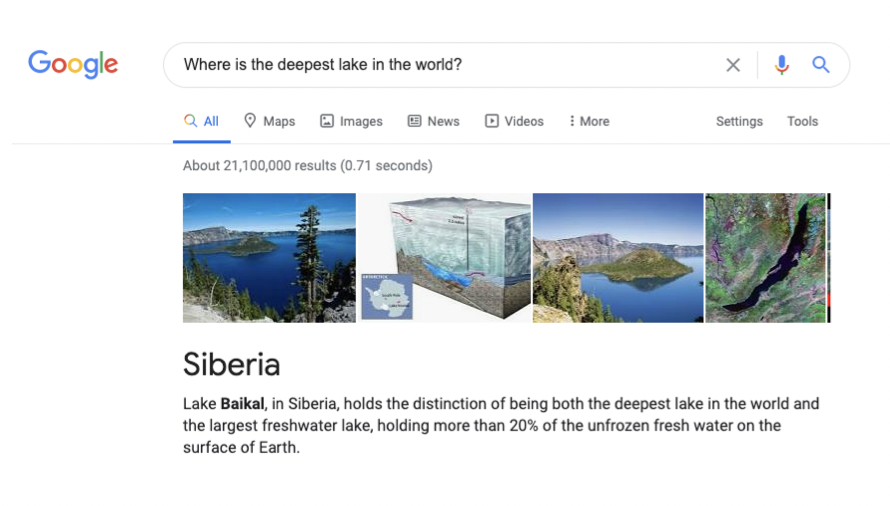
예를 들어, 구글에 세계에서 가장 깊은 호수가 무엇인가요?를 검색하면 단답형으로 호수의 이름이 나옵니다.
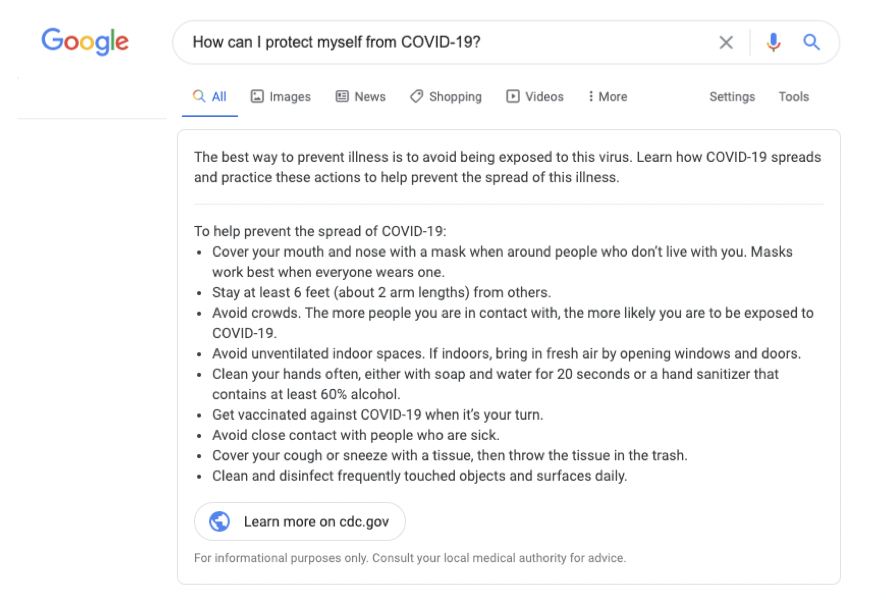
그러나 만약, 코로나19로 부터 나를 어떻게 보호할 수 있죠?를 검색하면 CDC 기사를 요약하여 단락으로 어떻게 해야하는 지 방법을 알려줍니다.
Reading Comprehension

reading comprehension이 중요한 이유
- 컴퓨터 시스템이 인간의 언어를 얼마나 잘 이해하는지 평가하기 위한 매우 중요한 테스트 베드
- 다른 NLP task도 reading comprehension 문제로 단순화 가능

- 정보추출: 텍스트의 모든 부분의 relevant 계산하여 정답 추출
- Semantic Role Labling: 한 문장 내에서의 단어의 역할 식별. 의미론적 역할 관계를 모두 구하여 독해력 상승.
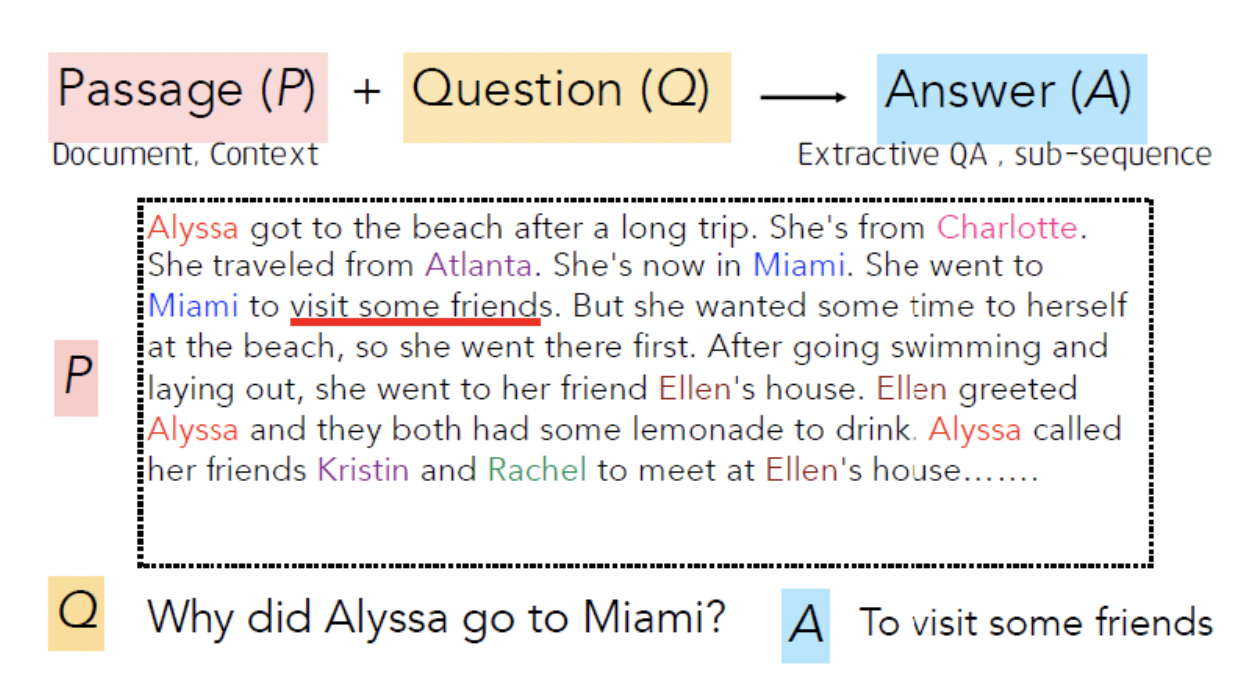
SQuAD (Stanford Question Answering Dataset)
"답은 지문에 있어. 찾아봐"
SQuAD: 100k annotated (passage, question, answer) triples
-
Passage는 영어 위키피디아에서 가져온 것으로, 100~150 단어로 구성되어 있습니다.
-
Questions는 크라우드소싱 인력들이 만들었으며,
-
Answer은 Passage 속 하위 시퀀스로 구성되었습니다.
-
Evaluation
exact match : 3개 중 하나로 나왔으면 1, 아니면 0으로 binaray accuracy.
f1 score : 단어 단위로 구한 F1-score 3개 중 max one 을 per-question F1-scroe로 두고 전체 macro average

Neaural Models for reading comprehension

1. BiDAF
01. Character Embedding Layer
Character Embedding Layer 에서는 charCNN 을 사용하여 각 단어를 vector space에 mapping합니다.
- character에 ID vector를 부여하고 CNN에 넣어서 word를 예측하는 방식으로 학습
- CNN output을 pooling으로 차원을 줄여 embedding으로 사용
- dimension으로 embedding
02. Word Embedding Layer
pre-trained word embedding model(GloVe)로 word를 vector로 만들어줍니다.
- dimension으로 embedding
03. Contextual Embedding Layer
char embedding과 word embedding을 concatenate한 후 2 layer highway network를 통과시켜 양 방향의 문맥이 모두 고려된 contextualized representation이 나오고, 어텐션 레이어에 넣기위한 준비가 완료됩니다.
-
word 주변의 contextual cues(문맥적 단서)를 사용하여 단어의 embedding을 재정의
-
BiLSTM을 통해 주변 문맥을 파악할 수 있게 함
-
forward, backward output을 concatenate하므로 dimension =
= context words, = query words
= Context의 context matrix, = Query의 context matrix where -
matrix에 vector가 행으로 쌓인 것이 아니라 열로 쌓인 것을 주의, 즉 번째 열 = 번째 단어
04. Attention Flow Layer
Attention layer 에서는 Query to Context, Context to Query 이렇게 양방향으로 attention 이 일어나게 됩니다. 즉, Query와 Context 를 쌍으로 묶어서 Attention 을 학습하는곳입니다.
- Query to Context : Context의 어떤 정보다 Query 와 관련이 있는지
- Context to Query : Query 의 어떤 정보가 Context 와 관련이 있는지
query 와 context(=passage) 를 single feature vector로 요약하지 않고, query 와 context 를 연결시킨다는 특징이 있습니다.
그렇다면 이 attention은 어떻게 양방향으로 일어날수 있을까요?
similarity matrix
이 양방향 attention을 위해 shared matrix S를 이용하며, 는 i-th context word와 j-th query word의 similarity를 의미합니다.
- Shared matrix S 의 element 값은 '알파' 라는 function을 거쳐서 나옴
- 알파 function은 c와 q, c와 q를 element-wise 곱해서 나온 세개의 벡터를 concat 한 후 linear transform 해서 구함
similarity matrix = where
- 는 t-th context word와 j-th query word의 similarity 의미
- = context의 i번째 word vector, = query의 j번째 word vector
- =
- = a trainable scalar function, similarity를 encoding하는 역할
- = trainable weight vector, where
Context2Query Attention
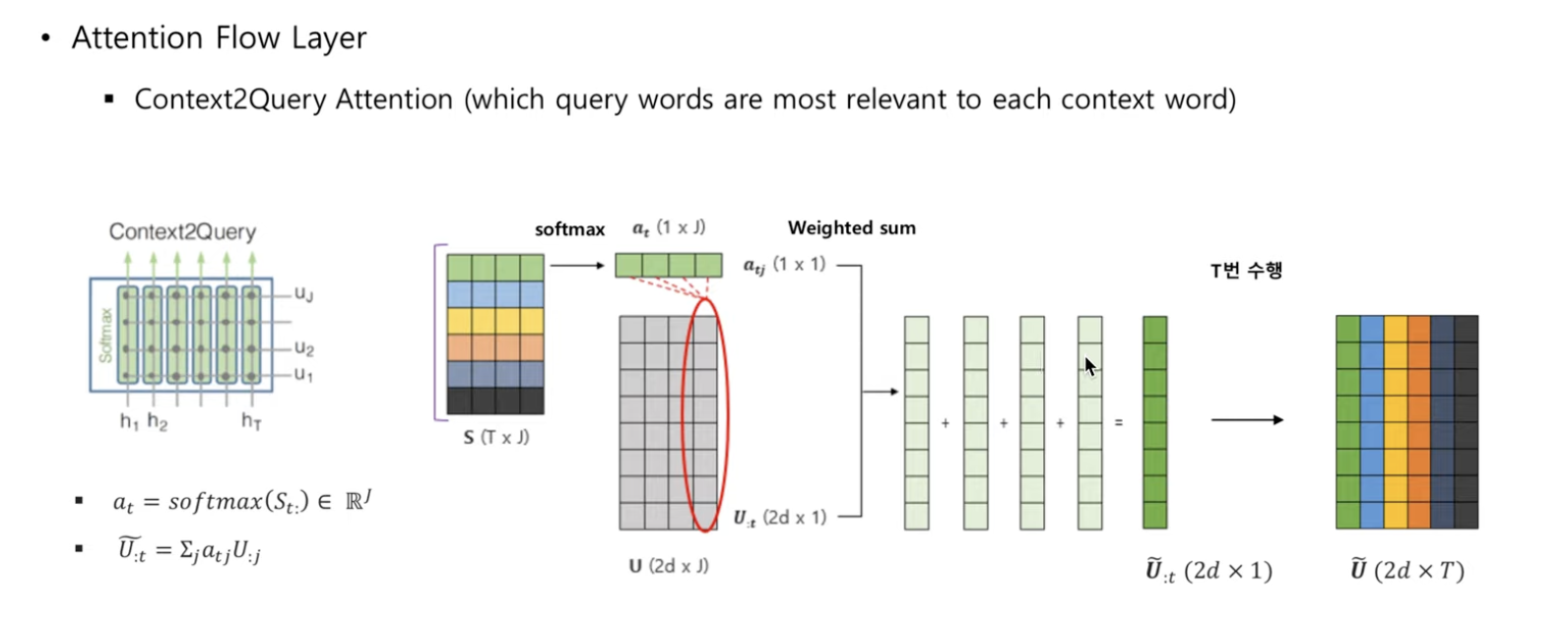
- query words 중에서 어떤 query word가 각각의 context word와 가장 관계가 있는지 signify
=
- = t-th context word와 query word들의 similarity를 의미
- similarity 에 softmax를 취해줬으므로 유사성이 큰 weight만 값이 커지게 됨
Query2Context Attention
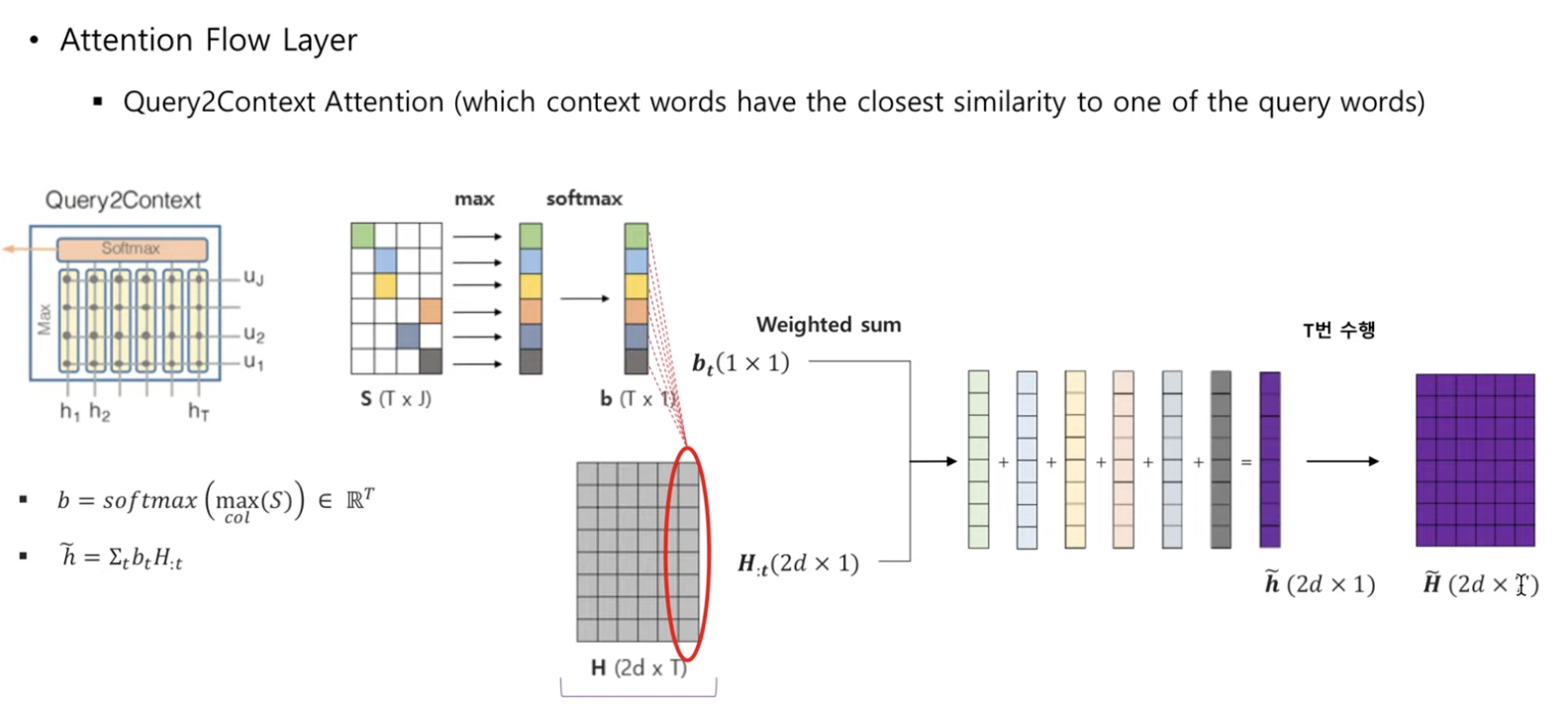
- context words 중에서 어떤 것이 각각의 query word와 가장 관계 있는지 signify
= , where
- : 각 row에서 가장 큰 값을 뽑아냄
- softmax를 취해줬으므로 에서 값이 큰 만 살아남음
05. Modeling Layer
Query와 Context간의 Interaction을 학습하기 위해 Bi-LSTM을 사용합니다.
- RNN을 통하여 context scan
- 위에서 구한 가 input
- query와 context word의 interaction을 파악
BLSTM 사용
006. Output Layer
마지막으로 Output을 Predict하는 과정입니다. Context 내 어떤 문장이 정답이 포함된 문장인가를 찾아야 하므로, 이 정답을 표기하기 위해 Start(정답 문장의 시작 단어)와 End(정답 문장의 마지막 단어)를 찾습니다. 다시말해, Output에서는 Modeling Layer에서의 Forward Output과 Backward Output을 Input으로 받아 Start 토큰과 End 토큰을 찾게 됩니다.
- query에 대한 answer을 output
- 질문에 대한 대답으로 paragraph의 sub-phrase를 찾아야함
- paragraph안에 있는 start, end의 indices 를 predict 해서 phrase를 찾음
=
=
는 각각 LSTM의 forward, backward output
2. BERT
BERT에서는 Transformer구조 중 Encoder만 사용하고 있습니다. (Base모델: 12개, Large모델: 24개) 조금 더 자세하게 설명하자면, Input으로 Word-piece Model을 사용하여 Encoding을 합니다. 이러한 Word-piece encoding은 Transformer에 그대로 입력으로 들어가게 되고, Encoder를 이용해서 Context와 연관이 있는 정보만 남기고자 하는 의도입니다.
NLP의 많은 Task들은 이후 출현하는 단어의 확률을 이전 단어에 기반하여 순차적으로 예측해야 하는 특성을 가지고 있습니다. 따라서 Statistical LM은 Bidirectional하게 구축할 수 없다는 특성을 가지게 되는데, BERT에서는 이를 다른 형태로 전환해서 Bidirectional이 가능하게 합니다.
MLM(Masked Laguage Model)
기존 Language Model의 경우 주어진 단어 시퀀스를 통해 그 다음 단어를 예측하는 Task로 학습합니다. 하지만 이때 현재 입력 단어 이후의 단어들의 정보를 모델에게 알려줄 수 없습니다.(left-to-right, 단방향)
그에 반해 MLM(Masked Laguage Model)은 문장에서 무작위 토큰에 빈칸(MASK)을 해놓으면 빈칸(Mask)에 맞는 단어를 찾는 것이 목표로 합니다. Transformer encoder에 특정 토큰에 MASK 처리를 한 문장을 한번에 넣고 MASK 단어의 정답을 찾게 하도록 합니다. 이는 Mask 단어의 left, right context를 모두 활용해야 하므로 deep-bidirectional 학습을 가능하게 합니다.
MLM에 필요한 학습 데이터를 만드는 절차는 아래와 같습니다.
- 전체 학습 데이터 토큰의 15%을 마스킹 대상 토큰으로 선정합니다.
- 마스킹 대상 토큰 가운데 80%는 [Mask] 토큰으로 만듭니다. (my dog is hairy -> my dog is [MASK])
- 마스킹 대상 토큰 가운데 10%는 토큰을 그대로 둡니다. (my dog is hairy -> my dog is hairy)
- 마스킹 대상 토큰 가운데 10%는 토큰을 랜덤으로 다른 토큰으로 대체합니다. (my dog is hairy -> my dog is apple)
- MLM은 마스킹 대상 토큰을 예측하는 pre-training task를 수행하게 됩니다.
Q. 왜 모든 마스킹 대상 토큰을 마스킹하지 않고 일부는 그대로 두거나 다른 단어로 바꾸나요?
A. [Mask] 토큰은 pre-train 과정에서만 사용하고, fine-tuning 과정에서는 사용하지 않습니다. 이는 두 과정 사이의 불일치(mismatch)를 유발하여 downstream task를 수행할 때 문제가 생길 수 있습니다. 따라서 마스킹 대상 토큰을 랜덤으로 두거나 그대로 둬서 모델이 모든 단어 사이의 의미적, 문법적 관계를 세밀히 살필 수 있게 합니다.
NSP(Next Sentence Prediction)
두 개의 문장이 이어지는 문장인지 모델이 맞추도록 하는 Task입니다.
Question Answering(QA)나 Natural Language Infrence(NLI)와 같은 Task에서는 두 문장 사이의 관계(Relationship)을 이해하는 것이 중요합니다. 하지만 기존 Languauge Model에서는 문장 사이의 관계를 학습시키기 어려웠습니다. 이를 해결하고자 BERT는 NSP를 통해 문장 사이의 관계를 모델이 이해할 수 있도록 합니다.
NSP에 필요한 학습 데이터를 만드는 절차는 아래와 같습니다.
- 모든 학습 데이터는 1건당 문장 두개로 구성된 문장 쌍으로 구성합니다.
- 학습 문장쌍 데이터 중 50%는 동일한 문서에서 실제 이어지는 문장쌍을 선정합니다. 정답 Label로는 참(IsNext)를 부여합니다.
- 나머지 50%는 서로 다른 문서에서 랜덤으로 뽑아 문장쌍을 구성합니다. (관계가 없는 문장 만들기) 정답 Label로는 거짓(NotNext)를 부여합니다.
- 이제 모델에서는 문장 쌍이 참(IsNext)인지 판별하는 Task를 수행하게 됩니다.
앞서 살펴본 BERT 구조를 보면, 맨 앞의 출력 토큰이 C입니다. 해당 C 토큰으로 문장 쌍이 참인지 판별하는 NSP Task를 수행하는 것입니다.
