컴퓨터 이론
1.[C.A] 컴퓨터 구조 개요

컴퓨터 구조는 아래와 같은 큰 구조로 나뉜다.Software \- Data \- 명령어Hardware \- CPU \- 메모리 \- 보조기억장치 \- I/O 장치Hardware에서 CPU는 아래와 같은 요소로 구성된다.ALURegisterCUHardware는
2.[C.A] 데이터 표현
데이터의 최소 표현단위 : bitbit를 8개 묶어서 byte로 표현하고 byte부터는 1000단위로 KB, MB, GB 등으로 표현한다.word : CPU가 한번에 처리하는 단위이며 현대의 CPU에서는 대부분 32bit 또는 64bit를 채용한다.데이터를 표현할 때는
3.[C.A] 소스코드의 실행과정
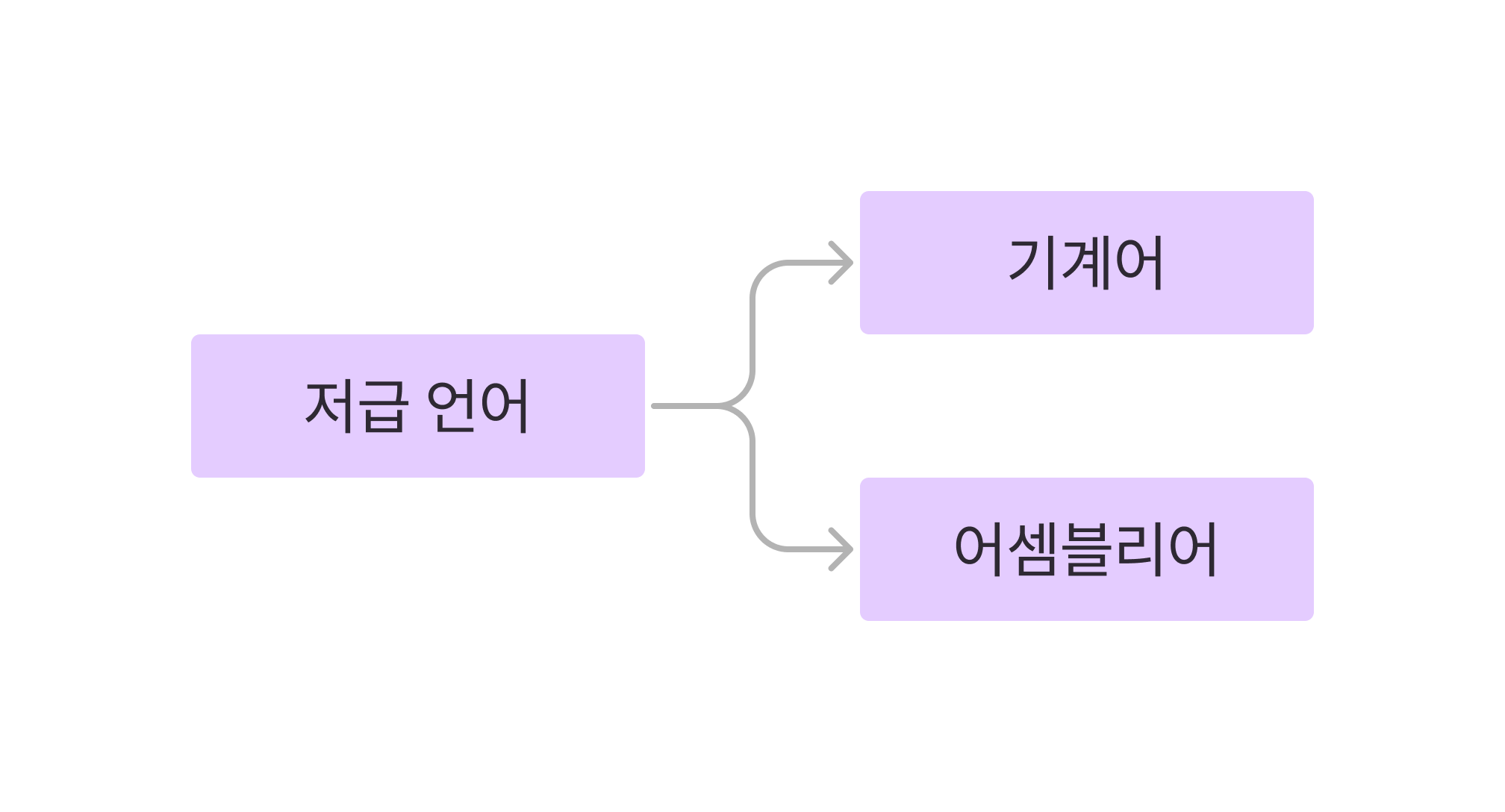
컴퓨터 언어는 고급언어, 저급언어두 종류로 나뉜다.고급언어는 사람이 이해하고 작성하기 쉽게 만들어진 언어이고 컴퓨터가 이해하도록 하기 위해서는 저급언어로 변환하는 과정을 거쳐야 한다.저급언어는 컴퓨터가 직접 이해하고 실행할 수 있는 언어로 기계어와 어셈블리어 2가지로
4.[C.A] 명령어
Operand와 Operation Code로 구성된다.Operation Code는 그 명령어가 수행할 연산을 나타내며 연산자 라고도 하고, Operand는 연산에 사용할 데이터 혹은 그 데이터가 저장된 위치를 나타내며 피연산자 라고도 한다.Operand는 연산에 사용하
5.[C.A] CPU 구성
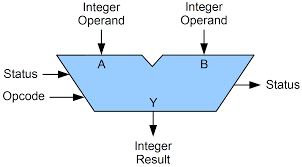
컴퓨터의 하드웨어 중 CPU를 구성하는 요소는 아래와 같다.ALU제어장치RegisterALU는 그림과 같은 흐름을 가진다.\[]ALU는 계산을 처리하는 부품으로 Register를 통해 피연산자를 받아들이고 제어장치를 통해 제어 신호를 받아들여 연산을 수행한 후, 그 결
6.[C.A] Interrupt
Interrupt란 CPU의 작업을 방해하는 신호로 CPU가 작업을 중단해야 할 정도의 중요한 문제 혹은 먼저 처리해야할 다른 작업이 발생했을 때 발생한다.Interrupt는 아래 2종류가 있다.Synchronous interrupt (exception)(동기 인터럽트
7.[C.A] 빠른 CPU 설계
빠른 CPU를 설계하기 위한 방법으로는 아래 3가지 요소를 조절할 수 있다.Clock speedCoreThread컴퓨터 부품은 Clock에 맞춰서 작동한다.즉, 빠른 CPU를 위해서는 clock의 속도를 올리면 CPU를 비롯한 부품들은 그만큼 빠른 박자에 맞춰서 움직일
8.[C.A] 명령어 병렬 처리
CPU가 빠르게 동작하려면 hardware의 동작도 중요하지만 software적인 부분도 중요하다.software에서는 명령어를 효과적으로 처리하기 위해 여러 기법을 사용하는데 이에는 ILP, 명령어 처리 파이프라인, 슈퍼스칼라, 비순차적 명령어 처리 등이 있다.ILP
9.[C.A] CISC RISC
ISA : 명령어 집합, 명령어 집합 구조(Instruction Set Architecture)이 ISA를 기반으로 설계되는 두 종류의 CPU가 CISC, RISK이다.다양하고 강력한 기능의 명령어 집합을 활용하기 때문에 명령어의 형태와 크기가 다양한 가변 길이 명령어
10.[C.A] RAM
RAM에는 실행할 프로그램의 명령어와 데이터가 저장이 된다.여기서 RAM은 전원을 차단하면 저장된 내용이 사라지는데 이를 휘발성 memory라고 한다.반면 전원을 차단해도 내용이 유지되는 저장 장치들을 비휘발성 memory라고 부른다.여기에는 hard disk, SSD
11.[C.A] Cache Memory
CPU는 프로그램을 실행하는 과정에서 memory에 접근해 저장된 데이터를 사용한다.memory에 접근하는 시간은 CPU의 연산 속도보다 당연히 느린데, 접근 시 overhead를 줄이기 위한 저장 장치로 Cache Memory를 사용한다.CPU와 가까울수록 빠른 저장
12.[C.A] 보조 기억 장치
보조 기억장치는 여러 종류와 특징을 가지고 있다.자기적인 방식으로 데이터를 저장한다.HDD는 아래와 같은 구성요소를 가지고 있다.platterplatter는 자기적인 방식으로 데이터를 저장할 수 있도록 자기 물질로 덮여있어 수많은 N극과 S극을 저장한다.이 극성이 0과
13.[C.A] RAID
RAID(Redundant Array of Indeppendent Disks)란 주로 HDD와 SSD를 사용하는 기술로, 데이터의 안정성 혹은 높은 성능을 위해 여러 개의 물리적인 보조기억장치를 하나의 논리적 보조기억장치처럼 사용하는 기술을 말한다.RAID를 구성하는
14.[C.A]I/O 장치
IO장치에는 많은 종류가 있다.이들은 각각 속도, 데이터, 전송 형식을 가지고 있으며 데이터 전송에 대해 규격화를 하기 어렵다라는 특징을 가지고 있다.또한 일반적으로 CPU와 memory에 비해 데이터 전송률이 낮다는 특징도 가지고 있다.위와 같은 특징들 때문에 I/O
15.[C.A] 입출력 방법
CPU와 장치 컨트롤러가 정보를 주고 받는 방법은 3가지가 있다.기본적으로 프로그램 속 명령어로 IO장치를 제어하는 방법.아래 순서로 작동한다.1\. CPU는 device controller의 control register에 쓰기 명령을 보낸다.2\. device co
16.[OS] 운영체제 개요
운영체제 : 시스템의 자원을 관리하기 위한 프로그램운영체제는 사용자 모드와 Kernel 모드 2가지 모드를 가지고 있다.사용자가 직접 자원을 활용하려면 System Call을 사용해서 Kernel 모드로 변경하여 OS를 통해 하드웨어에 접근하도록 한다.System Ca
17.[OS] Process
Process프로그램을 실행하는 과정에서 보조저장장치 등에서 프로그램을 메모리에 적재 후 실행할 경우 Process가 된다고 한다.모든 process는 CPU를 필요로 하며 CPU의 사용권한은 한정되어 있으므로 OS는 process에 정해진 시간만큼 CPU를 할당해주고
18.[OS] Process State와 Layer
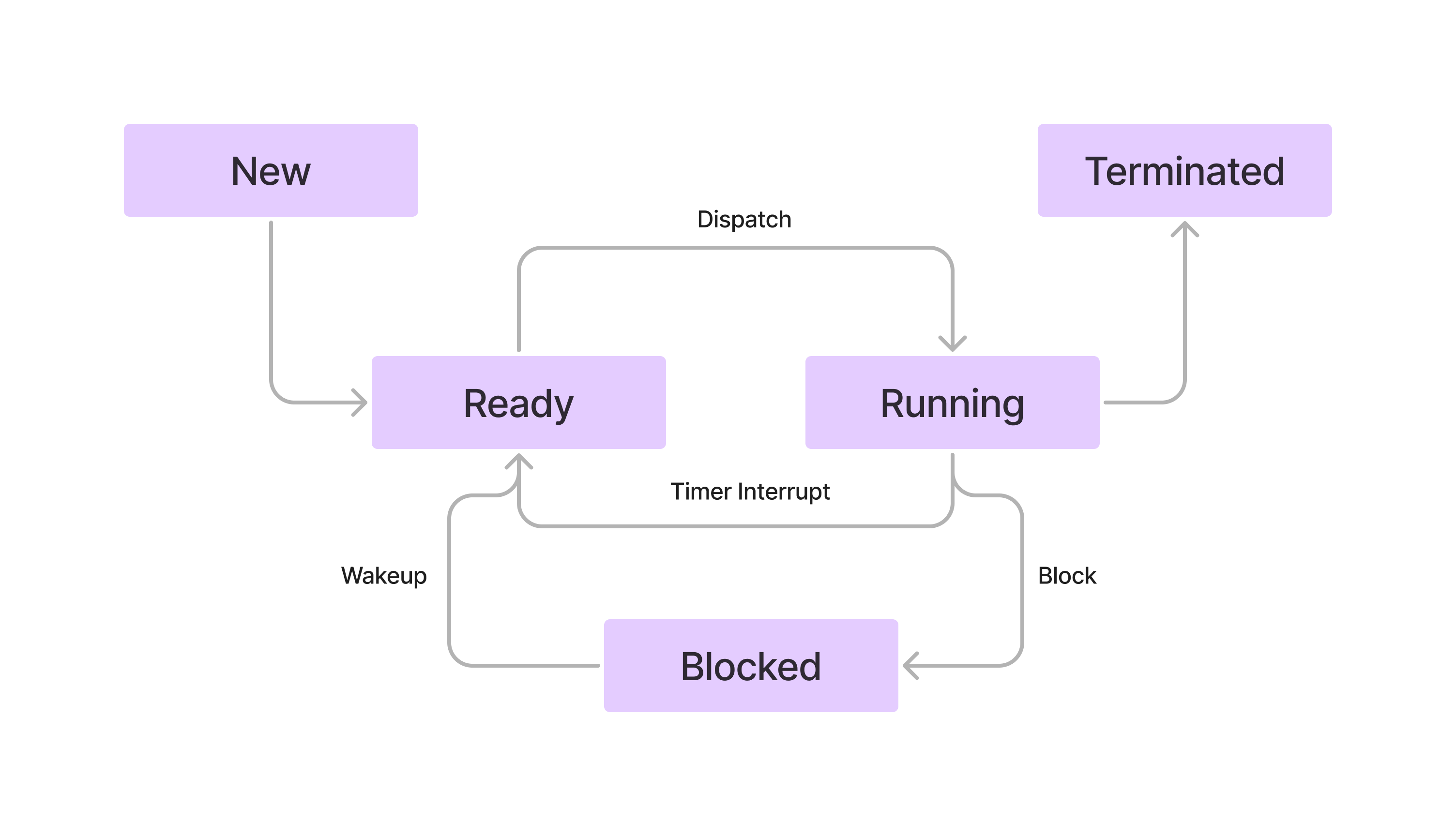
Process는 저마다의 상태를 가지는데 이를 Process State라고 한다.이는 5가지가 있다.NewProcess가 생성되어 메모리에 적재된 뒤 PCB에 할당받은 상태, 바로 실행되지 않고 Ready 상태가 되어 CPU의 할당을 기다린다.ReadyCPU를 할당받으
19.[OS] 스레드
Process를 구성하는 실행의 흐름 단위.전통적으로는 하나의 process는 하나의 thread를 갖는 단일 thread process라고도 볼 수 있다.Process에 thread라는 개념이 동비되면서 하나의 process에 여러 thread가 존재해 한 번에 여러
20.[OS] CPU Scheduling
OS가 어떤 process에 CPU 자원을 할당하고 어떤 process가 기다리도록 할지 결정하는 CPU 자원을 배분하는 과정을 CPU Scheduling이라고 한다.모든 process는 각자의 우선순위를 가지고 있다.우선순위가 높은 process는 빠르게 처리해야하는
21.[OS] CPU Scheduling Algorithm
ready queue에 먼저 요청한 process부터 CPU를 할당하는 Scheduling 방식의 비선점형 Scheduling.가장 공정해 보이지만 CPU를 너무 오래 차지하는 process가 있는 경우 다른 process들의 대기 시간이 매우 길어질 수 있다.예를들어
22.[OS] 동기화
process의 실행 순서와 자원의 일관성을 보장하기 위해 process의 수행 시기를 맞추는 것실행 순서 제어를 위한 동기화와 상호 배제를 위한 동기화 2종류가 있다.상호 배제를 위한 동기화에 대해서는 생산자와 소비자 문제가 있다.생산자와 소비자가 총합 이라는 데이터
23.[OS] 동기화 기법
process를 동기화하기 위해서는 아래 도구들을 사용한다.mutex locksemaphoremonitormutex lock은 critical section에 진입하는 process가 자신이 있음을 알리기 위해 lock을 걸도록 하는 도구이다.이를 통해 다른 proce
24.[OS] Deadlock
어떤 process를 실행하기 위해서는 자원이 필요한데 두개 이상의 process가 각기 가지고 있는 자원을 기다리는 상태라면, 서로가 자원을 무한정 기다리게 된다.이를 deadlock이라고 부른다.deadlock을 표현하는 문제상황이다.n명이 앉아있는 식탁에 n-1개
25.[OS] deadlock의 해결 방법
OS는 deadlock을 해결하기 위해 크게 3가지 방법을 사용하는데 이는 예방, 회피, 검출 후 회복 이다.애초에 deadlock이 일어나지 않도록 deadlock의 발생 조건에 부합하지 않도록 자원을 분배하여 예방할 수 있고, deadlock이 발생하지 않도록 조금
26.[OS] 연속 메모리 할당
현재까지는 memory 내부에 process들이 연속적으로 배치되는 상황을 가정했다.이러한 방식으로 process에 연속적인 memory 공간을 할당하는 방식을 연속 메모리 할당이라고 부른다.memory에 적재된 process 중에서 현재 실행되지 않는 process가
27.[OS] pagenation
외부 단편화가 생기는 근본적인 이유는 각기 다른 크기의 process가 memory에 연속적으로 할당되었기 때문이다.만일 process와 memory를 일정한 단위로 자르고 이를 memory에 불연속적으로 할당할 수 있다면 외부 단편화는 존재하지 않는다.이러한 과정을
28.[OS] page 교체와 frame 할당
process를 memory에 적재할 때 처음부터 모든 page를 적재하지 않고 필요한 page만을 memory에 적재하도록 하는 기법을 말한다.기본적인 양상은 아래와 같다.1\. CPU가 특정 page에 접근하는 명령어를 실행2\. 해당 page가 현재 memory에
29.[OS] File system
File system은 file과 directory를 보조기억장치에 저장하고 접근할 수 있게 하는 OS 내부 프로그램이다.대표적으로 FAT file system과 Unix file system이 있다.보조기억장치를 처음 사용하는 경우 사용을 위해서는 partioning
30.[Network] Network 살펴보기
네트워크란 graph라는 자료구조의 형태로 구성되는데 node, node를 연결하는 edge, node간 주고받는 message로 구성된다.host는 network 가장자리에 위치한 노드로 network를 통해 흐르는 정보를 생성, 송신, 수신한다.network의 가장
31.[Network] Network Model
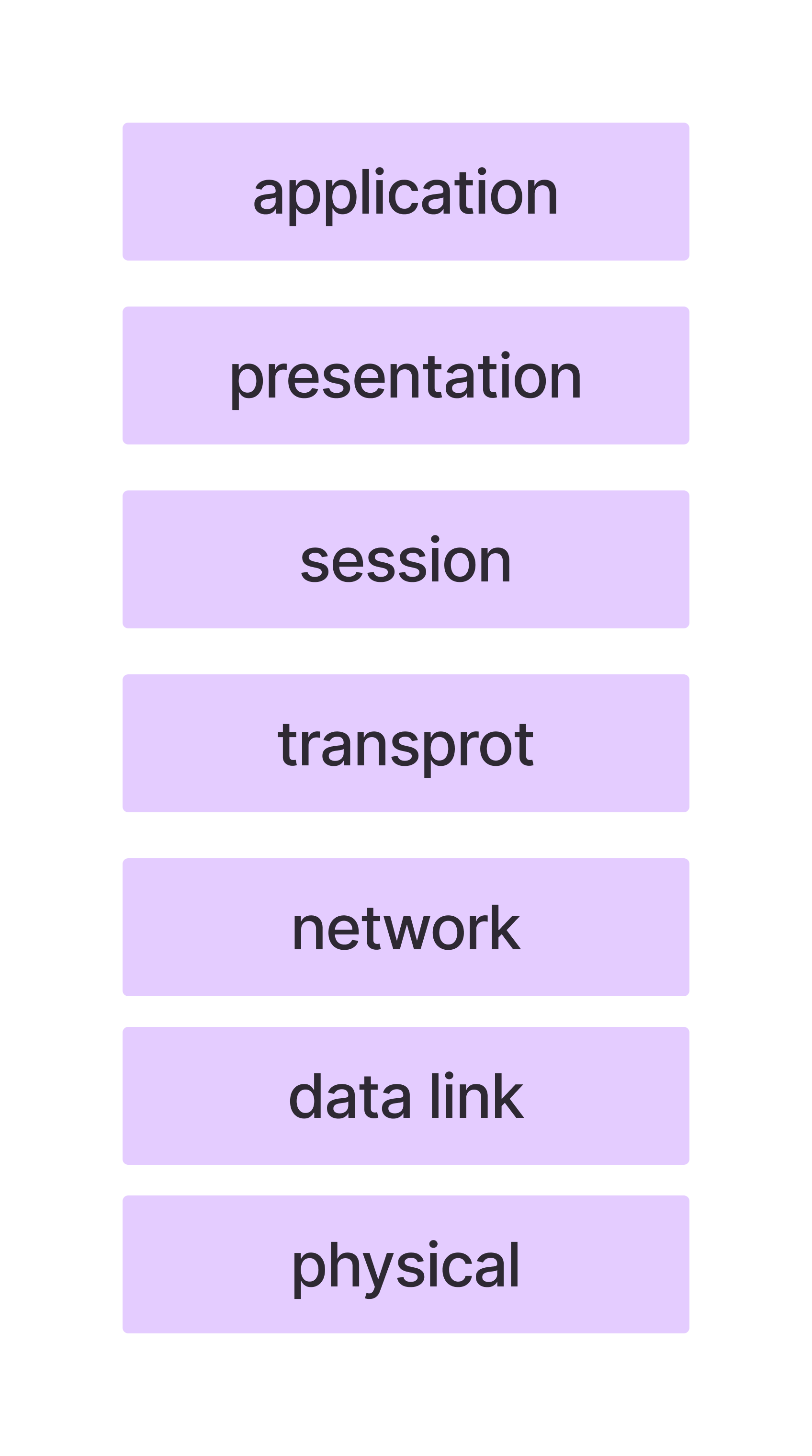
Network를 통해 정보를 주고받을 때, 정형화된 여러 단계를 거친다.이 과정을 계층으로 표현하며 이렇게 통신이 일어나는 과정을 계층으로 나눈 구조를 network reference model, 네트워크 계층 모델 이라고 한다.이렇게 계층구조로 나누는 이유는 네트워크
32.[Network] Ethernet
오늘날의 유선 LAN 환경은 대부분 이더넷을 기반으로 구성된다.이더넷은 현재 국제 표준이며 IEEE 802.3이라는 이름으로 표준화가 되어있다.보통 이더넷 표준 규격에 따라 구현된 통신 매체를 지칭하는 경우 전송속도BASE-추가특성 의 순서로 표기한다.1\. 전송 속도
33.[DB] DataBase 개요
DB : Database, 데이터의 집합 DBMS : DB를 관리, 운영하는 소프트웨어. 다양한 종류의 데이터가 대용량으로 저장되는 DB에 여러 명의 사용자나 응용 프로그램과 공유하고 동시에 접근할 수 있도록 한다. DBMS에는 여러 종류가 있으며 각각의 사용 방법
34.[DB] SELECT 기본
SELECT는 조건에 맞는 데이터를 추출하는 기능을 한다.가장 기본적인 형식으로는 FROM을 사용해 원하는 테이블을 지정하고 WHERE로 조건을 지정하는 SELECT FROM WHERE 형태이다.SELECT 열-이름 FROM 테이블-이름특정 DB를 사용한다는 설정을 하
35.[DB] SELECT 심화
SELECT에서는 결과의 정렬, 결과의 개수 제한, 중복 제거 등 추출하는 데이터에 대한 조건에서 추가적인 처리가 가능하다.또한 GROUP BY 등 지정한 열의 데이터들을 같은 데이터끼리는 묶어 결과를 추출하는 방식도 가능하다.주로 그룹으로 묶는 경우는 합계, 평균,
36.[DB] 데이터 변경을 위한 SQL
SELECT 문이 데이터를 수정하지 않고 추출하는 쿼리라면 데이터를 수정할 수 있는 쿼리문 또한 있다.새로 데이터를 입력하는 경우 SELECT, 데이터를 수정하는 경우 UPDATE, 데이터를 삭제하는 경우 DELETE 등이 있다.INSERT는 테이블에 데이터를 삽입하는
37.[DB] 데이터 형식
테이블을 만들 때 각 열에 대해서 데이터 형식을 정해야한다.데이터 형식에는 크게 숫자, 문자, 날짜 등이 있고 세부적으로는 여러 개로 나뉘기도 한다.주로 INT를 사용하며 숫자 범위는 바이트수를 따르며 각 형식의 범위를 벗어나면 OUT OF RANGE 에러가 출력된다.
38.[DB] JOIN
JOIN이란 두 개의 테이블을 서로 묶어서 하나의 결과를 만들어 내는 것을 말한다.예를 들면, 회원 테이블에는 회원의 이름과 연락처 등의 정보가 있고 구매 테이블에는 회원이 구매한 물건이 있는 경우물건을 배송하려면 회원 이름과 연락처, 구매 테이블의 회원이 구매한 물건
39.[DB] SQL 프로그래밍
스토어드 프로시저는 MYSQL에서 프로그래밍 기능이 필요할 때 사용하는 DB 개체이다.SQL 프로그래밍은 기본적으로 프로시저 안에 만들어야 한다.기본 구조는 아래와 같다.기본 문장에 대해서 IF문 뒤에 ELSE 구문을 추가하면 된다.위 예시의 경우에서1\. DECLAR
40.[DB] 테이블의 구조
TABLE은 표 형태로 구성된 2차원 구조로, 행과 열로 구성되어 있다.행은 ROW나 RECORD라고 부르며, 열은 COLUMN또는 FIELD라고 부른다.테이블을 생성하는 경우 CREATE TABLE을 통해 생성하도록 한다.기본적으로 테이블 이름, 열 이름, 각 FIE
41.[DB] 제약조건
테이블을 만들 때는 테이블의 구조에 필수적인 제약조건을 설정해줘야 한다.앞에서 계속 말했던 PK, FK가 대표적인 제약조건이라고 할 수 있다.이메일, PHONE, ID 등 다른 열과 중복되지 않는 열에는 고유키(UNIQUE)를 지정할 수 있다.회원의 키가 3M를 넘는
42.[DB] VIEW
뷰는 DB 개체 중 하나이고 테이블과 아주 밀접한 관련이 있다.VIEW는 한 번 생성하면 테이블이라고 생각하고 사용할 정도로 사용자들의 입장에서는 테이블과 거의 동일한 개체로 취급한다.VIEW는 실제로 데이터를 갖고 있지는 않지만 VIEW에 접근하면 SELECT가 실행
43.[DB] INDEX 기본
INDEX는 데이터를 빠르게 찾을 수 있도록 도와주는 도구이다.INDEX에는 클러스터형 인덱스와 보조 인덱스가 있다.CLUSTERED INDEX는 기본 키로 지정하면 자동 생성되며 테이블에 1개만 만들 수 있다.기본 키로 지정한 열을 기준으로 자동 정렬된다.SECOND
44.[DB] INDEX의 내부 작동
CLUSTERED INDEX와 SECONDARY INDEX는 모두 내부적으로 균형 트리(B-TREE)로 만들어진다. INDEX 내부 작동 원리 INDEX의 정확한 사용을 위해서는 내부 작동 원리를 이해하는 것이 좋다. B-TREE 개념 균형 트리에서 데이터가 저장되
45.[DB] INDEX의 효과적인 사용
앞에서 알아본 인덱스의 특징을 바탕으로 효과적인 사용에 대해 정리한다.하나의 열에 2개 이상의 인덱스를 만들 수 있고, 2개 이상의 열을 묶어서 하나의 인덱스로 만드는 것도 가능은 하지만, 이런 경우는 드물기 때문에 하나의 열에 하나의 인덱스를 만드는 것이 가장 일반적
46.[DB] STORED PROCEDURE
SQL은 DB에서 사용되는 언어이다.앞에서 본 내용들을 총합하면 SQL을 사용하는 경우 자동화하지 않고 반복적으로 사용하기에는 상당히 불편하고 한계가 명확하다.MYSQL의 스토어드 프로시저는 이러한 한계를 극복하기 위해 SQL에 프로그래밍 기능을 추가해서 일반 프로그래
47.[DB] TRIGGER
트리거는 자동으로 수행하여 사용자가 추가 작업을 잊어버리는 실수를 방지해준다.예를 들면, 직원이 퇴사하는 경우 직원 테이블에서 퇴사자 테이블로 옮긴 뒤 직원 테이블의 내용을 지워야하는데 만약 옮기기 전에 데이터를 지운다면 백업하기 이전에 데이터 자체가 삭제된다.트리거를