
ASCII(American Standard Code for Information Interchange)
ASCII, abbreviated from American Standard Code for Information Interchange, is a character encoding standard for electronic communication. ASCII codes represent text in computers, telecommunications equipment, and other devices.
from wiki: https://en.wikipedia.org/wiki/ASCII
ASCII는 1바이트를 사용하여 문자를 인코딩한 코드다. 이 코드는 검사열(체크섬) 1비트를 제외하고 7비트를 사용하여 문자를 나타낼 수 있는데, 7비트는 128개의 문자를 코드화할 수 있다. 당연히 128은 세계 언어에서 사용되는 문자를 모두 커버하기에는 한계가 있다. 그래서 이 문제를 인식하고 모든 문자를 표현하기 위한 유니코드라는 인코딩 방식이 등장하게 되었다.
유니코드
2바이트에서 4바이트까지 여유 있게 메모리 공간을 차지하며 넓은 범위의 문자를 코드화한다. 장점이 있듯 단점도 존재했는데, 유니코드의 문제점은 1바이트로 표현가능한 영어, 숫자 또한 2바이트 이상의 메모리를 차지하게 된다는 것이다. 그래서 다시 한번 메모리 낭비를 해결하기 위해 가변 길이 문자 인코딩 방식을 생각하게 되었는데, 가장 대표적인 것이 Go로 유명한 롭 파이크와 유닉스 개발자로 유명한 켄 톰슨이 함께 개발한 UTF-8이다.
UTF-8
UTF-8은 유니코드를 다시 한 번 인코딩한다.
| 바이트 수 | 바이트 1 | 바이트 2 | 바이트 3 | 바이트 4 |
|---|---|---|---|---|
| 1 | 0xxxxxxx | |||
| 2 | 110xxxxx | 10xxxxxx | ||
| 3 | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| 4 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
이 표의 이진 포맷은 매우 간단하면서도 직관적이다. 시작 비트를 살펴보면 문자의 전체 바이트를 결정할 수 있다. 원래는 6바이트 까지 확장할 수 있었으나 RFC 3629(인터넷 표준)에서 총 4바이트까지로 제한하여 예약된 공잔을 제외하면 약 100만 자를 표현할 수 있게 되었다.
예시
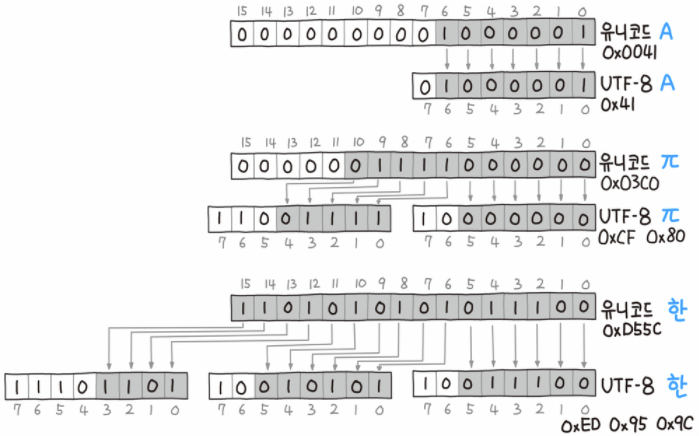
파이썬 알고리즘 인터뷰에서 발췌하였습니다.
3바이트로 표현되는 한글 유니코드 한을 보자. 3바이트 표를 보면 1바이트는 10xxxxxx로 표현되며 xxxxxx에 해당하는 값은 유니코드 우측부터 순차적으로 대입된다. 2바이트도 10xxxxxx로 표현되기 때문에 xxxxxx에는 1바이트에 적용한 유티코드 비트를 제외하고 6비트부터 11비트 까지 대입된다. 3바이트는 1110xxxx로 표현되며 xxxx에는 나머지 12비트부터 15비트까지 대입된다!
모든 한글은 3바이트로 표현이 가능하며 영어는 1바이트로 표현하는 등 가변적으로 바이트를 사용하기 때문에 메모리를 효율적으로 사용할 수 있다.
파이썬은 문자열에 빠르게 접근하는 여러가지 수단을 제공하는데, UTF-8과 같은 가변길이 인코딩 방법은 인덱스를 통해 빠르게 접근하기 어렵다. 따라서 파이썬은 UTF-8을 사용하지 않고 문자열 단위로 다른 고정 길이 인코딩 방식을 적용해 이 문제를 해결하고 있다. 만약 모든 문자열이 ASCII 범위 내에 있다면 Latin-1 인코딩을 사용하고 특수기호 등이 포함되면 USC-4로 4바이트 인코딩을 하는 등 바이트 수를 문자열에 따라 다르게 책정하는 방식이다. 문자열의 문자가 고정 바이트로 표현되기 때문에 문자열 슬라이싱을 포함하여 인덱스에 빠르게 접근할 수 있게 된다.
