Python에서 csv 파일 읽는 방법을 자꾸 까먹어서 정리해보려고 한다!
기본 csv 라이브러리를 이용해 읽기
import csv
with open(filename, newline='') as csvfile:
csvreader = csv.reader(csvfile)
for row in csvreader:
print(row)이 작업에서는 csvreader에 담긴 한줄씩의 정보를 for문으로 접근한다
그 한 줄씩 print해주는 작업
next() 이용하기
한 줄씩 읽는 작업이지만, 다음 주로 넘어가고 싶다면 next()를 쓰면 된다
import csv
with open(filename, newline='') as csvfile:
csvreader = csv.reader(csvfile)
next(csvreader)
for row in csvreader:
print(row)하면 csv 파일의 헤더를 제외한 부분을 print 하는 작업이 되는 것
import csv
with open(filename, newline='') as csvfile:
csvreader = csv.reader(csvfile)
for row in csvreader:
print(row)
next(csvreader)라고 한다면 홀수 줄의 정보만 print할 수 있겠지요
list에 관리하기
import csv
infos = []
with open(filename, newline='') as csvfile:
csvreader = csv.reader(csvfile)
next(csvreader)
for row in csvreader:
infos.append(row)csv 파일의 정보를 한 줄씩 묶어 담는 list를 만드는 경우가 많아, 보통은 이렇게 작업하고 있다.
하지만 이렇게 작업하다보니 몇 번째 요소가 어떤 역할을 하고 있는지 기억해줘야 한다는 단점이 있음
DictReader를 이용하면 csv 파일을 딕셔너리로 저장할 수 있다고 한다.
파일 헤더와 함께 DictReader로 읽어 Python Dictionary 타입으로 사용하기
import csv
infos = []
with open(filename, newline='') as csvfile:
csvreader = csv.DictReader(csvfile)
next(csvreader)
for row in csvreader:
infos.append(row)DictReader를 이용하면 row의 값이 dictionary로 저장된다
이 때의 key는 자동으로 헤더의 값이 들어감
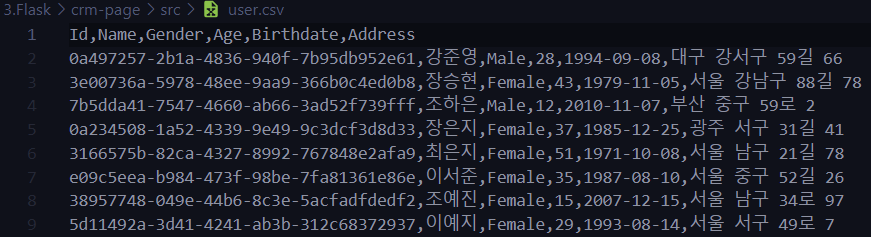
실습
user.csv 파일
import csv
users = []
with open('src/user.csv', newline='', encoding="utf-8") as user:
reader = csv.DictReader(user)
next(reader)
for user in reader:
users.append(user)
for user in users :
print(user.keys())
print(user.values())
print()이 코드로 확인해보면
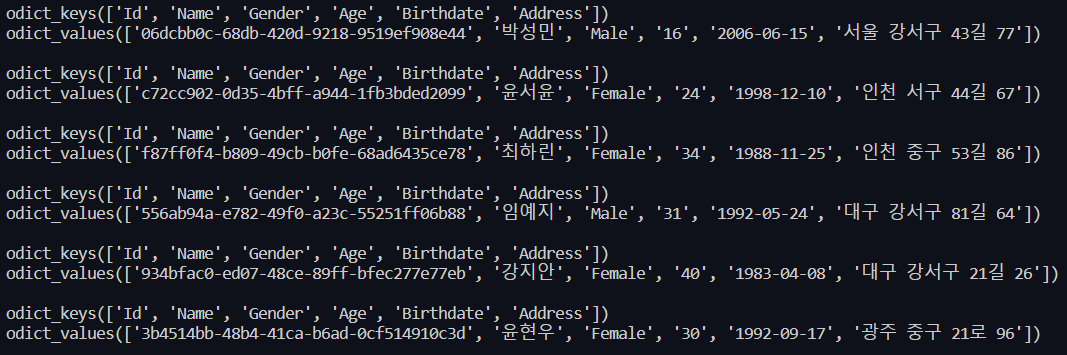
각 요소가 dictionary 타입으로 잘 들어간 것을 확인할 수 있다
