SurveyDocument
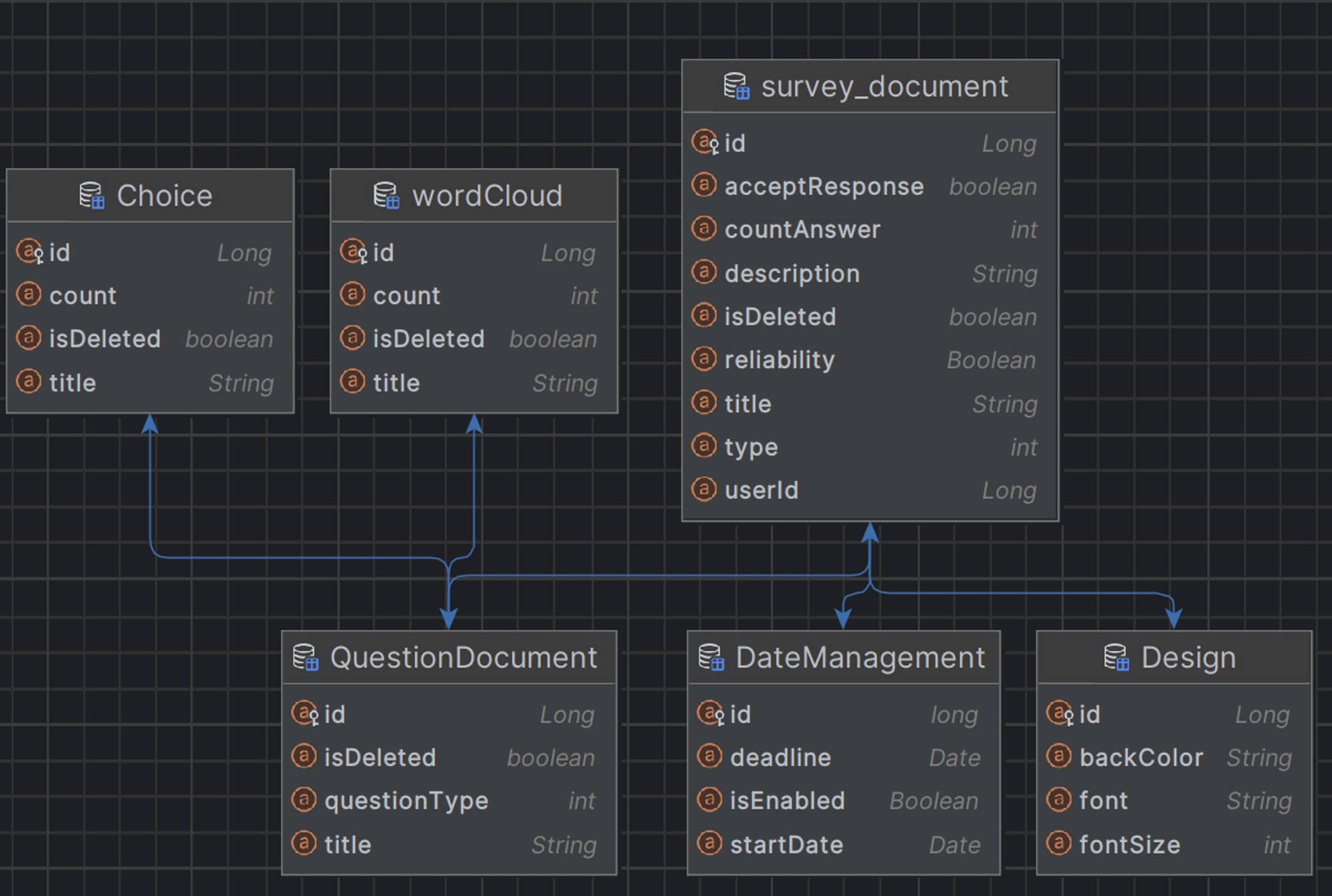
survey document ERD
- 현재 모든 엔티티 연관 관계 매핑에서
fetch = FetchType.LAZY로 설정해 놓았다.
현재 연관관계
survey_document
- (
OneToOne)Design - (
OneToOne)DateManagement - (
OneToMany)question_document- (
OneToMany)Choice - (
OneToMany)wordCloud
- (
설문 조회 DB 쿼리 - fetchJoin, batchSize
밑에 있는 조회 쿼리는 밑의 구성으로 된 정보를 조회할 때 생긴 쿼리이다.
-
suveydocument #1
- questiondocument #1
- choice #1
- wordCloud #1
- choice #2
- wordCloud #2
- questiondocument #2
- choice #3
- wordCloud #3
- choice #4
- wordCloud #4
- questiondocument #1
-
조회 쿼리
Hibernate:
select
s1_0.survey_document_id,
s1_0.accept_response,
s1_0.answer_count,
d1_0.date_id,
d1_0.survey_deadline,
d1_0.survey_enable,
d1_0.survey_start_date,
s1_0.survey_description,
d2_0.design_id,
d2_0.back_color,
d2_0.font,
d2_0.font_size,
s1_0.is_deleted,
s1_0.reliability,
s1_0.survey_title,
s1_0.survey_type,
s1_0.user_id
from
survey_document s1_0
left join
date_management d1_0
on s1_0.survey_document_id=d1_0.survey_document_id
left join
design d2_0
on s1_0.survey_document_id=d2_0.survey_document_id
where
s1_0.survey_document_id=?
and (
s1_0.is_deleted = 0
)
2023-10-18T00:32:17.373+09:00 INFO 3496 --- [nio-8082-exec-3] p6spy : #1697556737373 | took 13ms | statement | connection 6| url jdbc:mysql://localhost:3306/surveydb
select s1_0.survey_document_id,s1_0.accept_response,s1_0.answer_count,d1_0.date_id,d1_0.survey_deadline,d1_0.survey_enable,d1_0.survey_start_date,s1_0.survey_description,d2_0.design_id,d2_0.back_color,d2_0.font,d2_0.font_size,s1_0.is_deleted,s1_0.reliability,s1_0.survey_title,s1_0.survey_type,s1_0.user_id from survey_document s1_0 left join date_management d1_0 on s1_0.survey_document_id=d1_0.survey_document_id left join design d2_0 on s1_0.survey_document_id=d2_0.survey_document_id where s1_0.survey_document_id=? and (s1_0.is_deleted = 0)
select s1_0.survey_document_id,s1_0.accept_response,s1_0.answer_count,d1_0.date_id,d1_0.survey_deadline,d1_0.survey_enable,d1_0.survey_start_date,s1_0.survey_description,d2_0.design_id,d2_0.back_color,d2_0.font,d2_0.font_size,s1_0.is_deleted,s1_0.reliability,s1_0.survey_title,s1_0.survey_type,s1_0.user_id from survey_document s1_0 left join date_management d1_0 on s1_0.survey_document_id=d1_0.survey_document_id left join design d2_0 on s1_0.survey_document_id=d2_0.survey_document_id where s1_0.survey_document_id=4 and (s1_0.is_deleted = 0);
2023-10-18T00:32:17.395+09:00 INFO 3496 --- [nio-8082-exec-3] p6spy : #1697556737395 | took 0ms | commit | connection 6| url jdbc:mysql://localhost:3306/surveydb
;
Hibernate:
select
q1_0.survey_document_id,
q1_0.question_document_id,
q1_0.is_deleted,
q1_0.question_type,
q1_0.question_title
from
question_document q1_0
where
q1_0.survey_document_id=?
and (
q1_0.is_deleted = 0
)
2023-10-18T00:32:17.405+09:00 INFO 3496 --- [nio-8082-exec-3] p6spy : #1697556737405 | took 1ms | statement | connection 6| url jdbc:mysql://localhost:3306/surveydb
select q1_0.survey_document_id,q1_0.question_document_id,q1_0.is_deleted,q1_0.question_type,q1_0.question_title from question_document q1_0 where q1_0.survey_document_id=? and (q1_0.is_deleted = 0)
select q1_0.survey_document_id,q1_0.question_document_id,q1_0.is_deleted,q1_0.question_type,q1_0.question_title from question_document q1_0 where q1_0.survey_document_id=4 and (q1_0.is_deleted = 0) ;
Hibernate:
select
c1_0.question_id,
c1_0.choice_id,
c1_0.choice_count,
c1_0.is_deleted,
c1_0.choice_title
from
choice c1_0
where
c1_0.question_id=?
and (
c1_0.is_deleted = 0
)
2023-10-18T00:32:17.409+09:00 INFO 3496 --- [nio-8082-exec-3] p6spy : #1697556737409 | took 0ms | statement | connection 6| url jdbc:mysql://localhost:3306/surveydb
select c1_0.question_id,c1_0.choice_id,c1_0.choice_count,c1_0.is_deleted,c1_0.choice_title from choice c1_0 where c1_0.question_id=? and (c1_0.is_deleted = 0)
select c1_0.question_id,c1_0.choice_id,c1_0.choice_count,c1_0.is_deleted,c1_0.choice_title from choice c1_0 where c1_0.question_id=14 and (c1_0.is_deleted = 0) ;
Hibernate:
select
w1_0.question_id,
w1_0.word_cloud_id,
w1_0.word_cloud_count,
w1_0.is_deleted,
w1_0.word_cloud_title
from
word_cloud w1_0
where
w1_0.question_id=?
and (
w1_0.is_deleted = 0
)
2023-10-18T00:32:17.412+09:00 INFO 3496 --- [nio-8082-exec-3] p6spy : #1697556737412 | took 1ms | statement | connection 6| url jdbc:mysql://localhost:3306/surveydb
select w1_0.question_id,w1_0.word_cloud_id,w1_0.word_cloud_count,w1_0.is_deleted,w1_0.word_cloud_title from word_cloud w1_0 where w1_0.question_id=? and (w1_0.is_deleted = 0)
select w1_0.question_id,w1_0.word_cloud_id,w1_0.word_cloud_count,w1_0.is_deleted,w1_0.word_cloud_title from word_cloud w1_0 where w1_0.question_id=14 and (w1_0.is_deleted = 0) ;
Hibernate:
select
c1_0.question_id,
c1_0.choice_id,
c1_0.choice_count,
c1_0.is_deleted,
c1_0.choice_title
from
choice c1_0
where
c1_0.question_id=?
and (
c1_0.is_deleted = 0
)
2023-10-18T00:32:17.414+09:00 INFO 3496 --- [nio-8082-exec-3] p6spy : #1697556737414 | took 0ms | statement | connection 6| url jdbc:mysql://localhost:3306/surveydb
select c1_0.question_id,c1_0.choice_id,c1_0.choice_count,c1_0.is_deleted,c1_0.choice_title from choice c1_0 where c1_0.question_id=? and (c1_0.is_deleted = 0)
select c1_0.question_id,c1_0.choice_id,c1_0.choice_count,c1_0.is_deleted,c1_0.choice_title from choice c1_0 where c1_0.question_id=15 and (c1_0.is_deleted = 0) ;
Hibernate:
select
w1_0.question_id,
w1_0.word_cloud_id,
w1_0.word_cloud_count,
w1_0.is_deleted,
w1_0.word_cloud_title
from
word_cloud w1_0
where
w1_0.question_id=?
and (
w1_0.is_deleted = 0
)
2023-10-18T00:32:17.416+09:00 INFO 3496 --- [nio-8082-exec-3] p6spy : #1697556737416 | took 0ms | statement | connection 6| url jdbc:mysql://localhost:3306/surveydb
select w1_0.question_id,w1_0.word_cloud_id,w1_0.word_cloud_count,w1_0.is_deleted,w1_0.word_cloud_title from word_cloud w1_0 where w1_0.question_id=? and (w1_0.is_deleted = 0)
select w1_0.question_id,w1_0.word_cloud_id,w1_0.word_cloud_count,w1_0.is_deleted,w1_0.word_cloud_title from word_cloud w1_0 where w1_0.question_id=15 and (w1_0.is_deleted = 0) ;
2023-10-18T00:32:17.424+09:00 INFO 3496 --- [nio-8082-exec-3] c.e.s.s.service.SurveyDocumentService : SurveyDetailDto(id=4, title=test2, description=test2, countAnswer=0, questionList=[QuestionDetailDto(id=14, title=test, questionType=1, choiceList=[ChoiceDetailDto(id=15, title=test1, count=0), ChoiceDetailDto(id=16, title=test2, count=0)], wordCloudDtos=[]), QuestionDetailDto(id=15, title=test, questionType=1, choiceList=[ChoiceDetailDto(id=17, title=test3, count=0), ChoiceDetailDto(id=18, title=test4, count=0)], wordCloudDtos=[])], reliability=true, startDate=2023-10-02 00:27:17.1, endDate=2023-10-02 00:27:17.1, enable=true, design=DesignResponseDto(font=font, fontSize=0, backColor=font))-
조회 쿼리에서
SurveyDocument와@OneToOne관계인Design 과 DateMangaement를left join해서 가져 온다. -
SurveyDocument에 연관된@OneToMany관계인QuestionDocument들을 가져올 때 지연 로딩이 발생하여 다시 쿼리를 날려서 가져온다. -
QuestionDocument1에@OneToMany관계로 연관된Choice를 가져올 때도 지연 로딩이 발생하여 다시 쿼리를 날려서 가져온다. -
QuestionDocument1에@OneToMany관계로 연관된wordCloud를 가져올 때도 지연 로딩이 발생하여 다시 쿼리를 날려서 가져온다. -
QuestionDocument2에@OneToMany관계로 연관된Choice를 가져올 때도 지연 로딩이 발생하여 다시 쿼리를 날려서 가져온다. -
QuestionDocument2에@OneToMany관계로 연관된wordCloud를 가져올 때도 지연 로딩이 발생하여 다시 쿼리를 날려서 가져온다.
즉, N + 1 문제가 발생하고 있다.
N + 1문제는 이름에서 알 수 있듯이, 먼저1의 쿼리가 실행되어 주 엔티티를 조회하고, 그 후에 각각의 하위 엔티티를 조회하기 위해 "N"의 추가 쿼리가 실행되는 패턴을 말합니다. 이 경우N은 하위 엔티티의 수에 해당하며, 따라서 하위 엔티티의 수가 많을수록 데이터베이스에 부담을 줍니다.)
- 설문 조회 쿼리는 지정된
id의surveydocument에 관한 모든 칼럼을 조회해야 한다.
fetch join을 통해서 컬렉션 조회 최적화를 해야한다.
queryDsl을 이용한 쿼리 작성
queryFactory
.selectFrom(surveyDocument)
.join(surveyDocument.questionDocumentList, questionDocument).fetchJoin()
.leftJoin(questionDocument.choiceList, choice).fetchJoin()
.fetchOne();-
이때
MultipleBagFetchException이 발생하였다. (Fetch Join은xx**ToOne은 여러 개 적용이 가능하지만,xx**ToMany와 같이1:N의 관계에서N에 대해서는 여러 개 사용할 수 없다.) -
application.properties에batch size설정 추가 (Hibernate는 한 번에 지정된 배치 크기만큼의 엔티티를 데이터베이스에서 가져오게 됩니다.)
spring.jpa.properties.hibernate.default_batch_fetch_size=1000- 그 이후
in절이 사용되며 쿼리 수를 줄였다. (6번→4번) - 쿼리
Hibernate:
select
s1_0.survey_document_id,
s1_0.accept_response,
s1_0.answer_count,
d1_0.date_id,
d1_0.survey_deadline,
d1_0.survey_enable,
d1_0.survey_start_date,
s1_0.survey_description,
d2_0.design_id,
d2_0.back_color,
d2_0.font,
d2_0.font_size,
s1_0.is_deleted,
s1_0.reliability,
s1_0.survey_title,
s1_0.survey_type,
s1_0.user_id
from
survey_document s1_0
left join
date_management d1_0
on s1_0.survey_document_id=d1_0.survey_document_id
left join
design d2_0
on s1_0.survey_document_id=d2_0.survey_document_id
where
s1_0.survey_document_id=?
and (
s1_0.is_deleted = 0
)
2023-10-18T00:30:14.584+09:00 INFO 20032 --- [io-8082-exec-10] p6spy : #1697556614584 | took 0ms | statement | connection 22| url jdbc:mysql://localhost:3306/surveydb
select s1_0.survey_document_id,s1_0.accept_response,s1_0.answer_count,d1_0.date_id,d1_0.survey_deadline,d1_0.survey_enable,d1_0.survey_start_date,s1_0.survey_description,d2_0.design_id,d2_0.back_color,d2_0.font,d2_0.font_size,s1_0.is_deleted,s1_0.reliability,s1_0.survey_title,s1_0.survey_type,s1_0.user_id from survey_document s1_0 left join date_management d1_0 on s1_0.survey_document_id=d1_0.survey_document_id left join design d2_0 on s1_0.survey_document_id=d2_0.survey_document_id where s1_0.survey_document_id=? and (s1_0.is_deleted = 0)
select s1_0.survey_document_id,s1_0.accept_response,s1_0.answer_count,d1_0.date_id,d1_0.survey_deadline,d1_0.survey_enable,d1_0.survey_start_date,s1_0.survey_description,d2_0.design_id,d2_0.back_color,d2_0.font,d2_0.font_size,s1_0.is_deleted,s1_0.reliability,s1_0.survey_title,s1_0.survey_type,s1_0.user_id from survey_document s1_0 left join date_management d1_0 on s1_0.survey_document_id=d1_0.survey_document_id left join design d2_0 on s1_0.survey_document_id=d2_0.survey_document_id where s1_0.survey_document_id=4 and (s1_0.is_deleted = 0);
2023-10-18T00:30:14.585+09:00 INFO 20032 --- [io-8082-exec-10] p6spy : #1697556614585 | took 0ms | commit | connection 22| url jdbc:mysql://localhost:3306/surveydb
;
Hibernate:
select
q1_0.survey_document_id,
q1_0.question_document_id,
q1_0.is_deleted,
q1_0.question_type,
q1_0.question_title
from
question_document q1_0
where
q1_0.survey_document_id=?
and (
q1_0.is_deleted = 0
)
2023-10-18T00:30:14.587+09:00 INFO 20032 --- [io-8082-exec-10] p6spy : #1697556614587 | took 0ms | statement | connection 22| url jdbc:mysql://localhost:3306/surveydb
select q1_0.survey_document_id,q1_0.question_document_id,q1_0.is_deleted,q1_0.question_type,q1_0.question_title from question_document q1_0 where q1_0.survey_document_id=? and (q1_0.is_deleted = 0)
select q1_0.survey_document_id,q1_0.question_document_id,q1_0.is_deleted,q1_0.question_type,q1_0.question_title from question_document q1_0 where q1_0.survey_document_id=4 and (q1_0.is_deleted = 0) ;
Hibernate:
select
c1_0.question_id,
c1_0.choice_id,
c1_0.choice_count,
c1_0.is_deleted,
c1_0.choice_title
from
choice c1_0
where
c1_0.question_id in(?,?)
and (
c1_0.is_deleted = 0
)
2023-10-18T00:30:14.591+09:00 INFO 20032 --- [io-8082-exec-10] p6spy : #1697556614591 | took 0ms | statement | connection 22| url jdbc:mysql://localhost:3306/surveydb
select c1_0.question_id,c1_0.choice_id,c1_0.choice_count,c1_0.is_deleted,c1_0.choice_title from choice c1_0 where c1_0.question_id in(?,?) and (c1_0.is_deleted = 0)
select c1_0.question_id,c1_0.choice_id,c1_0.choice_count,c1_0.is_deleted,c1_0.choice_title from choice c1_0 where c1_0.question_id in(14,15) and (c1_0.is_deleted = 0) ;
Hibernate:
select
w1_0.question_id,
w1_0.word_cloud_id,
w1_0.word_cloud_count,
w1_0.is_deleted,
w1_0.word_cloud_title
from
word_cloud w1_0
where
w1_0.question_id in(?,?)
and (
w1_0.is_deleted = 0
)
2023-10-18T00:30:14.601+09:00 INFO 20032 --- [io-8082-exec-10] p6spy : #1697556614601 | took 8ms | statement | connection 22| url jdbc:mysql://localhost:3306/surveydb
select w1_0.question_id,w1_0.word_cloud_id,w1_0.word_cloud_count,w1_0.is_deleted,w1_0.word_cloud_title from word_cloud w1_0 where w1_0.question_id in(?,?) and (w1_0.is_deleted = 0)
select w1_0.question_id,w1_0.word_cloud_id,w1_0.word_cloud_count,w1_0.is_deleted,w1_0.word_cloud_title from word_cloud w1_0 where w1_0.question_id in(14,15) and (w1_0.is_deleted = 0) ;
2023-10-18T00:30:14.601+09:00 INFO 20032 --- [io-8082-exec-10] c.e.s.s.service.SurveyDocumentService : SurveyDetailDto(id=4, title=test2, description=test2, countAnswer=0, questionList=[QuestionDetailDto(id=14, title=test, questionType=1, choiceList=[ChoiceDetailDto(id=15, title=test1, count=0), ChoiceDetailDto(id=16, title=test2, count=0)], wordCloudDtos=[]), QuestionDetailDto(id=15, title=test, questionType=1, choiceList=[ChoiceDetailDto(id=17, title=test3, count=0), ChoiceDetailDto(id=18, title=test4, count=0)], wordCloudDtos=[])], reliability=true, startDate=2023-10-02 00:27:17.1, endDate=2023-10-02 00:27:17.1, enable=true, design=DesignResponseDto(font=font, fontSize=0, backColor=font))

N + 1문제가 완화되었으며 성능 향상도 있다.- 데이터의 크기가 작아서
1.43배 정도 속도가 빨라졌지만 - 데이터의 크기가 커지면 효과는 더 커질 것이다.
- 데이터의 크기가 작아서
fetch join을 1:N 관계에 대해 하나만 사용할 수 있다면(@xxToMany) 쿼리를 두 개로 나누는 방법은 얼마나 최적화 될 지 궁금하였다.
surveydocument와 연관된question들을fetch join으로 가져오는 쿼리 하나- 가져온
question들에 대해서choice들을fetch join으로 가져오는 쿼리 하나 - 총 2 개로 나누었다.
@Override
public SurveyDocument findSurveyById(Long surveyDocumentId) {
SurveyDocument survey = queryFactory
.selectFrom(surveyDocument)
.leftJoin(surveyDocument.design, design).fetchJoin()
.leftJoin(surveyDocument.date, dateManagement).fetchJoin()
.leftJoin(surveyDocument.questionDocumentList, questionDocument).fetchJoin()
.where(surveyDocument.id.eq(surveyDocumentId))
.fetchOne();
if (survey != null && survey.getQuestionDocumentList() != null) {
List<QuestionDocument> questionDocuments = queryFactory
.selectFrom(questionDocument)
.leftJoin(questionDocument.choiceList, choice).fetchJoin()
.where(questionDocument.in(survey.getQuestionDocumentList()))
.fetch();
}
return survey;
}- 그 결과로 쿼리는 총 3번이 나갔다
- 쿼리
Hibernate: select s1_0.survey_document_id, s1_0.accept_response, s1_0.answer_count, d2_0.date_id, d2_0.survey_deadline, d2_0.survey_enable, d2_0.survey_start_date, s1_0.survey_description, d1_0.design_id, d1_0.back_color, d1_0.font, d1_0.font_size, s1_0.is_deleted, q1_0.survey_document_id, q1_0.question_document_id, q1_0.is_deleted, q1_0.question_type, q1_0.question_title, s1_0.reliability, s1_0.survey_title, s1_0.survey_type, s1_0.user_id from survey_document s1_0 left join design d1_0 on s1_0.survey_document_id=d1_0.survey_document_id left join date_management d2_0 on s1_0.survey_document_id=d2_0.survey_document_id left join question_document q1_0 on s1_0.survey_document_id=q1_0.survey_document_id and ( q1_0.is_deleted = 0 ) and ( q1_0.is_deleted = 0 ) where ( s1_0.is_deleted = 0 ) and s1_0.survey_document_id=? 2023-10-18T01:02:28.500+09:00 INFO 12756 --- [io-8082-exec-10] p6spy : #1697558548500 | took 0ms | statement | connection 9| url jdbc:mysql://localhost:3306/surveydb select s1_0.survey_document_id,s1_0.accept_response,s1_0.answer_count,d2_0.date_id,d2_0.survey_deadline,d2_0.survey_enable,d2_0.survey_start_date,s1_0.survey_description,d1_0.design_id,d1_0.back_color,d1_0.font,d1_0.font_size,s1_0.is_deleted,q1_0.survey_document_id,q1_0.question_document_id,q1_0.is_deleted,q1_0.question_type,q1_0.question_title,s1_0.reliability,s1_0.survey_title,s1_0.survey_type,s1_0.user_id from survey_document s1_0 left join design d1_0 on s1_0.survey_document_id=d1_0.survey_document_id left join date_management d2_0 on s1_0.survey_document_id=d2_0.survey_document_id left join question_document q1_0 on s1_0.survey_document_id=q1_0.survey_document_id and (q1_0.is_deleted = 0) and (q1_0.is_deleted = 0) where (s1_0.is_deleted = 0) and s1_0.survey_document_id=? select s1_0.survey_document_id,s1_0.accept_response,s1_0.answer_count,d2_0.date_id,d2_0.survey_deadline,d2_0.survey_enable,d2_0.survey_start_date,s1_0.survey_description,d1_0.design_id,d1_0.back_color,d1_0.font,d1_0.font_size,s1_0.is_deleted,q1_0.survey_document_id,q1_0.question_document_id,q1_0.is_deleted,q1_0.question_type,q1_0.question_title,s1_0.reliability,s1_0.survey_title,s1_0.survey_type,s1_0.user_id from survey_document s1_0 left join design d1_0 on s1_0.survey_document_id=d1_0.survey_document_id left join date_management d2_0 on s1_0.survey_document_id=d2_0.survey_document_id left join question_document q1_0 on s1_0.survey_document_id=q1_0.survey_document_id and (q1_0.is_deleted = 0) and (q1_0.is_deleted = 0) where (s1_0.is_deleted = 0) and s1_0.survey_document_id=4; Hibernate: select q1_0.question_document_id, c1_0.question_id, c1_0.choice_id, c1_0.choice_count, c1_0.is_deleted, c1_0.choice_title, q1_0.is_deleted, q1_0.question_type, q1_0.survey_document_id, q1_0.question_title from question_document q1_0 left join choice c1_0 on q1_0.question_document_id=c1_0.question_id and ( c1_0.is_deleted = 0 ) and ( c1_0.is_deleted = 0 ) where ( q1_0.is_deleted = 0 ) and q1_0.question_document_id in(?,?) 2023-10-18T01:02:28.505+09:00 INFO 12756 --- [io-8082-exec-10] p6spy : #1697558548505 | took 1ms | statement | connection 9| url jdbc:mysql://localhost:3306/surveydb select q1_0.question_document_id,c1_0.question_id,c1_0.choice_id,c1_0.choice_count,c1_0.is_deleted,c1_0.choice_title,q1_0.is_deleted,q1_0.question_type,q1_0.survey_document_id,q1_0.question_title from question_document q1_0 left join choice c1_0 on q1_0.question_document_id=c1_0.question_id and (c1_0.is_deleted = 0) and (c1_0.is_deleted = 0) where (q1_0.is_deleted = 0) and q1_0.question_document_id in(?,?) select q1_0.question_document_id,c1_0.question_id,c1_0.choice_id,c1_0.choice_count,c1_0.is_deleted,c1_0.choice_title,q1_0.is_deleted,q1_0.question_type,q1_0.survey_document_id,q1_0.question_title from question_document q1_0 left join choice c1_0 on q1_0.question_document_id=c1_0.question_id and (c1_0.is_deleted = 0) and (c1_0.is_deleted = 0) where (q1_0.is_deleted = 0) and q1_0.question_document_id in(14,15); Hibernate: select w1_0.question_id, w1_0.word_cloud_id, w1_0.word_cloud_count, w1_0.is_deleted, w1_0.word_cloud_title from word_cloud w1_0 where w1_0.question_id in(?,?) and ( w1_0.is_deleted = 0 ) 2023-10-18T01:02:28.510+09:00 INFO 12756 --- [io-8082-exec-10] p6spy : #1697558548510 | took 1ms | statement | connection 9| url jdbc:mysql://localhost:3306/surveydb select w1_0.question_id,w1_0.word_cloud_id,w1_0.word_cloud_count,w1_0.is_deleted,w1_0.word_cloud_title from word_cloud w1_0 where w1_0.question_id in(?,?) and (w1_0.is_deleted = 0) select w1_0.question_id,w1_0.word_cloud_id,w1_0.word_cloud_count,w1_0.is_deleted,w1_0.word_cloud_title from word_cloud w1_0 where w1_0.question_id in(14,15) and (w1_0.is_deleted = 0) ;
- 쿼리
하지만 두 번째 쿼리 코드를 살펴보면
if (survey != null && survey.getQuestionDocumentList() != null) {
List<QuestionDocument> questionDocuments = queryFactory
.selectFrom(questionDocument)
.leftJoin(questionDocument.choiceList, choice).fetchJoin()
.where(questionDocument.in(survey.getQuestionDocumentList()))
.fetch();
}in 절로 가져오기 때문에 batch_fetch 설정으로 인해 자동으로 생성되는 쿼리와 똑같은 쿼리가 나간다.
즉, 결론을 내리자면
hibernate.default_batch_fetch_size를 글로벌 설정으로 사용해N+1문제를 최대한in쿼리로 기본적인 성능을 보장하게 한다.@OneToOne, @ManyToOne과 같이1관계의 자식 엔티티에 대해서는 모두Fetch Join을 적용하여 한방 쿼리를 수행한다.@OneToMany, @ManyToMany와 같이N관계의 자식 엔티티에 관해서는 가장 데이터가 많은 자식쪽에Fetch Join을 사용한다.Fetch Join이 없는 자식 엔티티에 관해서는 위에서 선언한hibernate.default_batch_fetch_size적용으로100~1000개의in쿼리로 성능을 보장한다.
- 코드 설명
@Override
public SurveyDocument findSurveyById(Long surveyDocumentId) {
// SurveyDocument 조회 시 design, date에 대해서는 fetchJoin을 사용
// questionDocumentList에 대해서도 fetchJoin을 사용하여 한 번의 쿼리로 로딩
SurveyDocument survey = queryFactory
.selectFrom(surveyDocument)
.leftJoin(surveyDocument.design, design).fetchJoin()
.leftJoin(surveyDocument.date, dateManagement).fetchJoin()
.leftJoin(surveyDocument.questionDocumentList, questionDocument).fetchJoin()
.where(surveyDocument.id.eq(surveyDocumentId))
.fetchOne();
return survey;
}
그 후 객체의 값을 사용하기 위해 객체의 프록시를 초기화 할 때, batch_fetch 설정을 통해 자동으로 생긴 in 절로 나머지 @oneToMany 컬렉션들을 가져온다.
- 그 결과로
- 처음 결과: 쿼리 총
6번 (survey, question 1+2, choice1, wordcloud1, choice2, wordcloud2)

batchsize:1000적용: 쿼리 총4번 (survey, question, choice, wordcloud)

- + fetch join 적용: 쿼리 총
3번

- 속도 측면에서 아주 눈에 띄는 차이는 아니지만 처음 결과에 비해 거의 2배 이상 상승한 결과이며 DB에 날리는 쿼리는 1/2로 줄어 들었다. 또한, 데이터의 크기가 커지면 커질 수록 효과는 더욱 더 증가할 것으로 보인다. (여기서는 question 2개, choice 4개인 아주 작은 크기의 설문으로 테스트 하였다)
OneToMany 관계의 entity를 Querydsl로 조회할 때 fetchjoin을 사용하면 데이터가 중복되어 조회될 수 있다.
distinct를 추가하여 중복된 row를 제거할 수 있다. 이는 중복된 로우를 제거하지만, 실제로는 데이터베이스에서 모든 중복된 결과를 가져온 후, 애플리케이션 메모리 내에서 엔티티의 중복을 제거하기 때문에 완전히 중복 조회를 피한다고는 할 수 없다.
@Override
public Optional<SurveyDocument> findSurveyById(Long surveyDocumentId) {
SurveyDocument survey = queryFactory
.selectFrom(surveyDocument)
.leftJoin(surveyDocument.design, design).fetchJoin()
.leftJoin(surveyDocument.date, dateManagement).fetchJoin()
.leftJoin(surveyDocument.questionDocumentList, questionDocument).fetchJoin()
.where(surveyDocument.id.eq(surveyDocumentId))
.distinct()
.fetchOne();
return Optional.ofNullable(survey);
}다른 최적화 방법은?!
여기서 더 최적화 하여 쿼리 한번에 가져오는 방법이 있다.
1. 컬렉션 하나를 Set으로 바꿔 단일 쿼리로 한 번에 fetch join
Hibernate는 List(인덱스 없는 bag) 두 개 이상의 fetch join을 금지하지만,
List(bag) + Set 조합이라면 List 한 개만 bag으로 보기 때문에 두 개 이상의 to‑many라도 한 번에 join 해 올 수 있다.
@Entity
public class QuestionDocument {
// … 기존 …
// 선택지는 Set으로
@OneToMany(mappedBy="questionDocument", fetch=LAZY)
private List<Choice> choiceSet = new HashSet<>();
// 워드클라우드도 Set으로
@OneToMany(mappedBy="questionDocument", fetch=LAZY)
private Set<WordCloud> wordCloudSet = new HashSet<>();
}
// 리포지토리 쿼리
SurveyDocument survey = queryFactory
.selectFrom(surveyDocument)
.leftJoin(surveyDocument.design, design).fetchJoin()
.leftJoin(surveyDocument.date, dateManagement).fetchJoin()
.leftJoin(surveyDocument.questionDocumentList, questionDocument).fetchJoin()
// List<QuestionDocument> 와 Set<Choice> 와 Set<WordCloud> 조합이므로 세 번의 fetchJoin 가능
.leftJoin(questionDocument.choiceSet, choice).fetchJoin()
.leftJoin(questionDocument.wordCloudSet, wordCloud).fetchJoin()
.distinct()
.fetchOne();-> 결과
Hibernate:
select
distinct s1_0.survey_document_id,
s1_0.accept_response,
s1_0.answer_count,
d2_0.date_id,
d2_0.survey_deadline,
d2_0.survey_enable,
d2_0.survey_start_date,
s1_0.survey_description,
d1_0.design_id,
d1_0.back_color,
d1_0.font,
d1_0.font_size,
s1_0.is_deleted,
q1_0.survey_document_id,
q1_0.question_document_id,
c1_0.question_id,
c1_0.choice_id,
c1_0.choice_count,
c1_0.is_deleted,
c1_0.choice_title,
q1_0.is_deleted,
q1_0.question_type,
q1_0.question_title,
w1_0.question_id,
w1_0.word_cloud_id,
w1_0.word_cloud_count,
w1_0.is_deleted,
w1_0.word_cloud_title,
s1_0.reliability,
s1_0.survey_title,
s1_0.survey_type,
s1_0.user_id
from
survey_document s1_0
left join
design d1_0
on s1_0.survey_document_id=d1_0.survey_document_id
left join
date_management d2_0
on s1_0.survey_document_id=d2_0.survey_document_id
left join
question_document q1_0
on s1_0.survey_document_id=q1_0.survey_document_id
and (
q1_0.is_deleted = 0
)
and (
q1_0.is_deleted = 0
)
left join
choice c1_0
on q1_0.question_document_id=c1_0.question_id
and (
c1_0.is_deleted = 0
)
and (
c1_0.is_deleted = 0
)
left join
word_cloud w1_0
on q1_0.question_document_id=w1_0.question_id
and (
w1_0.is_deleted = 0
)
and (
w1_0.is_deleted = 0
)
where
(
s1_0.is_deleted = 0
)
and s1_0.survey_document_id=?→ 단 한 번의 SQL로 설문 + 질문 + 선택지 + 워드클라우드까지 모두 조회된다.
하지만 나의 경우 각 질문의 선택지 또한 순서가 중요하기 때문에 선택지는 in 절로 추후 가져오도록 해서 쿼리를 총 2번 나가게 해야 했다.
2. @EntityGraph로 별도 쿼리 없이 깔끔하게 가져오기
Spring Data JPA의 @EntityGraph를 쓰면, JPA 구현체(Most Hibernate)가 to‑many 관계를 별도 SELECT(batch or subselect)로 가져오도록 처리해 주기 때문에 코드엔 쿼리 한 줄만 남고, 내부적으로는 N+1 없이 최적화 로드가 된다.
public interface SurveyDocumentRepository extends JpaRepository<SurveyDocument, Long> {
@EntityGraph(attributePaths = {
"design",
"date",
"questionDocumentList",
"questionDocumentList.choiceList",
"questionDocumentList.wordCloudList"
})
@Query("SELECT s FROM SurveyDocument s WHERE s.id = :id")
Optional<SurveyDocument> findOneWithAll(Long id);
}
위 메서드를 호출만 하면, Hibernate가
- 설문 + 1:1 관계(조인)
- questionDocumentList 배치 페치(단일 IN‑쿼리)
- choiceList 배치 페치
- wordCloudList 배치 페치
순으로 최적화된 쿼리(join + subselect)들을 자동으로 실행해 준다.
하지만 여전히 쿼리가 여러 번(3번) 나가며 배치 페치 설정 의존성에 가진다.
3. QueryDSL DTO 프로젝션으로 한 번에 조회
엔티티가 아니라 DTO 형태로 직접 설문 ▶ 질문 ▶ 선택지 ▶ 워드클라우드를 조인해서 꺼내면,
-
필요한 데이터만 쿼리에 담고
-
애플리케이션 레벨에서 그룹핑만 하면 돼서
-
전체 fetch 로직이 한 메서드 안에 깔끔히 모인다.
List<SurveyDetailDto> rows = queryFactory
.select(new QSurveyDetailDto(
surveyDocument.id,
surveyDocument.title,
questionDocument.id,
questionDocument.title,
choice.id,
choice.choiceTitle,
wordCloud.wordCloudId,
wordCloud.wordCloudTitle
))
.from(surveyDocument)
.leftJoin(surveyDocument.questionDocumentList, questionDocument)
.leftJoin(questionDocument.choiceList, choice)
.leftJoin(questionDocument.wordCloudList, wordCloud)
.where(surveyDocument.id.eq(surveyDocumentId))
.fetch();
// 그 후 Java 스트림으로 question별로 groupBy 해서 SurveyDetailDto 구조로 가공이렇게 하면 SQL은 한 번만 나가고,
애플리케이션에서 간단히 groupBy(questionId)만 해 주면 끝이다.
이 방법의 장점은,
-
쿼리 수: 1번
-
가져오는 컬럼만 정확히 지정 → 네트워크/DB I/O 최소화
-
객체 매핑 비용: DTO로 바로 바인딩 → 불필요한 엔티티 관리 오버헤드 없음
하지만 언제나 장점만 있는 방법은 없듯이 단점이 존재한다.
-
DTO 변경 시 Q 클래스(어노테이션)·프로젝션도 함께 수정해야 한다.
-
복잡한 컬렉션 구조(Grouping) 로직을 Java 쪽에서 직접 작성해야 한다.
설문 관리 조회 DTO로 바로 조회 - @QueryProjection
- 설문 관리 조회에서 필요한 데이터는 단 3개이다.
{
"startDate": "2023-10-01T15:27:17.100+00:00",
"endDate": "2023-10-01T15:27:17.100+00:00",
"enable": true
}- 하지만 사용되는 쿼리는 survey의 모든 정보를 쿼리하고 있다
Hibernate:
select
s1_0.survey_document_id,
s1_0.accept_response,
s1_0.answer_count,
d1_0.date_id,
d1_0.survey_deadline,
d1_0.survey_enable,
d1_0.survey_start_date,
s1_0.survey_description,
d2_0.design_id,
d2_0.back_color,
d2_0.font,
d2_0.font_size,
s1_0.is_deleted,
s1_0.reliability,
s1_0.survey_title,
s1_0.survey_type,
s1_0.user_id
from
survey_document s1_0
left join
date_management d1_0
on s1_0.survey_document_id=d1_0.survey_document_id
left join
design d2_0
on s1_0.survey_document_id=d2_0.survey_document_id
where
s1_0.survey_document_id=?
and (
s1_0.is_deleted = 0
)
2023-10-18T01:53:55.051+09:00 INFO 19692 --- [io-8082-exec-10] p6spy : #1697561635051 | took 1ms | statement | connection 22| url jdbc:mysql://localhost:3306/surveydb
select s1_0.survey_document_id,s1_0.accept_response,s1_0.answer_count,d1_0.date_id,d1_0.survey_deadline,d1_0.survey_enable,d1_0.survey_start_date,s1_0.survey_description,d2_0.design_id,d2_0.back_color,d2_0.font,d2_0.font_size,s1_0.is_deleted,s1_0.reliability,s1_0.survey_title,s1_0.survey_type,s1_0.user_id from survey_document s1_0 left join date_management d1_0 on s1_0.survey_document_id=d1_0.survey_document_id left join design d2_0 on s1_0.survey_document_id=d2_0.survey_document_id where s1_0.survey_document_id=? and (s1_0.is_deleted = 0)
select s1_0.survey_document_id,s1_0.accept_response,s1_0.answer_count,d1_0.date_id,d1_0.survey_deadline,d1_0.survey_enable,d1_0.survey_start_date,s1_0.survey_description,d2_0.design_id,d2_0.back_color,d2_0.font,d2_0.font_size,s1_0.is_deleted,s1_0.reliability,s1_0.survey_title,s1_0.survey_type,s1_0.user_id from survey_document s1_0 left join date_management d1_0 on s1_0.survey_document_id=d1_0.survey_document_id left join design d2_0 on s1_0.survey_document_id=d2_0.survey_document_id where s1_0.survey_document_id=4 and (s1_0.is_deleted = 0);
2023-10-18T01:53:55.067+09:00 INFO 19692 --- [io-8082-exec-10] p6spy-
사용되는 코드가 db에서
findById로 설문을 조회하고 거기서 필요한 데이터 3개를 뽑아서DTO에 넣어서 반환하고 있었다. -
이 코드를 최적화 하기 위해 db에서 바로
dto로 조회하는 방법으로 수정할 것이다. -
이 방법은 컴파일러로 타입을 체크할 수 있으므로 가장 안전한 방법이다.
-
다만
DTO에QueryDSL어노테이션을 유지해야 하는 점과DTO까지Q 파일을 생성해야 하는 단점이 있다. -
QueryDsl수정
@Override
public ManagementResponseDto findManageById(Long surveyDocumentId) {
return queryFactory.select(new QManagementResponseDto(dateManagement.startDate, dateManagement.deadline, dateManagement.isEnabled))
.from(dateManagement)
.where(dateManagement.surveyDocument.id.eq(surveyDocumentId))
.fetchOne();
}- 쿼리 결과
Hibernate:
select
d1_0.survey_start_date,
d1_0.survey_deadline,
d1_0.survey_enable
from
date_management d1_0
where
d1_0.survey_document_id=?- 한 눈에 봐도 쿼리의 길이가 확연히 줄어든 것을 볼 수 있다.
설문 활성화/비활성화 수정 쿼리 - 직접 업데이트 쿼리
-
설문의 활성/비활성화는
survey에 연결된DateManagement의is Enabled만 바꿔주면 된다. -
하지만 지금은 불필요하게 많은 데이터를 가져와서
update를 해주고 있다. -
보통 JPA 사용 시 엔티티를 먼저 조회(
fetch)한 후, 해당 엔티티의 상태를 변경하고 트랜잭션 커밋 시점에서 변경 감지(dirty checking)를 통해SQL Update문이 실행되는 방식을 사용한다. -
하지만 이 경우, 불필요하게 엔티티를 메모리에 로딩하는 상황이 발생할 수 있다. 특히, 엔티티가 복잡하거나 연관 관계가 많은 경우에는 성능 저하의 원인이 될 수 있다.
-
수정 전 조회 쿼리
Hibernate:
select
s1_0.survey_document_id,
s1_0.accept_response,
s1_0.answer_count,
d1_0.date_id,
d1_0.survey_deadline,
d1_0.survey_enable,
d1_0.survey_start_date,
s1_0.survey_description,
d2_0.design_id,
d2_0.back_color,
d2_0.font,
d2_0.font_size,
s1_0.is_deleted,
s1_0.reliability,
s1_0.survey_title,
s1_0.survey_type,
s1_0.user_id
from
survey_document s1_0
left join
date_management d1_0
on s1_0.survey_document_id=d1_0.survey_document_id
left join
design d2_0
on s1_0.survey_document_id=d2_0.survey_document_id
where
s1_0.survey_document_id=?
and (
s1_0.is_deleted = 0
)
2023-10-18T02:32:54.241+09:00 INFO 3588 --- [nio-8082-exec-1] p6spy : #1697563974241 | took 1ms | statement | connection 9| url jdbc:mysql://localhost:3306/surveydb
select s1_0.survey_document_id,s1_0.accept_response,s1_0.answer_count,d1_0.date_id,d1_0.survey_deadline,d1_0.survey_enable,d1_0.survey_start_date,s1_0.survey_description,d2_0.design_id,d2_0.back_color,d2_0.font,d2_0.font_size,s1_0.is_deleted,s1_0.reliability,s1_0.survey_title,s1_0.survey_type,s1_0.user_id from survey_document s1_0 left join date_management d1_0 on s1_0.survey_document_id=d1_0.survey_document_id left join design d2_0 on s1_0.survey_document_id=d2_0.survey_document_id where s1_0.survey_document_id=? and (s1_0.is_deleted = 0)
select s1_0.survey_document_id,s1_0.accept_response,s1_0.answer_count,d1_0.date_id,d1_0.survey_deadline,d1_0.survey_enable,d1_0.survey_start_date,s1_0.survey_description,d2_0.design_id,d2_0.back_color,d2_0.font,d2_0.font_size,s1_0.is_deleted,s1_0.reliability,s1_0.survey_title,s1_0.survey_type,s1_0.user_id from survey_document s1_0 left join date_management d1_0 on s1_0.survey_document_id=d1_0.survey_document_id left join design d2_0 on s1_0.survey_document_id=d2_0.survey_document_id where s1_0.survey_document_id=4 and (s1_0.is_deleted = 0);
Hibernate:
update
date_management
set
survey_deadline=?,
survey_enable=?,
survey_start_date=?,
survey_document_id=?
where
date_id=?
2023-10-18T02:32:54.244+09:00 INFO 3588 --- [nio-8082-exec-1] p6spy : #1697563974244 | took 1ms | statement | connection 9| url jdbc:mysql://localhost:3306/surveydb
update date_management set survey_deadline=?, survey_enable=?, survey_start_date=?, survey_document_id=? where date_id=?
update date_management set survey_deadline='2023-10-02T00:27:17.100+0900', survey_enable=true, survey_start_date='2023-10-02T00:27:17.100+0900', survey_document_id=4 where date_id=7;
2023-10-18T02:32:54.290+09:00 INFO 3588 --- [nio-8082-exec-1] p6spy : #1697563974290 | took 44ms | commit | connection 9| url jdbc:mysql://localhost:3306/surveydb- Querydsl를 사용하여 데이터베이스에 직접적으로 업데이트 쿼리를 실행하도록 최적화를 해주었다.
@Override
@Transactional
public void updateManage(Long id, Boolean enable) {
queryFactory.update(dateManagement)
.where(dateManagement.surveyDocument.id.eq(id))
.set(dateManagement.isEnabled, enable)
.execute();
}- 수정 후 쿼리
Hibernate:
update
date_management
set
survey_enable=?
where
survey_document_id=?
2023-10-18T02:45:33.646+09:00 INFO 16500 --- [nio-8082-exec-3] p6spy : #1697564733646 | took 1ms | statement | connection 17| url jdbc:mysql://localhost:3306/surveydb
update date_management set survey_enable=? where survey_document_id=?
update date_management set survey_enable=true where survey_document_id=4;- 쿼리의 길이는 매우 많이 줄어들었다.
- 더티 체크를 사용하지 않았으므로
select로 불필요한 정보를 가져올 필요도 없어졌다. Querydsl의update메서드를 사용하여, 필요한 엔티티의 상태만을 직접 변경하는 방식을 채택하였다.- 이는 불필요한 엔티티 로딩을 방지하고, 데이터베이스 차원에서 즉시 업데이트를 수행함으로써 성능을 향상시키는 효과가 있다.
