Background
- Iceberg 테이블 생성 및 데이터 갱신 시 Iceberg 의 Data, Metadata 파일을 추적하며 어떻게 동작하는지 기록한다.
Work ENV
- 로컬 환경구성: https://velog.io/@todaybow/environments-for-iceberg-study-on-local
- Language: Python(with. PySpark)
- Data storage: MinIO
- Catalog: REST
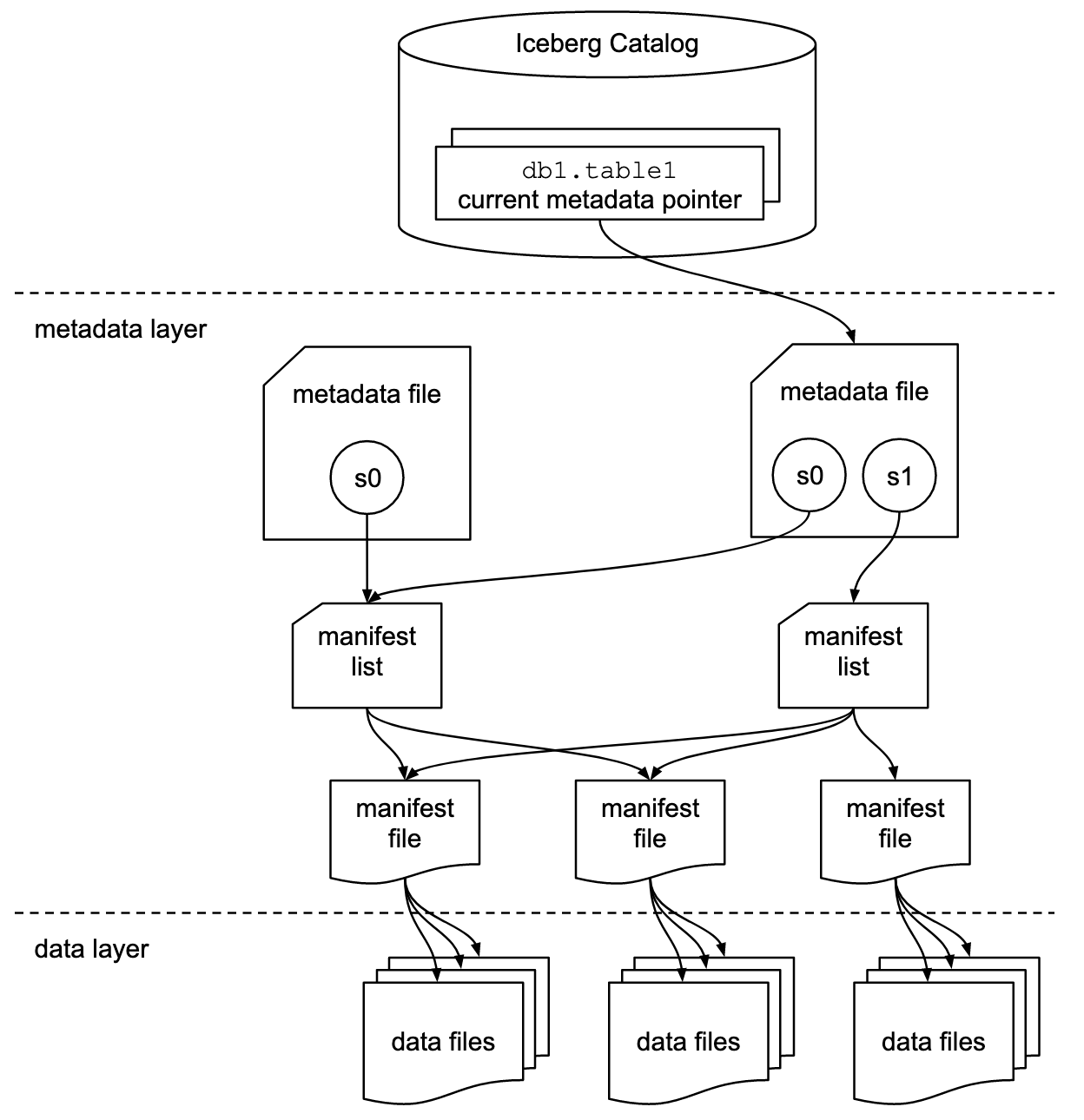
Iceberg Architecture
Iceberg 는 그림과 같이 크게 세 가지 레이어로 구분 된다.
Catalog layer: Iceberg 관련 Catalog 정보를 관리한다. (e.g. DB, 테이블 목록, 각 테이블 의 파일 저장 위치, 최신 metadata 파일 정보 등)Metadata layer: Table 의 Metadata 정보를 기록한다. (e.g. 스키마정보, 테이블생성 시각, 테이블파티션 정보 등)Data layer: 실제 데이터 파일을 관리한다. (e.g. Parquet, Orc etc)
PySpark 으로 Iceberg TABLE 생성 시 Metadata 내용 분석하기
PySpark Session config
Iceberg 학습 환경 세팅 내용을 참고하여 Spark Session config 를 아래와 같이 설정한다.
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("IcebergSparkWithMinIo") \
.config("spark.sql.catalog.iceberg_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.iceberg_catalog.type", "rest") \
.config("spark.sql.catalog.iceberg_catalog.uri", "http://iceberg-rest:8181") \
.config("spark.sql.catalog.iceberg_catalog.warehouse", "s3://warehouse/") \
.config("spark.sql.catalog.iceberg_catalog.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \
.config("spark.sql.catalog.iceberg_catalog.s3.endpoint", "http://minio:9000") \
.config("spark.sql.catalog.iceberg_catalog.s3.access-key-id", "admin") \
.config("spark.sql.catalog.iceberg_catalog.s3.secret-access-key", "password") \
.config("spark.sql.catalog.iceberg_catalog.s3.path-style-access", "true") \
.getOrCreate()CREATE DATABASE
spark session config 에서 설정한
iceberg_catalog카탈로그 하위에서 사용할default데이터베이스를 생성한다.
# PySpark SQL 로 데이터베이스 생성
spark.sql("CREATE DATABASE iceberg_catalog.default")
spark.sql("SHOW DATABASES IN iceberg_catalog").show()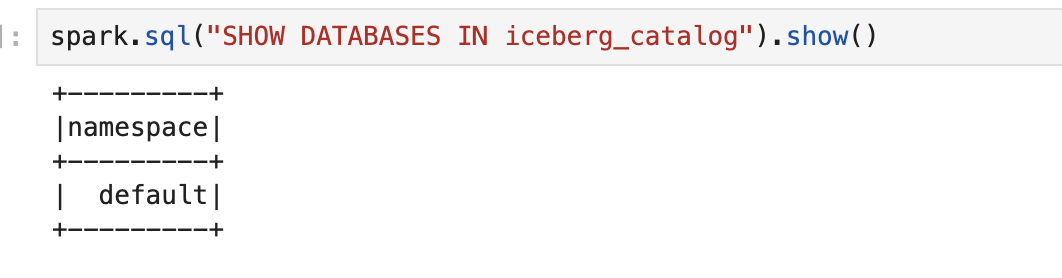
CREATE TABLE
my_table테이블을 생성하고 처음에 데이터가 없은 것을 확인한다.
spark.sql("""
CREATE TABLE iceberg_catalog.default.my_table (
id BIGINT,
name STRING
) USING iceberg
""")spark.sql("""
SELECT * FROM iceberg_catalog.default.my_table
""").show()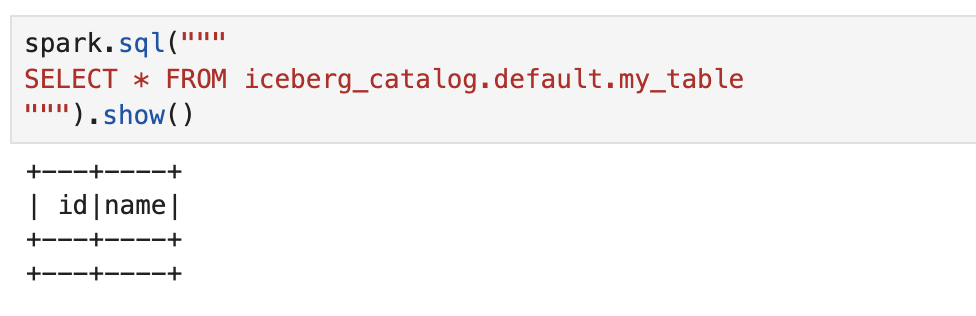
테이블 생성 후 MinIO 에서
default데이터베이스 경로 하위에my_table/와 같이 생성된 것을 볼 수 있다.
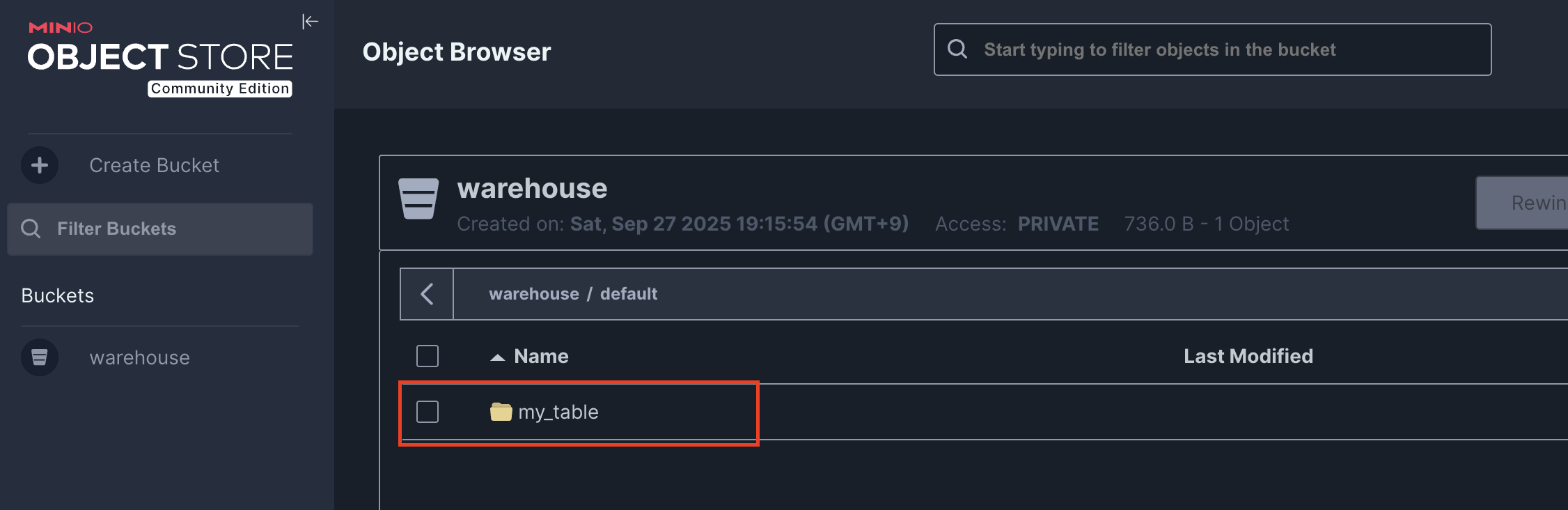
그리고 처음 생성된 테이블에는 아래와 같이
metadata/경로만 존재하는 걸 볼 수 있다. 실제로 삽입된 데이터가 없기 때문에 저장된 data 파일도 없는 것이다.
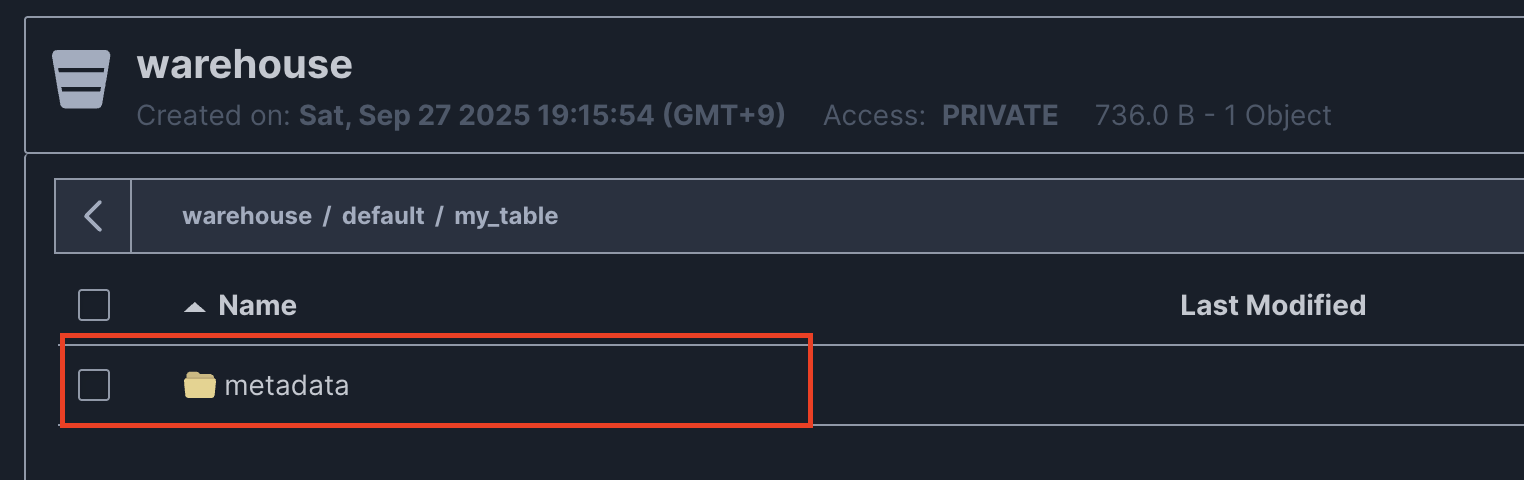
처음 생성된 테이블
metadata/경로에는 아래와 같이 json 파일 하나가 존재한다.
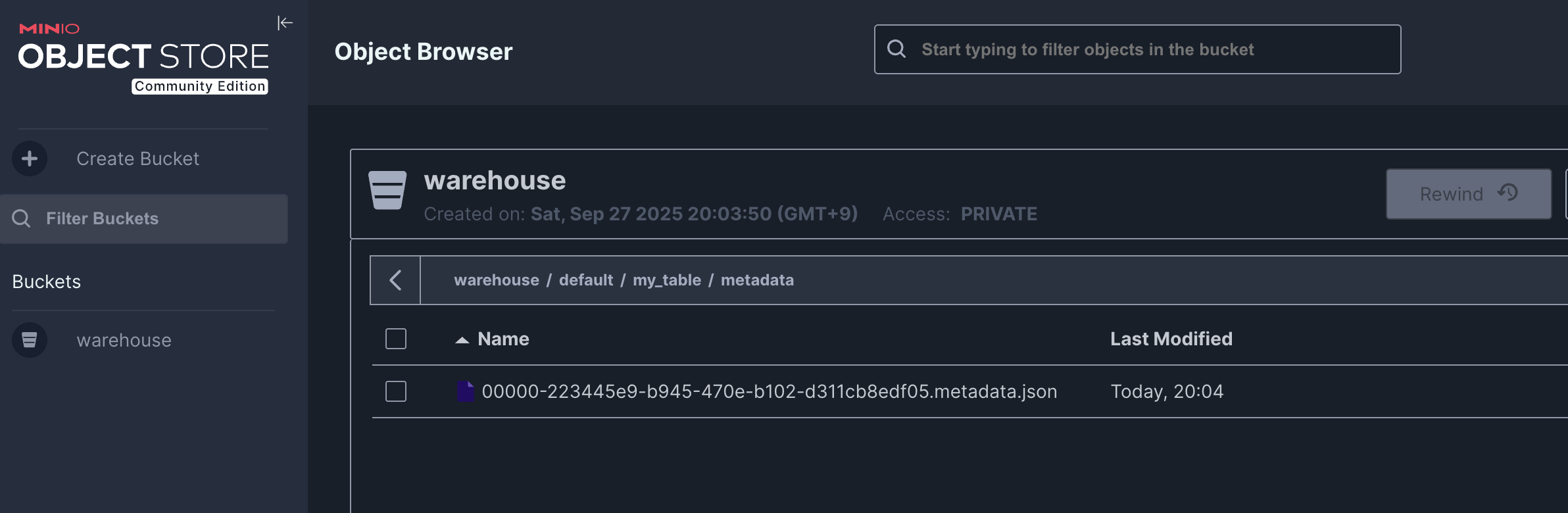
metadata json 파일은 아래와 같은 구조로 되어 있다.
{
"format-version": 2, # Iceberg 테이블 포맷 버전 (https://iceberg.apache.org/spec/#format-versioning)
"table-uuid": "c65bf263-e8ca-4ab0-9d02-e23affe0530d",
# 테이블이 처음 생성될 때 부여되고 CTAS 와 같이 테이블 복제하는 경우가 아니라면 uuid 는 변경되지 않는다.
"location": "s3://warehouse/default/my_table",
# 테이블의 실제 데이터 및 메타데이터가 저장되는 루트 경로
"last-sequence-number": 0, # 데이터 변경작업, 스냅샷 작업 등 모든 변경 사항에 따라 시퀀스 번호가 증가한다.
"last-updated-ms": 1758971050467, # 메타데이터가 마지막으로 갱신된 시간 (epoch milliseconds)
"last-column-id": 2, # 현재 metadata 에서 사용중인 컬럼 id 중 가장 마지막에 사용된(큰) 값
"current-schema-id": 0, # 현재 활성화된 스키마 ID
"schemas": [ # 테이블의 스키마를 기록한다.(e.g. id, name 2개 컬럼이 존재할 때와 ALTER 명령 후 id, name, age 컬럼이 존재하는 버전의 스키마 정보를 모두 저장한다.
{
"type": "struct", # 스키마의 타입 (struct = 구조체 형태)
"schema-id": 0, # 스키마 식별자 -> 스키마가 변경 될 때마다 갱신 되며, 마지막에 갱신된 schema-id 가 current-schema-id 에 할당되어 현재 사용중인 스키마 버전이 무엇인지 확인한다.
"fields": [ # 컬럼 정의 목록
{
"id": 1, # 컬럼 고유 ID(rename, data type 변경 되어도 컬럼 고유 ID 는 변경되지 않는다)
"name": "id", # 컬럼 이름
"required": false,# NULL 허용 여부 (false = nullable)
"type": "long" # 데이터 타입(Spark BIGINT
},
{
"id": 2,
"name": "name",
"required": false,
"type": "string"
}
]
}
],
"default-spec-id": 0, # 현재 사용 중인 파티션 스펙 ID(partition-specs 리스트 중에 사용중인 spec-id 정보)
"partition-specs": [ # 테이블의 파티션 스펙 정의
{
"spec-id": 0, # 파티션 스펙 ID
"fields": [] # 파티션 컬럼이 없는 상태 (즉, non-partitioned table)
}
],
"last-partition-id": 999, # 파티션 필드 ID를 생성할 때 사용하는 마지막 ID 값
"default-sort-order-id": 0, # 현재 사용 중인 정렬 순서 ID
"sort-orders": [ # 정의된 정렬 순서 목록
{
"order-id": 0,
"fields": [] # 정렬 조건 없음 (default)
}
],
"properties": { # 사용자 정의 속성 및 Iceberg 옵션
"owner": "root", # 테이블 소유자 정보
"write.parquet.compression-codec": "zstd"
# Parquet 파일 저장 시 사용하는 압축 코덱
},
"current-snapshot-id": -1, # 현재 활성화된 스냅샷 ID (-1은 아직 스냅샷 없음 → 초기 상태)
"refs": {}, # 스냅샷 참조(브랜치/태그) 정보
"snapshots": [], # 스냅샷 히스토리 (아직 없음)
"statistics": [], # 스냅샷/파일 통계 정보
"partition-statistics": [], # 파티션 단위 통계 정보
"snapshot-log": [], # 스냅샷 히스토리 로그
"metadata-log": [] # 메타데이터 파일 변경 히스토리
}
안녕하세요. 데이터 엔지니어 김재민 입니다.