3.1 대규모 분산 처리의 프레임워크
3.1.1 구조화 데이터와 비구조화 데이터
- SQL로 데이터를 집계하는 경우, 테이블의 칼럼 명과 데이터형, 테이블 간의 관계 등을 스키마(schema)로 정함
- 스키마가 명확하게 정의된 데이터를 ‘구조화된 데이터(structured data)’라고 함
- 기존의 데이터 웨어하우스에서는 데이터는 항상 구조화된 데이터로 축적하는 것이 일반적이었음
- 스키마가 없는 데이터(텍스트 데이터, 이미지 데이터 등) 는 ‘비구조화된 데이터(unstructured data)’ 라고 함→ SQL 집계 불가능
- 이러한 데이터를 데이터 레이크에 모아놓고 ETL을 통해 스키마를 정의하고 구조화된 데이터로 변환함으로써 분석이 가능해짐
스키마리스 데이터
- CSV, JSON, XML 등, 데이터의 서식은 정해져있으나, 칼럼 수나 데이터형은 명확하지 않은 데이터를 ‘스키마리스 데이터(schemaless data)’ 라고 부름
- 몇몇 NoSQL 데이터베이스는 이에 대응하고 있음
데이터 구조화의 파이프라인
- 각 데이터 소스에서 수집된 비구조화/스키마리스 데이터는 분산 스토리지에 저장됨
- 이대로 SQL로 집계할 수 없으므로, 스키마를 명확하게 한 테이블 형식의 ‘구조화 데이터’로 바꿔줘야 함
- 구조화 데이터는 데이터 압축률을 높이기 위해 일반적으로 열 지향 스토리지 형식으로 저장됨
- 구조화 데이터 중 시간에 따라 증가하는 데이터를 팩트 테이블, 그에 따른 부속 데이터를 디멘션 테이블 로 취급함
- 테이블을 조인하지 않고, 먼저 데이터를 구조화하여 SQL로 집계 가능한 테이블을 만드는 것만 생각
열 지향 스토리지의 작성
분산 스토리지 상에 작성해 효율적으로 데이터를 집계
- Hadoop에서는 사용자가 직접 열 지향 스토리지의 형식을 선택하고, 자신이 좋아하는 쿼리 엔진에서 그것을 집계할 수 있음
- Apache ORC: 구조화 데이터를 위한 열 지향 스토리지로, 처음에 스키마를 정한 후 데이터를 저장함 → 책에서는 이 것 이용
- Apache Parquet: 스키마리스에 가까운 데이터 구조로 되어 있어 JSON같은 뒤얽힌 데이터도 그대로 저장할 수 있음
3.1.2 Hadoop
분산 데이터 처리의 공통 플랫폼
- Hadoop은 단일 소프트웨어가 아니라 분산 시스템을 구성하는 다수의 소프트웨어로 이루어진 집합체이다.
분산 시스템의 구성 요소
HDFS, YARN, MapReduce
-
Hadoop의 기본 구성 요소
- 분산 파일 시스템인 ‘HDFS(Hadoop Distributed File System)’
- 리소스 관리자 인 ‘YARN(Yet Another Resource Negotiator’)
- 분산 데이터 처리의 기반인 ‘MapReduce’
-
모든 분산 시스템이 Hadoop에 의존하는 것이 아니라, Hadoop을 일부만 사용하거나, 혹은 전혀 이용하지 않는 구성도 있음
-
다양한 소프트웨어 중에서 자신에게 맞는 것을 선택하고 그것들을 조합함으로써 시스템을 구성하는 것이 Hadoop을 중심으로 하는 데이터 처리의 특징
분산 파일 시스템과 리소스 관리자
HDFS, YARN
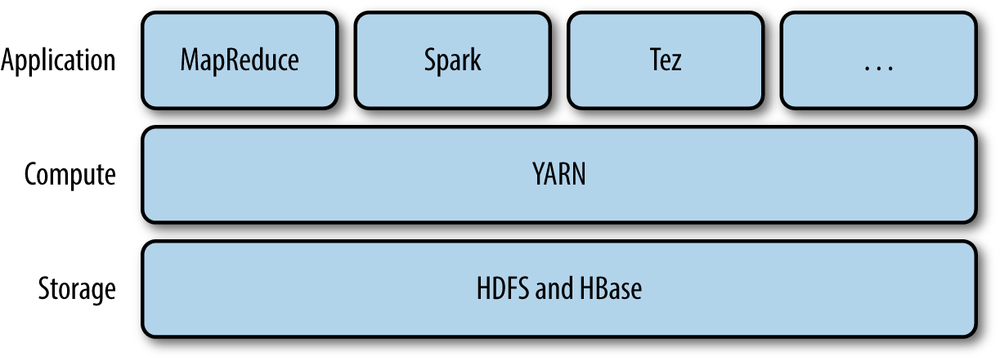
-
하둡에서 처리되는 데이터 대부분은 분산 파일 세스템인 HDFS에 저장됨
-
네트워크에 연결된 파일 서버와 같은 존재이지만, 다수의 컴퓨터에 파일을 복사하여 중복성을 높인다는 특성이 있음
-
CPU나 메모리 등의 계산 리소스는 리소스 매니저인 YARN에 의해 관리됨
-
YARN은 애플리케이션이 사용하는 CPU 코어와 메모리를 컨테이너(container)라 불리는 단위로 관리함
-
Hadoop에서 분산 애플리케이션을 실행하면 YATN이 클러스터 전체의 부하를 보고 비어 있는 호스트부터 컨테이너를 할당함
분산 데이터 처리 및 쿼리 엔진
MapReduce, Hive
-
MapReduce는 YARN 상에서 동작하는 분산 애플리케이션 중 하나이며, 분산 시스템에서 데이터 처리를 실행하는 데 사용됨
-
비구조화 데이터를 가공하는 데 적합
-
대량의 데이터를 배치 처리하기 위해 개발된 시스템으로, 작은 프로그램을 실행하려면 오버헤드가 너무 큼
-
SQL 등의 쿼리 언어에 의한 데이터 집계가 목적이라면 그것을 위해 설계된 쿼리 엔진을 사용함
-
Apache Hive
-
MapReduce와 마찬가지로 작은 프로그램을 실행하기엔 부적합
Hive on Tez
- Hive를 가속화하기 위한 노력으로 개발됨
대화형 쿼리 엔진
Impala와 Presto
- 대화형 쿼리 엔진으로는 순간 최대 속도를 높이기 위해 모든 오버헤드가 제거되어 사용할 수 있는 리소스를 최대한 활용하여 쿼리를 실행함
- SQL-on-Hadoop: Hadoop에서 개발한 다수의 쿼리 엔진
3.1.3 Spark
인 메모리 형의 고속 데이터 처리
- 대량의 메모리를 활용하여 고속화를 실현한다는 특징이 있음
- 컴퓨터에서 취급하는 메모리의 양이 증가함에 따라, 뭐든지 디스크에서 읽고 쓰는 것이 아니라 ‘가능한 한 많은 데이터를 메모리상에 올린 상태로 두어 디스크에는 아무것도 기록하지 않는다’는 선택 현실화됨
MapReduce 대체하기
Spark의 입지
- Spark는 Hadoop이 아니라 MapReduce를 대체하는 존재
- HDFS, YARN은 모두 Spark에서 사용 가능함
- Hadoop을 이용하지 않는 구성 이용 가능
- 분산 스토리지로 Amazon S3 이용, 분산 DB인 Cassandra에서 데이터 읽어들이기
- Spark 실행에는 자바 런타임이 필요하지만, Spark 상에서 실행되는 데이터 처리는 스크립트 언어로 사용할 수 있음
