5주차 MAD-GAN 논문 리뷰
본 포스팅은 고려대학교 DSBA 연구실 허재혁님의 MAD-GAN논문 리뷰 영상을 바탕으로 작성하였습니다.
1. 서론
시계열 데이터가 방대해지고 복잡해짐에 따라 이러한 다변량 시계열을 위한 이상치 탐지 모델의 필요성이 대두되었습니다. 하지만 저자는 기존의 방법론들은 다변량 시계열 데이터의 특성을 적절하게 고려하지 못한다고 지적하고 이러한 문제를 해결할 수 있는 MAD-GAN모델을 제안합니다.
-
CUSUM, EWMA and Shewhart charts 등 기존의 임계값을 기반으로 이상치를 탐지하는 방법론은 최근 시계열 데이터의 동적인 복잡성(dynamic complexities)을 제대로 반영하지 못한다는 한계가 있습니다.
-
지도학습을 하는 머신러닝 모델의 경우, 점점 더 많아지는 데이터에 대해 모두 레이블링을 할 수 없기 때문에 방대한 양의 시계열 데이터를 구할 수 없다는 단점을 가지고 있습니다.
-
최근에 나온 비지도학습의 머신러닝기법들은 다변수간의 시공간적 연관성, 잠재된 의존성을 충분히 활용하지 못합니다.
(여기서 다변수는 이상치를 찾아내기 위한 여러가지 센서와 작동장치를 의미합니다.)
반면, GAN은 이미지 생성에 성공적인 퍼포먼스를 보여주었으나 논문이 쓰인 시점을 기준으로 시계열 task에는 아직 깊은 연구가 이루어지지 않았습니다. GAN을 통한 이상치 탐지 기법은 노이즈가 포함된 현실적이고 복잡한 데이터셋을 생성자와 판별자간의 동시적인 학습을 통해 성공적인 퍼포먼스를 보여줄 수 있을 것이라고 판단되어 해당 연구를 진행하게 되었다고 합니다.
1-1. 기존의 방법론의 한계
PCA, PLS와 같은 linear model-based methods
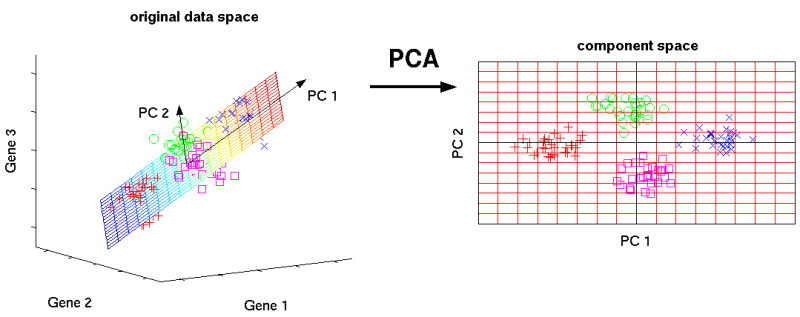
PCA, PLS 등 선형 모델 기반 이상치 탐지 기법의 경우, 다변량 자료분석 방법론의 일종입니다. 공분산행렬의 정보를 최대한 유지한 채로 정상 데이터의 차원을 축소하여 주성분을 구한 뒤, 주성분으로 이루어진 공간을 기준으로 정상, 비정상 데이터를 판별합니다. 주성분으로 이루어진 공간 내에서 비정상 개체의 사영값은 작을 것이고, 정상 개체는 높은 사영값을 보일 것이므로 이를 기반으로 이상치를 탐지할 수 있습니다.
하지만 PCA의 경우 변수간 연관성이 높은 자료를 요구하며, PLS는 다변량 가우시안 분포를 가정하기에 적용할 수 있는 데이터 종류가 한정적이라는 단점이 있습니다.
KNN, CBLOF 등 거리 기반 이상치 탐지 기법
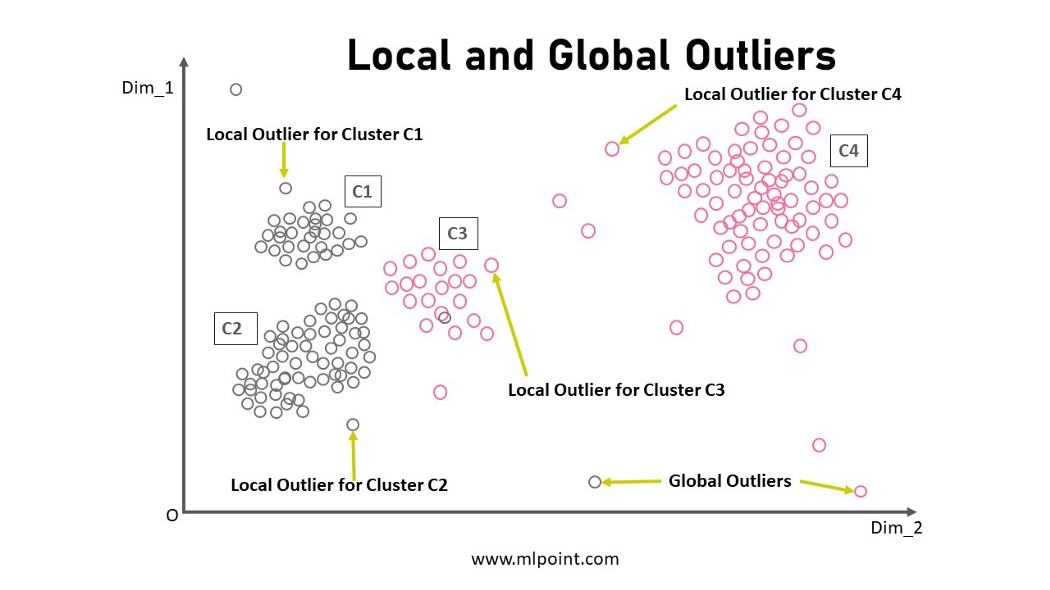
KNN, Clustering Based Local Outlier Factor (CBLOF)와 같은 거리 기반 이상치 탐지 기법들은 몇몇 케이스에는 효과적으로 이상치를 탐지하지만, 이상치 발생횟수나 지속기간과 관련된 사전정보가 추가되어야 적절한 성능을 내는 경우가 있다는 점에서 한계가 있다고 합니다.
Angle-Based Outlier Detection(ABOD)
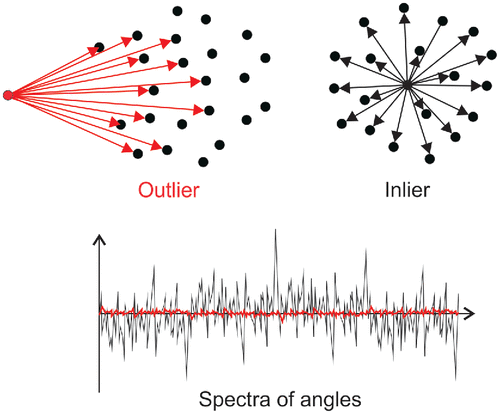
Feature Bagging(FB)

Angle-Based Outlier Detection(ABOD), Feature Bagging(FB) 등 확률 기반 방법론들은 데이터의 분포에 집중함으로써 거리기반 방법론보다 발전된 양상을 보여주었지만 변수간 상관성만 고려할 뿐, 시간적인 상관성(temporal correlation)을 고려하지 못해 다변량 시계열 데이터에 좋은 성능을 보이지 못한다는 단점이 있습니다.
딥러닝 기반의 이상치 탐지 기법
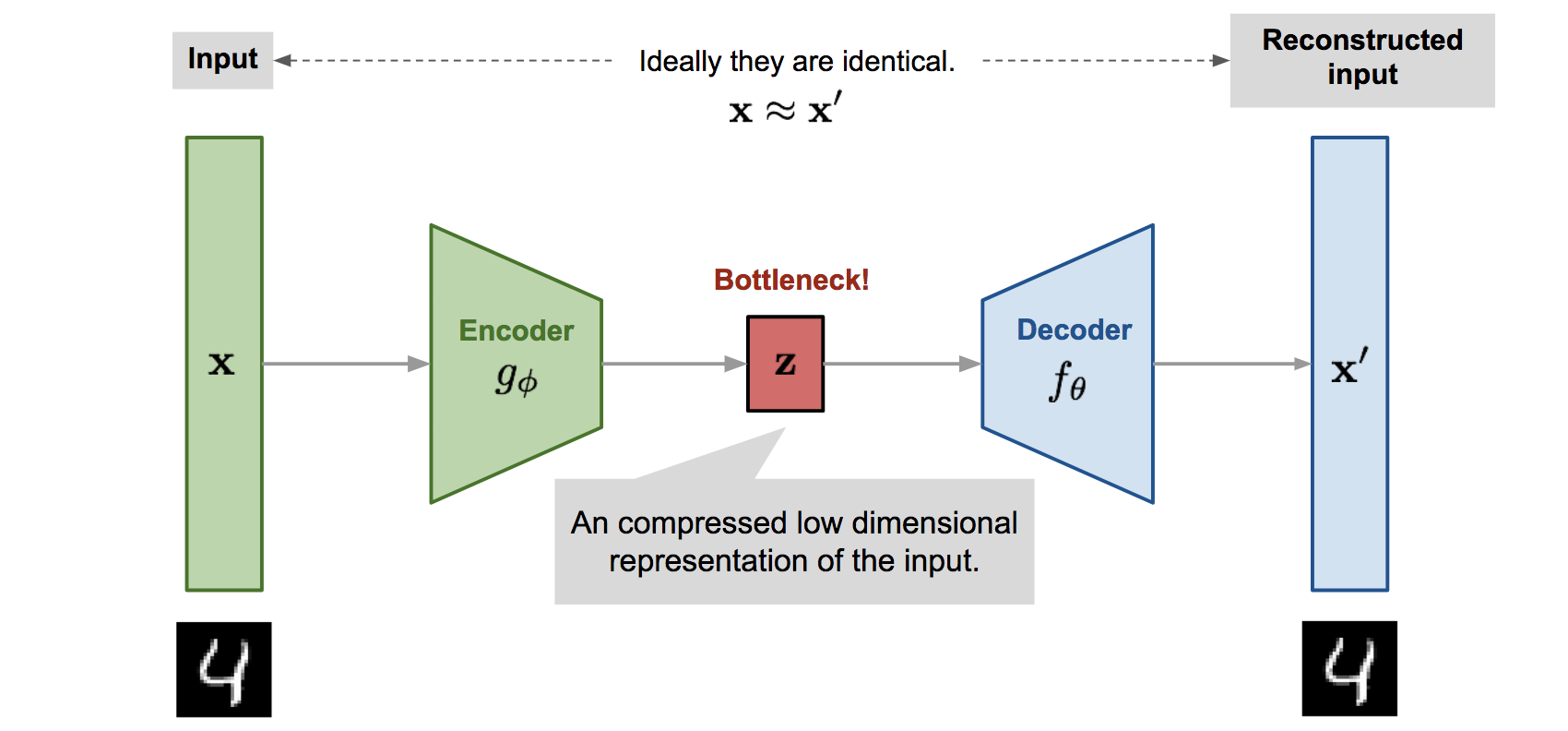
딥러닝 기반의 이상치 탐지 기법은 Auto-Encoder(AE), Deep Auto-encoding Gaussian Mixture Model(DAGMM), LSTM Encoder-Decoder 등이 있습니다. 이러한 방법론들은 다변량 이상치 탐지 분야에서 좋은 성능을 보여주었으며, 본 논문에서는 딥러닝 기반의 비지도학습 이상치탐지 방법론의 장점을 최대한 수용하는 GAN 기반의 이상치 탐지 기법을 제안합니다.
Deep Auto-encoding Gaussian Mixture Model(DAGMM)
: https://www.youtube.com/watch?v=byvMpGsl7cE
1-2. 논문의 기여
본 논문의 기여를 요약하면 다음과 같습니다.
-
다변량 시계열 데이터를 기반으로 이상치를 탐지하는 문제에 GAN을 활용했다는 점
-
LSTM-RNN 기반의 GAN구조를 활용함으로써 시간적 연관성까지 잡아낸 점
-
GAN모델의 생성자와 판별자의 loss를 결합한 새로운 이상치 점수,
DR-score를 활용한 점
2. 모델
MAD-GAN모델의 큰 틀은 다음과 같습니다.
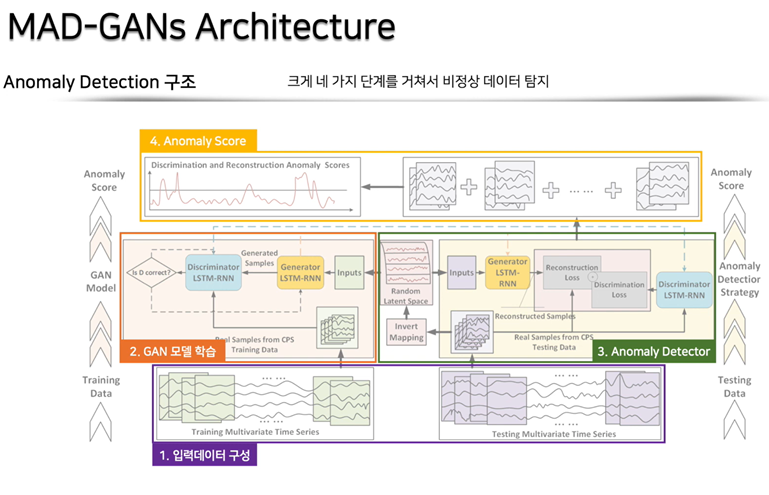
입력 데이터를 전처리한 후, 데이터를 GAN모델에 넣어 학습을 진행합니다.
학습된 생성자와 판별자를 오른쪽에 있는 이상치 탐지 모델에 넣어 각 샘플 데이터별로 생성자와 판별자 loss를 구합니다.
마지막으로 앞서 구한 두 loss를 선형결합하여 이상치 점수인 DR score를 만들게 됩니다. 샘플 데이터마다 구한 DR score가 미리 설정한 값보다 클 경우, 이상치로 판단하게 됩니다.
단계별로 자세히 알아보도록 하겠습니다.
2-1. 입력 데이터 전처리
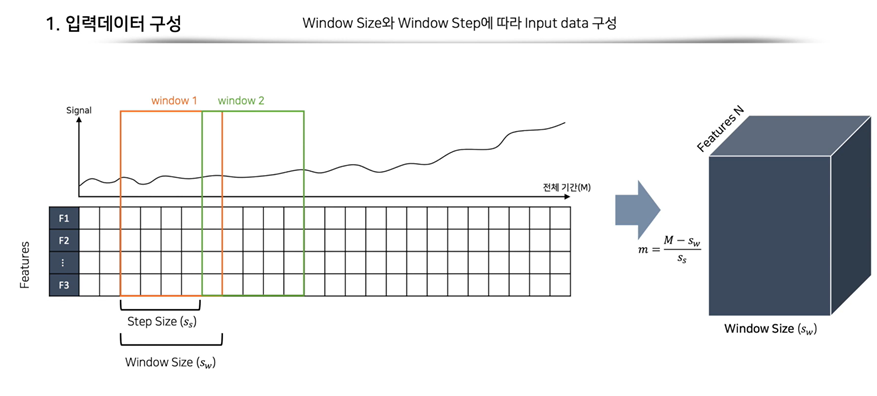
길이의 window를 step size 만큼 이동하며 윈도우를 만듭니다. 그 결과 m개의 윈도우가 생성되고, 이를 그림으로 표현하면 오른쪽과 같은 3차원 입력 데이터가 만들어지게 됩니다.
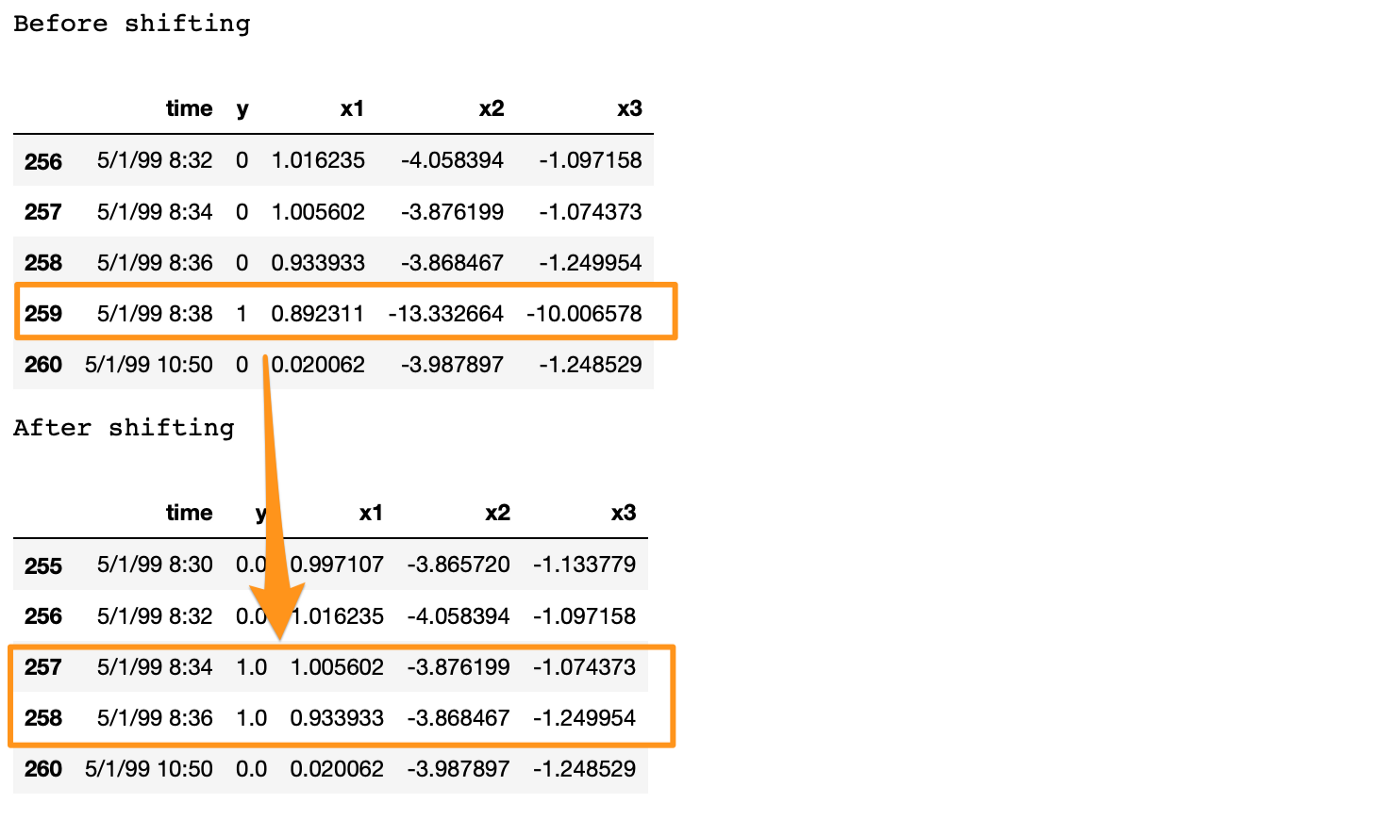
4주차 오토인코더 코드 리뷰에서 다뤘던 것처럼 입력 데이터는 3차원이 되며, 각 윈도우에서는 이상치를 "미리" 탐지하는 것이 핵심이기에 레이블이 1인 이상치 데이터 개체를 지우고, 시간적으로 앞선 데이터 개체의 레이블을 1로 설정하는 방식으로 전처리를 진행합니다.
참고로, 학습단계에서 정상데이터만을 학습해야 이상치 판별 단계에서 이상치 데이터에 대해 생성자는 재구축 오차가, 판별자는 판별 오차가 커집니다. 따라서 이를 기반으로 train, validation, test 데이터를 나눈 후, 필요한 스케일링을 진행합니다.
2-2. GAN 모델 학습
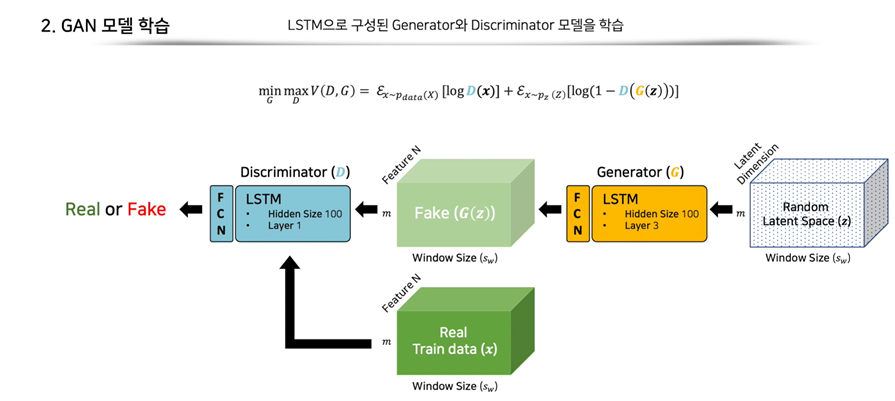
GAN구조가 학습하는 과정은 위 그림과 같습니다. 논문에서는 오른쪽에 있는 random latent space, Z를 임의의 공간에서 추출한 다변량 부분수열(multivariate sub-sequences)이라고 합니다.
이러한 Z는 train data의 윈도우 사이즈()와 동일한 크기로 생성자에 입력됩니다. 생성자에서는 히든 사이즈가 100인 3개의 layer로 이루어진 LSTM구조를 거친 후, fully connected layer에서 입력 데이터와 같은 크기로 출력합니다.
이렇게 가짜 데이터가 만들어지고 판별자는 생성자에서 만든 가짜 데이터와 정상 데이터로 이루어진 진짜 데이터를 비교해 이를 판별하여 scaler값을 출력하게 됩니다.
위에 있는 min max 문제를 풀면서 판별자와 생성자가 경쟁하며 모델이 학습하게 됩니다. GAN의 이론상으로는 이 두 모델이 경쟁한다고 하지만 시간이 지날수록 판별자가 거의 완벽하게 구분하게 되면 생성자의 학습이 제대로 이뤄지지 않는다는 단점도 존재합니다.
2-3. 이상치 판별 모델
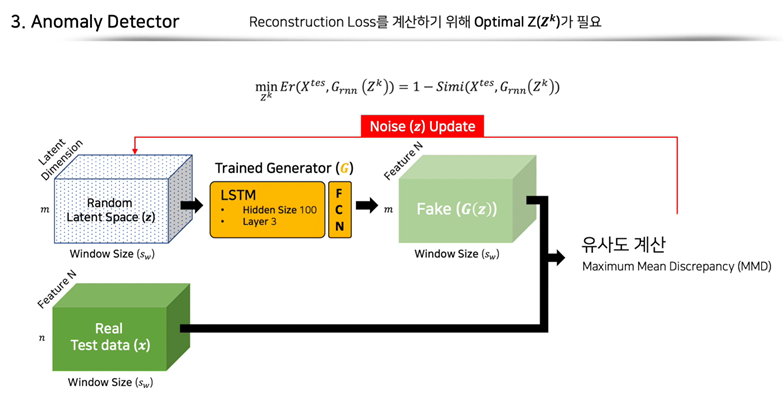
그 다음은 이상치 판별 단계입니다. 이 단계에서는 학습된 생성자와 판별자를 활용하게 되는데 그 이전에 앞서 언급했던 가 임의의 공간이므로 와 의 거리가 너무 멀어지지 않게 하기 위해 노이즈 를 업데이트하는 과정이 필요합니다. 학습된 생성자가 생성한 와 테스트 데이터인 의 유사도를 Maximum Mean Discrepency로 측정하여 를 업데이트하게 됩니다.
여기서 의 업데이트는 이상치 탐지 모델에서 재구축 오차가 단순히 를 통해 구해지기 때문에 test data set 중 정상 데이터만을 기준으로 업데이트될 것이라고 볼 수 있습니다. 만약 random latent space 가 비정상 데이터까지 업데이트하게 된다면 생성된 가짜 데이터 가 비정상 테스트 데이터와의 오차가 클 것이라고 확정할 수 없기 때문입니다.
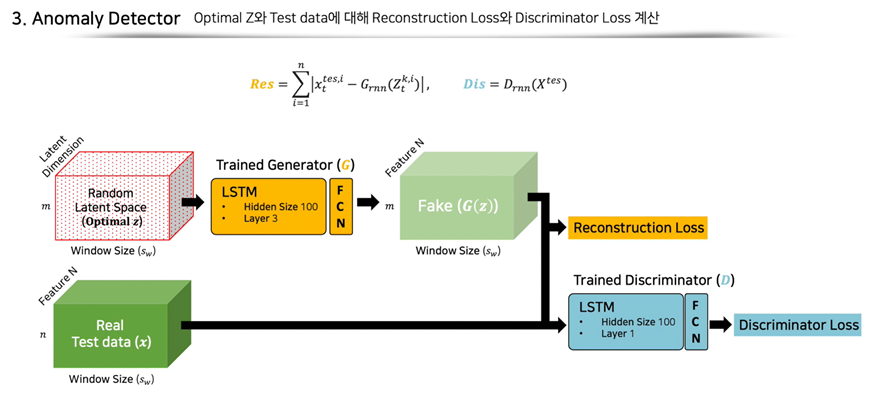
업데이트된 노이즈 를 기반으로 생성자는 가짜 데이터 를 만들어내고, 를 비교하여 재구축 오차를 구하게 됩니다. 판별자는 가짜 데이터와 진짜 데이터 구별하며 scaler값을 출력하고 이를 정답과 비교하여 판별 오차를 구합니다.
여기서 중요한 점은 Test data에는 비정상 데이터가 포함되어 있다는 점입니다. 정상 데이터만으로 학습한 생성자는 정상분포만을 생성하기에 비정상 데이터와 비교했을 때, 재구축 오차가 클 것입니다. 판별자 또한 정상 데이터만으로 판별을 진행했기 때문에 이상치에 해당하는 진짜 데이터를 가짜 데이터라고 볼 확률이 높아집니다. 이에 따라 판별 오차가 커지게 되고 오차가 커진 만큼 이상치로 판단할 확률이 높아집니다.
저번 시간에 다룬 AE구조를 통한 이상치 탐지와 헷갈리실 수 있는데 오토인코더의 디코더가 여기서 생성자에 해당한다고 보시면 됩니다.
2-4. DR-score 계산 단계
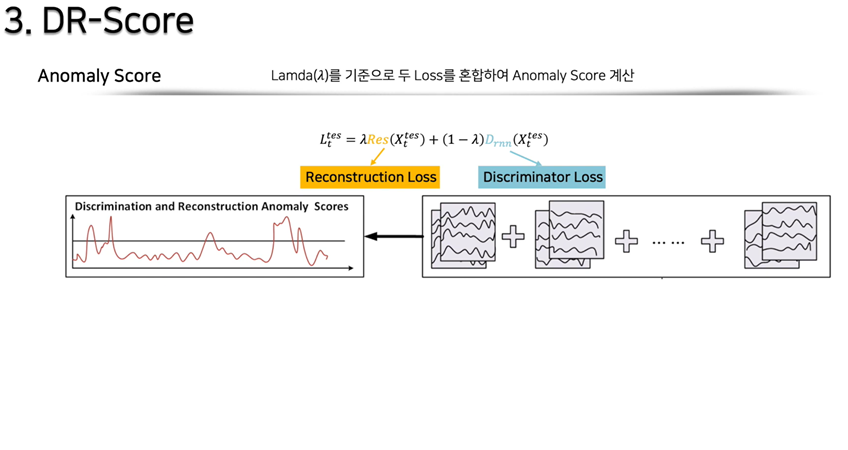
재구축 오차와 판별 오차에 임의의 를 곱하여 이상치 점수를 계산합니다.
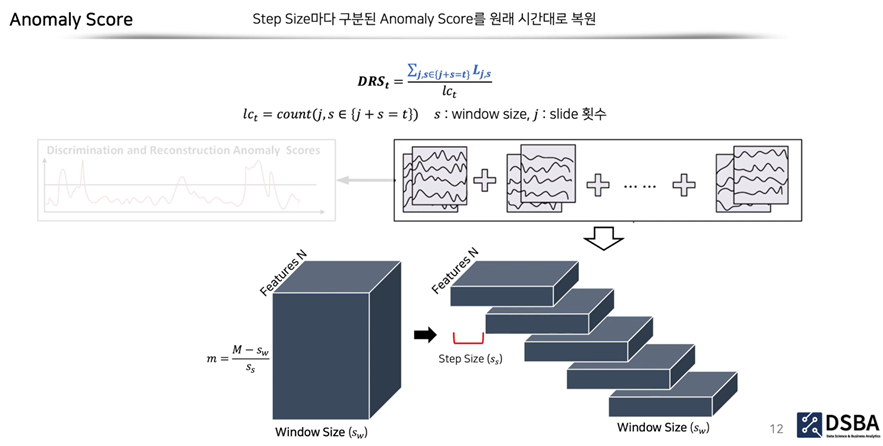
입력 데이터를 구성할 때, window가 중복되도록 step size를 설정해주었기에 중복된 횟수만큼을 나눠주는 작업으로 통해 DR score를 구하게 됩니다.
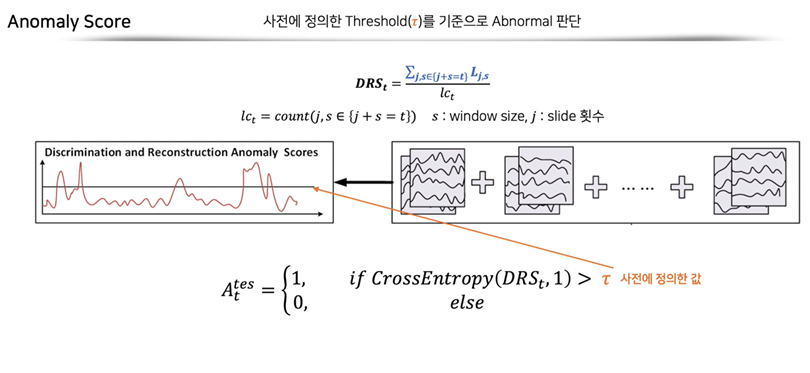
마지막으로 DR score가 사전에 정의한 값보다 클 경우, 이상치로 판단합니다.
3. 데이터셋 및 실험
데이터
해당 모델의 성능을 실험하기 위해 사용된 데이터셋은 the Secure Water Treatment (SWaT) 데이터셋과 the Water Distribution (WADI) 데이터셋을 사용했다고 합니다.
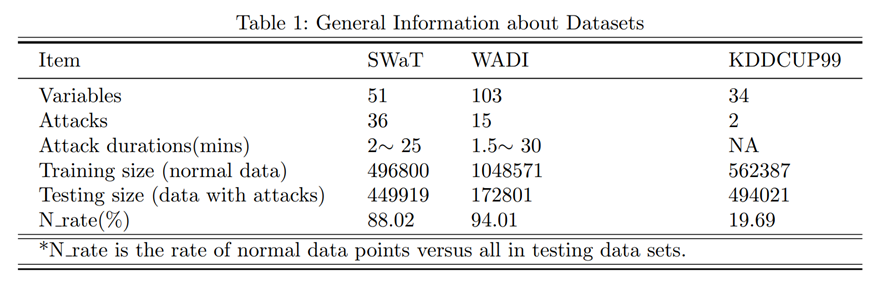
SWaT과 WADI 데이터셋은 사이버 공격 패턴을 감지하는 수십개의 센서들을 기반으로 이루어진 다변량 시계열 데이터셋입니다. 데이터 크기 또한 상당히 큰데 어떤 논문에서는 MAD-GAN이 방대한 데이터셋에서만 유용하다는 점을 지적한 바가 있습니다.
다변량 vs 단변량
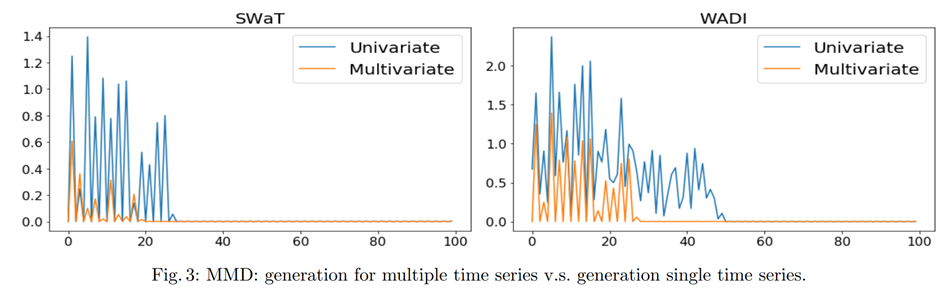
각 반복횟수별로 생성자가 실제 분포를 잘 학습했는지 MMD(maximum mean discrepancy)를 확인했을 때, 단변량 데이터보다 다변량 데이터에 대해 보다 빠르게 수렴하고 있다는 것을 확인할 수 있습니다. 서론에서 다변량 시계열에 맞는 모델을 만든다고 했는데 실험결과를 보면 맞는 것 같습니다.
타 모델과의 비교
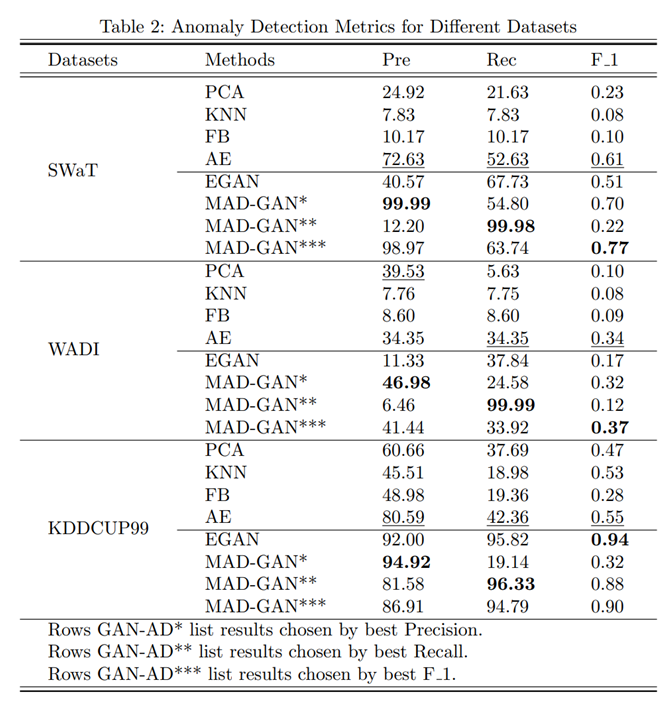
실험장표를 보면 타 모델과 달리, MAD-GAN모델은 각 평가지표별로 가장 높은 성능을 보인 모델에 대해 볼드처리로 돋보이게 한 것을 확인할 수 있습니다. 이런 점이 실험 결과의 객관성을 저하하는 것 같아 아쉬웠습니다.
또한, wadi 데이터에서 재현율이 가장 높은 MAD-GAN모델의 정밀도가 6%가량인 것을 보면 94%가 false알람이라는 것을 확인할 수 있습니다. 모델이 탐지한 이상치 중 대부분이 정상 데이터인 것을 고려하면 해당 모델이 기존의 모델에 비해 최고의 성능을 보였다고 보기에 어려운 점이 있습니다.
학습 결과 시각화
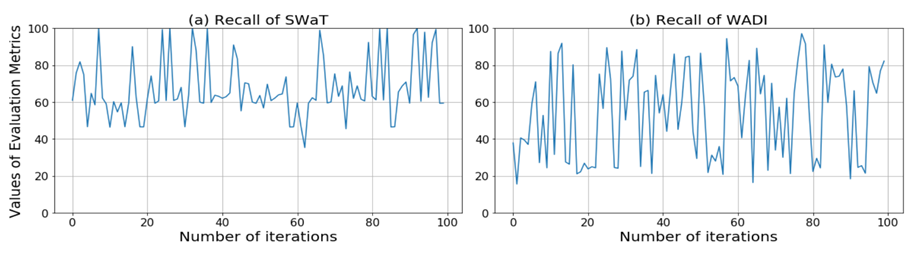
본 논문에서는 해당 모델이 빠른 시간 내에 높은 성능을 달성할 수 있다고 하지만 학습 결과를 보면 학습이 매우 불안정하다는 것을 알 수 있습니다. 이는 GAN구조에서 학습이 안정되기 어렵다는 점에서 기인한 것으로 보입니다.
느낀 점
본 논문을 읽으면서 LSTM-RNN구조로 학습한 GAN 모델을 써야 하는 이유에 대한 증명이나 설명이 조금 부족하다고 느껴졌습니다.
논문에서는 기존의 모델들이 방대해져가는 시계열 데이터셋에 적합하지 않다는 점을 지적했지만 GAN모델을 써야 하는 이유에 대해 이미지 생성 등 다른 분야에서 뛰어난 성능을 보였기 때문이라고만 서술되어 있기 때문입니다.
또한, 실험장표와 학습결과에서 볼 수 있듯이 GAN구조가 과연 다변량 시계열 데이터셋에서 이상치를 탐지하는 데 기존의 모델들보다 효과적인지 의문이 듭니다.
하지만 MAD-GAN논문이 GAN을 활용하여 다변량 시계열 데이터에서 이상치를 탐지할 수 있는 가능성을 제공하여 이후에 나올 여러 논문에 영감을 주었다는 점에서 그 의의가 있다고 생각합니다.
참고자료
https://www.youtube.com/watch?v=bEX6WPMiLvo
https://www.youtube.com/watch?v=Y3FMi2EW23Y&t=5s
작성자: 고려대학교 식품자원경제학과 김주호

안녕하세요 논문 리뷰해주신거 잘 읽었습니다. 다름이 아니라, 2-3 단락에
"여기서 Z의 업데이트는 이상치 탐지 모델에서 재구축 오차가 단순히 l1 loss를 통해 구해지기 때문에 test data set 중 정상 데이터만을 기준으로 업데이트될 것이라고 볼 수 있습니다. 만약 random latent space Z가 비정상 데이터까지 업데이트하게 된다면 생성된 가짜 데이터 G(Z)가 비정상 테스트 데이터와의 오차가 클 것이라고 확정할 수 없기 때문입니다."
라고 언급해주셨는데, 이게 test data set 중 정상 데이터만을 활용하여 latent vector z를 optimize한다 라는 의미로 적어주신게 맞으실지 문의드립니다.
모델의 구조가 AnoGAN의 학습 과정과 많이 유사한 것 같은데 AnoGAN에서도 정상 데이터를 이용하여 Generator와 Discriminator를 학습한 뒤 정상, 비정상 데이터가 모두 섞인 테스트 데이터 셋을 이용하여 z를 update하는 방식으로 알고 있습니다.
논문 상으로나, 참고하신 유튜브 리뷰 영상에서나 test 데이터 중 정상 데이터만 사용한다는 언급은 딱히 없는데 혹시 제가 잘못 이해한 것인가 싶어서 여쭤봅니다!