[cs224n] Lecture 5 - Language Models and Recurrent Neural Networks
4강에서 다룬 dependency parsing의 단점 보완을 위하여, neural dependency parsing이 제안되었습니다.
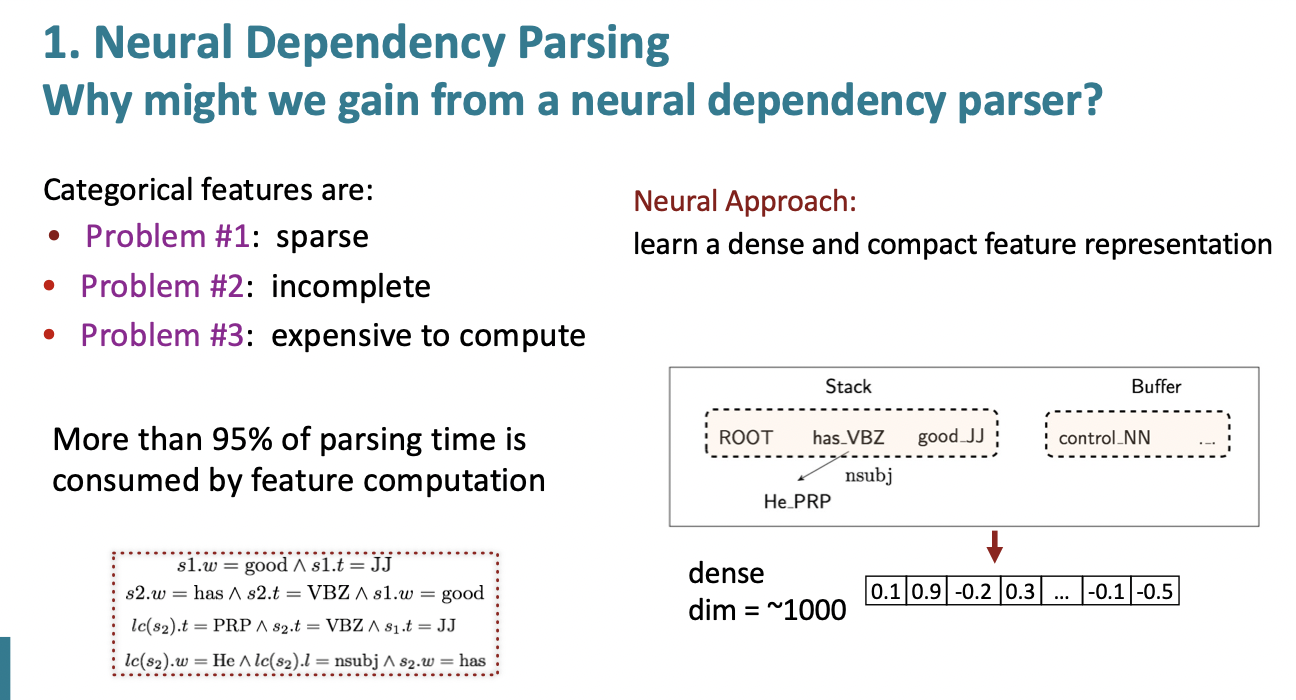
기존 parser의 문제점은 아래와 같습니다.
1) Sparse : 기존 parser에서는 단어는 bag of words처럼 나타내고, 여기에 feature에 top of stack word, 그 단어의 POS, top of buffer word 등을 원핫벡터로 나타내어 이 vector들을 concat하여 feature로 이용합니다. 그런데, 단어를 bag of words 방식으로 나타내면 당연히 희소 행렬 문제가 발생하고, dimension 역시 매우 커집니다.
2) Incomplete : configuration 에서 본 적이 없는 단어나 단어 조합이 있을 경우, feature table에 없기에 incomplete한 모델이 됩니다.
3) Expensive to compute : parsing time의 95%가 feature computing에 사용되어 computing 시간이 매우 오래걸리는 단점이 있습니다. 이 역시 sparse 문제에서 파생되는 문제입니다.
Neural dependency parser
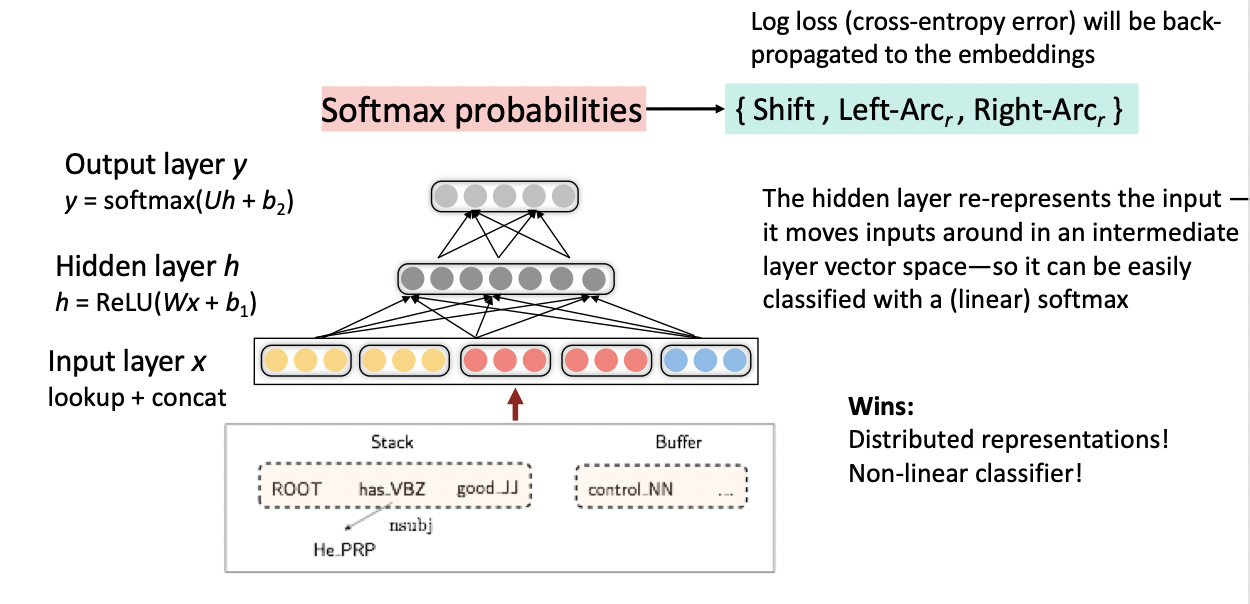
Neural dependency parser의 모델 구조는 꽤 단순합니다. Input layer에서 입력 받은 vector를 Hidden layer에서 ReLU 함수를 통해 Hidden vector를 생성합니다. 그리고 만들어진 Hidden vector를 Softmax layer에서 Softmax 함수를 통해서 Output을 만들게 됩니다.
모델 구조는 기본적인 feed forward network와 비슷하나, hidden layer의 활성화 함수에서 차이가 있습니다.
이 부분을 자세히 살펴보면, 각 feautre별로 임베딩된 벡터가 input layer를 입력된 이후에 hidden layer에서는 일반적인 feed forward network처럼 Embedding Vector와 weight matrix를 곱한 뒤 bias vector를 더합니다. 그런데, 이때 신경망에서 보통 쓰이는 ReLU, Sigmoid, Tanh과 같은 activation function을 사용하지 않고 word, POS tag, arc-label간 상호작용을 반영할 수 있는 cube function을 사용하게 됩니다. cube function을 사용하면 x의 피쳐들이 곱해지는 형태가 상호작용하는 것으로 표현되기 때문에 word, POS tag, arc-label 간의 상호작용을 잘 반영할 수 있다고 합니다.
Graph-Based Dependency parsers

Graph-base 파싱 방법은 그 문장에서 가능한 모든 의존관계를 찾아내고, 그 의존관계들의 조합에서 가장 합리적인 트리를 입력 문장의 트리로 결정하는 것입니다. 이 때 가장 합리적인 트리를 결정하는 방법은, 여러 트리를 구성하고 있는 각각의 의존관계들의 점수 합이 가장 큰 트리를 가장 합리적인 트리라고 봅니다.
성능 비교
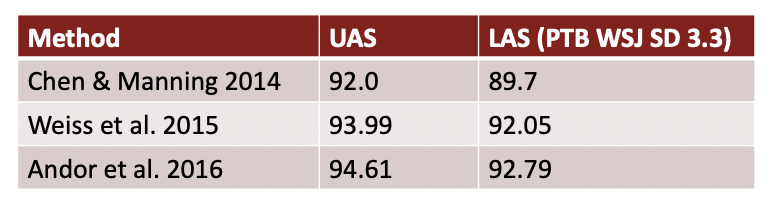
각 parsing 방법에 따른 성능을 비교해보자면 conventional features representation이 적용된 Transition-based parser의 경우 모든 경우의 수를 체크하는 Graph-based parser보다 훨씬 빠르지만 성능이 조금 낮은 것을 확인할 수 있습니다. 하지만 Neural Network를 적용함으로써 Transition-based parser와 Graph-based parser보다 빠르고 좋은 성능을 이끌 수 있게 됩니다.
Language Modeling

Language Modeling은 이전 단어들로부터 다음 단어를 예측하는 일을 말합니다. Language Model은 단어 시퀀스에 확률을 할당(assign) 하는 일을 하는 모델입니다. 다시말해, Language Model은 가장 자연스러운 단어 시퀀스를 찾아내는 모델입니다. 단어 시퀀스에 확률을 할당하게 하기 위해서 가장 보편적으로 사용되는 방법은 언어 모델이 이전 단어들이 주어졌을 때 다음 단어를 예측하도록 하는 것입니다.
Language Model은 단어 시퀀스에 확률을 할당하는 모델이고, 단어 시퀀스에 확률을 할당하기 위해서 가장 보편적으로 사용하는 방법은 이전 단어들이 주어졌을 때, 다음 단어를 예측하도록 하는 것입니다. 이를 조건부 확률로 나타내면 아래와 같습니다.

우리는 Language Models를 일상생활에서 매일 사용하고 있습니다.
n-gram

N-Gram model
n-gram은 n개의 연속적인 단어 나열을 의미합니다. 다시 말해, 갖고 있는 코퍼스에서 n개의 단어 뭉치 단위로 끊은 것을 하나의 토큰으로 간주합니다.
📌 "An adorable little boy is spreading smiles"라는 문장이 있을 때, 각 n에 대해서 n-gram을 전부 구해보면 다음과 같습니다.
- unigrams : an, adorable, little, boy, is, spreading, smiles
- bigrams : an adorable, adorable little, little boy, boy is, is spreading, spreading smiles
- trigrams : an adorable little, adorable little boy, little boy is, boy is spreading, is spreading smiles
- 4-grams : an adorable little boy, adorable little boy is, little boy is spreading, boy is spreading smiles
n이 1일 때는 유니그램(unigram), 2일 때는 바이그램(bigram), 3일 때는 트라이그램(trigram)이라고 명명하고 n이 4 이상일 때는 gram 앞에 그대로 숫자를 붙여서 명명합니다.
n-gram 모델에서의 단어 예측 방법을 알아보겠습니다. 이 때 우리는 t+1 시점에 등장할 x는 n-1 words에만 영향을 받는다고 가정하며, t+1 시점에 등장하는 단어는 단어 집합 v에 속하는 단어입니다.
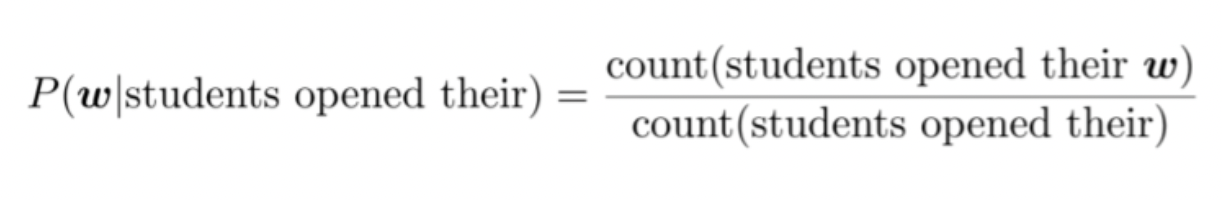
n-gram과 (n-1)-gram의 확률은 counting 방식으로 구합니다.
즉,
'students opened their' 다음에 단어 w가 나올 확률은 4-gram을 3-gram으로 나눈 값을 뜻하고,
For example, suppose that in the corpus:
"students opened their" : 1,000번 발생
"students opened their books" : 400번 발생
⇒ P(books∣students opened their)=0.4
"students opened their exams" : 100번 발생
⇒ P(exams∣students opened their)=0.1
위와 같은 방식으로 확률이 구해집니다.

위에서 보면 알 수 있듯 4-gram model을 사용하므로 'students' 이전 단어들을 고려하지 않습니다. 그러나, proctor은 굉장히 예측에 중요한 영향을 끼칩니다. 따라서 n-gram은 문맥 고려에 단점이 있다는 것을 알 수 있습니다.
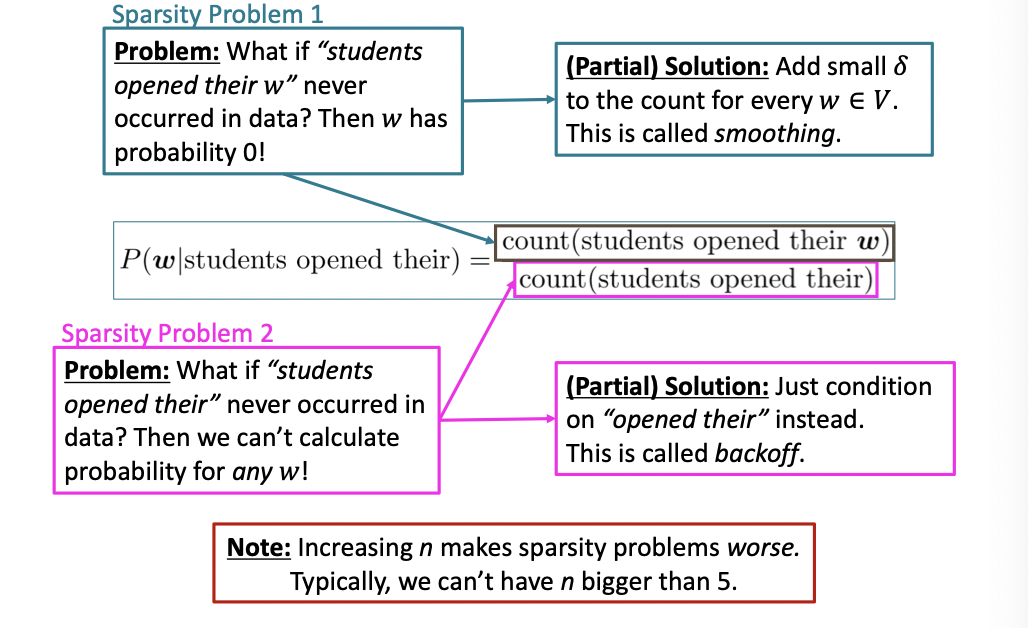

N-gram Language Model의 문제점은 아래와 같습니다.
1. "students opened their w"가 훈련 코퍼스에 존재하지 않으면, w의 확률은 0이 된다(조건부 확률의 분자가 0)
=> 이를 해결 하기 위해 우리는 smoothing을 사용할 수 있습니다. 즉, 모든 w∈V의 count에 대해 작은 값의 δ를 더해줍니다.
2. "students opened their" 훈련 코퍼스에 존재하지 않으면, w의 확률은 계산할 수 없다(조건부 확률의 분모가 0).
=> 이를 해결 하기 위해 우리는 n-gram 대신 (n-1)-gram인 "opened their"의 값으로 대신할 수 있습니다.
3. Corpus 내 모든 n-gram에 대한 count를 저장해줘야 하고, 이에 따라 n이 커지거나 corpus가 증가하면 모델의 크기가 증가하여 저장 문제가 발생합니다.
Generating text with a n-gram Language Model

n-gram 으로 텍스트 생성을 한 예시입니다. 문법적으로는 생각보다 괜찮은 결과를 얻을 수 있었으나, 문맥적으로 일관성이 없음을 알 수 있습니다. n의 크기를 늘리면 이러한 문제를 해결할수도 있으나, 그렇게 되면 sparsity 문제가 심해지게 됩니다.

