Background
- 우리 팀은 AWS EKS 에서 NodeGroup 의 Scale In/Out 을 위해 Cluster AutoScaler(이하 CA) 를 사용중이다.
- 하나의 EKS 클러스터에서 다양한 서비스가 실행 되고 있었고, 시간이 지나면서 자연스럽게 다양한 사양의 인스턴스 요구 되었다.
때문에, NodeGroup 또한 다양하게 관리 되었는데, 어느순간 하나의 EKS 클러스터에서 만들 수 있는 NodeGroup 의 수를 초과 하는 일이 발생 했다. - AWS CA 는 AWS AutoScaling Group(이하 ASG) 에 의존 하여 동작하면서 Scaling 시 속도가 느리기도 하였고, 이번 기회에 Karpenter 로 전향하자는 의견이 합치 되어 다른 팀원분께서 Karpenter 적용하는 업무를 진행해 주셨다.
- 나는 Karpenter 관련 작업을 아직 경험해보지 않아서, Karpenter 에 대해 간략히 학습하고자 해당 게시글을 정리 중이다.
Cluster AutoScaler(CA) 동작 플로우
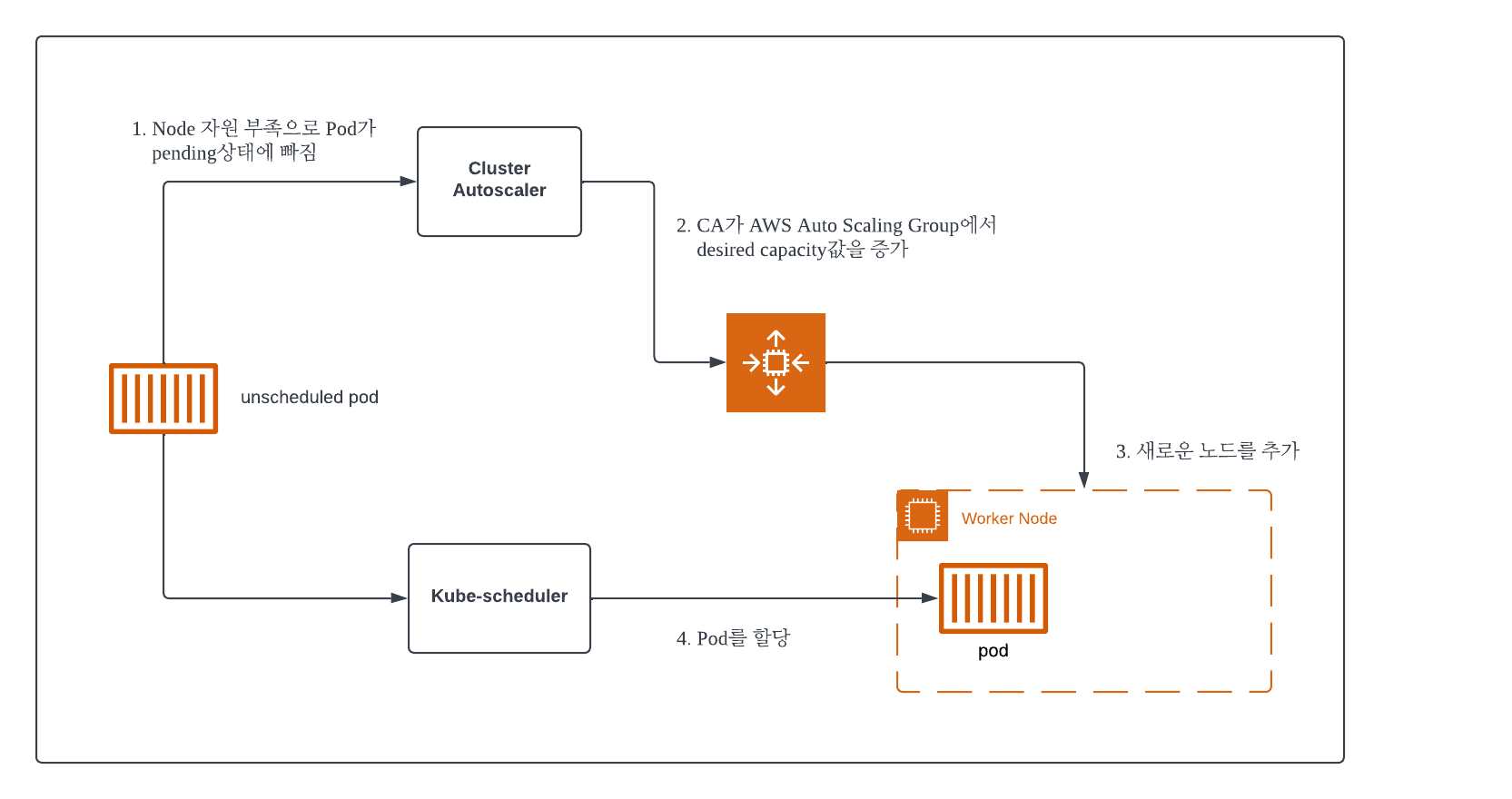
1. Horizontal Pod AutoScaler(HPA) 에 의한 pod의 수평적 확장이 한계에 다다르면, pod는 적절한 Node 를 배정받지 못하고 pending 상태에 빠진다.
2. 이때, CA 는 Pod 의 상태를 관찰 하다가 지속해서 할당에 실패하면 Node Group 의 ASG Desired Capacity 값을 수정하여 Worker Node 개수를 증가하도록 설정 한다.
3. 이를 인지한 ASG 가 새로운 Node 를 추가 한다.
4. 여유 공간이 생기면 kube-scheduler 가 Pod를 새 Node 에 할당 한다.
- 즉, CA 에 의해서 ASG Desired capacity 가 수정 된 후 ASG 가 실질적으로 Node 를 증성하여도 pending 되었던 pod 가 바로 배포 되는 것이 아니라, Kube-scheduler 가 unscheduled pod 를 한 번 더 감지해서 증설된 Node 에 배포 해주어야 한다. 그만큼 Pod 가 실제 배포 되는 시간이 증가 되는 것이다.
출처: https://devblog.kakaostyle.com/ko/2022-10-13-1-karpenter-on-eks/
Karpenter(https://karpenter.sh/)
- Just-in-time Nodes for Any Kubernetes Cluster
- Karpenter 는 직접 pending 된 Pod 를 감지해서 해당 Pod 가 배포되기 적합한 Node 사양으로 직접 Node 증설을 명령하고, 해당 Node 에 Pod 를 직접 배포 하도록 명령 해준다고 한다.
- 때문에, CA 보다 Pod 배포 속도가 더 빠르다고 한다.

안녕하세요. 데이터 엔지니어 김재민 입니다.