🤔테이블 전략 전에 알아둬야할 요소들
강의보면 테이블 전략에서 예시로 사용되는 MAIN함수 안에서 못보던(..????놓쳤나 잊었나) 놈들이 있어서 정리좀하고가야겠어요
EntityManagerFactory emf = Persistence.createEntityManagerFactory("entity");
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
이놈들이다....
Spring boot에서는 잘 안씀
🟠 EntityManagerFactory
역할
- JPA에서 가장 처음 만들어야 하는 객체
Persistence Unit을 기반으로EntityManager를 생성하는 팩토리 역할을 한다.- 하나의 애플리케이션에서 딱 하나만 생성해야 한다. (비용이 비싸기 때문에)
Persistence.createEntityManagerFactory("entity")호출로 생성
→persistence.xml파일에서"entity"라는 이름의persistence-unit설정을 찾아 설정을 로딩함.
✅ 언제 필요?
- 애플리케이션이 시작될 때 딱 한 번 생성해서 재사용.
SpringBoot에서는EntityManagerFactory를 스프링이 자동으로 설정해줌 (직접 만들 필요 X)
머임 ?직접 만들 필요가없대
EntityManagerFactory emf = Persistence.createEntityManagerFactory("entity");이 내용을 풀어보면
META-INF/persistence.xml파일을 찾는다.- 그 안에 라는 설정을 찾는다.
- 그 설정을 기반으로 EntityManagerFactory를 생성한다.
참고로 META-INF/persistence.xml은
<!-- META-INF/persistence.xml -->
<persistence-unit name="entity">
<class>com.example.Product</class>
...
</persistence-unit>
이렇게 생겼을 것이다!!
결국엔 Product 테이블에 CRUD하게씀 준비할거임 임.
설정 로딩 → EntityManager 생성기
🟡 EntityManager
✨ 역할
- JPA의 핵심 객체
- 실제로 엔티티를 데이터베이스에 CRUD 하는 기능을 제공
→ persist, find, merge, remove 등
✅ 언제 필요?
- 하나의 트랜잭션 단위 또는 요청/스레드 단위로 생성해서 사용
- 사용 후 반드시
close()해야 함
실제 DB 조작 (CRUD)
🟢 EntityTransaction
역할
- JPA는 트랜잭션 안에서만 작동함.
EntityTransaction은 JPA에서 트랜잭션을 시작하고, 커밋하고, 롤백하는 역할.
✅ 언제 필요?
자바 SE 환경에서는 명시적으로 트랜잭션을 시작하고 끝내야 함
스프링에서는 @Transactional을 써서 자동으로 트랜잭션을 시작하고 커밋/롤백함
트랜잭션 시작/커밋/롤백
테이블 전략 이모지 뭘로하지.
🧮 테이블 전략
참고자료 : 강의 자료
https://datamoney.tistory.com/328
https://colevelup.tistory.com/44
JPA에서 엔티티 상속 구조를 데이터베이스 테이블에 매핑하는 방법을 말한다.
JPA는 엔티티의 상속 구조를 처리하기 위해 3가지의 테이블 전략을 제공하며 각각의 전략은 데이터 저장 방식과 성능에 차이가 있으므로 프로젝트의 요구사항에 맞게 선택할 수 있다.
💡 관계형 데이터베이스의 테이블에는 상속 관계가 없다.
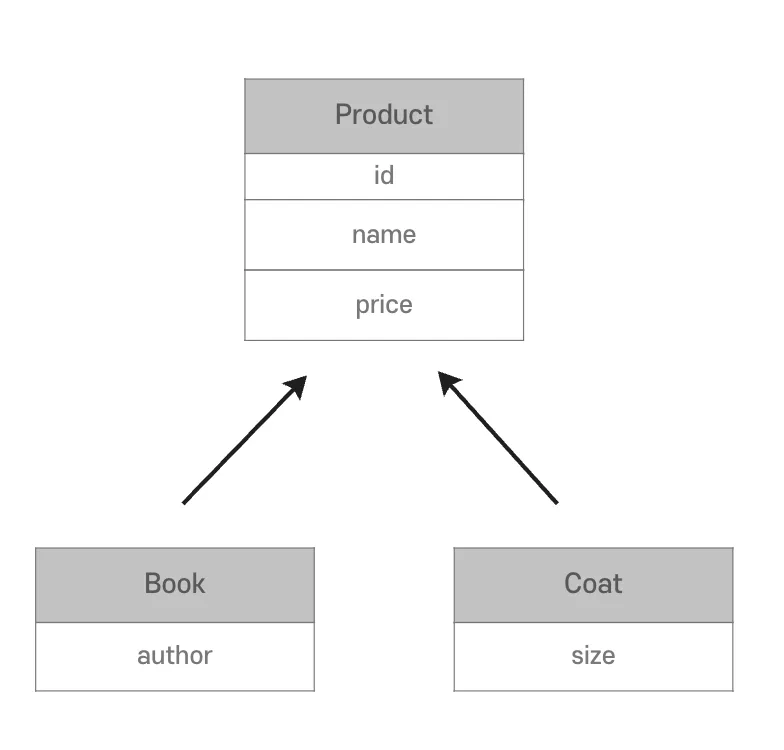
예를들어서 이런 테이블 구조가 있다고 치자
화살표 보면 알겠지만
- Book 객체는 Product를 상속받아서 안에 변수가 author, id, name, price가 있음
- Coat 객체는 Product를 상속받아서 안에 변수가 size, id, name, price가 있음
<3가지의 테이블 전략>
1️⃣ 조인 전략
- 각각을 테이블로 만든다.
DTYPE으로 어떤 테이블의 데이터인지 구분한다.- Book, Coat 테이블에 Product_id값이 들어감.
2️⃣ 단일 테이블 전략
- 하나의 테이블로 만든다.
- DTYPE 으로 어떤 테이블의 데이터인지 구분한다.
- 두 테이블의 값 중 하나는
null이 허용된다.
3️⃣ 구현 클래스
- 구현 클래스 각각을 테이블로 만든다.
- Book 테이블에 author, id, name, price 컬럼을 넣는다.
- Coat 테이블에 size, id, name, price 컬럼을 넣는다.
<Annotation>
-
@Inheritance(strategy = InheritanceType.${전략})JOINED: 조인SINGLE_TABLE: 단일 테이블(Default)TABLE_PER_CLASS: 구현 클래스
-
@DiscriminatorColumn(name = "dtype")dtype컬럼을 생성한다(관례).- 이름 변경이 가능하다.
- 기본 값 :
DTYPE
-
@DiscriminatorValue("${값}")dtype값 지정- 기본 값 : 클래스 이름
엔티티의 기본 골자는 아래와 같다.
@Entity
@Table(name = "product")
public abstract class Product {
@Id @GeneratedValue
private Long id;
private String name;
private int price;
}
//=================================
@Entity
public class Book extends Item{
private String author;
}
//==================================
@Entity
public class Coat extends Item{
private int size;
} ✔️ 여기서는 공통으로 들어가는 클래스(id, name, price를 가진 Product)는 상속과 항관없이 해당 item값만으로 독단적으로 사용할 여지가 있기 때문에 abstract로 선언되어야 한다.
1️⃣ 조인 전략
JPA의 조인 전략에서
@DiscriminatorColumn을 선언하지 않으면 DTYPE 컬럼이 생성되지 않는다. (부모 클래스의 기본 키를 자식 클래스에서 외래 키로 사용)JOIN을 통해 테이블을 구분할 수 있지만, DTYPE 컬럼을 넣어주는 것이 명확하다.
++) @DiscriminatorColum을 넣어주면 DTYPE이라고 생기고 default가 Entity명이 들어감.
하지만 DTYPE 이 있는 게 좋다.

결과로 이런식으로 나온다!(강의자료 펌 ㅎ)
가으이 자료에서는 DTYPE 에다가 "B"라고 값을 넣어줬는데, 만약에 따로값 주지않으면 테이블이름인 "Book"이 들어감//
@Entity
@DiscriminatorColumn
@Inheritance(strategy = InheritanceType.JOINED)
public abstract class Product {
@Id @GeneratedValue
private Long id;
private String name;
private int price;
}
//=================================
@Entity
public class Book extends Item{
private String author;
}
//==================================
@Entity
public class Coat extends Item{
private int size;
}값 넣어주려면
public class Main {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("entity");
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
transaction.begin();
try {
Book book = new Book("wonuk", "spring-advanced", BigDecimal.TEN);
em.persist(book);
em.flush(); // 변경사항을 즉시 DB로 반영
em.clear(); // 영속성 컨텍스트 초기화
Book findBook = em.find(Book.class, book.getId());
transaction.commit();
} catch (Exception e) {
transaction.rollback();
} finally {
em.close();
}
emf.close();
}
}🛑 장점
- 테이블의 정규화
- 외래 키 참조 무결성 제약조건 활용 가능
- 저장공간 효율성
🛑 단점
- 조회시 많은 조인이 일어나 성능에 문제될 수 있음
- 조회시 쿼리 복잡
- INSERT SQL 두번 실행됨
❓
flush()와commit()의 차이점예시) 영속성 컨텍스트는 JPA가 들고 있는 "작업 임시장부"
flush()는 그 장부의 내용을 임시로 DB에 넘겨주는 행위
commit()은 그 내용을 진짜로 계약서에 도장 찍는 행위flush()만 하면:
→ DB에 INSERT/UPDATE는 날렸지만, 트랜잭션이 끝난 건 아님.
→ 롤백하면 다시 되돌릴 수 있음.commit() 하면:
→ 트랜잭션 종료 + flush 자동 호출 → 데이터 확정
→ 롤백 불가능.

2️⃣ 단일 테이블 전략
JPA 단일 테이블 전략에서
@DiscriminatorColumn을 선언해 주지 않아도 기본으로DTYPE컬럼이 생성된다. 한 테이블에 모든 컬럼을 저장하기 때문에DTYPE없이는 테이블을 판단할 수 없다.
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
public abstract class Product {
@Id @GeneratedValue
private Long id;
private String name;
private int price;
}
//=================================
@Entity
public class Book extends Item{
private String author;
}
//==================================
@Entity
public class Coat extends Item{
private int size;
}🛑 장점
- 조회 성능 빠름 (조인 X)
- 조회 쿼리 단순
🛑 단점
- 자식 엔티티 컬럼에 null 허용됨
- 단일 테이블이라 오히려 몸집이 커져 성능에 문제 생길 수 있음
단일 테이블에 모든 것을 저장하므로 테이블이 커질 수가 있음.
상황에 따라서 조회 성능이 오히려 느려질 수 있음.
보통 임계점을 넘지는 않아 보임.
3️⃣ 구현 클래스
JPA 구현 클래스 전략에서는 상속 관계를 무시하고 각 테이블이 별도의 ID 시퀀스를 관리해야 한다. 동일한 @Id 값을 가진 데이터가 여러 테이블에 존재할 수 있다.
GenerationType.IDENTITY를 사용하지 못한다.
상당히 비추
객체 지향과 디비 둘 다 싫어하는 전략 이라고 함
🛑 장점
- 자식 테이블 컬럼에 not null을 설정할 수 있음
- 서브 타입 구별 처리에 효과적
🛑 단점
- 자식이 여럿일 때 조회 성능 떨어짐 (UNION 사용)
- 자식을 통합해 쿼리하기 어려움
그럼이건 건너뛰겠삼,
❓테이블 조인 전략 vs @MappedSuperclass
👉
@MappedSuperclass는 JPA 입장에서 공통 속성 필드를 자식에게 물려주는 용도로,
테이블은 생성되지 않으며 상속 구조로 표현되지도 않는다.반면 JOINED 같은 테이블 조인 전략은 비즈니스 계층 구조를 테이블 설계로 표현하며,
부모와 자식이 각각 테이블을 가지며 조인하여 조회한다.
어떤 걸 표현하려는지(단순 공통 속성 vs 계층 구조 개념)를 명확히 하는 게 중요함!
📟 Proxy
참고자료
https://velog.io/@guswns3371/프록시-즉시-로딩-그리고-지연로딩
강의자료
https://jskim-dev.tistory.com/34
JPA에서 엔티티 객체의 지연 로딩(Lazy Loading)을 지원하기 위해 사용하는 대리 객체로 실제 엔티티 객체를 생성하거나 데이터베이스에서 값을 읽어오지 않고도 엔티티의 참조를 사용할 수 있다.
즉, 실제 데이터는 필요할 때(DB에서 진짜 값을 꺼내야 할 때) 가져오고,
그 전까지는 "껍데기"로만 존재하는 객체라고 보면됨.
언제 디비가 읽어지나
DB에서 실제 데이터를 조회하는 시점은 프록시 객체의 실제 필드나 메서드에 접근할 때.
Book book = em.getReference(Book.class, BookId); // 프록시 객체만 반환 (DB 접근 X)
String name = book.getName(); // 이때 진짜 DB에 접근해서 데이터를 조회함실제 객체 안의 특정 값이나 메서드를 사용할때 읽어옴.
그래서 프록시는 처음 사용하는 시점에 한 번만 초기화되고, 그 이후는 진짜 객체처럼 동작할 수 잇음.
특징
- 최초로 사용(실제 Entity에 접근)할 때 한 번만 초기화된다.
- 초기화되면 프록시 객체를 통해서 실제 엔티티에 접근 가능하게 되는 것이지 실제 엔티티로 바뀌는 것은 아님
- 프록시 객체를 통해 실제 Entity에 접근할 수 있다.
em.getReference()호출 시 영속성 컨텍스트에 Entity가 존재하면 실제 Entity가 반환된다.- 이 반대 상황도 마찬가지다. (프록시 객체로 조회하면 em.find()를 호출해도 프록시 객체를 반환한다.)
- 왜냐하면, JPA는 동일 트랜잭션안에서 동일 영속성 컨택스트 속에 조회되는 Entity의 동일성을 보장해줘야하기 떄문이다.
- 준영속 상태에서 프록시를 초기화하면
LazyInitializationException예외가 발생한다. - 프록시 객체는 원본 엔티티를 상속받는다. 따라서 타입 체크시 주의해야한다.
(== 비교 대신instance of사용해야한다.)
⚠️ LazyInitializationException
이건 프록시 객체가 아직 초기화되지 않은 상태인데, 영속성 컨텍스트 밖에서 사용하려고 할 때 터지는 에러임.
프록시 객체가 초기화 되려면 em.getReference() 함수를 통해서 객체를 가져와야함. (물론 db읽어오는건아니고 초기화 한다는 소리)
그전에 Lazy한 객체안의 필드값이나 메서드를 불러오려고 할 때 일어남..,
또!!!!
초기화 된 객체를 em.detach(member); 이런식으로 준 영속 상태를 만들어준 후에 접근하려고 하면 일어남..,
프록시는 영속성 컨텍스트 안에서만 제대로 작동한다는 것
- 초기화 되어야 하고
- 준영속 상태로 만들면 안됨.
언제쓰면좋지?
-
연관된 객체를 반드시 즉시 사용하지 않을 때
예: Member → Team 관계가 있을 때, 멤버 정보를 자주 조회하지만 팀 정보는 거의 필요 없을 때 -
성능 최적화가 필요할 때
연관된 엔티티를 한 번에 다 불러오면 쿼리가 너무 많아지고, 불필요한 조회가 생길 수 있어 -
트랜잭션 범위 내에서 사용하는 서비스
지연 로딩된 프록시 객체가 트랜잭션 안에서 쓰이면 DB에서 조회가 가능하므로 안정적으로 작동
정리
- 프록시는 실제 객체 대신 존재하는 지연 로딩용 껍데기 객체
- DB 조회는 진짜 필드/메서드에 처음 접근할 때 한 번만 발생
- 트랜잭션 밖에서 접근하면
LazyInitializationException발생 (⚠️주의!)- 프록시는 연관된 데이터를 꼭 필요할 때만 조회하고 싶은 경우 유용하다
지연로딩, 즉시로딩
지연로딩은 저번에 대충 알아둬서 대충쓰고감
지연 로딩 - Lazy Loading
지연 로딩(Lazy Loading)은 데이터를 실제로 사용할 때 데이터베이스에서 조회하는 방식
FetchType.LAZY: 지연로딩- 지연로딩을 사용하면 Proxy 객체를 조회한다.
- 연관된 객체(
Company)를 매번 함께 조회하는것은 낭비인 경우에 사용한다.
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "company_id")
private Company company;이렇게 해두면 실제 값에 접근할 때 조회 SQL이 실행된다.
💡 지연 로딩을 사용하면 연관된 객체를 Proxy로 조회한다
읽기 전용이면 웬만하면 Lazy로 하라고 추천하더라
즉시로딩 - Eager Loading
즉시 로딩(Eager Loading)은 엔티티를 조회할 때 연관된 데이터까지 모두 한 번에 로드하는 방식
FetchType.EAGER: 즉시 로딩- Proxy 객체를 조회하지 않고 한 번에 연관된 객체까지 조회한다.
- 연관된 객체(
Company)를 매번 함께 조회하는것이 효율적인 경우에 사용한다.
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "company_id")
private Company company;JOIN을 사용해 한번의 SQL로 모두 조회하기 때문에 Proxy가 필요없다.
왜? 매번 다같이 조회해서 프록시로 둬봤자 의미없음
‼️ 즉시 로딩 주의점
- 즉시 로딩을 적용하면 예상하지 못한 SQL이 발생한다
- 즉시 로딩은 JPQL에서 N+1 문제를 일으킨다
- 즉시 로딩은 생각보다 강제적이라서 엔티티가 조회될 때 연관된 객체도 무조건 즉시 로딩됨.
-> JPA가 알아서 자동 JOIN 쿼리로 함께 불러오려고 한다.
- 즉시 로딩은 생각보다 강제적이라서 엔티티가 조회될 때 연관된 객체도 무조건 즉시 로딩됨.
- jPQL에서
fetch join과 충돌할 수 있다
⚠️ N+1 문제
예시)
List<Tutor> tutorList = em.createQuery("select t from Tutor t", Tutor.class)
.getResultList();
for (Tutor tutor : tutorList) {
System.out.println(tutor.getSubjects().size());
}<실제 발생하는 쿼리>
1. 먼저 Tutor 리스트를 가져오는 쿼리 1번: SELECT * FROM tutor;
2. 그 다음 for문에서 tutor.getSubjects()에 접근할 때마다, 각 튜터마다 subjects를 조회하기 위해 쿼리가 1번씩 더 실행
SELECT * FROM subject WHERE tutor_id = 1;
SELECT * FROM subject WHERE tutor_id = 2;
SELECT * FROM subject WHERE tutor_id = 3;
...
예를 들어 Tutor가 10명이라면,
1번: Tutor 목록을 불러오는 쿼리
10번: 각 Tutor의 Subject 리스트를 가져오는 쿼리
👉 총 11개의 쿼리가 실행됨 = N+1 문제
해결법
- 모든 연관관계를 LAZY로 설정한다.
@ManyToOne,@OneToOne은 기본이 즉시 로딩 -> LAZY로 설정@OneToOne,@ManyToMany는 기본이 지연 로딩
- JPQL
fetch join: Rumtime에 원하는 Entity를 함께 조회할 수 있다.(대부분 사용) @EntityGraph: 연관된 엔티티를 즉시 로딩(Fetch Join) 하도록 지정하는 어노테이션. JPQL 없이도 N+1 문제를 해결할 수 있음.@BatchSize: 지연 로딩(LAZY) 을 유지하면서도 연관된 엔티티들을 일괄 로딩(batch fetch) 하도록 지정. 여러 SELECT를 한 번에 처리함.Native Query
정말 "무조건 매번 함께 조회해야 하는 관계"라면 괜찮지만,
대부분은 상황에 따라 다르므로 지연 로딩(LAZY) 으로 설정해놓고
fetch join으로 필요한 시점에 가져오는 방식이 더 안정적이고 효율적임.
그워어어억 다와간다....
너무 자세하게 쓰려고하는거같음.. 맞음;;; 모르는 내용이니깐!!!!!!!!!!!!!!!!!!!
🔗 Cascade
영속성 전이(Cascade)란 JPA에서 특정 엔티티를 저장, 삭제 등의 작업을 할 때 연관된 엔티티에도 동일한 작업을 자동으로 적용하도록 설정하는 기능이다.
ㅇㅇ db에서 설정좀 해봣다.. 이건그냥 강의자료 요약만해야지
주요 옵션:
CascadeType.ALL: 모든 작업에 대해 전이됨 (persist + remove + merge + refresh + detach)CascadeType.PERSIST: 부모 저장 시 자식도 저장CascadeType.REMOVE: 부모 삭제 시 자식도 삭제
나머진 잘 안씀
@Entity
@Table(name = "category")
public class Category {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "category", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Product> productList = new ArrayList<>();즉, 연관된 엔티티를 함께 관리하고 싶을 때 사용하면 좋다..
고아객체 ( & orphanRemoval 속성)
말이너무 심하네
부모 엔티티와 연관관계가 끊어진 자식 엔티티(=고아 객체) => 없애줘야겠지
orphanRemoval = true사용 해서 자동으로 삭제해줄 수 있음.
(기본 값 : false)‼️ 주의점
1. 참조하는 곳이 하나인 경우에만 사용한다.
- 단일 Entity에 완전히 종속적인 경우 생명주기가 같다면 사용한다.
2.@OneToOne,@OneToMany만 사용이 가능하다.
3. 부모 Entity를 제거하면 자식 Entity는 고아 객체가 된다.
4.CascadeType.REMOVE와 비슷하게 동작한다.
CascadeType.ALL과 orphanRemoval=true 를 함께 사용하는 경우 부모 Entity를 통해서 자식 Entity의 생명주기를 관리할 수 있다. 도메인 주도개발(Domain Driven Design =DDD)에 주로 사용한다.(자식 Entity는 별도의 Repository Layer가 없어도 된다.)
드디어..마지막..
📢 Transaction 전파
하나의 트랜잭션이 다른 트랜잭션 내에서 어떻게 동작할지를 결정하는 규칙으로 여러 개의 트랜잭션이 포함된 시스템에서 특정 작업이 다른 작업에 어떻게 영향을 미칠지를 정의한다.
<사용법>
@Transactional(propagation = Propagation.전파 종류)
public void 함수() {
//로직
}
❓ propagation
JPA에서 Transaction 시작과 끝은 각 메서드의 시작과 끝이다. 하지만 현재있는 트랜젝션과 다른 클래스의 메서드 트랜젝션간의 처리가 어떻게 진행될까? 그 부분의 교통정리를 하는 부분이 propagation이다.
트랜잭션 전파 종류
REQUIRED(Default)
- 기존 트랜잭션이 있다면 기존 트랜잭션을 사용한다.
- 기존 트랜잭션이 없다면 트랜잭션을 새로 생성한다.REQUIRES_NEW
- 항상 새로운 트랜잭션을 시작하고, 기존의 트랜잭션은 보류한다.
- 두 트랜잭션은 독립적으로 동작한다.SUPPORTS
- 기존 트랜잭션이 있으면 해당 트랜잭션을 사용한다.
- 기존 트랜잭션이 없으면 트랜잭션 없이 실행한다.NOT_SUPPORTED
- 기존 트랜잭션이 있어도 트랜잭션을 중단하고 트랜잭션 없이 실행된다.MANDATORY
- 기존 트랜잭션이 반드시 있어야한다.
- 트랜잭션이 없으면 실행하지 않고 예외를 발생시킨다.NEVER
- 트랜잭션 없이 실행되어야 한다.
- 트랜잭션이 있으면 예외를 발생시킨다.NESTED
- 현재 트랜잭션 내에서 중첩 트랜잭션을 생성한다.
- 중첩 트랜잭션은 독립적으로 롤백할 수 있다.
- 기존 트랜잭션이 Commit되면 중첩 트랜잭션도 Commit 된다.
