컬렉션 프레임워크 - List
[JAVA 공부] - 김영한의 자바 중급 2편

'김영한의 실전 자바 - 중급 2편' 강의를 들으면서 복습할만한 내용을 정리하였다.
5. 컬렉션 프레임워크 - List
5.1 리스트 추상화1 - 인터페이스 도입
다형성과 OCP 원칙을 가장 잘 활용할 수 있는 곳 중에 하나가 바로 자료 구조이다.
List 자료 구조
순서가 있고, 중복을 허용하는 자료 구조를 리스트(List)라 한다.
직접 구현한 MyArrayList, MyLinkedList 는 내부 구현만 다를 뿐 같은 기능을 제공하는 리스트이다. 물론 내부 구현이 다르기 때문에 상황에 따라 성능은 달라질 수 있다. 핵심은 사용자 입장에서 보면 같은 기능을 제공한다는 것이다.
이 둘의 공통 기능을 인터페이스로 뽑아서 추상화하면 다형성을 활용한 다양한 이득을 얻을 수 있다.
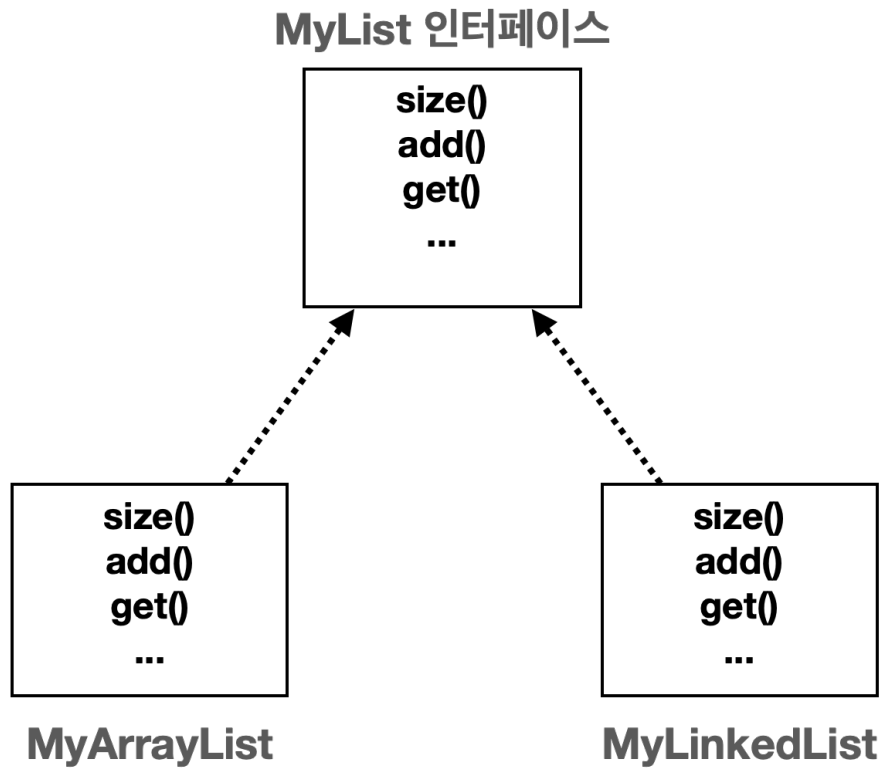
5.2 리스트 추상화2 - 의존관계 주입
컬렉션 프레임워크 - ArrayList와컬렉션 프레임워크 - LinkedList의 글에서는 데이터를 앞에서 추가하거나 삭제할 때 MyArrayList 보다 MyLinkedList 가 O(1)로 더 좋은 성능을 낸다고 하였다.
만약 리스트의 앞에 반복적으로 데이터를 추가하는 코드가 MyArrayList 를 사용하고 있다고 가정해보자.
public class BatchProcessor {
private final MyArrayList<Integer> list = new MyArrayList<>(); //코드 변경
public void logic(int size) {
for (int i = 0; i < size; i++) {
list.add(0, i); //앞에 추가
}
}
}위의 코드는 리스트의 앞에 반복적으로 데이터를 추가하므로 MyLinkedList 를 사용하는 것이 효율적이므로 코드를 변경해야 한다. 이 경우 리스트를 사용하는 코드의 주체(클라이언트)인 BatchProcessor 의 내부 코드도 변경해야 한다.
이러한 경우를 BatchProcessor는 구체적인 클래스에 의존한다고 표현한다. 이렇게 직접적인 클래스에 직접 의존하면 MyArrayList를 MyLinkedList로 변경할 때 마다 BatchProcessor(클라이언트)의 코드를 변경해야 한다.
OCP 원칙을 지키기 위해 BatchProcessor 가 구체적인 클래스에 의존하는 대신 추상적인 MyList 인터페이스를 의존하게 한다.
public class BatchProcessor {
private final MyList<Integer> list;
public BatchProcessor(MyList<Integer> list) {
this.list = list;
}
public void logic(int size) {
for (int i = 0; i < size; i++) {
list.add(0, i); //앞에 추가
}
}
}main() {
new BatchProcessor(new MyArrayList()); //MyArrayList를 사용하고 싶을 때
new BatchProcessor(new MyLinkedList()); //MyLinkedList를 사용하고 싶을 때
}위의 코드 변경을 통해 MyList 를 사용하는 클라이언트 코드인 BatchProcessor 를 전혀 변경하지 않고, 원하는 리스트 전략을 런타임에 지정할 수 있다.
의존관계 주입
Dependency Injection, 줄여서 DI라고 부른다. 의존성 주입이라고도 부른다.
public BatchProcessor(MyList<Integer> list) {
this.list = list;
}BatchProcessor의 생성자에MyArrayList와MyLinkedList중 사용할 리스트 전략을 결정해서 넘겨야 한다.- 이렇게 생성자를 통해 런타임 의존관계를 주입하는 것을 생성자 의존관계 주입 또는 생성자 주입 이라 한다.
5.3 리스트 추상화3 - 컴파일 타임, 런타임 의존관계
- 컴파일 타임(complie time) : 코드 컴파일 시점을 뜻한다.
- 런타임(runtime) : 프로그램 실행 시점을 뜻한다.
컴파일 타임 의존관계 vs 런타임 의존관계
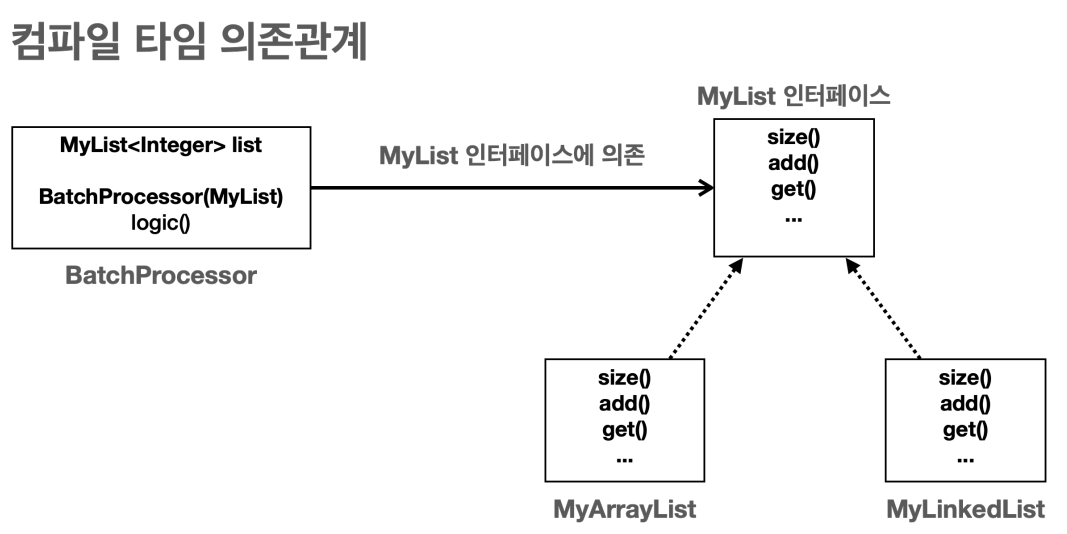
- 컴파일 타임 의존관계는 자바 컴파일러가 보는 의존관계이다. 클래스에 모든 의존관계가 다 나타난다.
- 클래스에 바로 보이는 의존관계이다. 그리고 실행하지 않은 소스 코드에 정적으로 나타나는 의존관계이다.
BatchProcessor클래스는MyList인터페이스만 사용한다. 코드 어디에도MyArrayList와MyLinkedList에 대한 정보는 보이지 않는다.
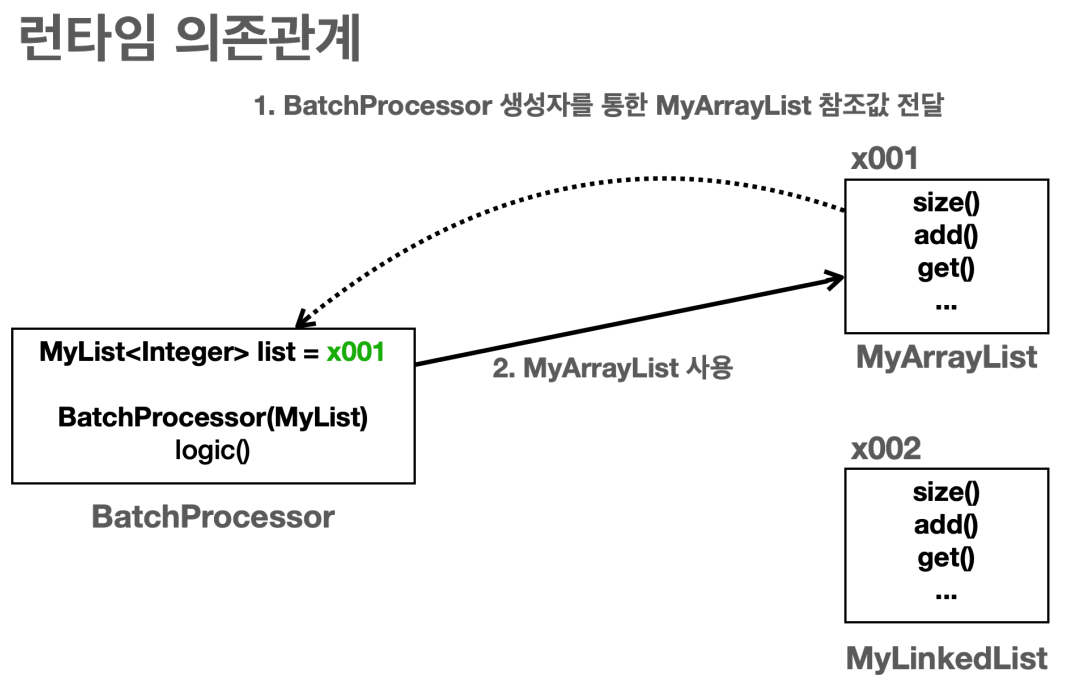
- 런타임 의존관계는 실제 프로그램이 작동할 때 보이는 의존관계이다. 주로 생성된 인스턴스와 그것을 참조하는 의존관계이다.
- 인스턴스 간에 의존관계로 보면 된다.
- 런타임 의존관계는 프로그램 실행 중에 계속 변할 수 있다.
클라이언트 클래스는 컴파일 타임에 추상적인 것에 의존하고, 런타임에 의존관계 주입을 통해 구현체를 주입받아 사용함으로써, OCP 원칙을 지켰다. 클라이언트 코드의 변경 없이, 인터페이스의 구현을 자유롭게 확장할 수 있다.
5.4 자바 리스트
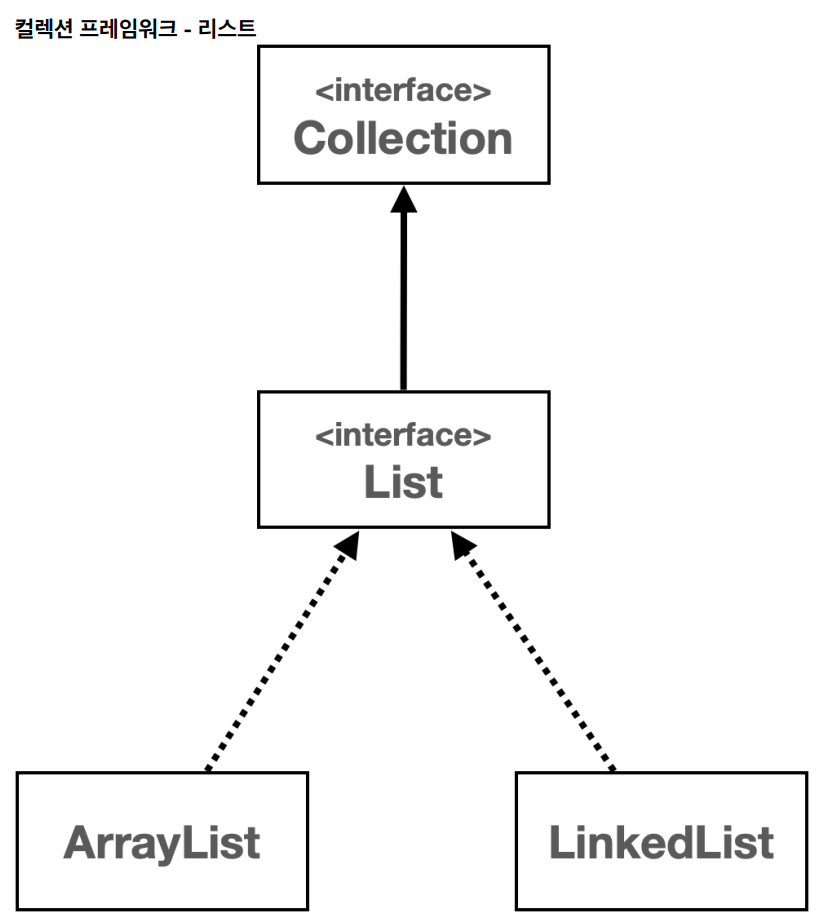
Collection 인터페이스
Collection 인터페이스는 java.util 패키지의 컬렉션 프레임워크의 핵심 인터페이스 중 하나이다. 이 인터페이스는 자바에서 다양한 컬렉션, 즉 데이터 그룹을 다루기 위한 메서드를 정의한다. Collection 인터페이스는 List, Set, Queue 와 같은 다양한 하위 인터페이스와 함께 사용되며, 이를 통해 데이터를 리스트, 세트, 큐 등의 형태로 관리할 수 있다.
List 인터페이스
List 인터페이스는 java.util 패키지에 있는 컬렉션 프레임워크의 일부이다. List 는 객체들의 순서가 있는 컬렉션을 나타내며, 같은 객체의 중복 저장을 허용한다. 이 리스트는 배열과 비슷하지만, 크기가 동적으로 변화하는 컬렉션을 다룰 때 유연하게 사용할 수 있다.
자바 ArrayList
java.util.ArrayList
특징
-
배열을 사용해서 데이터를 관리한다.
-
기본
CAPACITY는 10이다.CAPACITY를 넘어가면 배열을 50% 증가시킨다.
-
메모리 고속 복사 연산을 사용한다.
-
ArrayList의 중간 위치에 데이터를 추가하면, 추가할 위치 이후의 모든 요소를 모두 한 칸씩 뒤로 이동시켜야 한다. -
자바가 제공하는
ArrayList는 이 부분을 최적화 하는데, 배열 요소 이동은 시스템 레벨에서 최적화된 메로리 고속 복사 연산을 사용해서 비교적 빠르게 수행된다. 참고로System.arraycopy()를 사용한다.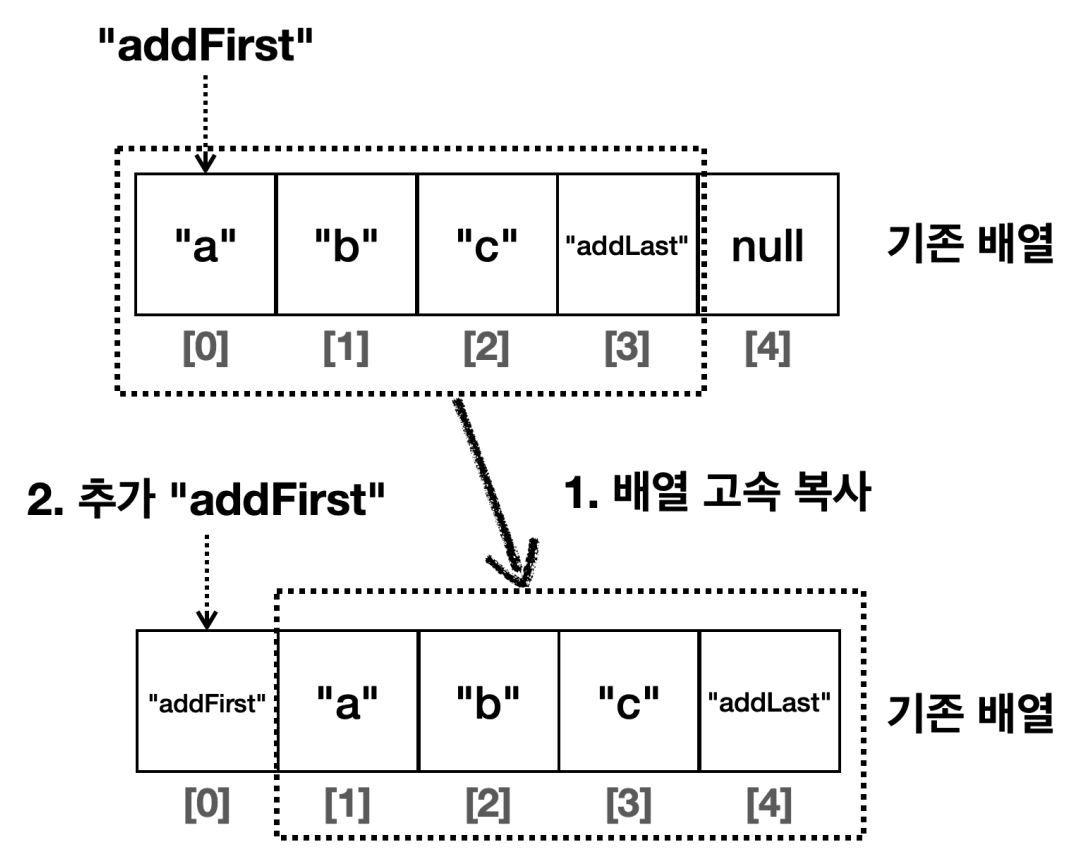
자바 LinkedList
java.util.LinkedList
특징
-
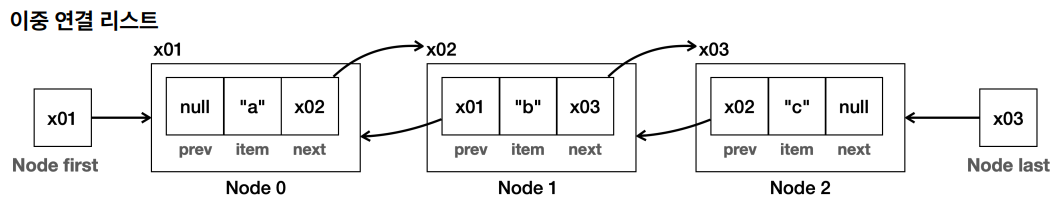
이중 연결 리스트
-
첫 번째 노드와 마지막 노드 둘다 참조
5.5 자바 리스트 성능 비교
| 기능 | 배열 리스트 | 연결 리스트 |
|---|---|---|
| 앞에 추가(삭제) | O(n) - 106ms | O(1) - 2ms |
| 평균 추가(삭제) | O(n) - 49ms | O(n) - 1116ms |
| 뒤에 추가(삭제) | O(1) - 1ms | O(1) - 2ms |
| 인덱스 조회 | O(1) - 1ms | O(n) - 493ms |
| 검색 | O(n) - 104ms | O(n) - 473ms |
위의 성능 비교 표를 보면 이상한 점이 있을 것이다.
데이터를 추가할 때 자바 ArrayList가 직접 구현한 MyArrayList보다 빠른 이유
- 자바의 배열 리스트는 이때 메모리 고속 복사를 사용하기 떄문에 성능이 최적화된다.
- 메모리 고속 복사는 시스템에 따라 성능이 다르기 때문에 정확한 계산은 어렵지만 대략
O(n/10)정도로 추정하자. 하지만 메모리 고속 복사라도 데이터가 아주 많으면 느려진다.
시간 복잡도와 실제 성능
- 이론적으로
LinkedList의 중간 삽입 연산은ArrayList보다 빠를 수 있다. 그러나 실제 성능은 데이터 순차적 접근 속도, 메모리 할당 및 해제 비용, CPU 캐시 활용도 등 다양한 요소에 의해 영향을 받는다.- 추가로
ArrayList는 데이터를 한 칸씩 이동시키지 않고, 메모리 고속 복사 연산을 사용한다.
- 추가로
ArrayList는 배열을 사용하기 때문에 데이터들이 메모리 상에 연속적으로 위치하여 CPU 캐시 효율이 좋고, 메모리 접근 속다가 빠르다.- 반면,
LinkedList는 각 요소가 별도의 객체로 존재하고 다음 요소의 참조를 저장하기 때문에 CPU 캐시 효율이 떨어지고, 메모리 접근 속도가 상대적으로 느려질 수 있다. ArrayList의 경우CAPACITY를 넘어서면 배열을 다시 만들고 복사하는 과정이 추가된다. 하지만 한번에 50%씩 늘어나기 때문에 이 과정은 자주 발생하지 않고, 전체 성능에 큰 영향을 주지 않는다.
정리하면 이론적으로는 LinkedList가 중간 삽입에 있어 더 효율적일 수 있지만, 여러가지 요소에 의해 ArrayList 가 실제 사용 환경에서 더 나은 성능을 보여주는 경우가 많다.
이러한 이유로 실무에서는 주로 배열 리스트를 기본으로 사용한다. 만약 많은 데이터를 앞쪽에서 반복적으로 추가/삭제 하는 일이 많다면 연결 리스트를 고려하자.
