Background
pyspark 으로 dataframe 을 s3 에 wrtie 할 때, 아래와 같이 partitionBy 경로를 지정해두고 overwrite 하는 경우 동일 뎁스에 위치한 다른 파티션(이하 폴더)이 같이 삭제되고 새로 업로드 되는 파티션 경로만 업로드 된다.
df_clean.write.parquet(path=destination_s3_path,
mode="overwrite",
partitionBy=["yyyymmddhh"],
compression="snappy"
)예를 들어,
my_folder/하위에2024080800/,2024080801/,202408082/폴더가 존재하고2024080803/데이터를 overwrite 하게 되면 00~02 시에 해당하는 폴더들이 삭제 되고,2024080803/폴더만 남게 된다. 하지만, 나는 작업이 재수행 될 때 해당 폴더만 삭제 되면서 overwrite 되길 원했다.
Countermeasures
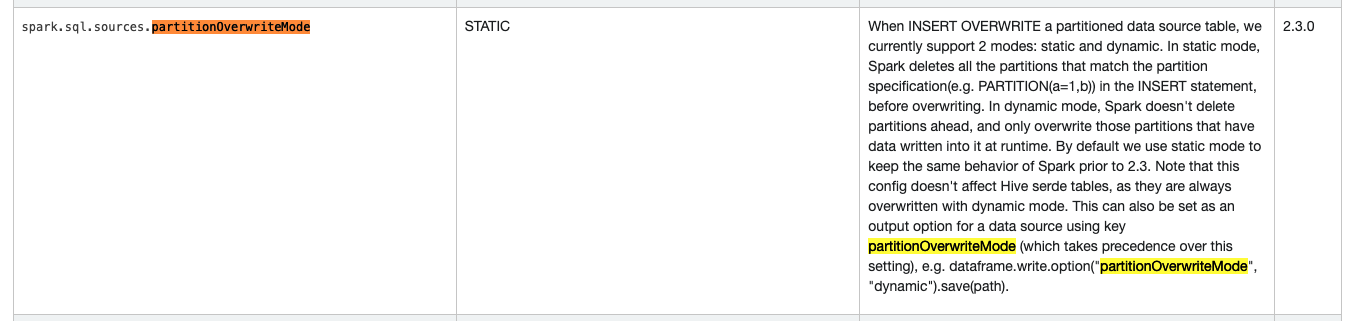
멱등성 유지를 위해서, 해당 폴더만 overwrite 하려면 아래와 같이
partitionOverwriteMode옵션을dynamic으로 지정하면 된다.
df_clean.write.option("partitionOverwriteMode", "dynamic")\
.parquet(path=destination_s3_path,
mode="overwrite",
partitionBy=["yyyymmddhh"],
compression="snappy"
)Spark Document

안녕하세요. 데이터 엔지니어 김재민 입니다.