[Algorithm] Pattern Matching
이번 글은 서강대학교 소정민 교수님의 강의와 Ellis Horowitz의「Fundamentals of Data Structures in C」를 바탕으로 작성했음을 밝힙니다.
0. Overview
Pattern Matching은 문자열(String) 자료구조에서 가장 중요한 Operation 중 하나입니다.
Pattern Matching의 기본적인 명세는 "문자열 두 개가 주어지면, 한 문자열(pattern)이 다른 문자열에 나타나는지 판단" 하는 것입니다.
1. Simple Matching Algorithm
1.1 Illustration
C에는 Pattern Matching에 쓸 수 있는 strstr(string, pat) 이라는 패키지가 있는데, 이를 직접 구현해보도록 합시다.
이 단순한 알고리즘은 아래와 같은 단계로 진행됩니다.
-
string을 탐색하며 pat의 맨 앞 문자와 비교함
- 같으면 string과 pat의 다음 문자가 같은지 비교함
- 다르면 다음 문자로 이동
-
패턴의 끝 문자까지 문자열이 같으면 Yes를 출력
-
문자열의 끝 문자까지 탐색하면 No를 출력
1.2 Implementation
C
# include <stdio.h>
# include <stdlib.h>
# include <string.h>
int nfind(char*, char*);
void main() {
char pat1[] = "fici";
char pat2[] = "Arts";
char str[] = "ArtificialIntelligence";
int rv;
rv = nfind(str, pat1);
if (rv == -1) {
printf("The pattern %s was not found in the string.\n", pat1);
}
else {
printf("The pattern %s was found at position %d in the string.\n", pat1, rv);
}
}
int nfind(char* string, char* pat) {
int i, j, start = 0;
int lasts = strlen(string) - 1;
int lastp = strlen(pat) - 1;
int endmatch = lastp;
//slight improvement > compare last
for (i = 0; endmatch <= lasts; endmatch++, start++) {
if (string[endmatch] == pat[lastp])
for (j = 0, i = start; j < lastp && string[i] == pat[j]; i++, j++);
if (j == lastp) return start;
}
return -1;
}Python
def nfind(string, pat):
length_pat = len(pat)
length_string = len(string)
for n in range(length_string):
if string[n] == pat[0]:
for m in range(1, length_pat):
if string[n+m] != pat[m]:
break
else:
return(f"YES({n})")
else:
return("NO")
if __name__ == "__main__":
string = "ArtificialIntelligence"
pat1 = "fici"
pat2 = "Arts"
print(f"string: {string}, pat: {pat1}, match: {nfind(string, pat1)}")
print(f"string: {string}, pat: {pat2}, match: {nfind(string, pat2)}")2. KMP Algorigthm
1.1 Illustration
KMP 알고리즘은 Pattern Matching을 linear complexity에 수행하는 알고리즘입니다.
이 알고리즘은 위의 Simple Matching Algorithm이 낭비하고 있는 정보 를 이용해서 Pattern Matching 문제에 훨씬 효율적으로 접근하는 알고리즘입니다.
이에 대한 이야기는 끝에서 하고 우선, 기본적인 아이디어를 살펴보겠습니다.
Idea
When a mismatch occurs, use our knowledge of the characters in the pattern and the position in the pattern where the mismatch occured, to determine where we should continue the search
Strategy
첫 번째 iteration이 다음 위치에서 종료되었다고 합시다.
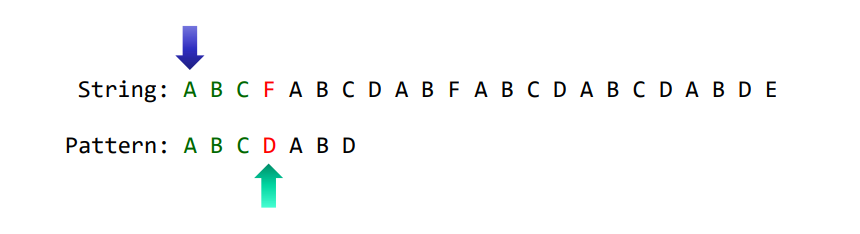
A, B, C는 비교가 끝났으므로, mismatch가 일어난 시점부터 다시 iteration을 진행한다면, 훨씬 효율적일텐데요. 위의 예에서는 A가 패턴에 두 번 이상 나타나지 않았기 때문에(ABC) 이러한 방법이 가능합니다.
한편, 다음의 iteration을 고려해봅시다.
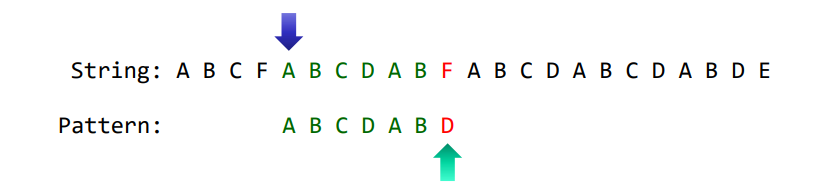
위의 예에서는 Pattern의 마지막 문자에서 mismatch가 일어났기 때문에, 앞의 논리대로라면 그 때부터 iteration을 진행하면 될 테지만, 이 때에는 아래처럼 mismatch가 일어난 시점 전에 A가 존재합니다. 따라서 이 지점을 시작으로 하는 패턴이 존재할 가능성이 있으므로, 아래와 같이 포인터를 앞으로 땡겨야 합니다.
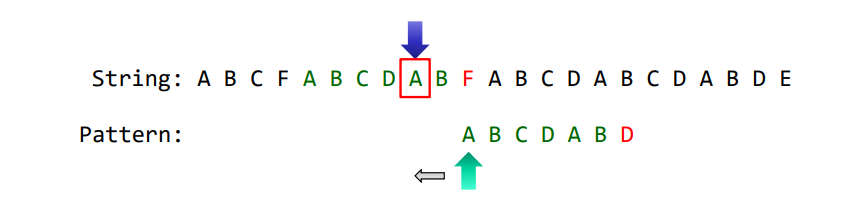
하지만, 이 때, A, B 두 문자는 이미 패턴의 첫 번째, 두 번째 문자와 일치한다는 사실을 알고 있으면, 포인터를 앞으로 땡길 필요 없이, C에서부터 iteration을 진행하면 됩니다.
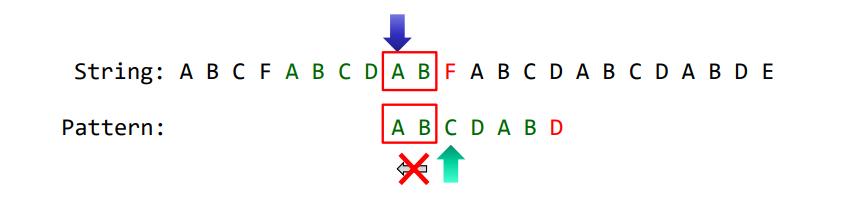
그렇다면, 어느 지점부터 iteration을 진행하야 하는지는 어떻게 알 수 있을까요?
이를 위해서는 Prefix와 Suffix라는 개념을 이해해야 합니다.
Prefix and Suffix
저는 Prefix와 Suffix를 다음과 같이 이해했습니다.
- Prefix: 크기가 인 문자열 S의
S[:k]( k<=n ) - Suffix: 크기가 인 문자열 S의
S[n-k:]( k<=n )
구체적인 예시를 보면, ABCDE의 Prefix는 다음과 같습니다.
- A
- AB
- ABC
- ABCD
- ABCDE
ABCDE의 Suffix는 다음과 같습니다.
- E
- DE
- CDE
- BCDE
- ABCDE
KMP 알고리즘은 Prefix와 Suffix를 이용해, 주어진 문자열(string)에서 prefix == suffix 인 문자열 중 가장 긴 것의 길이를 구합니다. 그리고 mismatch가 발생하면, 이 길이만큼을 뛰어넘고 iteration을 진행합니다.
2.2 Implement
C Code
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_STRING_SIZE 100
#define MAX_PATTERN_SIZE 100
int pmatch(char*, char*);
void fail(char*);
int failure[MAX_PATTERN_SIZE];
char string[MAX_STRING_SIZE];
char pat[MAX_PATTERN_SIZE];
void main() {
int rv, i;
strcpy(string, "ababcabcabababdabaabaabacabaababaaabaabaacaaba");
strcpy(pat, "abaababaaaba");
fail(pat);
for(i=0; i<strlen(pat); i++) {
printf("%d ", failure[i]);
}
printf("\n");
rv = pmatch(string, pat);
printf("rv: %d\n", rv);
}
void fail(char *pat) {
// 일차적으로 패턴 먼저 분석
int i, j, n = strlen(pat);
failure[0] = -1;
for(j=1; j<n; j++) {
i = failure[j-1];
//중요! 이 줄을 이해하는 것이 핵심임
//n번째 문자열로써 일치하지 않을 때, ~n-1번째 문자열로써 일치하는지 확인
while((pat[j] != pat[i+1]) && (i >= 0)) i = failure[i];
if(pat[j] == pat[i+1]) failure[j] = i+1;
else failure[j] = -1;
}
}
int pmatch(char *string, char *pat) {
// 분석한 패턴으로 string matching 진행
int i=0, j=0;
int lens = strlen(string);
int lenp = strlen(pat);
while(i < lens && j < lenp) {
if(string[i] == pat[j]) { i++; j++; }
else if(j == 0) i++;
else j = failure[j-1] + 1;
}
return ((j==lenp) ? (i-lenp) : -1);
}Python Code
def fail(pat):
global failure
for j in range(1, lenp):
i = failure[j-1]
while pat[j] != pat[i+1] and i>=0:
i = failure[i]
if pat[j] == pat[i+1]:
failure[j] = i+1
else:
failure[j] = -1
def pmatch(string, pat):
global failure
i, j = 0, 0
while i<lens and j<lenp:
if string[i] == pat[j]:
i+=1
j+=1
elif j==failure[j-1]+1:
i+=1
else:
j=failure[j-1]+1;
if j==lenp:
return(i-lenp)
else:
return(-1)
if __name__ == "__main__":
string = input()
pat = input()
lens = len(string)
lenp = len(pat)
failure = [-1]
pmatch(string, pat)3. Time Complexity
| Simple Matching | KPM Algorithm | |
|---|---|---|
| Worst-Case |
Refercence
교재와 강의만으로는 알고리즘을 이해하기 어려워 다양한 블로그와 유튜브를 찾아보았는데, 이 블로그 가 이해에 도움이 가장 많이 되었습니다.
