Preview
AMBA : Advanced Microcontroller Bus Architecture
- On-chip interconnect spcification
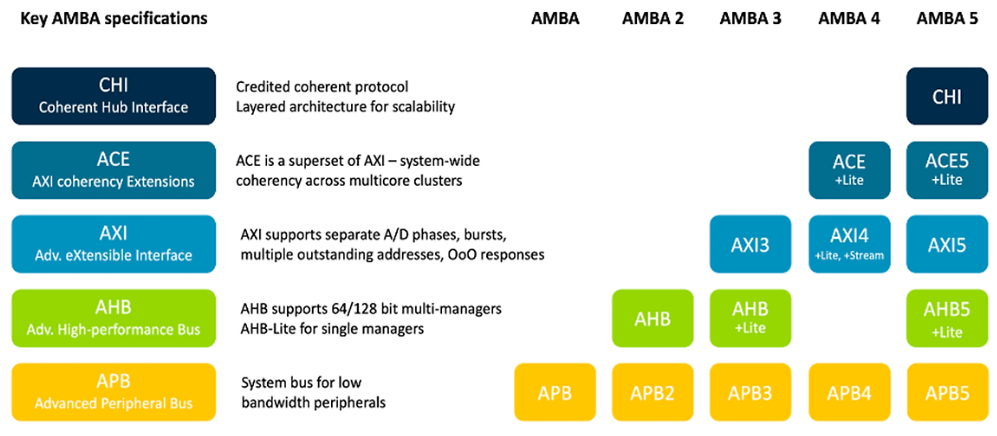
APB : 가장 simple 한 I/F. Area 에 이득이 있음. AXI4-Lite와 비슷
AHB : 요새 잘 안 씀. Transaction할 때 Bus에 Lock을 걸어버림.
AHB5 : TrustZone 지원
CHI : ARM Core 의 coherent 기능에 주로 사용AXI : high data bandwidth, high frequency
- AXI3 vs AXI4
| 구분 | AXI3 | AXI4 |
|---|---|---|
| Max burst length | 16 beats | 256 beats |
| Write interleaving | Support | Not Support |
| Locked transfers | Support | Not Support |
| QoS | Not Support | Support |
USER signals | Not Support | Support |
REGION | Not Support | Support |
WID | Support | Not Support |
beats : burst 내의 개별 전송되는 데이터
burst : 연속된 데이터 전송
USERsignals : sideband signals그 외 : 추후 설명
AXI4 Channels
Terminology
| AXI4 R/W Channels |
|---|
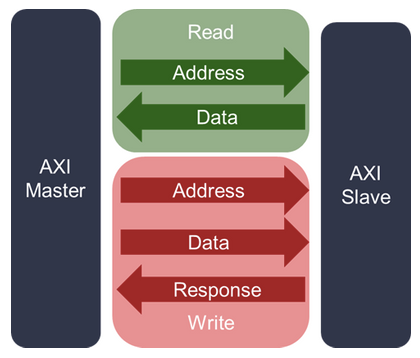 |
Channel : ready-valid + payload(data) signals 로 구성 된 것. 단방향 전송
Transfer : channel 을 통한(Ready-Valid Handshake 한 번의) data 전송 과정
Transaction : Read / Write 자체를 의미(Transfer 전체)AWxxx : Write Address Channel
ARxxx : Read Address Channel
Wxxx : Write Data Channel
Rxxx : Read Data Channel
Bxxx : Write Response ChannelxxADDR : Address signals
xDATA : Data signals
xVALID : Valid signals
xREADY : Ready signals
AXI4-Lite
IP Status 확인, Control
(register R/W 용)
MMIO(Memory-mapped I/O)
가상 메모리를 만들고, 주변 장치를 해당 메모리에 주소로 지정하여 접근 하는 동작 방식.
주변 장치를 접근하기 위해 CPU는 Load, Store와 같은 메모리 접근 방식으로 I/O 제어 가능
OS가 설정하므로, Kernel level(I/O나 kernel data, text(=program) 등이 있는 영역),
User level(IP 등)로 나누어서 맵핑한다.
ARM 계열이 주로 사용(RISC)
PMIO(Port-mapped I/O)
메모리와 주변장치 접근을 위한 Address 가 분리 되어 있음.
Address decoding을 안해도 되기 때문에 접근을 위한 HW 복잡도는 낮은 편
접근을 위한 특별한 Instruction이 필요하므로 CPU 설계 복잡도는 증가.
Intel Process 계열이 주로 사용(CISC)
AXI4-Lite Read Transaction
| AXI4-Lite의 Read Timing diagram |
|---|
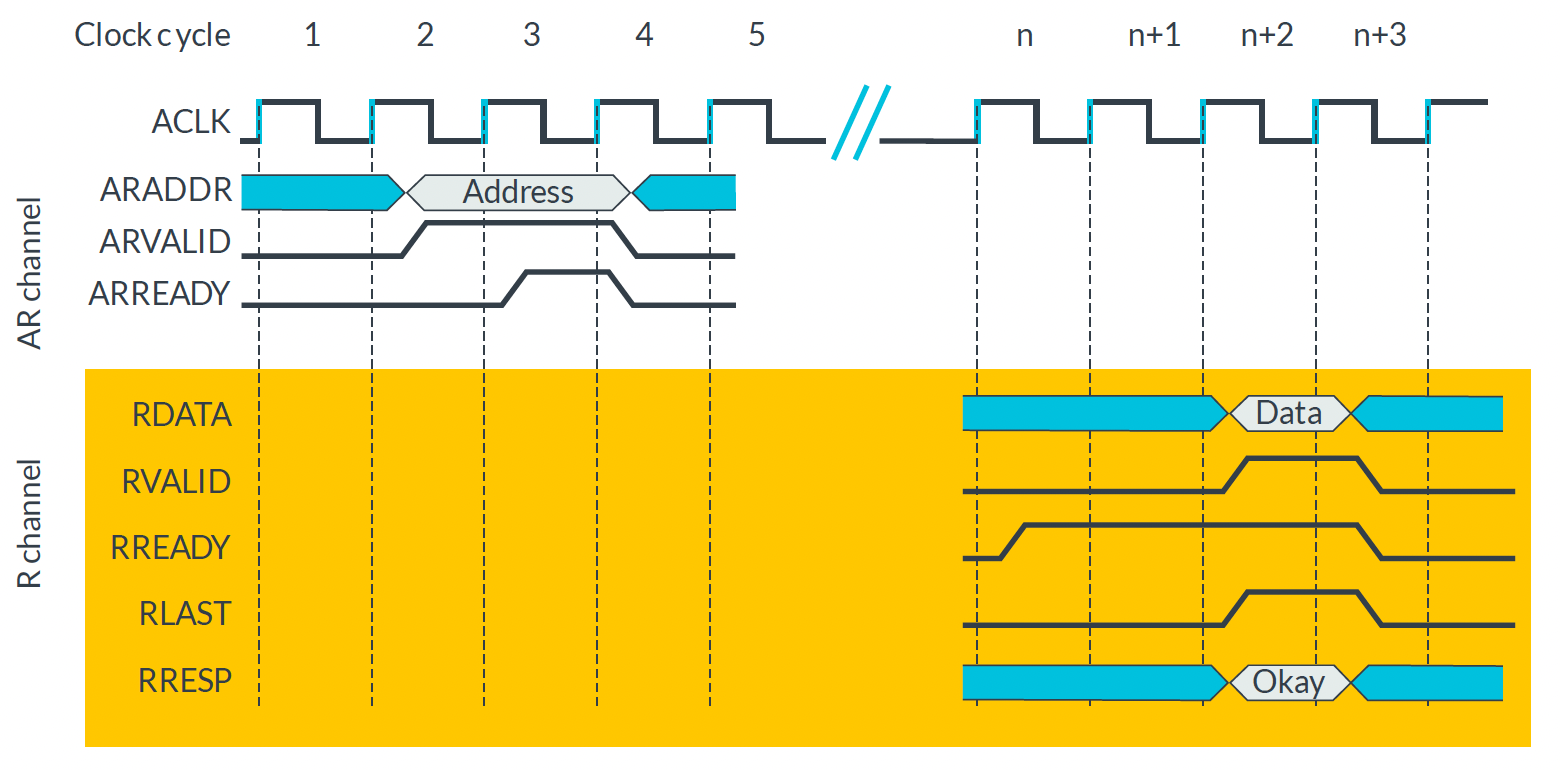 |
Read의 경우, R channel에
RESP가 같이 실려 가는 것을 볼 수 있다.
즉, Read에서는 response를 위한 별도의 행위(channel)이 필요 없다.
| Read transaction dependencies |
|---|
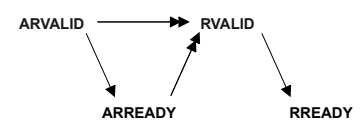 |
머리가 한 개인 화살표 : rule, 꼭 따라야 하는건 아님
머리가 두 개인 화살표 : dependency, 무조건 선행 되어야 함즉,
RVALID(Read Data Channel의 VALID signal) 전에 무조건
AR(Read Address Channel)의 Ready-Valid handshake가 선행 되어야 한다.
- 쉽게 말하면, Read 행위는 Data 보내기 전에 Address를 줘야 한다. ← 당연한 소리
- 또한, Ready와 Valid 사이에는 dependency가 없다.
(rule에는 ready가 valid를 보고 띄울 수 있다고 되어 있으나)- 만약 Ready-Valid handshake에서 Ready 가 asserted 되는 거 보고 Valid를 assert 시키게 설계하면 deadlock에 걸릴 수도 있다.
- 검증은 그냥 ready가 먼저 뜰 때, valid가 먼저 뜰 때, 둘이 동시에 뜰 때.
이 세 가지 확인하면 된다.
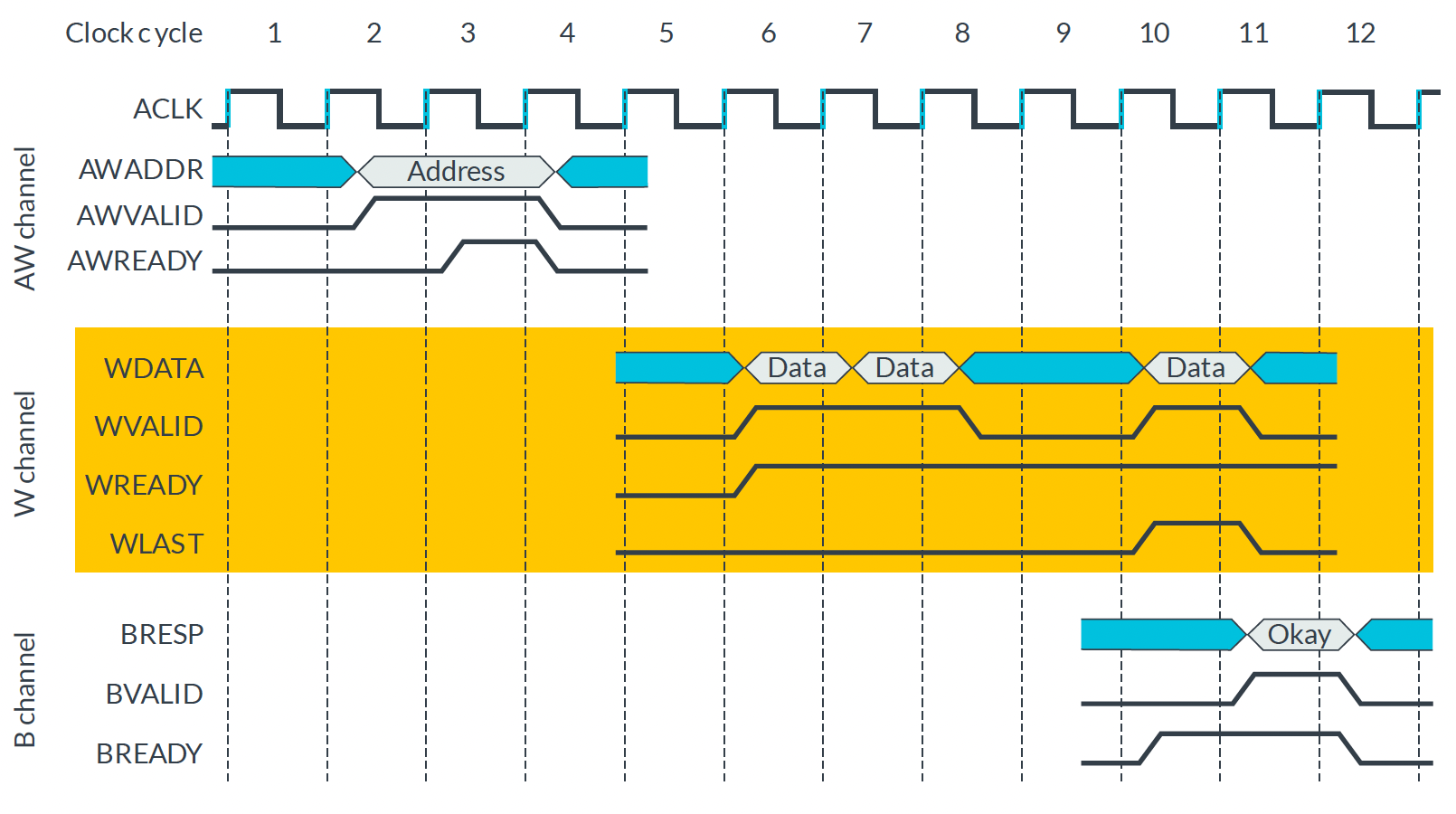
AXI4-Lite Write Transaction
| AXI4-Lite의 Write Timing diagram |
|---|
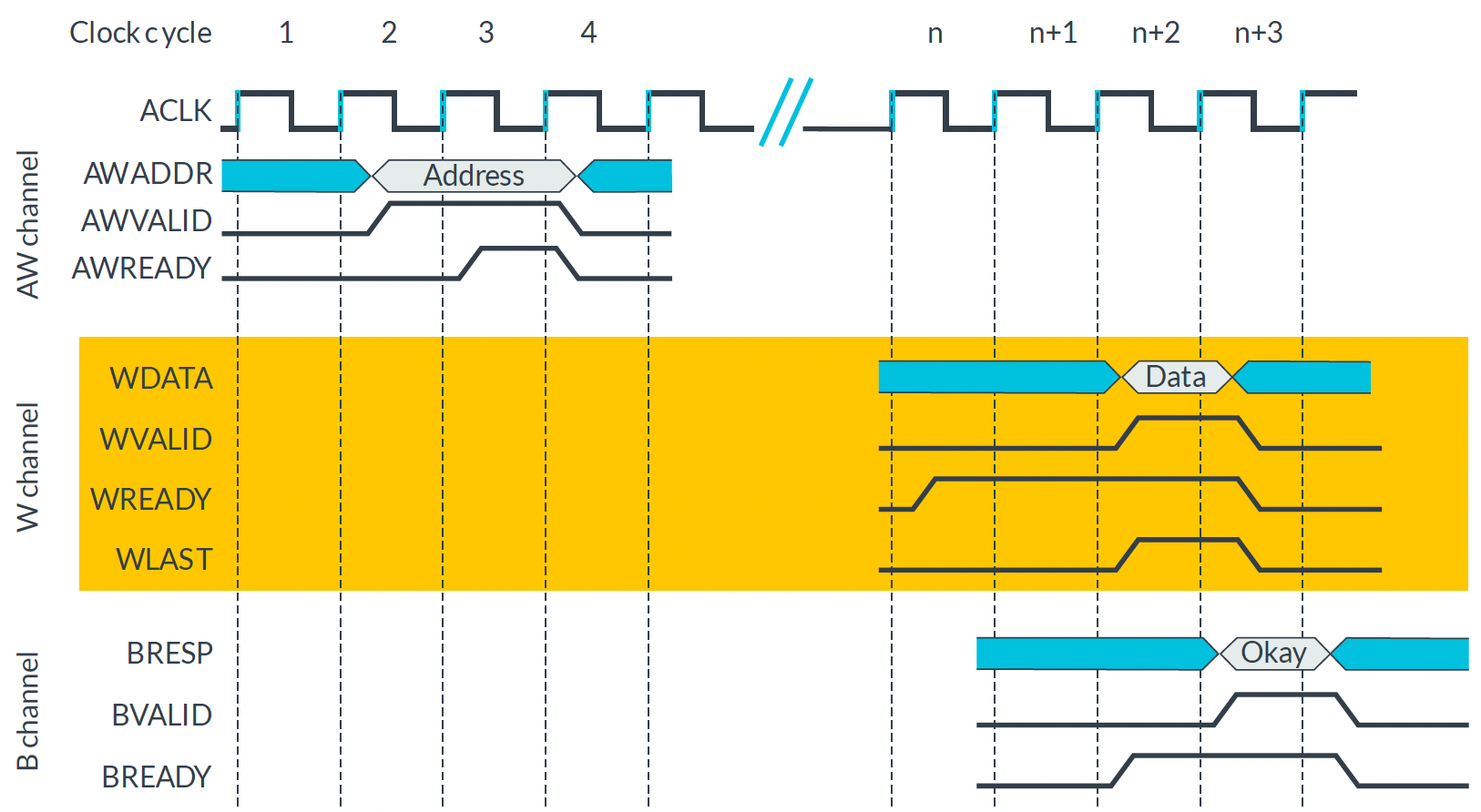 |
Response Channel 이 B 인 이유 : 항상 Slave가 준 데이터에 대한 응답을 해야 하므로 버퍼링이 걸린 것과 같아서 B(buffering) 이라고 함
| Write transaction dependencies |
|---|
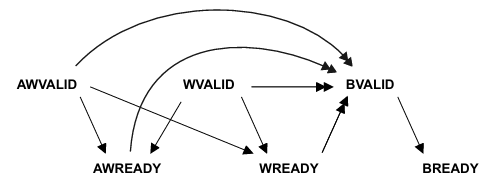 |
Write Transaction의 특징은 W Channel과 AW Channel 간의 화살표 머리가 한 개인 점이다.
즉, W(Write Data) Channel이 handshake 하기 전에 AW(Write Address) Channel이 handshake 할 필요가 없다.따라서 검증 할 때,
WDATA쏴주는 clock을 위의 그림처럼 뒤로 할 것이 아니라AWADDR과 동시에,
그 전에도 해야 하는 case를 작성해야 한다.
AXI4-Stream
단방향 1대 1 통신
고효율 Data 전송
AXI4-Stream Channels
| Stream transaction |
|---|
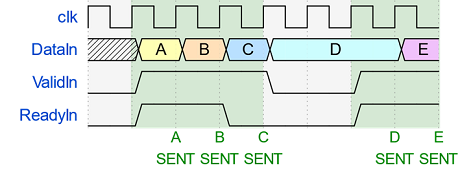 |
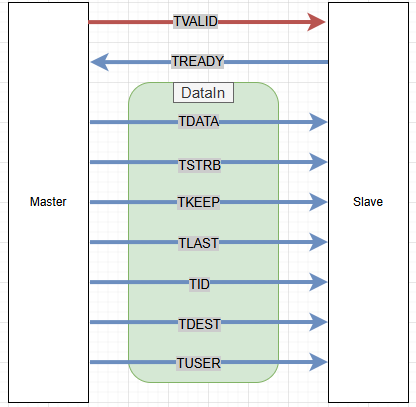
DataIn에는 아래의 signal 들이 있다.
AXI4-Stream port list 한 번의 handshake로 위의
TDATA부터TUSER까지 전체가 다 넘어 간다.
- 파란색은 Optional,
빨간색은 필수 구현 signal
TVALID와 함께ACLK(AXI Clock),AResetn(AXI Reset negative) 3개만 필수이다.TREADY를 high(=1’b1) 로 묶어도 괜찮다.Txxxx : Stream channel이라는 의미
TDATA [ 8n - 1 : 0 ]: byte 단위. Optional이긴 하지만 data다...
xSTRB [ n - 1 : 0 ]: Strobe. 버스에서 유효한 byte 표시.예를 들어,
4byte 데이터(n=4) 보낼 때,STRB를0011로 setting하면
끝의 2byte만 Write 되는 것이다.
이를 통해 Read & Modify 과정을 생략할 수 있다.
TKEEP [ n - 1 : 0 ]: 보내는 데이터의 유효 여부. Strobe와 비슷하다.
Stream의 경우 저장하는 데이터가 아니라서 indexing 을 위한 keep이 따로 존재한다.
keep에 해당하지 않는 데이터는 bus 차원에서 고려하지 않는다.
TLAST: packet의 마지막 handshake 에서 같이 high로 띄워서 보낸다. 끝을 표시
TID [ i - 1 : 0 ]: i 대 d 연결에서 Master 구분을 위한 signals
TDEST [ d - 1 : 0 ]: i 대 d 연결에서 Slave 구분을 위한 signals
TUSER [ i - 1 : 0 ]: Sideband signalsex) 영상 데이터일 경우, frame 의 마지막을 표현(EOF).
네트워크 데이터일 경우, header 표현.
다음 Stream data의 크기가 바뀔 경우 여기에 해당 크기
(예를 들어 4byte였다가 256byte로 보낼 경우256)를 적고
다음 transfer 부터 256(n=32)으로TDATA를 보냄
AXI4-Full
AXI4-Standard, AXI4 라고도 표기 되어 있다
사용처
- multi master, multi slave
- high BW data 전송
특징
- 유연함. AXI3, AHB, APB 들과 Converting이 가능
| Interconnect 구조 및 AXI I/F 구조 |
|---|
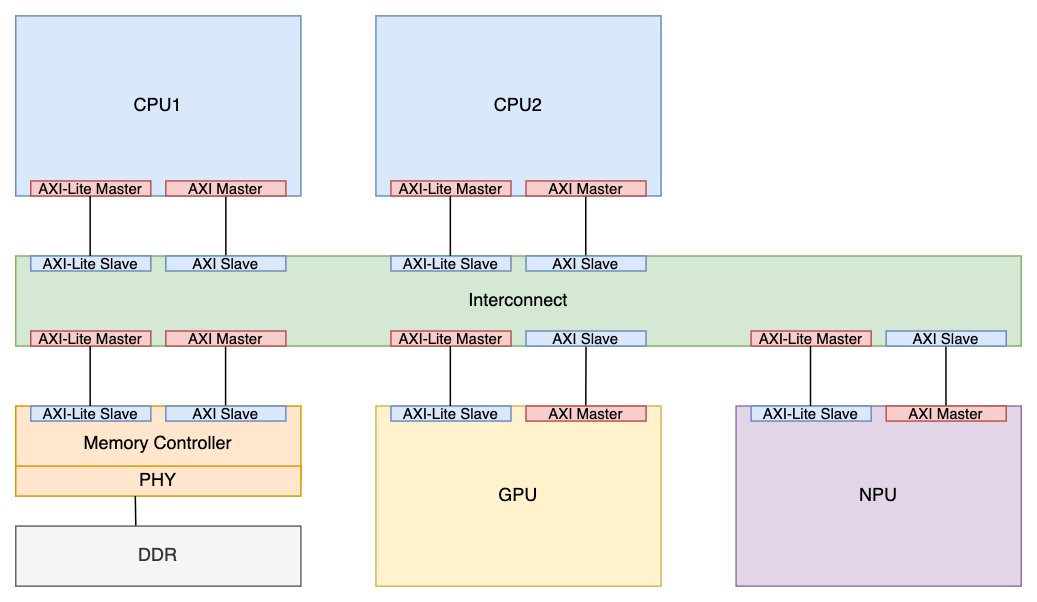 |
Interconnect : MUX + Arbitration.
시스템 전체의 BW = Performance 결정
AXI4 Features
-
Read, Write Transaction 동시 수행 가능
-
Unaligned Data Transfer 지원
| Unalign Transfer |
|---|
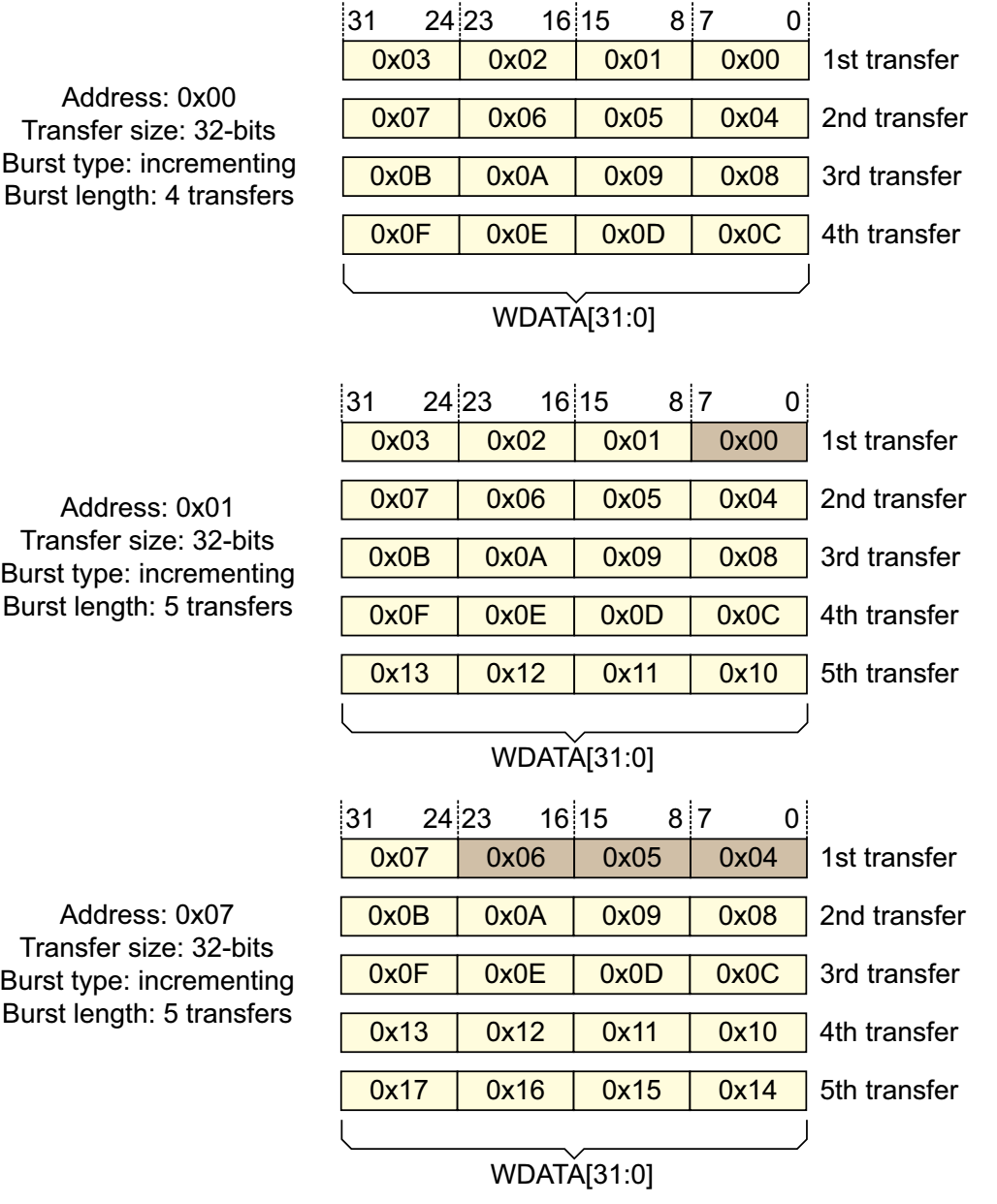 |
Transfer size가 4bytes(32-bits) 지만,
Address 시작 지점은 0x01, 0x07과 같이 align 되지 않았다.
하지만 Read, Write를 눈치껏 해준다.위의 그림은 strb를 사용하는 게 맞지만 아래 그림과 같은 패턴은 strb 로 힘들다.
Unalign Data Transfer 활용
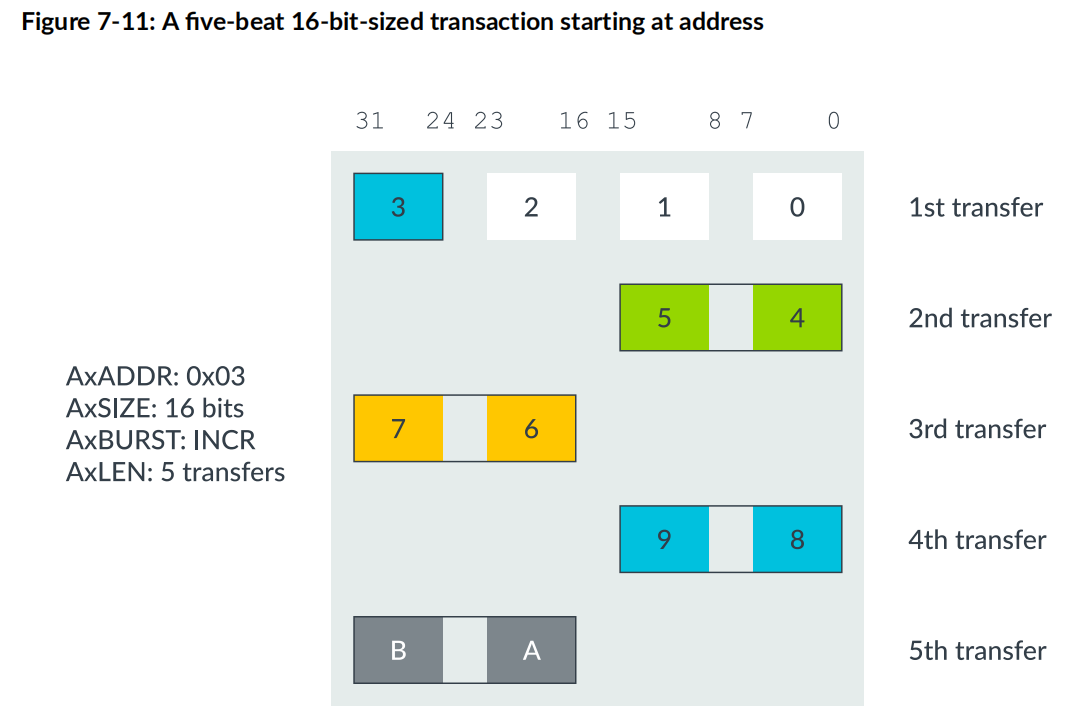
- Multiple Outstanding(미불인=미해결) Address 지원
| Multiple Outstanding |
|---|
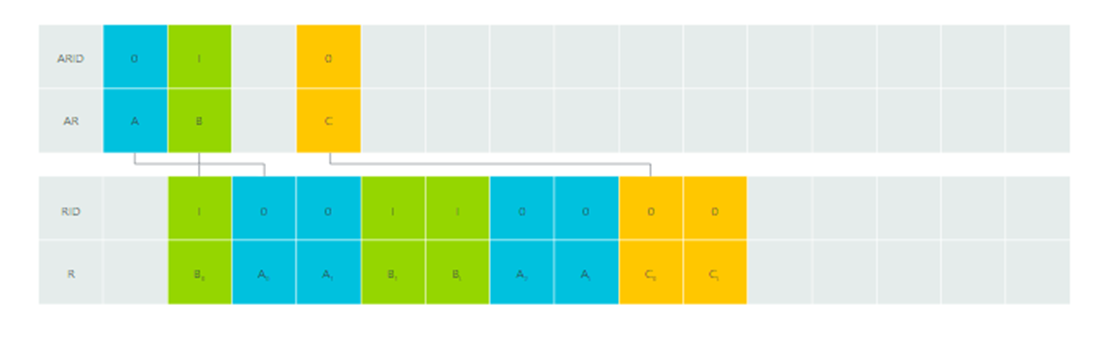 |
A,B,C 순으로 READ Address Transfer를 진행했으나,
A 가 read되는 와중에 B,
B 끝나기 전에 C가 Read 될 수 있다.
- Out-of-Order transaction 지원
| OOO transaction |
|---|
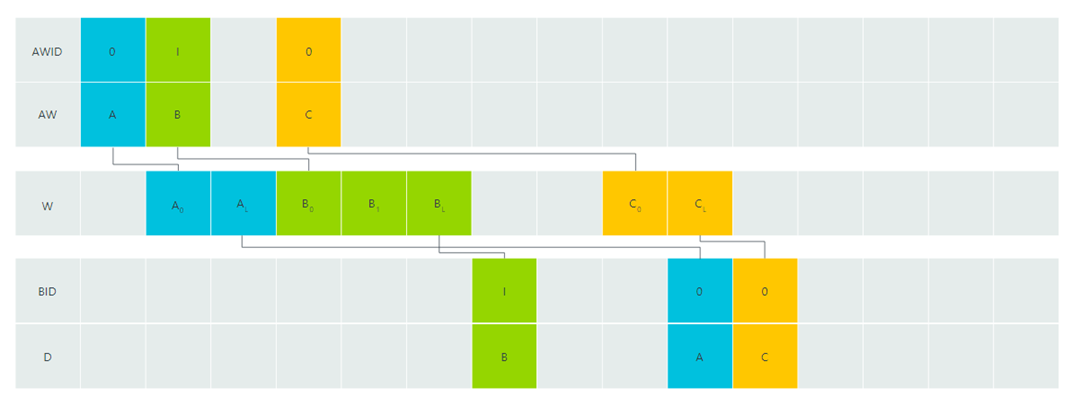 |
같은 Master(ID가 같은 Transaction) 끼리 순서만 맞으면 된다.
A와 C는 0번 Master가 보낸 Write Transaction 이므로 서로 완료 순서(BRESP)가 맞아야 하지만
B는 1번 Master가 요청한 Transaction 이므로 A 끝날 때 까지 기다릴 필요가 없다.
- 4K Boundary 고려
| burst write transaction |
|---|
 |
위의 그림처럼 Burst를 지원하므로,
Base Address 한 개에 여러 Data(Beat)가 전송되는 상황에서 4K Boundary를 주의해야 한다.
AXI4 Signals
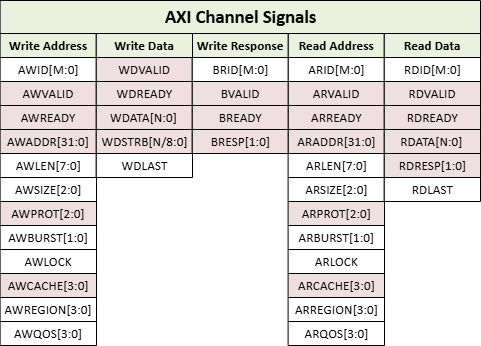
- ID : Master 구분
WID는 AXI3에만 있음.
즉, Write Data Interleaving은 AXI3만 지원Read의 경우 Slave 에서 데이터를 받아야 해서 Performance drop이 발생할 수 있지만
Write는 Master에서 Data를 쌓아놨다가 전송 타이밍을 정할 수 있으므로 Data Interleaving을 지원 안해도 performance drop이 크지 않다.
- Burst
AxLEN [7 : 0]: 한 번의 Transaction에서 전송하는 Transfer(Beat)의 범위.
1부터 최대 2^8 = 256개 까지 가능 → len에 0을 적으면 1로 고려한다.
AxSIZE [2 : 0]: 하나의 Transfer(Beat)의 최대 크기(byte).
2^n. 즉, 최대 2^7 = 128byte. 웬만하면 bus width와 동일한 크기 사용
AxBURST[1 : 0]
0x00(FIXED) : 같은 Address 주소에 접근. 예) FIFO0x01(INCR) : Address가AxSIZE만큼 증가
ex)AxLEN은 0x03,AxSIZE가 0x2,AxADDR이 0x00 이였다면,
4bytes size의 beat를 4개 전송. 즉, 0x00, 0x04, 0x08, 0x0C 에 data 전송0x10(WRAP) : Total Transfer 의 Byte 크기로 align 될 때 까지 증가. 즉, 한 바퀴 돈다. 이를 통해 데이터 받는 순서를 바꿀 수 있다.
ex)AxLEN은 0x03,AxSIZE가 0x2,AxADDR이 0x04 였다면,
4bytes size의 beat를 4개 = 16bytes = 0x10 에서 align 된다.
즉, 0x04, 0x08, 0x0C, 0x00 순서로 data 전송
1 사이클이라도 더 빨리 받기 위해 사용한다.
xDLAST: burst의 마지막 Data에서 1로 assert
- Response
BRESP,RRESP
00(OKAY) :
- Normal access : Success
- Exclusive access : Failure
01: EXOKAY : Exclusive access에서만 사용. Success10: SLVERR : Slave Error. ex) access address 범위 잘못 되었을 때11: DECERR : Decode Error. ex) BUS에서 (data 전송 안됨) 발생한 에러
- LOCK
같은 Address에 둘 이상의 Master가 Write를 하면 문제가 생긴다.
특히, Read & Modify 동작에서 해당 문제를 해결하기 위해
AXI3 에서는 Lock을 걸고,
AXI4 에서는 Exclusive access를 한다.
- Reason : Lock을 걸면 Performance Drop 발생하여 AXI4에서 바뀌었으나, Fail이 나면 더 느려진다.
Lock : ID0이 Lock을 걸면 풀릴 때 까지 ID1은 해당 bus 못 씀.
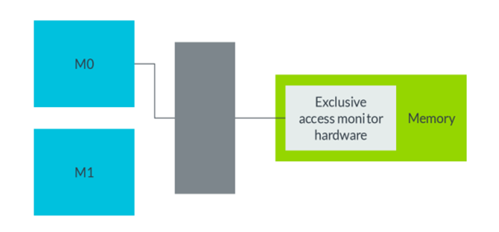
Exclusive : Slave에 Exclusive access monitor HW가 있어야 사용 가능.
AxLOCK: 0이면 Normal, 1이면 Exclusive Access mode
Exclusive Access Monitor 해당 모드를 사용하려면 위의 HW가 Slave에 있어야 한다.
- ID = 0, ARADDR = 0x00 이 전송되면 - Response : EXOKAY
- ID = 1, ARADDR = 0x00 이 전송되면 - Response : EXOKAY
- ID = 0, AWADDR = 0x00, AWDATA = 0x01 이 전송되면 - Response : EXOKAY
- ID = 1, AWADDR = 0x00, AWDATA = 0x03 이 전송되면 - Response : OKAY(Fail)
최종적으로 0x00에는 0x01이 적힘.
- Region
AxREGION: 하나의 Slave의 영역을 나눠서 접근이 가능한 기능.
Address로 똑같은 방식 사용 가능하다.
- Cache
Processor가 지원해야 의미가 있는 data이므로 Interconnect 입장에서는 특별한 의미가 없으나...
AxCACHE[0](B) : bufferable bit.
1. Write Transaction:
- asserted(high) 되면 중간에서 B Response를 보낼 수 있다.
- deasserted(low) 되면 destination에 도착해야 B Response를 보낸다.
2. Read Transaction: ARCACHE[3:2] 가 deasserted, ARCACHE[1]이 asserted (4’b001x)일 때,
- asserted(high) 되면 read data는 destination이나 dest로 진행중인 write 에서 얻을 수 있다.
- deasserted(low) 되면 destination에 도착해야 read data를 얻을 수 있다.
AxCACHE[1](C/M)
- AXI3 : cacheable bit
- AXI4 : modifiable bit.
- Low(deasserted) = Non-modifiable transaction:
transaction이 나눠지거나 병합될 수 없다.
AxADDR,AxREGION,AxSIZE,AxLEN,AxBURST,AxPROT,AxNSE가 변경 불가
AxCACHE의 경우 [0]번 bit를 low로 변경하는 것(bufferable → non-bufferable) 제외하고 변경 불가- High(asserted) = Modifiable transaction:
AxPROT,AxNSE,AxLOCK을 제외하고 다 변경 가능.
AxCACHE[2](RA),AxCACHE[3](WA) : Allocate, Other Allocate
1. Allocate:
- data가 이전에 allocated 되었을 수도 있으므로 cache에서 line을 확인해봐야 함
- data를 cache에 할당하는 것이 권장됨
2. Other Allocate:
- data가 이전에 allocated 되었을 수도 있으므로 cache에서 line 을 확인해봐야 함
- 다시 access 하지 않을 것으로 예상함으로 data 를 cache에 할당하는 것이 권장되지 않음
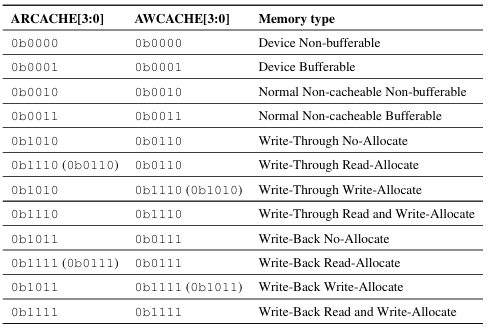
AxCACHEsignals에 따른 Memory Type은 아래와 같다.
Memory type Table
- QoS
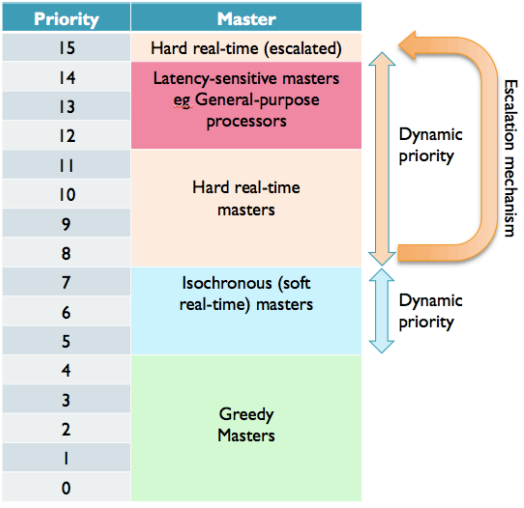
AxQOS: Multi Master 접근 시 우선순위. 높은 값이 높은 우선순위
QoS Priority
- Trustzone
ARM Core에서 제공하는 Trustzone 사용 여부이다.
AxPROT와 마찬가지로 BUS 입장에서 고려 사항이 아니다.
AxPROT[0](P)
-0: normal access
-1: privileged access
AxPROT[1](NS)
-0: Secure transaction
-1: Non-Secure transaction
AxPROT[2](I)
- 0 : data access
- 1 : instruction access
4k boundary
| wrong burst read transaction |
|---|
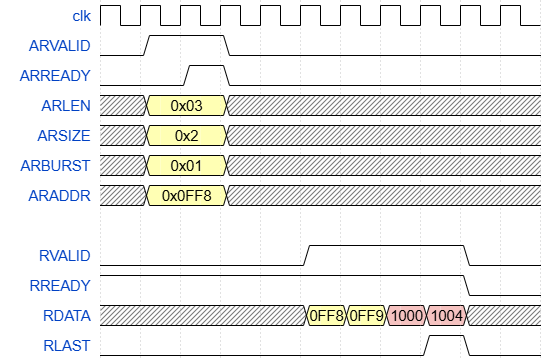 |
4k boundary란 4k = 4096 bytes 마다 끊어 줘야한다. ← Address 는 0x000 ~ 0xFFF 즉, 13번째 bit가 1인 지점
아래와 같이 해당 경계를 넘어서 한 번에 burst 하지 말고, 2 번에 나눠서 burst 해야 한다.
4K boundary 를 고려한 burst read transaction
- 이유
- OS가 관리하는 Virtual Memory에서 page 라는 단위가 있는데, 물리적인 메모리 frame과 동일하다.
해당 크기가 4096 bytes(4K) 일 때 메모리 관리 측면에서 가장 효율적이라는 실험 결과(?) 가 있다더라…- Processor가 Address를 받았을 때, 사용 중인지 확인하기 위해 decoding 과정을 거치는데
4K 기준으로 decoding 할 때가 효율적이었다.- EDC 할 때, 4K 로 하면 효율적이다.
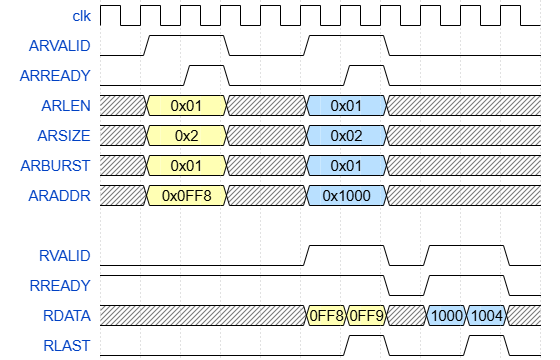
AXI Burst 주의점
| AXI4 Burst Write Transaction |
|---|
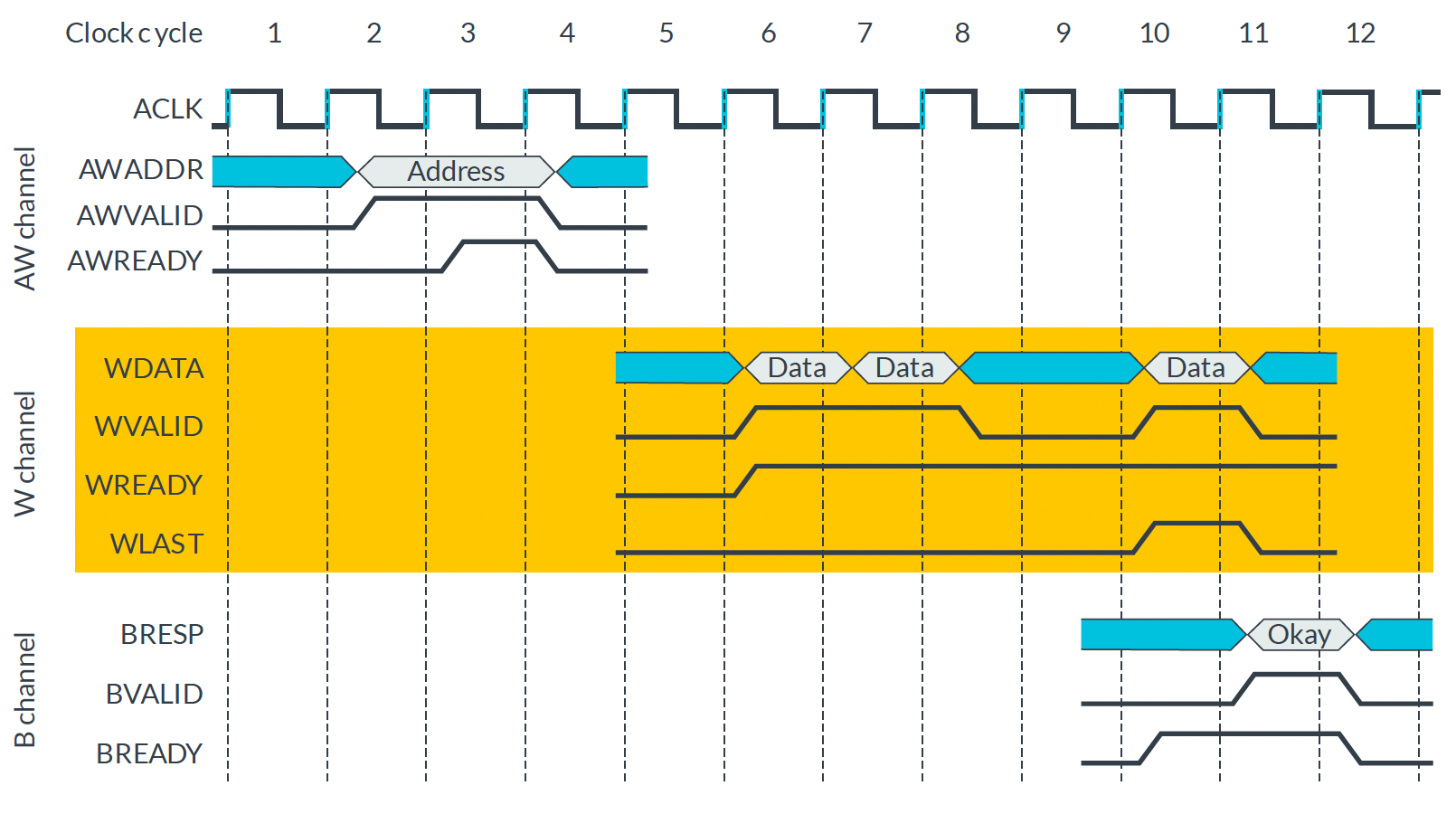 |
| AXI4 Burst Read Transaction |
|---|
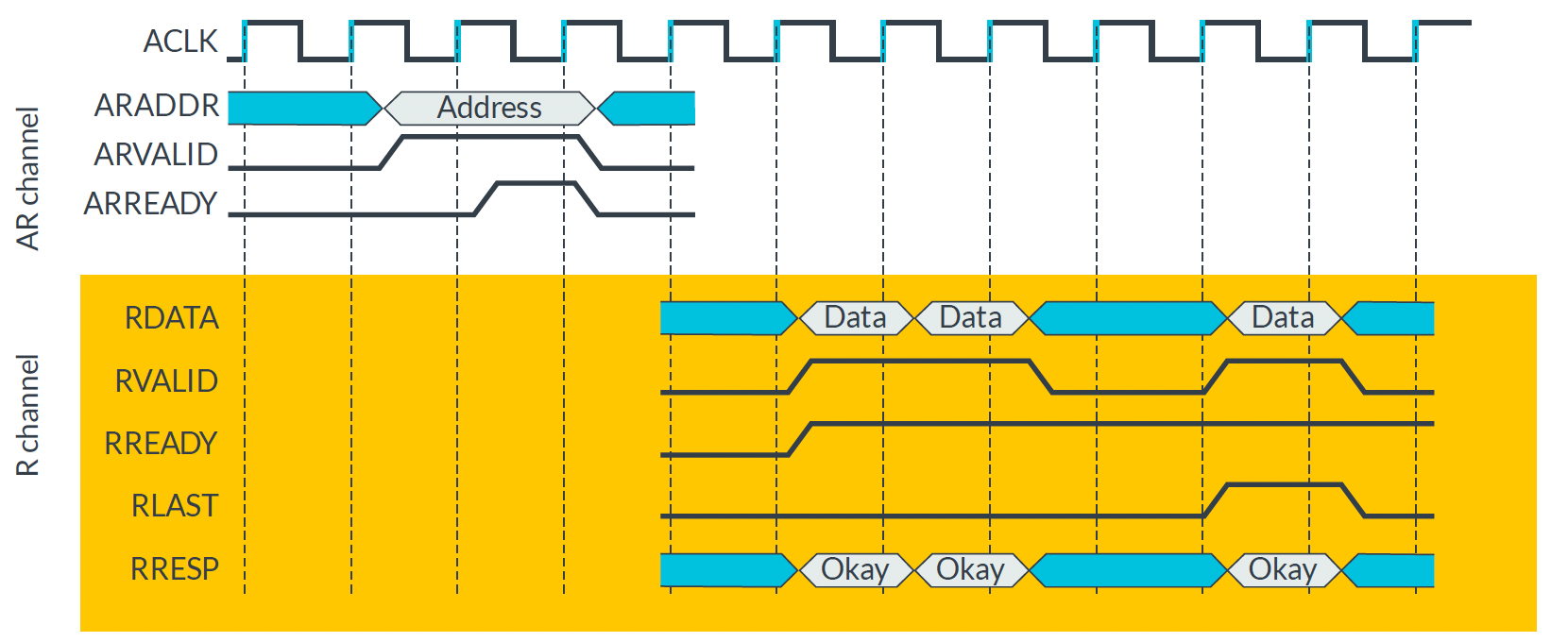 |
- Read Transaction 의 경우
RESP가DATA와 함께 전송된다.
Write Transaction 은 마지막에 한 번만 전송RESP가OKAY가 아니더라도 중간에 멈추면 안된다.
일단 끝까지 전송 완료하고 이후에 처리해야한다.

안녕하세요 글 잘봤습니다. 저도 현재 명지대학교 전자과 3학년 재학중입니다. 혹시 포스트 하신 글들, 특히 Vitis AI와 Systemverilog 내용들은 어떻게 공부하셨는지 궁금합니다. 감사합니다.