2-1 데이터 입출력
자료구조(Data Structure)
자료구조는 데이터를 효율적으로 저장하고 관리하기 위해 고안된 체계적인 방법론입니다. 이를 통해 작업 성능을 최적화할 수 있습니다.
- 선형 구조: 데이터를 순서대로 저장하며, 대표적으로 리스트, 스택(Stack), 큐(Queue), 데크(Deque)가 있습니다.
- 비선형 구조: 계층적 또는 복잡한 관계를 가진 트리(Tree)와 그래프(Graph) 등이 포함됩니다.
리스트
- 데이터를 순차적으로 저장하며, 배열과 연결 리스트로 구현할 수 있습니다. 배열은 메모리 연속성을 가지며, 연결 리스트는 포인터를 통해 요소를 연결합니다.
스택(Stack)
- 데이터를 삽입(Push)하거나 삭제(Pop)할 때 항상 마지막에 추가된 데이터부터 작업하는 구조입니다. 후입선출(LIFO, Last In First Out) 원칙을 따르며, 함수 호출, 재귀 처리 등에 사용됩니다.
큐(Queue)
- 한쪽 끝에서 삽입 작업이, 반대쪽 끝에서 삭제 작업이 이루어지는 자료구조로, 선입선출(FIFO, First In First Out) 원칙을 따릅니다. 작업 스케줄링 등에 활용됩니다.
데크(Deque)
- 양방향으로 삽입과 삭제가 가능한 자료구조로, 유연하게 데이터를 처리할 수 있습니다.
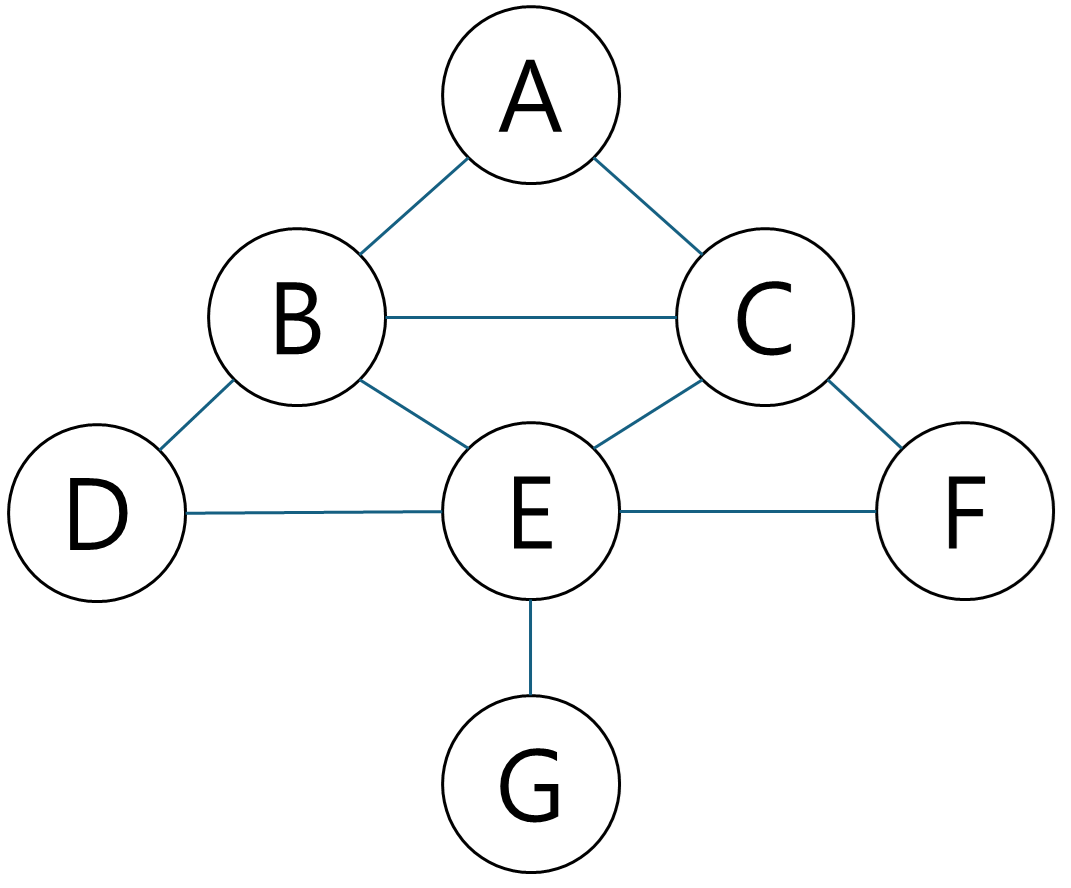
그래프(Graph)
- 정점(Node)와 이를 연결하는 간선(Edge)으로 이루어진 구조입니다.
- 방향 그래프: 간선에 방향이 있으며, 단방향 연결을 표현합니다.
- 무방향 그래프: 간선에 방향이 없으며, 쌍방향 연결을 나타냅니다.
트리(Tree)
- 그래프의 특수한 형태로, 계층적 구조를 가지며 정점 사이에 순환이 없습니다.
- 차수: 각 노드가 가진 자식 노드의 개수를 뜻하며, 트리의 전체 차수는 가장 많은 자식을 가진 노드의 자식 수로 결정됩니다.
- 트리는 전위, 중위, 후위 순회 방식을 통해 탐색할 수 있습니다.
탐색 방식
- 깊이 우선 탐색(DFS): 가능한 깊이까지 내려간 후 다른 경로를 탐색합니다.
- 너비 우선 탐색(BFS): 같은 계층의 모든 노드를 탐색한 후 다음 계층으로 이동합니다.
트리 종류
- 이진 탐색 트리(BST): 왼쪽 자식은 부모보다 작은 값, 오른쪽 자식은 부모보다 큰 값을 갖는 트리입니다.
- AVL 트리, 레드-블랙 트리: 자가 균형 유지로 효율적인 탐색을 지원하는 트리입니다.
중위식, 전위식, 후위식 표현
- 연산자의 위치에 따라 수식을 중위식(Infix), 전위식(Prefix), 후위식(Postfix)으로 표현할 수 있습니다.


공부하는중입니다.