
숙련수업에서 들었던 객체지향 4가지 특징련수업에서 들었던거 정리하고
스프링 숙련강의에서 다시 객체지향 언급이 나와서 그것도 같이 정리할까 싶다.
의존성
객체 지향에서 빼놓을 수 없는 단어다...
강의를 들으면서 생각하는 건데 결국엔 객체지향적인 프로그래밍은 각 객체가 확실한 자신의 일을 하면서 다른 객체와 협력을 어떻게 하느냐를 풀어나가는 과정인 것 같다.
여기서 중요한 점은 결합도를 낮추는 것이 중요하다는 점이다.
보통 이걸 결합도라고 많이 얘기하면서
뭐시기 순차적 결합, 기능적 결합 ,우연적 결합... 이런거 정처기 딸 때 외웠던 기억이 있다.
객체 지향의 특징으로 나오는
1️⃣추상화 2️⃣캡슐화 3️⃣상속 4️⃣다형성 전부 결합도를 낮추면서 각 객체가 자신의 일만 확실하게 하기위해서 나온 특징이라 생각한다.
여기저기서 다 볼수있는 특징들의 정의같은건 굳이 정리할 필요가 없는 것 같다.
객체지향 설계를 하면서 큰 그림을 그릴 수 있어야 하는듯
📌 결합도가 그렇게 중요한건가?
결합도는 다른 객체와 얼마나 끈끈하게 연결되어있나, 얼마나 의지하나 를 나타내는 것이다.
만약에 객체들 서로서로가 아주 긴밀하게 연결되어있다고 생각해보자
그럼 결합도가 높을것이다 -> 결합도가 높으니 의존성도 높겠지
-> 의존성이 높다는 뜻은 한쪽이 변경되면 다른 연결된 쪽도 모두 변경해줘야 한다
-> 유지보수에 안좋다.
소프트 웨어 공학을 배우면서 궁극적인 목표로 달달 외우던 것이있다 ㅋㅋ
소프트웨어 공학은 주어진 시간 내에서 모든 요구사항을 만족하는 서비스를 최소의 비용으로 설계/생산/유지보수 하는 것 이라는거슬. . . . .
완전 100프로는 안맞지만 키워드는 똑같다.
시간 잘맞추고, 요구사항 다들어주고, 돈은 적게 하기
유지보수가 생명주기에서 가장 돈이 많이 드는 곳이니 주의해야겠지??
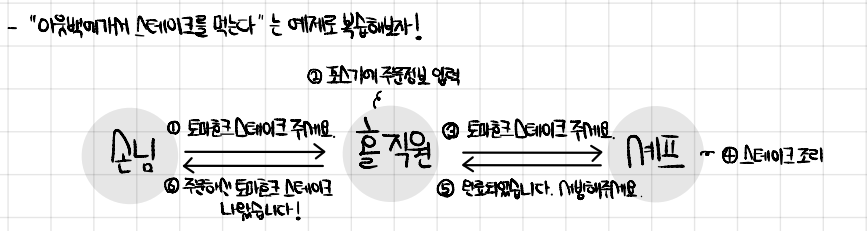
강의에서 나왔던 예제다.
여기서 손님, 홀직원, 셰프는 모두 객체고 서로서로 하는 일에 관심이 없다
요청만 주고 받고, 각자 뭘 어떻게 하는지 알빠? 나는 원하는 것만 받으면 돼 !!
만 하면 되는것이다.
의존성이 뭔진 알겠는데 코드로 무슨뜻이지?
의존성은 내(객체)가 다른 애(객체)를 알고있다
public class A {
private B b = new B();
public void smapleMethod(){
b.method();
}
}
이런식으로 A라는 객체가 B를 직접 불러서 B가 가지고있는 함수를 알고 있고 직접 실행하고 있다.
이걸 "A가 B를 의존하고 있다" 라고 함!!
근데 또 B가 다른C를 의존하고있을수 도 잇고, C가 D를 의존할수도있고... 이런식으로 꼬리에 꼬리를 물게 되는 형태가 있을 것이다.
여기서 제일 최종형인 D가 잇는데 얘의 함수가 바뀐다고 생각해보자
그럼 D->C->B->A 이런식으로 변경이 전파될 것이다.
이 변경을 전파하는 것을 최소화 하는 것이 중요함
=>‼️이게 객체지향 원리의 근본적인 Why?를 제공한다
변경 전파를 최소화 하려면 어떻게 해야 하는지 핵심은 캡슐화다
❤️캡슐화
클래스 안에 서로 연관성 있는 속성과 행위를 묶고, 실제 구현 내용의 일부를 감추어 은닉
이 은닉이라는 단어보다 무엇을?왜?? 은닉하는 지 초점을 맞춰보자
예시
위에서 나온 레스토랑 예시가 있다.
손님은 Client이라고 보면 홀 직원은 Server가 되겠고, 홀 직원이 Client면 요리사가 Server가 되겠지??
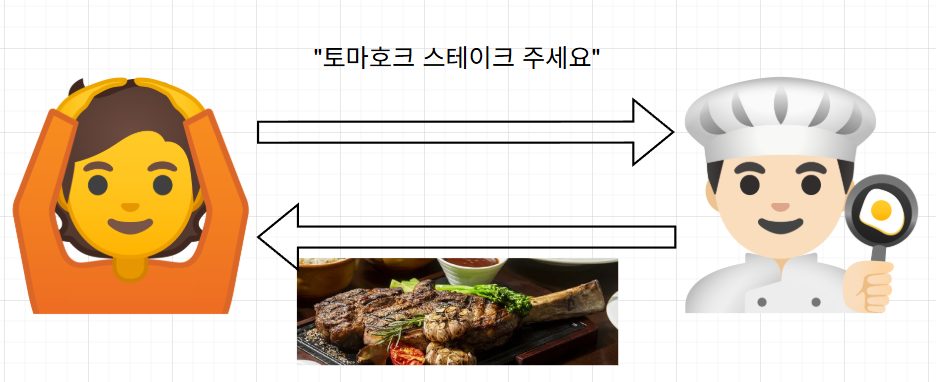

손님은 "토마호크 스테이크 주세요" 까지만 실행한다.
뭐 "고기는 n분만 구워주시고 소스는 이거 쓰시고 칼집은 이런 모양으로 썰어서 접시는 요런 모양으로 .." 안하잖음.
스테이크가 어떻게 만들어지는지 알 바가 없고, 손님 입장에서는 알 필요도 없다.
그저 "토마호크 스테이크 주세요"를 실행하면 "토마호크 스테이크"가 나온다.
이처럼 클라이언트 입장에서는 무엇이 나올지에 초점을 맞추지 어떻게 나올지는 신경안쓴다.
왜냐? 요리사는 전문가고 그걸 알고있고 확실하게 주문한 것에 맞는 결과물이 나올 것을 신뢰하기 때문이겠지
따라서, Client 객체가 추상적인 것만 의존하도록해야 한다는 것이 캡슐화의 핵심이다.
📌구체적인 것 vs 추상적인 것
이 단어가 참 헷갈렸는데 강의에서 정리 해주신 것이 도움이 많이 됐다.
<구체적인 것>
변경될 가능성이 높은 것.
메소드가 어떻게 동작하는 지에 대한 How가 대표적인 구체적인 것이다.
낮은 수준이라고 부르기도 한다.<추상적인 것>
변경될 가능성이 낮은 것.
메소드 이름, 파라미터, 반환 값 등 What에 대한 것이 대표적인 추상적인 것이다.
높은 수준이라고 부르기도 한다.이 구체/추상적인 것은 상대적인 것이고 상황에 따라서 다르게 판단될 수 있음!
이런 캡슐화를 코드에서는 1️⃣자주 변경될 것/ 안될 것 구분과 2️⃣구체적인 것을 늦게 결정하고
3️⃣최종적으로 호출 하는 쪽의 코드를 먼저 작성하는 방법으로
어떤 것이 추상 적인 것일 지 결정할 수 있다.
1️⃣3️⃣에서 생각해볼 수 있는 것이 인터페이스 구조다
인터페이스는 메소드의 형태를 먼저 만들어 놓는 편이고
implements와 interface(Service)를 분리하기 때문에 클라이언트 입장에서 인터페이스에 적혀있는
메소드만 알면된다. (메소드 내부구조 알 필요 ❌❌❌❌❌)
⚠️ 객체 자체가 다른 객체로 대체/확정되는 변경도 있다!!!!
변경에는 특정 객체의 구체적인 코드가 일부 변경되는 경우도 있지만 객체 자체가 다른 객체로 바뀌는 경우도 있다.
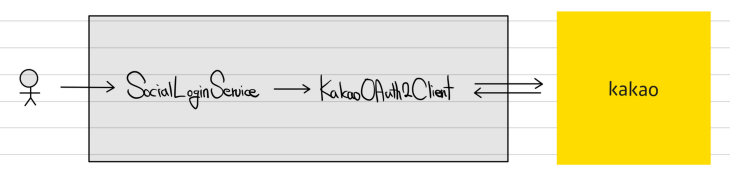
예시로 주신건데 "소셜 로그인 인터페이스"를 구현한 "카카오 로그인"이 나중에는 네이버나 구글 객체로 바뀔 수 도 있다.
그런데 이런 경우는
"소셜 로그인 인터페이스"는 "카카오 로그인"가 어떻게 카카오랑 대화하는지 모름!!! => 이미 캡슐화가 되어있다.
이는 "카카오 로그인" 객체자체가 다른 객체로 변경/대체/확장 될 수 있다는 것으로 보겠다는 것이다.
정리를 하자면
Client 쪽에서는 호출하는 객체의 내부를 모를수록 좋다
-> "무엇을 제공"만 있다 - Interface
-> "무엇을 제공" + "추가 로직" - abstract
레포지토리나 코드 내용보다는 "client가 호출하는 대상을 몰라야 한다"
서비스 제공 쪽은 호출하는 곳에 자신을 들키면 안된다.
추상화 타입을 만드는 것은 변경가능한 것에 대한 범위를 객체자체로 넓히겠다는 것이다.
그래서 더 높은 수준의 추상화라는 타이틀을 사용했다.

캡슐화-> 추상화를 정리하면서 SOLID 중에 OCP와 DIP 원칙도 지킬 수 있다.



이걸 다시 말로 풀어야하는데 천천히하겠다....
