
크롤링 정규수업을 복습하다가, 영 혼자 해결을 못해서 유튜브로 조금 더 학습을 해봤다. 기존에 주피터 노트북에서만 하던 걸 벗어나 VS Code에서 .py 파일로 진행했다. 참고로 VS Code 활용하니까 자동 완성이 돼서 너무 편하고 좋았다..
[컴터와 나의 대화]
-\ 어떤 거 검색할래?
-\ 파이썬
-\ 그래(크롬창을 열고 닫음, 결과 보여줌)
파이썬 파일로 저장해서 그런 건지는 모르겠지만, 자바스크립트처럼 문답을 실행해봐서 참신했다. 그 작업에 간접적으로 활용된 새로운 라이브러리도 있다.
우선 아래와 같이 라이브러리를 불러온다. 설치가 필요한 경우, vs code 내 터미널 창에서 pip install beautifulsoup4와 pip install selenium을 먼저 설치하고 아래 라이브러리를 불러온다. (주피터 노트북의 경우 대부분의 라이브러리가 자체적으로 설치 되어 있어서 pip를 할 필요는 없다. selenium은 없지만)
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
from selenium import webdriver유튜브 강사는 구글로 ‘파이썬’을 검색했을 때의 url을 찬찬히 봤다. 보면서, 다른 페이지로 이동하는 경우(이미지 검색, 뉴스 검색 등) 주소가 어떻게 달라지는지 살피고 아래와 같이 baseUrl과 검색어에 따라 달라지는 이후 부분인 plusUrl을 구분했다. 그리고 아래와 같은 인터랙션?이 가능하도록 했다. 코드 전체를 실행하면 '무엇을 검색할까요? :'가 나오고 거기에 '파이썬'을 입력하면 구글에서의 '파이썬' 검색 결과를 크롤링하는 방식이다.
baseUrl = 'https://www.google.com/search?q='
plusUrl = input('무엇을 검색할까요? :')
url = baseUrl + quote_plus(plusUrl)위에서 quote_plus가 나온다. 한글은 인터넷에서 바로 사용하는 방식이 아니라 변환이 필요한데 이때 역할을 해주는 친구다. 왜 아무리 한글로 해도 URL에 막 %CE%GD%EC 이런 거 나오잖아요? 그렇게 변환해주는 친구다.
이 이후에 큰 위기에 봉착했는데, 셀레니움을 위해 미리 깔았던 chromedriver가 정말... 화가 많이(순화) 날 정도로 동작하지 않았다. 같은 폴더 내에 설치했음에도 불구, path가 잘못 되었다느니 어쩌구 저쩌구 해서 결국 강사의 예시와 달리 path를 설정해주었다. 그 이후 url을 얻어 가져온 과정까지는 아래와 같다.
(그러고보니 이 과정에서는 html 파싱이 없는 듯하다. 그래도 되는 건가..?)
driver = webdriver.Chrome(executable_path= r'/Users/user/Desktop/python_trial/chromedriver')
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html)그리고 나서 내가 원하는 부분, 즉 검색 결과 페이지의 제목과 링크를 얻기 위해 해당 구역의 class를 아래와 같이 변수 v로 지정했다. (강의에서는 print(type(v)) 했을 때 list형이 나왔는데, 나는 bs4.element.ResultSet이 나왔고 이 역시 list처럼 취급해 줄 수 있다고 한다.
v = soup.select('.yuRUbf')최종적으로 해당 내용들을 볼 수 있도록 for문을 활용하여 정리하고 셀레니움으로 인해 열렸던 크롬 화면을 닫으면 원하는 크롤링이 마무리된다.
for i in v:
print(i.select_one('.LC20lb.DKV0Md').text) # 제목
print(i.a.attrs['href']) # 링크
print()
driver.close() # 크롬 창 닫기클래스 입력에 관한 몇 가지 이야기
- 클래스는 . 를 쓰고 아이디는 # 을 쓴다.
- 엘리먼트 사이에 공백이 있는 경우 공백 대신 . 을 쓴다.
- 특정 엘리먼트 하위 엘리먼트를 가져오고 싶으면
.upperelement .lowerelement요렇게 마침표 사이를 한 칸 띄운다. - 특정 엘리먼트 바로 하위 자식 엘리먼트를 가져오고 싶은 경우 이렇게도 쓸 수 있다.
.motherelement > .childelement그런데 바로 위 방법이 있는데 굳이..?
제목 부분에서 그냥 select가 아니라 select_one을 설정한 건 역시 리스트이기 때문이라고 했다. 근데 내가 확인해봤을 때는 오히려 str이 나와서 이 부분도 좀 미심쩍었다. (select_one은 클래스 이름이 .LC~로 시작하는 html 요소 중 첫 번째 요소만 반환한다.)
그리고 링크 부분은 v 에 해당하는 클래스 안에서 링크 태그에 해당하는 애들만 불러오는 방식인데 저렇게 조금 외워야 할 것 같이; 표기하였다.
그렇게 실행한 결과는 아래와 같다. 아직 VS code는 익숙하지 않아 이대로 올려둔다.
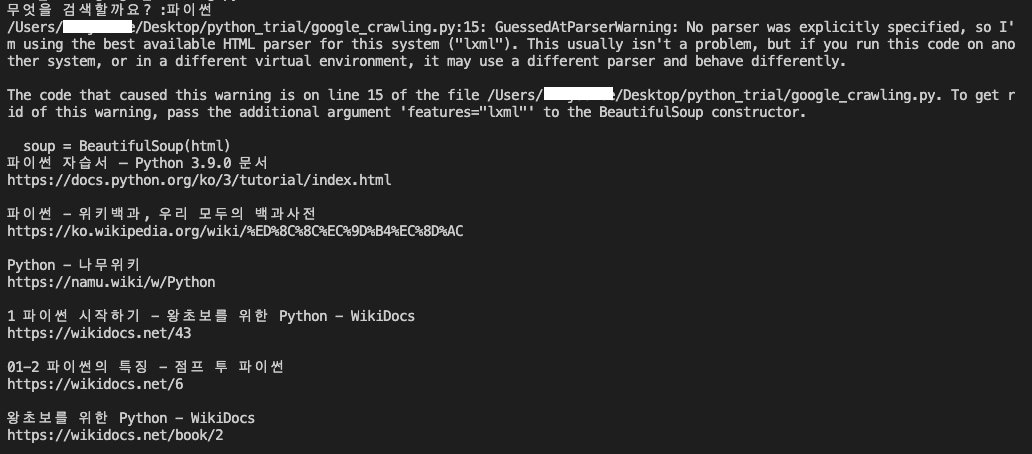
전체 코드는 아래와 같다. (크롬드라이버 path는 삭제)
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
from selenium import webdriver
baseUrl = 'https://www.google.com/search?q='
plusUrl = input('무엇을 검색할까요? :')
url = baseUrl + quote_plus(plusUrl)
# 한글은 인터넷에서 바로 사용하는 방식이 아니라, quote_plus가 변환해줌
# URL에 막 %CE%GD%EC 이런 거 만들어주는 친구
driver = webdriver.Chrome()
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html)
v = soup.select('.yuRUbf')
# print(type(v)) 강의에서는 list가 나오는데, 나는 bs4.element.ResultSet 나옴..
for i in v:
print(i.select_one('.LC20lb.DKV0Md').text)
print(i.a.attrs['href'])
print()
driver.close()중간에 너무 걸림돌 걸림산이 많고 커서 맥주를 깠지만, 그래도 배운 점들이 있어 이렇게 남겨둔다.
김플 스튜디오님, 좋은 강의 감사합니다. 유튜브 링크
