디렉토리의 저부분에 클래스 추가를 쉽게 할 수 있따.
완전 짱이다.
System.out.print ~~~를 자동으로 적어준다!!!
자바의 큰 특징 : 플랫폼 독립성 (Write Once, run anywhere!)
JDK (Java Development Kit) ← Java 개발에 필요한 모든 것 포함
├── JRE (Java Runtime Environment) ← Java 실행 환경
│ ├── JVM (Java Virtual Machine) ← 바이트코드 실행
│ ├── Java 라이브러리 (rt.jar 등) ← 필수 API 제공 (java.lang, java.util 등)
│ ├── 클래스 로더 (Class Loader) ← .class 파일 로드
│
├── Javac (Java Compiler) ← .java → .class 변환
├── 기타 개발 도구 (디버거, Javadoc 생성기, JAR 도구 등)
Javac(Java Compiler)- 자바 컴파일러JVM(Java Virtual Machine)- 자바 가상 머신
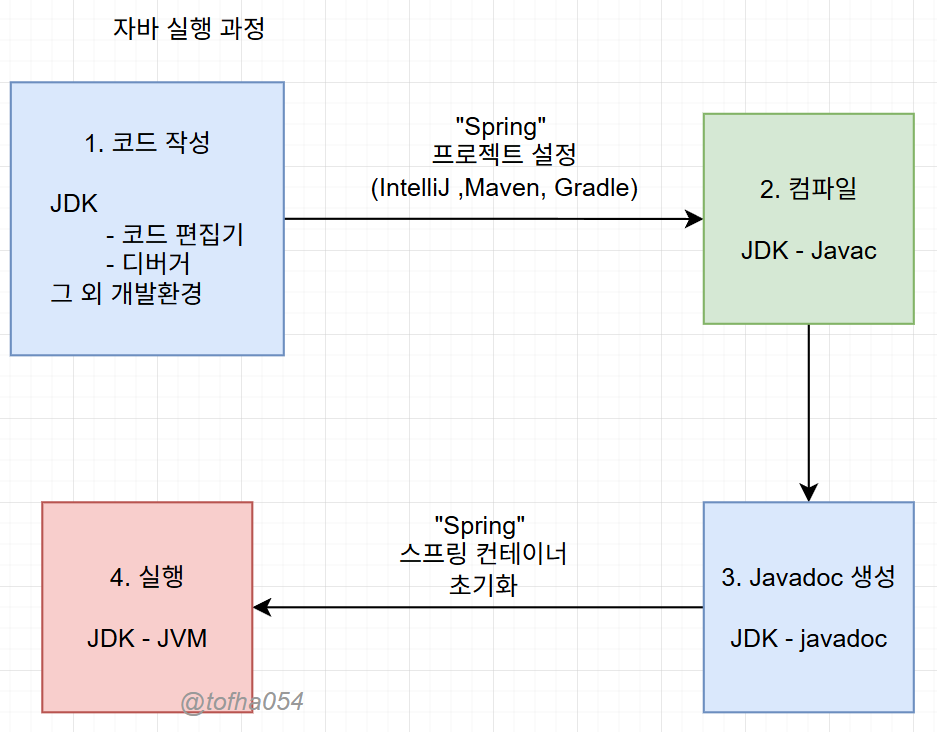
위는 내가 찾아본 것 바탕으로 그림한번 그려봤다
자바가 스프링안에서 굴러갈때 어떤 순서로되는지 JDK의 무엇이 어디서 사용되는지 궁금했었다.
자바 패키지 파일
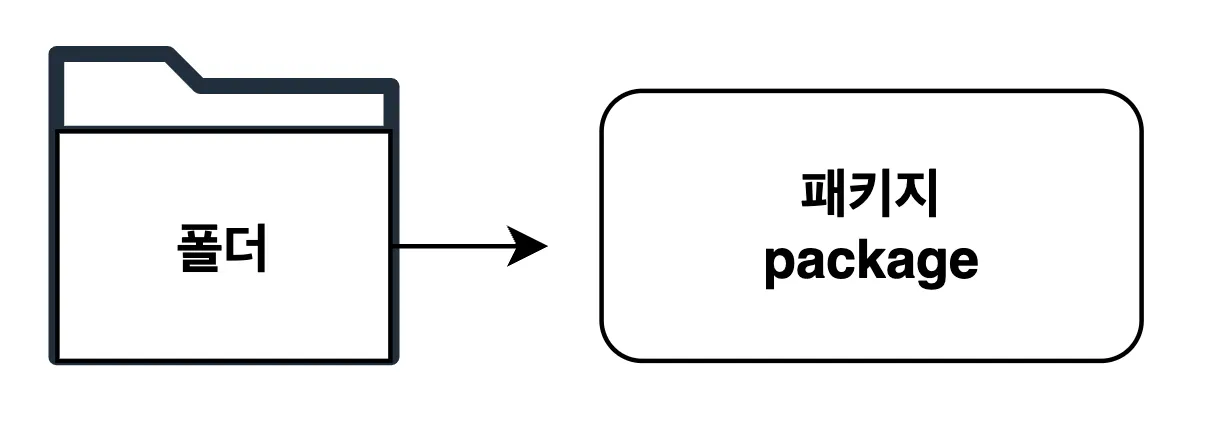
소문자로 점(.)을 이용한 계층 구조
- 자바 패키지 이름은 일반적으로 소문자를 사용하며, 계층 구조를 표현하기 위해
.을 사용.- 예:
com.example.myapp
- 예:
- ❌
CamelCase(대문자로 시작)나snake_case(언더스코어 사용),kebab-case(하이픈 사용)는 자바 패키지 명명 규칙에 맞지 않다.
다른 패키지에 있는 함수/클래스 선언시
import 패키지명.클래스명;
1. ❌ 패키지명 내 모든 클래스를 import 하므로 클래스명 만 사용할 수는 없습니다. 필요하지 않은 클래스까지 import 가 되기 때문이다.
2. ❌패키지 구조는 패키지명.클래스명; 형태로 접근해야하며 Main 은 패키지명이 아니다.
3. ✅ 특정 클래스를 명확하게 import 하는 방식이다.
4. ❌import Car 패키지명이 없으면 기본 패키지에서 찾으려고 하지만 클래스명 클래스는 패키지명 위치하고 있기 때문에 클래스명을 찾을 수 없다.
연산자
전위 연산( ++i ) VS 후위 연산( i++ )
증감 연산자는 변수 앞(++i)에 위치하는지 뒤(i++)에 위치하는 지에 따라 실행 순서가 달라짐
전위 연산(++i)
연산 후 값이 사용된다.
int a = 5;
System.out.println("++a: " + (++a)); // 6 (먼저 증가 후 출력)
System.out.println("현재 a 값: " + a); // 6
후위연산(i++)
값이 사용된 후 연산된다.
int b = 5;
System.out.println("b++: " + (b++)); // 5 (출력 후 증가)
System.out.println("현재 b 값: " + b); // 6
2차원 배열(Two-Dimensional Array)
boolean[][] board = {
{true, false}, // 0행의 0열, 0행의 1열,
{false, true} // 1행의 0열, 1행의 1열
};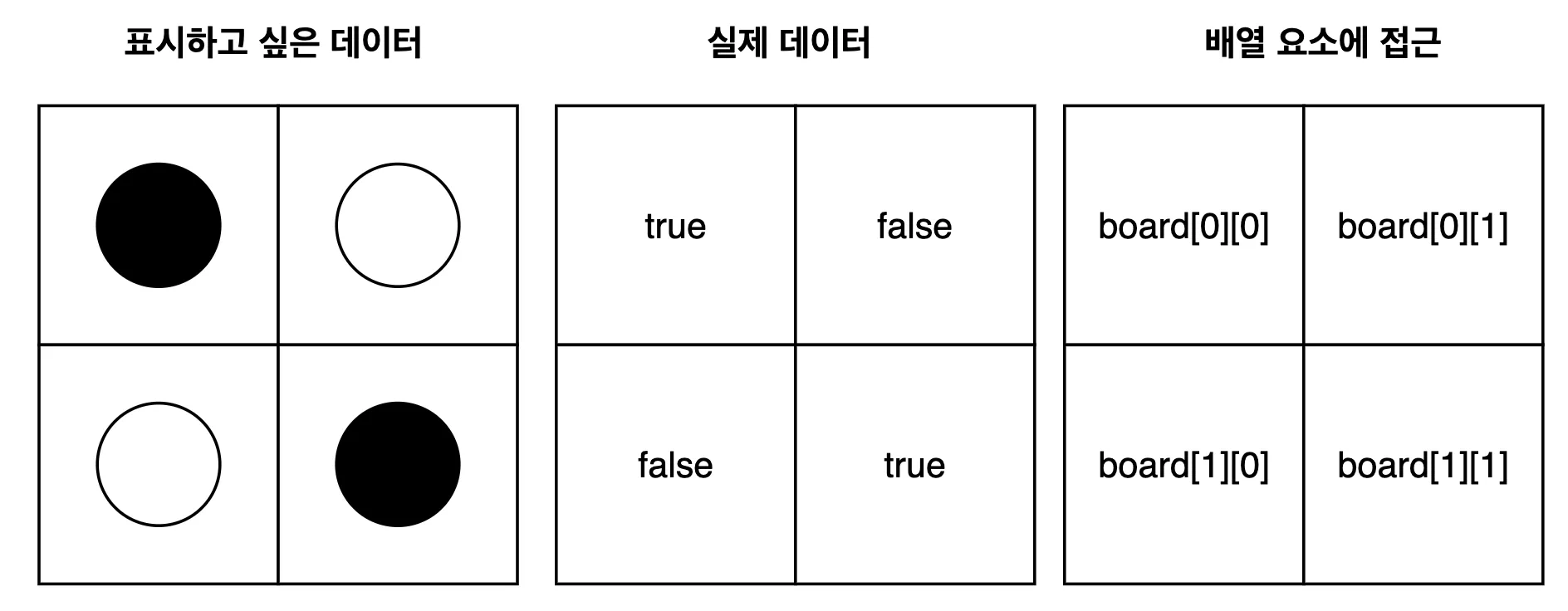
System.out.println(board[0][0]); // true 까만돌
System.out.println(board[0][1]); // false 흰돌
System.out.println(board[1][0]); // true 까만돌
System.out.println(board[1][1]); // false 흰돌
Git 2차 특강

1. 브랜치 활용하기
수정은 하고 싶은데, 원래 파일은 그대로 놔두려고 할 때 사용함.
그 "복사본"의 개념이 깃에서는 "브랜치"라고 한다.
브랜치 만드는 명령어
git branch 브랜치이름
생성하고 터미널에서 아무런 반응이 없는 것 처럼보이는 것이 정상적으로 먹혔다는 뜻이다.
브랜치 목록보는 명령어
git branch
브랜치 이동 명령어
git switch 브랜치이름<- 새롭게 나온 명령어
git checkout 브랜치이름
두 명령어 같은 기능을 하기 때문에 하고싶은거 쓰자. 근데 switch가 최근에 나왓음. checkout이 제공하는 옵션이 훨씬 더 많음
브랜치 생성 & 이동 한꺼번에 하는 명령어
git switch -c 브랜치이름
git checkout -b '브랜치 이름
브랜치 삭제
git branch -d 브랜치이름
✅ 브랜치 이동하면 브랜치에서 작성 했던 것이 없어짐 (복사본 개념)
✅ 브랜치가 다르다 = 서로 다른 파일이다
브랜치 합치기 (merge - 머지)
준비 : 가져올 브랜치로 이동git switch 최종브랜치이름
git merge 수정된내용브랜치
예를 들어서 A 브랜치가있고 main 브랜치가있는데, A브랜치에서 코드 작성을 하고 이 작성한 내용을 main브랜치로 가져오기 위해서 사용함
📌 왜 병합이 필요할까?
어떤 서비스이든 최종적으로 코드가 완성되어잇는 최종 브랜치가 필요해서
각각의 기능을 혼자하는 것이 아니라 여러사람이 협업하기 때문에 기능별로 브랜치를 나눠서
최종본의 역할로 main(최종) 브랜치가 필요하다
📌 Clone 과 Fork의 차이점
다른 레포지토리에 복사하고자 할때 유용하게 사용가능하다.
만약에 Fork해온 레포지토리가 막혀버릴때도 Fork해온 것들을 사용할 수 있다.
.
2. Pull Request 활용하기 (PR라고 많이 쓴다)
깃 merge는 사실 잘 안쓴다.
실제로 깃허브를 협업에서 사용할 땐 머지를 잘 안쓴다.
터미널 말고 github에서 합치자
📌 깃 허브에서 합치는 이유
- 코드리뷰가 가능하다. (합쳐지기 전에 중간에 협업자끼리 병합 내용을 확인할 수 있다.)
Pull = fetch & merge
Request = 요청 (내 코드를 최종 브랜치에 합칠 것을 요청드립니다!!)
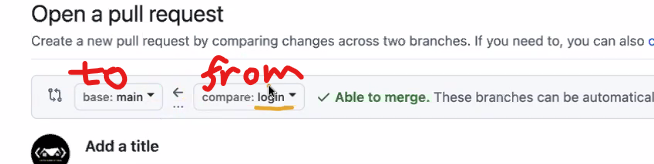
login 브랜치의 내용을 main에다가 가져올거다.
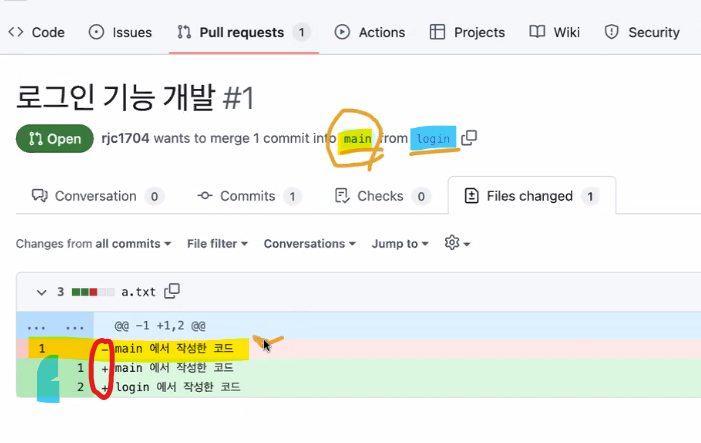
File changed챕터에서 바뀌는 내용을 볼 수 있다.
줄마다 +,- 자리에 마우스 hover를 하면 + 버튼이 생기는데, 코드리뷰나 코멘트를 달 수 있다.
Conversation 탭에서 Merge 버튼을 누르면 Merge 허락이 가능하다.
협업자들이 확인을 하고 confirm을 눌러줘야하는데, confirm 규칙을 정할 수 있다.
✅ 온라인 저장소 깃허브와 내 컴퓨터는 실시간 연동이 안된다.
✅ 깃 명령어를 쓰면 그때만 잠깐 연결되는것임
✅ 기능 브랜치는 기능 끝나고 삭제해주자 (일회용임)
📌 무엇인가 기능 개발을 해야한다면 브랜치를 따서 하자!!!
.
3. 협업 실전 가이드
Main 브랜치는 배포용(실제 사용자들이 사용하는 서비스)으로만 사용한다.
그렇기 때문에 Main브랜치는 민감하게 사용되어야 한다.
merge가 main 브랜치에서 사용되면 안됨!!!!
📌완벽하게 기능 개발해야 merge 가능하다.
- 만드는데 오래걸림
- QA도 잘 이루어져야한다.
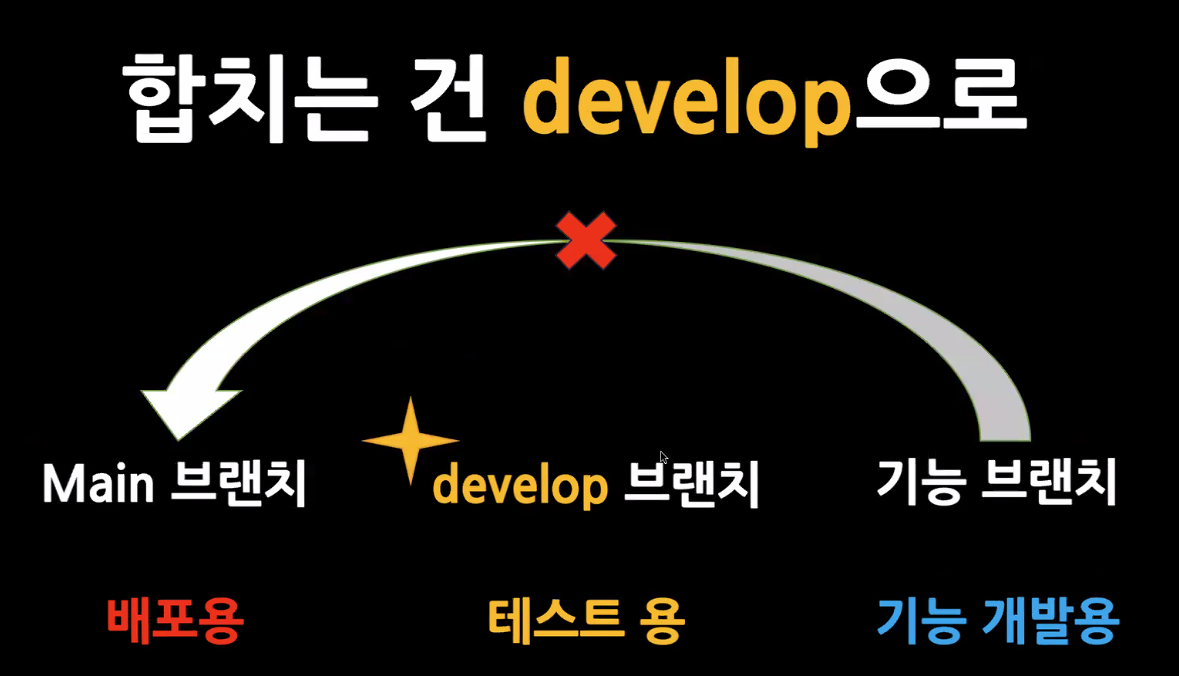
develop 브랜치(dev 브랜치)를 두어서 여기에다가 merge하고 테스트를 해야한다.
dev 브랜치에서 테스트와 어쩌고를 다 끝내고 main에 merge를 한다.
📌그냥 합치면 위험하다.
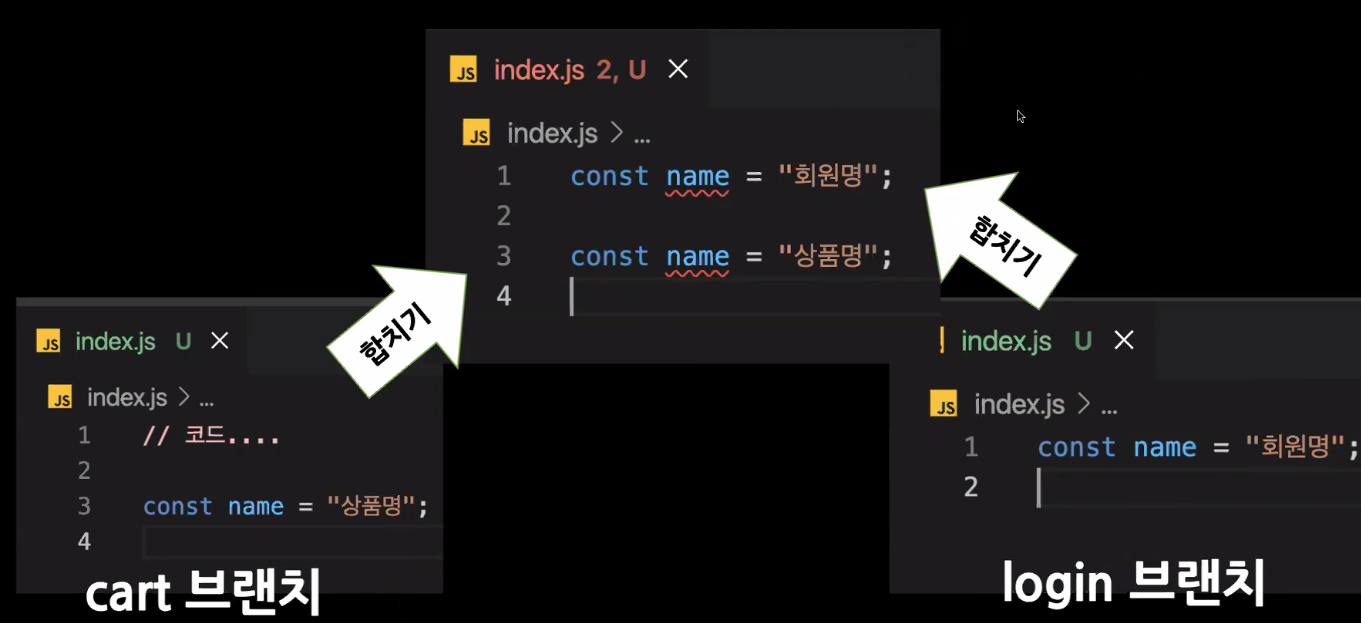
변수명이 겹치거나 하는 치명적인 실수를 깃허브에 올리면 안된다.
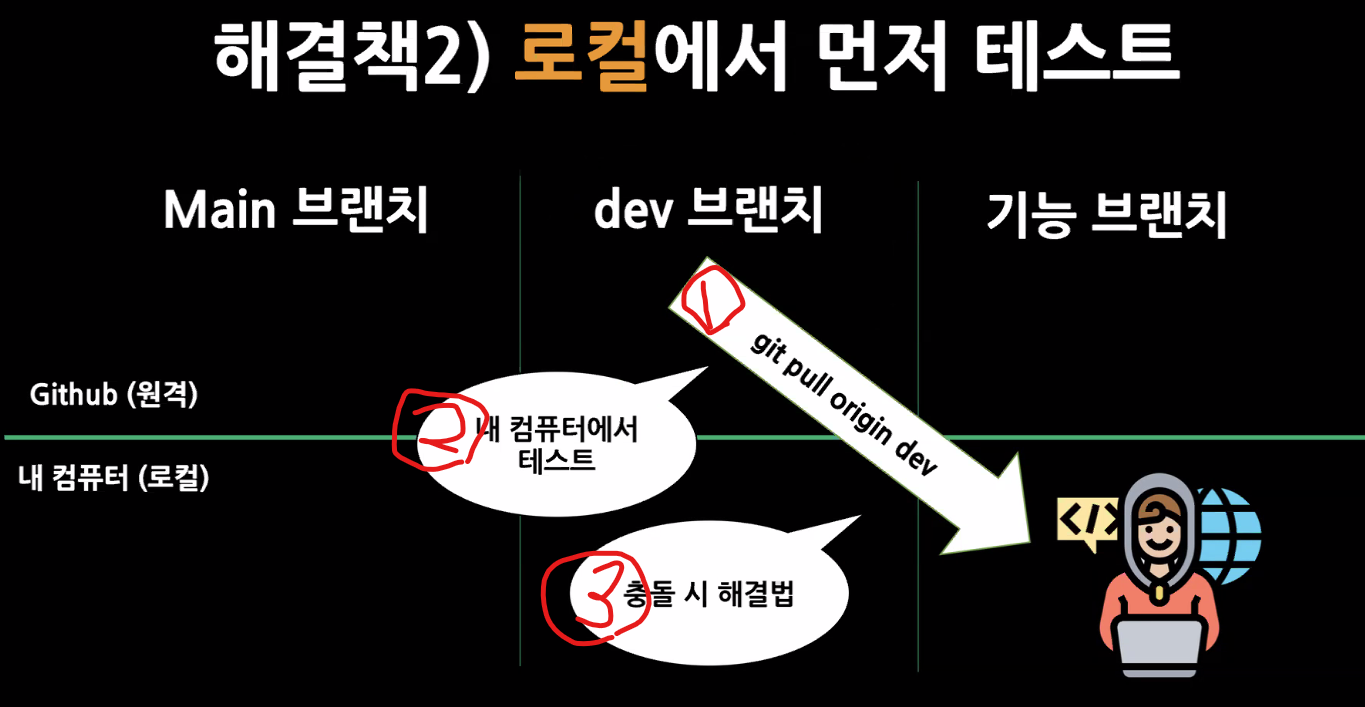
먼저 dev에 있는 내용을 받아와서 내가 작성한 코드가 실제로 올라갔을 때 오류가 없는 지 검증하는 절차가 필요하다.
1. 초기세팅
팀장
- 폴더 생성
- 초기 코드 작성
- git init, add, commit
- main 브랜치, dev 브랜치 생성
- git switch -c dev
- git push origin dev (깃허브반영)
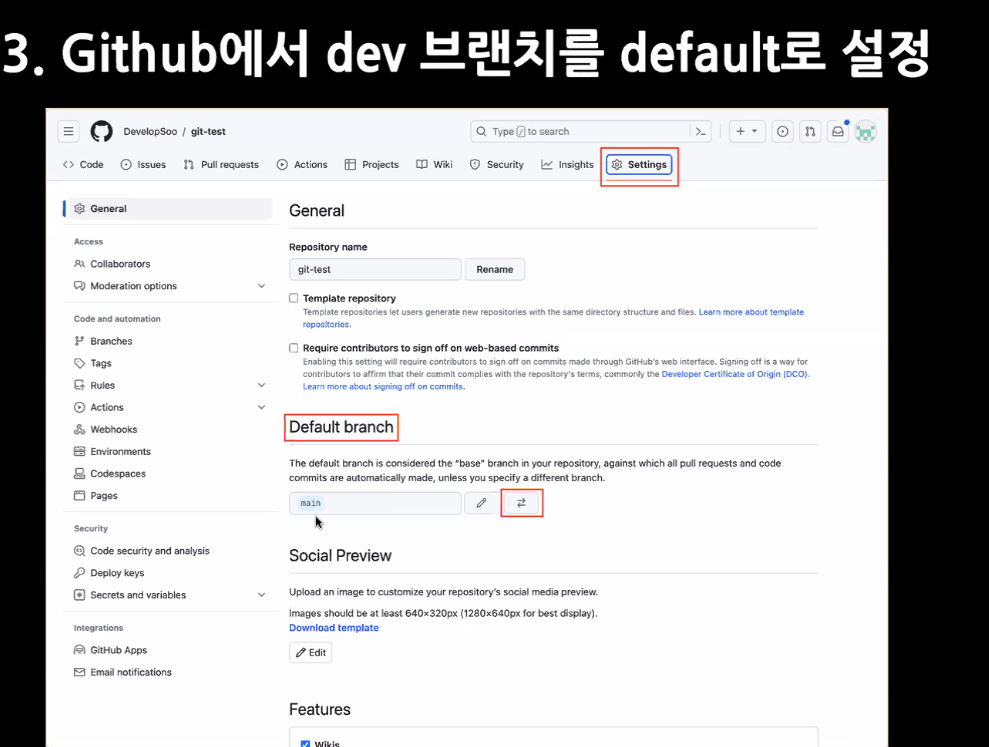
디폴트를 main에서 dev으로 바꿔줘야함
- 팀원들을 collaborator로 등록
팀원
- git clone 하기
- github의 링크 받아와서
git clone https://깃허브.주소 ^.- 마지막에 띄워쓰기 + . 필수!!!
git clone -b dev https://깃허브.주소 ^.- 만약 default 브랜치가 dev가 아니라면 사용할 명령어
2. 기능 개발 시작
- 기능 별 브랜치 꼭 만들어주기 >>>>>>>
git switch -c feat(ure)/기능이름 - 개발 후에는
git push origin feat(ure)/기능이름<<<<<<<< 으로 해야 한다.- dev 브랜치는 PR과정을 거쳐서 merge되어야 하기 떄문
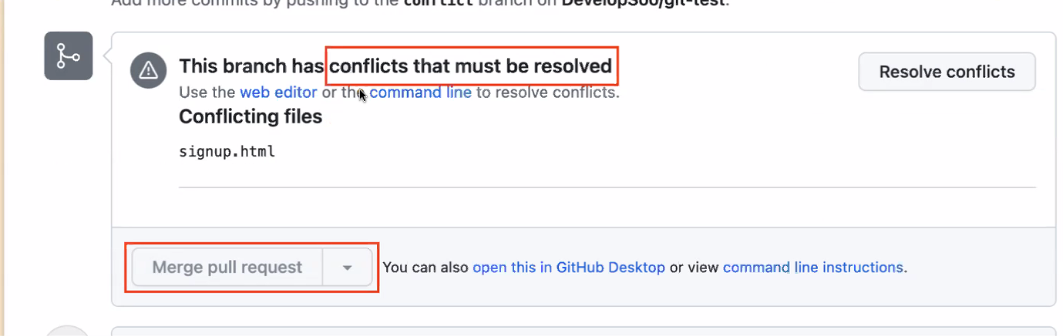
충돌 발생시 merge안됨!!!! ( 충돌 해결도 로컬에서 하면 된다. )
- 📌PR에서 오른쪽 Assigner 에 자기 등록 하기
- comment의 종류
- Comment(진짜 조언 그자체)
- Approve(만약에 PR merge에 조건이 생겼을 때 merge수락 하는 용도)
- Request changes (강제성이 생김) - 이건 절대 병합하면 안돼요
- dev에 올리기 전에 로컬에서 오류 검출을 해야함
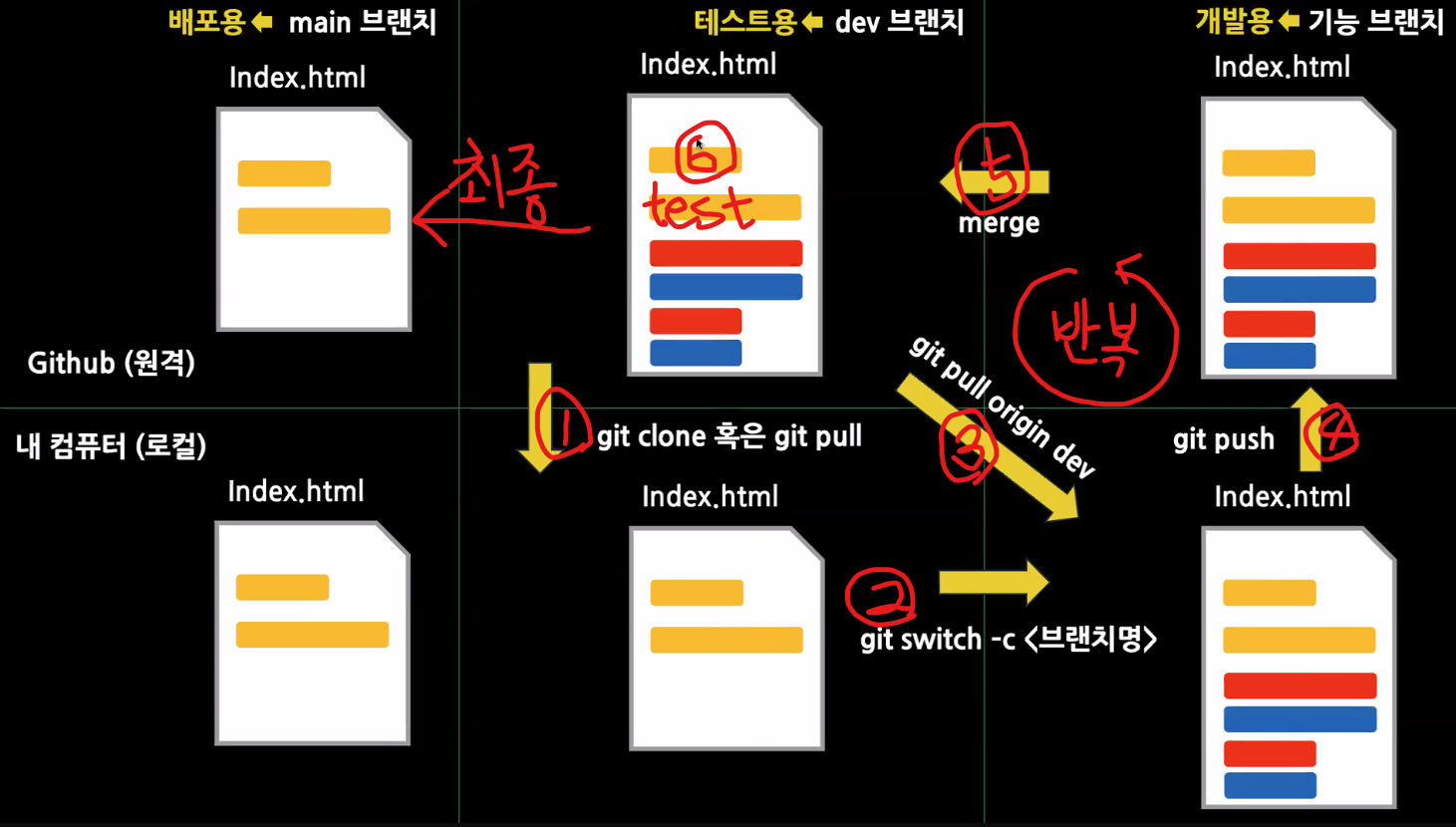
3->4->5가 반복됨
✅협업할 때 organization을 만들면 배포 사이트를 사용할 떄 유료버전으로 사용될 수 있다..! (기능 사용 비추)
HashSet+TreeSet과 List 비교
이 내용이 나오게 된 경위는 내가 백준으로 코테를 풀다가 메모리 제한 조건의 벽에 부딪혀서 ㅋㅋㅋㅋㅋ.. 결국 해시맵을 찾아보게 됐다.
contains나 key를 보는 것이 결국엔 맵안의 key 모두를 하나씩 보는거라 n번 도는것이 아닌가?
라고 했는데 컴퓨터 입장에서는 아예 관점이 다르다.. 근데이게 아직 이해가 안된다
쉬운 비유: "도서관 책 찾기"
📒 List 사용: 서가에서 책 한 권씩 훑어보기 (O(N))
도서관에 책이 줄 세워져 있음 (List)
특정 책을 찾으려면 처음부터 하나씩 넘겨가며 확인해야 함
→ contains() 사용 시 O(N) 시간이 걸림📒 HashSet 사용: 사서에게 바로 물어보기 (O(1))
책 제목을 도서관 전산 시스템(HashSet)에 저장
책이 있는지 한 번에 조회 가능!
→ contains() 사용 시 O(1) (거의 즉시 찾음)📒 TreeSet 사용: 자동 정렬된 책장 (O(log N))
책이 자동으로 제목 순 정렬된 책장에 저장됨
특정 구간을 찾을 때 이진 탐색을 하므로 O(log N)
📌 HashSet 과 TreeSet의 차이점
- Set이란 순서가 없는 집합체이며, 중복을 허용하지 않는다.
- TreeSet은 HashSet과 다르게 그 값이 정렬되어 저장이 되지만, 그렇기 때문에 HashSet보다 속도가 느리다.
HashSet & TreeSet 사용법
선언
HashSet<String> hs = new HashSet<String>();
TreeSet<String> ts = new TreeSet<String>();자주쓰는 함수
hs.add(value)hs.contains(value)
hs.clear()hs.equals(value)hs.isEmpty()
hs.remove(value)hs.size()hs.toArray()
TreeSet도 마찬가지이고, 함수이름 자체들이 리스트랑 다를바가 없다. 그래서 굳이 설명은안함 아는내용이니꽌
말하는것만보면 항상 Hash테이블이 List보다 좋아보이는데 HashSet과 TreeSet이랑 비교했을 때 리스트의 장점이 뭘까??
📌 HashSet & TreeSet과 비교했을 때 List의 장점
- 입력 순서 유지가 필요할 때
- HashSet은 순서를 유지하지 않음
- TreeSet은 자동 정렬됨(apple, banana, cherry)
- 인덱스 기반 접근이 필요할 때
- HashSet은 내부적으로 해시 테이블을 이용하므로 인덱스 개념 없음
- TreeSet은 트리 구조라 특정 원소 찾기 위해 O(log N) 필요
- 중복 데이터를 저장해야 할 때
- HashSet과 TreeSet은 중복을 허용하지 않음
- 중간 삽입/삭제가 자주 발생할 때
- ArrayList: 맨 끝에 추가하는 경우 O(1)
- LinkedList: 중간 삽입/삭제도 O(1)
- HashSet, TreeSet: 추가할 때 중복 검사 + 해싱/정렬 작업이 필요해 더 느릴 수 있음
✅ 결론:
"List는 순서 유지 + 인덱스 조회 + 중복 저장 + 특정 삽입/삭제에 강점이 있음"
∴검색, 중복 제거가 중요하면 HashSet/TreeSet, 그 외 대부분의 경우는 List가 적절함! 🔥
.
.
사실 이 주제에 대해서 나오게 된 이유는 백준 문제때문이다..
1764번문제 푸는데 아무생각 없이 List로 건들였다가 시간초과 엄청나와서 고민했었다.
결국엔 남들이 풀었던걸로 힌트 얻어서 코드 베끼기말고 내가 풀고싶다.
내가 첨에 풀었던 코드
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
String[] input= br.readLine().split(" ");
int n=Integer.parseInt(input[0]);
int m=Integer.parseInt(input[1]);
List<String> listenStr = new ArrayList<>();
String watchStr = "";
List<String> answer = new ArrayList<>();
for(int i = 0 ; i < n; i++){
listenStr.add(br.readLine());
}
for(int i = 0 ; i < m; i++){
watchStr = br.readLine();
if(listenStr.contains(watchStr)){
answer.add(watchStr);
listenStr.remove(watchStr);
}
}
answer.sort(String::compareTo);
bw.write(answer.size() + "\n");
for (String s : answer) {
bw.write(s + "\n");
}
bw.flush();
br.close();
bw.close();
}개선한 코드
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
String[] input= br.readLine().split(" ");
int n=Integer.parseInt(input[0]);
int m=Integer.parseInt(input[1]);
List<String> listenStr = new ArrayList<>();
String watchStr = "";
List<String> answer = new ArrayList<>();
for(int i = 0 ; i < n; i++){
listenStr.add(br.readLine());
}
for(int i = 0 ; i < m; i++){
watchStr = br.readLine();
if(listenStr.contains(watchStr)){
answer.add(watchStr);
listenStr.remove(watchStr);
}
}
answer.sort(String::compareTo);
bw.write(answer.size() + "\n");
for (String s : answer) {
bw.write(s + "\n");
}
bw.flush();
br.close();
bw.close();
}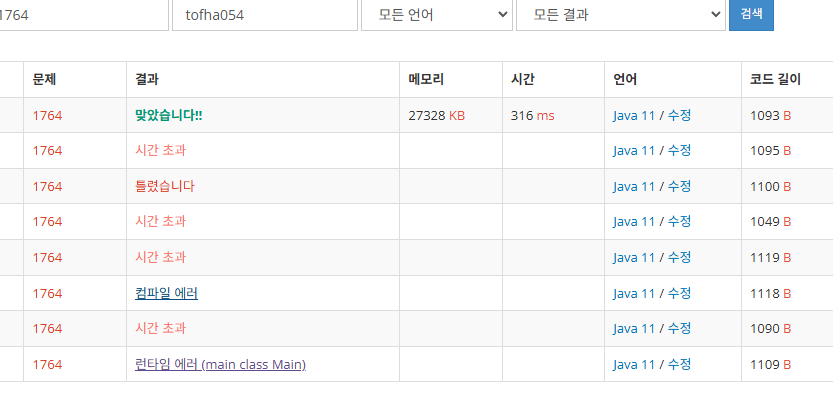
어려운 문제가 아닐텐데도 아직까지 어렵다 ㅜㅜ
