
- 실행 순서
- SELECT
- FROM
- WHERE
- GROUP BY
- HAVING
- ORDER BY
3-1. ORDER BY
1) 정의
- 정렬할 때 작성하는 구문
- 가장 마지막에 작성, 실행 순서도 가장 마지막
2) 표현식
- ORDER BY(컬럼명 혹은 별칭 혹은 컬럼 순번 / 정렬방식(오름차순 ASC, 내림차순DESC) 아무것도 안쓰면 오름차순 / NULLS FIRST 혹은 LAST(NULL을 어디에 작성할것인지)
3-2. GROUP BY
1) 정의
- 그룹함수는 단 한개의 결과값만을 산출 > 여러개의 결과 값 산출을 위해 그룹함수가 적용될 그룹의 기준을 GROUP BY 절에 기술하여 사용
2) 예시
- 같은 값이 여러 개 기록 된 컬럼을 가지고 같은 값들을 하나의 그룹으로 묶음
-- 부서별 급여 합계, 평균, 인원 수 조회 후 부서코드 순 오름차순 정렬
SELECT
DEPT_CODE
, SUM(SALARY)
, ROUND(AVG(SALARY))
, COUNT(*)
FROM EMPLOYEE
GROUP BY DEPY_CODE
ORDER BY 1 DESC NULLS FIRST;- GROUP BY 절에 하나 이상의 그룹을 지정 할 수 있음
SELECT
DEPT_CODE
, JOB_CODE
, SUM(SALARY)
, COUNT(*)
FROM EMPLOYEE
GROUP BY DEPT_CODE, JOB_CODE
ORDER BY 1;- GROUP BY 절에 함수식을 사용할 수 있음
SELECT
DECODE(SUBSTR(EMP_NO,8,1), '1', '남', '여') 성별
, ROUND(AVG(SALARY))
, SUM(SALARY)
, COUNT(*)
FROM EMPLOYEE
GROUP BY SUBSTR(EMP_NO,8,1), '1', '남', '여')
ORDER COUNT(*) DESC- HAVING 절
- 그룹 함수로 구해올 그룹에 대해 조건을 설정할 때 사용
- HAVING 컬럼명 혹은 함수식 비교연산자 비교값
- 집계 함수 : GROUP BY 절에서만 사용하는 함수
- ROLLUP
- 그룹별로 중간 집계 처리를 하는 함수
- D1기준 중간합계, D2기준 중간합계...
- 인자로 전달한 그룹 중 가장 먼저 지정한 그룹별 합계와 총 합계를 구하는 함수
SELECT DEPT_CODE , JOB_CODE , SUM(SALARY) FROM EMPLOYEE GROUP BY ROLLUP(DEPT_CODE, JOB_CODE) ORDER BY 1; - CUBE
- 그룹으로 지정 된 모든 그룹에 대한 집계와 총 합계를 구하는 함수
SELECT DEPT_CODE , JOB_CODE , SUM(SALARY) FROM EMPLOYEE GROUP BY CUBE(DEPT_CODE, JOB_CODE) ORDER BY 1;
- ROLLUP
3-3. GROUPING
- ROLLUP이나 COUBE에 의한 산출물이 인자로 전달 받은 컬럼 집합의 산출물이면 0을 반환하고, 아니면 1을 반환하는 함수
SELECT
NVL(DEPT_CODE, '부서없음')
, JOB_CODE
, SUM(SALARY)
, CASE
WHEN GROUPING(NVL(DEPT_CODE, '부서없음')) = 0 AND GROUPING(JOB_CODE) = 1 THEN '부서별합계'
WHEN GROUPING(NVL(DEPT_CODE, '부서없음')) = 1 AND GROUPING(JOB_CODE) = 0 THEN '직급별합계'
WHEN GROUPING(NVL(DEPT_CODE, '부서없음')) = 0 AND GROUPING(JOB_CODE) = 0 THEN '그룹별합계'
ELSE '총합계'
END 구분
FROM EMPLOYEE
GROUP BY CUBE(NVL(DEPT_CODE, '부서없음'), JOB_CODE)
ORDER BY 4;3-4. 집합 연산(SET OPERATION)
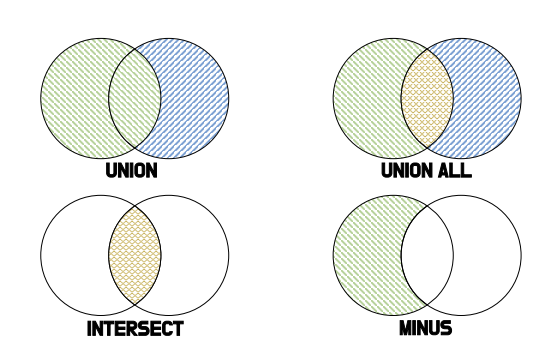
-
UNION
- 중복된 결과가 있으면 한번만 보여줌
- 여러 개의 쿼리 결과를 하나로 합치는 연산자
SELECT EMP_ID , EMP_NAME , DEPT_CODE , SALARY FROM EMPLOYEE WHERE DEPT_CODE = 'D5' UNION SELECT EMP_ID , EMP_NAME , DEPT_CODE , SALARY FROM EMPLOYEE WHERE SALARY > 3000000 ORDER BY 1; -
UNION ALL
- 중복된 결과가 있으면 중복된 만큼 보여줌
- UNION과의 차이는 중복 영역을 모두 포함시킨다는 것
-
INTERSECT
- 여러개의 SELECT한 결과에서 공통 부분만 결과로 추출
- 수학의 교집합과 유사
-
MINUS
- 선행 SELECT 결과에서 후행 SELECT 결과와 겹치는 부분을 제외한 나머지만 추출
3-5. GROUPING SET
- 그룹별로 처리 된 여러개의 SELECT문을 하나로 합칠 때 사용
- SET OPERATION과 결과 동일
SELECT
DEPT_CODE
, JOB_CODE
, MANAGER_ID
, FLOOR(AVG(SALARY))
FROM EMPLOYEE
GROUP BY GROUPING SETS((DEPT_CODE, JOB_CODE, MANAGER_ID)
,(DEPT_CODE, MANAGER_ID)
,(JOB_CODE, MANAGER_ID)
);
DREAM STARTER