JPA란
JPA(Java Persistence API)는 자바의 표준 ORM(Object-relational mapping)으로 자바 어플리케이션과 JDBC API의 인터페이스 역할을 합니다.
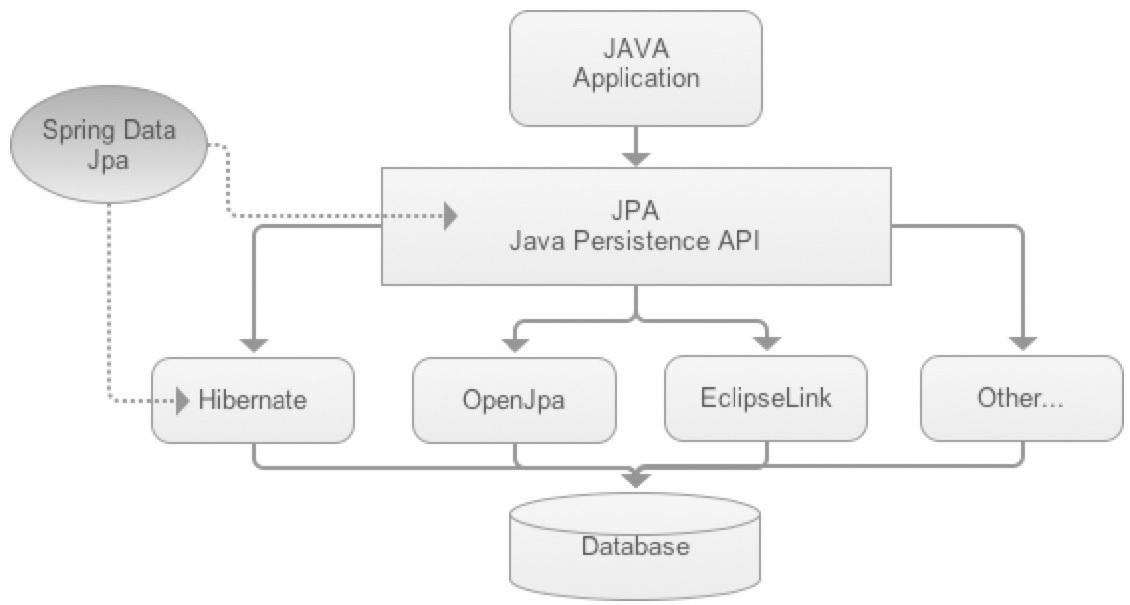
JPA는 실제 JDBC와 연결을 동작시키는 것이 아닌 표준 인터페이스 모음이므로 사용을 위해선 실제 구현체를 가진 프레임워크를 이용합니다.
- 실제 구현 프레임워크 종류 : Hibernate, EclipseLink, DataNucleus
JPA의 동작
JPA는 ORM 인터페이스이므로 객체 중심으로 JDBC에 접근하도록 합니다.
모든 엔티티 객체는 각각의 테이블에 매칭되어 CRUD 동작의 쿼리를 JPA가 생성하여 JDBC에 전달합니다. 즉 쿼리문의 작성이 필요 없습니다.
CRUD에 맞는 동작을 하는 JPA 표준 메서드들을 제공하여 JDBC에 접근합니다.
- 저장
- 개발자가 엔티티를 파라미터로 갖는 JPA 메서드 호출(
persist(엔티티)) - JPA에서 엔티티를 분석하여 SQL 생성, JDBC에 SQL 전송
- 개발자가 엔티티를 파라미터로 갖는 JPA 메서드 호출(
- 조회
- 개발자가 컬럼의 pk를 JPA로 호출(
find(pk)) - JPA가 JDBC에 SQL을 전송하고 결과 리턴
- 리턴된 결과(
ResultSet)을 목표 엔티티에 매핑
- 개발자가 컬럼의 pk를 JPA로 호출(
JPA를 사용하는 이유
JPA를 통해 SQL 문을 작성하는 것이 아닌 JPA 메서드로 개발할 수 있습니다. JPA 표준 메서드를 이용해 Collection 에 데이터를 넣고 가져오는 것처럼 이용할 수 있습니다.
SQL 중심 개발의 문제점
쿼리 중심 개발은 자바 객체와 관계형 DB의 패러다임 불일치라는 문제점을 갖고 있습니다.
객체지향의 다형성 추상화 등의 특성의 불일치로 모든 상속 및 참조 관계 등에서 각각의 쿼리를 작성해야합니다.
1. CRUD 코드의 반복
- 수정 시( 객체 속성, 컬럼 추가) 모든 작성된 쿼리문에서 해당 정보를 추가 필요
2. 상속 관계 제어
- 상속 관계를 가진 객체를 저장하기 위해 복잡한 동작 필요
- 부모 클래스와 자식 클래스의 테이블을 DB에서 사용할 때 자식 객체를 DB에 저장하거나 불러올 때 두 개의 테이블에 저장하고 JOIN을 통해 가져올 필요
3. 참조 관계 제어
- 객체 내에서 참조를 이용하는 경우 테이블에 맞게 정의하기 위해 객체의 레퍼런스가 아닌 참조키 값을 저장해야하는 불편함
4. 그래프 탐색
연관 관계 엔티티 탐색 과정에서 비효율적입니다.
- 모든 상황에서 필요한 메서드를 정의해야함
- 연관 관계의 탐색 과정에서 각 객체를 신뢰할 수 없는 문제가 발생
5. 동일성 비교
- 쿼리로 받아오는 데이터는 매번 새로운 객체를 가져오기 때문에 동일성 비교에 문제가 있음
- 각각의 객체의
equals()메서드 재정의로 동등성을 비교할 수 있으나 완전한 동일성(hashcode의 차이)을 보장할 수 없음
JPA 장점
객체 중심의 데이터베이스 매핑을 지원하기 때문에 작성된 문제점을 대부분 해결할 수 있습니다.
1. CRUD 코드 반복 및 상속 관계 제어
- JPA 가 엔티티에 맞게 쿼리를 작성하므로 각 엔티티를 수정(필드 추가 및 제거)하는 것만으로 제어 가능
- 또한 상속 관계를 가진 엔티티의 중복 테이블
INSERT및SELECT또한 JPA 에서 각각의 테이블을 만들고 매핑 및 조인
2. 연관 관계 제어, 탐색
- 자바 객체 기반이므로 참조 멤버를 통해 연관 관계 정의 가능
- 정의된 연관 관계에 맞게 JPA에서 쿼리 작성
- 연관객체 탐색 시 각 메서드의 신뢰성 보장
3. 동일성 보장
- 동일한 트랜잭션으로 호출한 객체는 동일함 비교 가능
Reference
https://gmlwjd9405.github.io/2019/08/04/what-is-jpa.html

민기1