Self-Supervised Learning (SSL)이란 말 그대로 모델이 인간의 도움 없이 스스로 학습하는 것이다. 최근 몇 년간 수많은 연구가 이뤄지며 딥러닝 모델의 핵심 기술로 자리잡았다. 현재도 이미지, 음성, 언어 등 다양한 분야에서 뛰어난 능력을 보여주며, 한정된 labeled data 자원을 극복하기 위한 매력적인 학습 방법으로 인식된다.
1. 정의
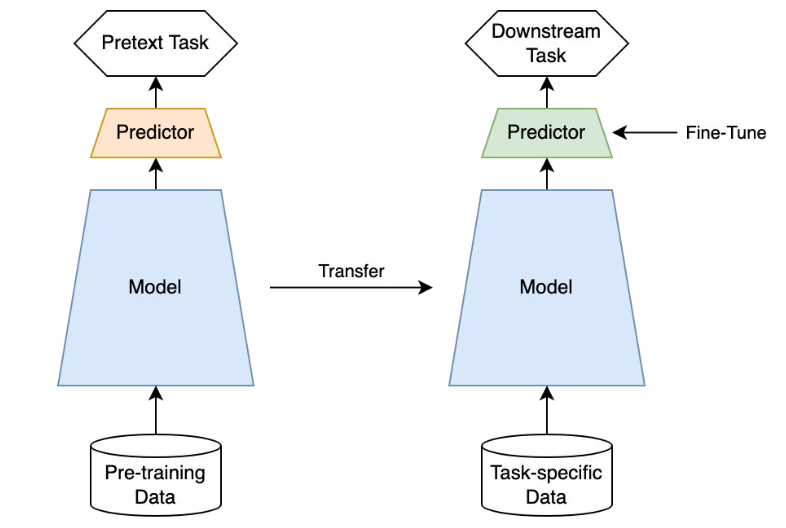
데이터에서 라벨 없이 학습을 진행할 수 있는 머신러닝 기법으로, 두 단계로 나눌 수 있다. Unsupervised learning (비지도 학습)의 일종으로 볼 수 있지만, 모델이 스스로 학습 목표 (pretext task)를 세우고 마치 supervised learning을 하듯이 학습한다는 점에서 구분된다.
1) 먼저 거대한 unlabeled dataset에서 스스로 학습 신호를 생성하여 representation learning을 한다. 이때, 의사 (pseudo) label을 정의하여 마치 supervised learning 처럼 학습한다. 이 과정은 일종의 사전 학습이다.
2) 이후 모델은 downstream task로 전이학습되어 fine-tuning 된다. 이 과정은 소량의 labeled task-specific data로 학습되기 때문에 supervised learning이라고 볼 수 있다.
2. 초기 연구
SSL의 핵심은 데이터의 구조와 관계를 스스로 파악하는데에 있다. 이에 영향을 준 다양한 초기 연구들이 존재한다.
1) Denoising Autoencoder
Vincent, P., Larochelle, H., Bengio, Y., & Manzagol, P. A. (2008): Extracting and Composing Robust Features with Denoising Autoencoders.
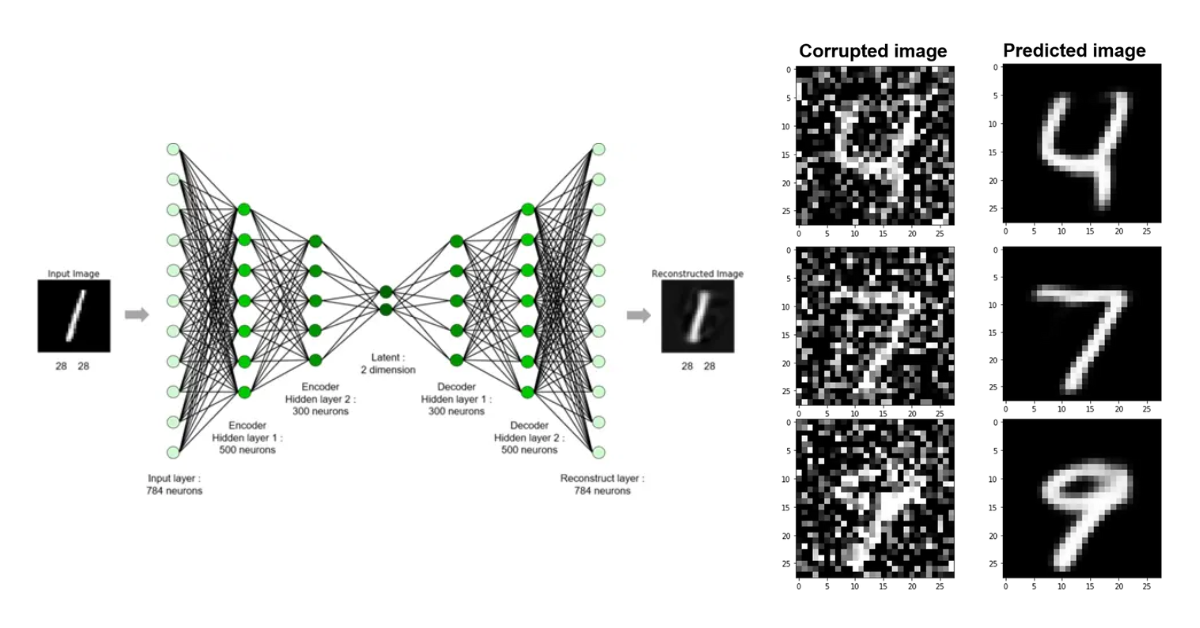 Autoencoder의 변형으로, 입력 데이터에 노이즈를 추가한 후 원래 데이터를 복원하도록 학습한다.
Autoencoder의 변형으로, 입력 데이터에 노이즈를 추가한 후 원래 데이터를 복원하도록 학습한다.
데이터 복원을 통해 유의미한 표현(Representation)을 학습하는 과정으로, SSL의 초기 표현 학습 기법으로 간주된다.
2) Word2Vec
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013): Efficient Estimation of Word Representations in Vector Space.
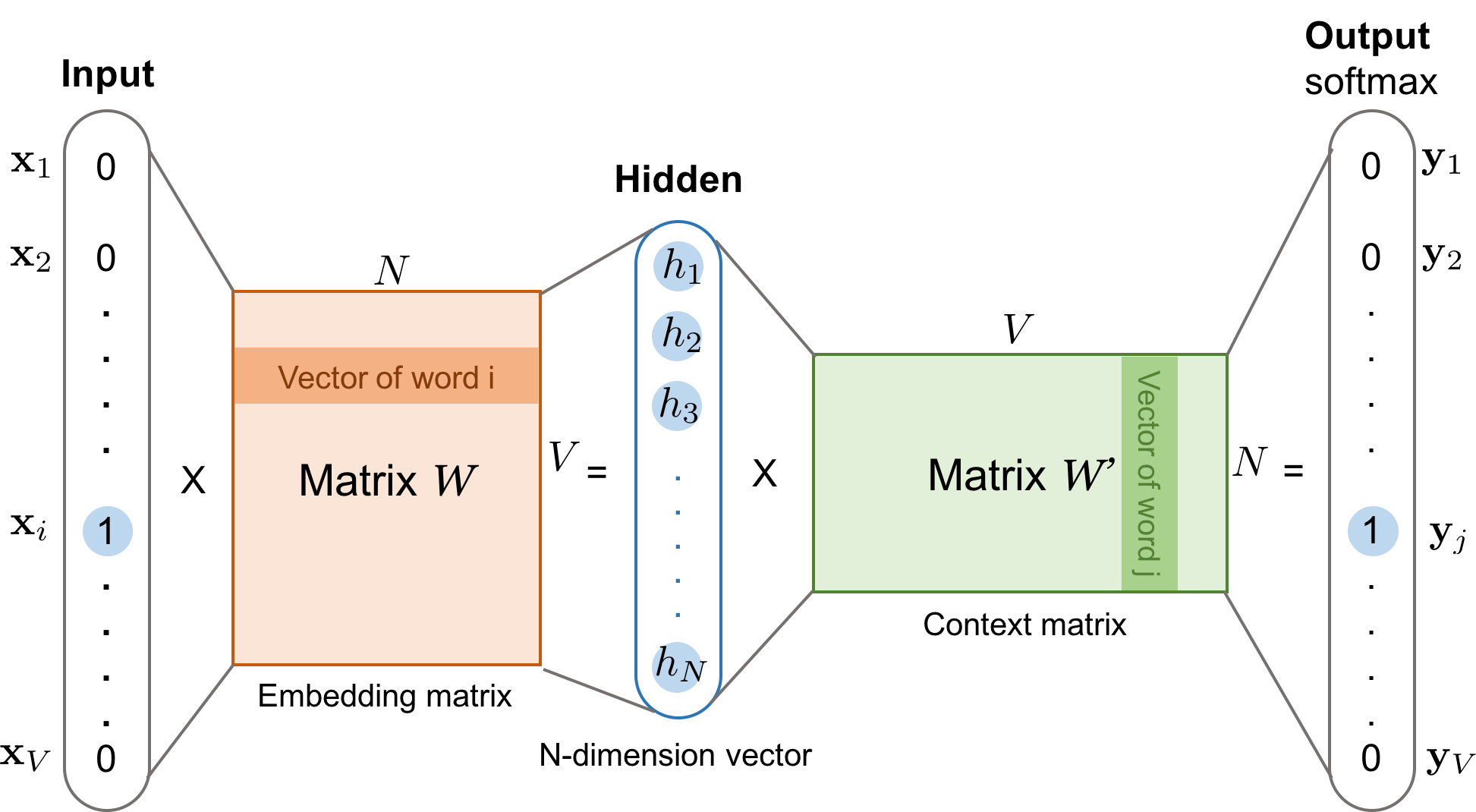 텍스트 데이터를 입력으로 받아 단어 간의 문맥적 관계를 학습한다. 주변 단어를 입력으로 주고 타겟 단어를 예측하거나 (CBOW), 타겟 단어를 입력으로 주고 주변 단어를 예측 (Skip-gram)하는 방법이 있다.
텍스트 데이터를 입력으로 받아 단어 간의 문맥적 관계를 학습한다. 주변 단어를 입력으로 주고 타겟 단어를 예측하거나 (CBOW), 타겟 단어를 입력으로 주고 주변 단어를 예측 (Skip-gram)하는 방법이 있다.
텍스트 데이터에서 라벨 없이 학습 신호를 생성한 대표적인 SSL 기법이다.
3) Autoregressive Modeling
RNN, HMM ...
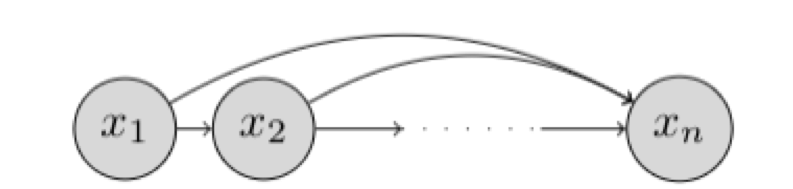 데이터의 순차적 구조를 기반으로 이전 시점의 데이터를 사용해 다음 시점을 예측하는 방식으로, 시계열 및 언어 모델링에 사용된다.
데이터의 순차적 구조를 기반으로 이전 시점의 데이터를 사용해 다음 시점을 예측하는 방식으로, 시계열 및 언어 모델링에 사용된다.
데이터 순차성을 활용해 학습 신호를 생성하는 방법으로, GPT와 같은 모델의 기초가 된다.
3. Methods
3-1. Self-prediction
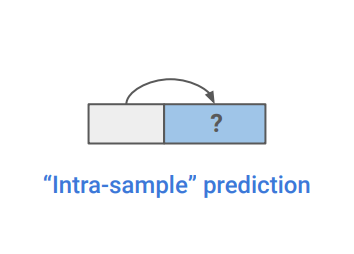
데이터의 한 파트를 다른 파트에 기반하여 예측하는 방식이다. 데이터의 일부분이 비어있는 것처럼 가정한다. Intra-sample prediction이라고도 한다.
1) Autoregressive Generation
이전의 behavior를 통해 미래 behavior를 예측하는 것으로, sequential order가 존재하는 데이터에 대해 적용할 수 있다.
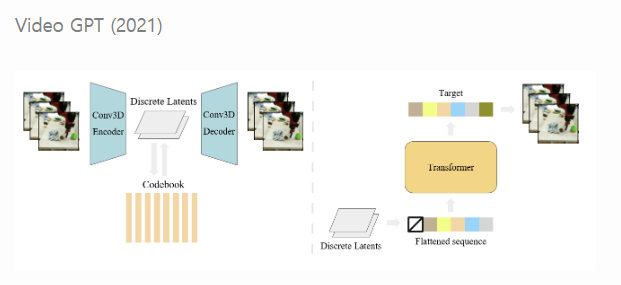
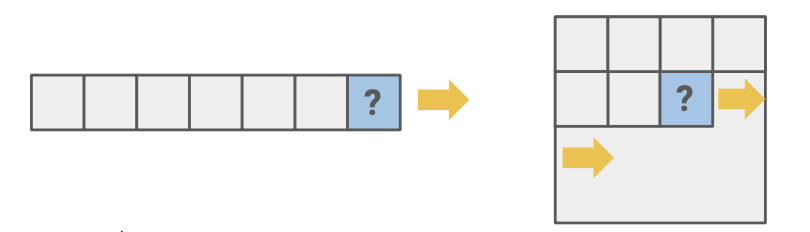 예시: GPT 기반 모델들
예시: GPT 기반 모델들

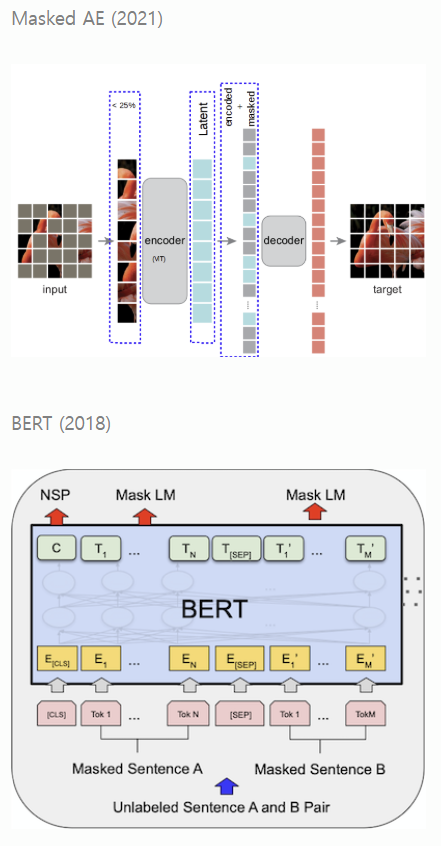
2) Masked Generation
데이터의 일부분을 랜덤하게 마스킹하여, 마치 비어있는 것처럼 간주한다. 이제 이 가려진 부분을 나머지 부분을 이용해 예측한다.

예시: Masked AE, BERT 기반 모델
3) Innate Relationship Prediction
'한 데이터 샘플에 rotation 등의 변형이 가해지더라도 본질적인 로직은 동일할 것'이라는 가정 하에 데이터 내 relationship을 예측하는 방법이다.
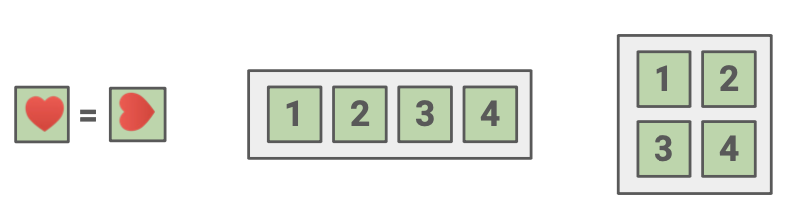
예시: Relative positions, Jigsaw

3-2. Contrastive learning
여러 데이터 간의 관계를 예측하는 것으로, inter-sample prediction이라고도 한다. 비슷한 데이터는 거리가 가깝게, 그렇지 않은 데이터는 멀어지게 학습하는 것을 목표로 한다.
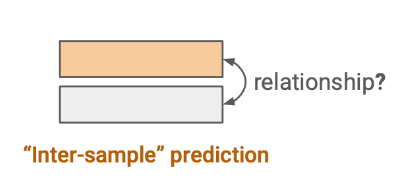
1) Inter-sample Classification
기준이 되는 'anchor data point'와 유사한 positive data 후보와 그렇지 않은 negative data 후보를 분류한다. 이때 positive 후보는 anchor data를 증강하여 만든다.
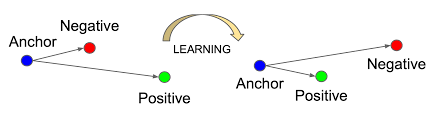
Anchor와 positive 간의 거리를 최소화하고, anchor와 negative 간의 거리를 최대화하는 것을 목표로 하는데, 이를 위해 다소 생소한 손실 함수를 사용한다.
- Contrastive loss: 는 두 데이터 사이 거리, 는 pos/neg.
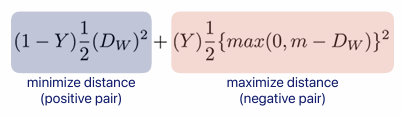
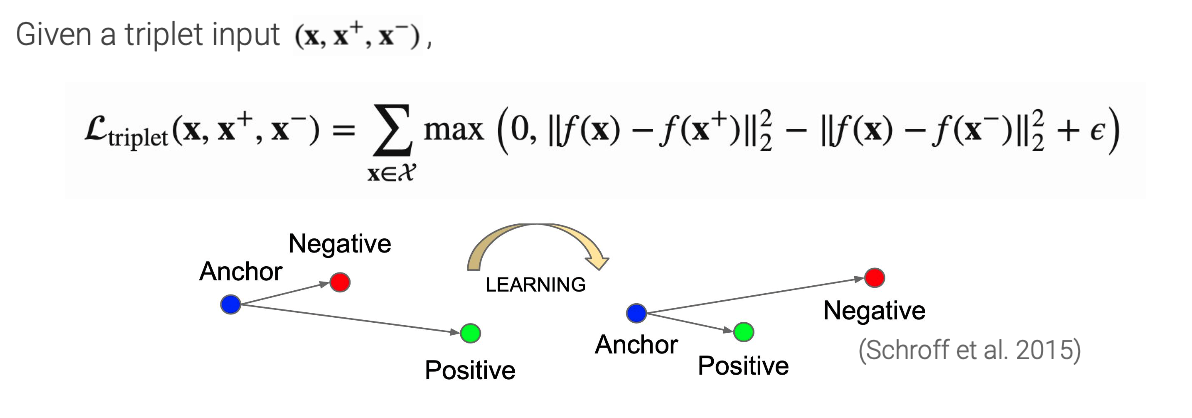
- Triplet loss: Contrastive loss 와 달리 함수 전체를 한 번에 maximize.
- N-pair loss: Triplet loss를 generalize한 것으로, multiple negative samples를 다룬다.
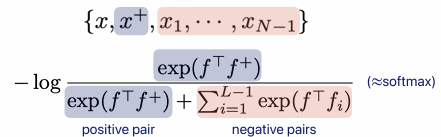
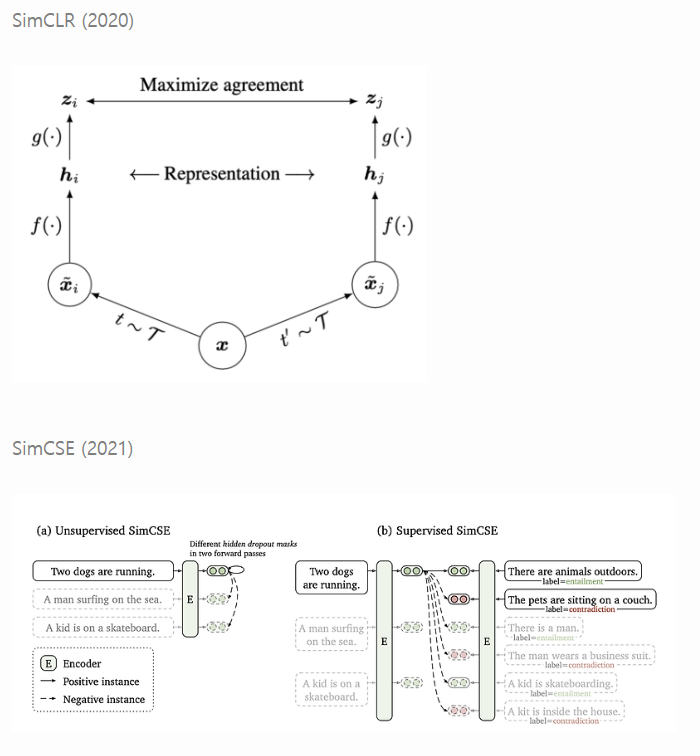
예시: SimCLR (vision), SimCSE (language), COLA (audio)
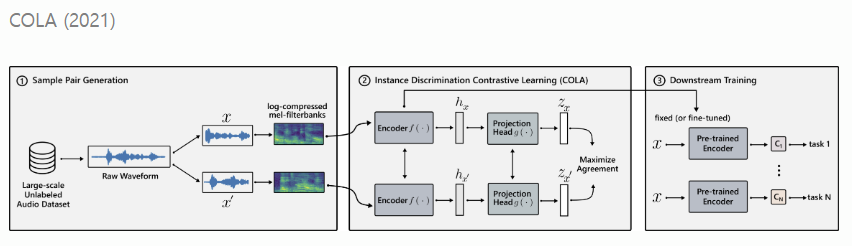
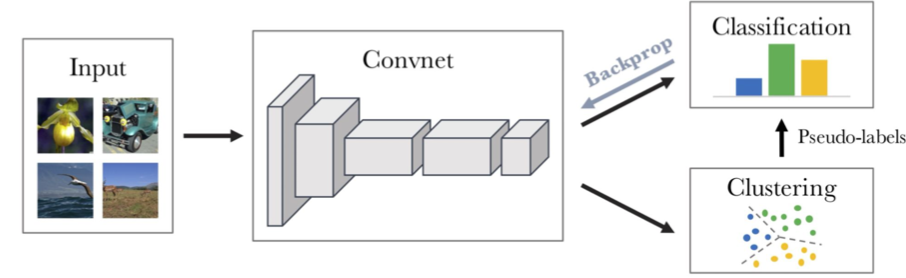
2) Feature Clustering
학습된 feature representation으로 데이터를 클러스터링 한 뒤, 각 class에 의사 레이블 (pseudo label)을 지정하여 분류한다.
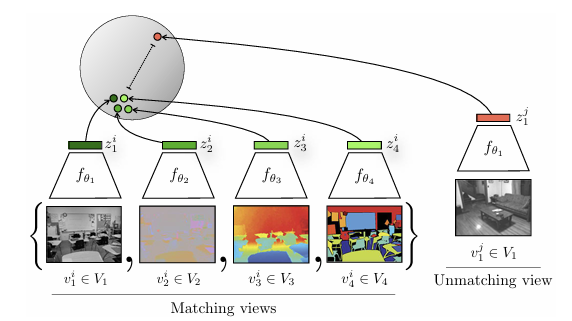
3) Multi-view Coding
입력 데이터를 augment하여 만든 여러 개의 view를 positive sample로 활용한다. 같은 장면에서의 다른 view간의 mutual information을 최대화 하는 방식으로 학습한다.
아래 그림은 CMC (Tian et al., 2021) 로, 4가지의 view를 이용하여 근본적인 scene semantics를 학습하도록 한다.
3-3. Non-Contrastive learning
Contrastive learning에서는 representation collapse (같은 값만 출력하는 현상)을 방지하기 위해 많은 양의 negative sample이 필요하다. 반면, NCSSL은 negative sample 없이 positive pair만 사용한다.
BYOL, SimSiam 등의 모델은 teacher-student의 구조를 활용하여 positive sample만 사용하고도 뛰어난 성능을 보인다.
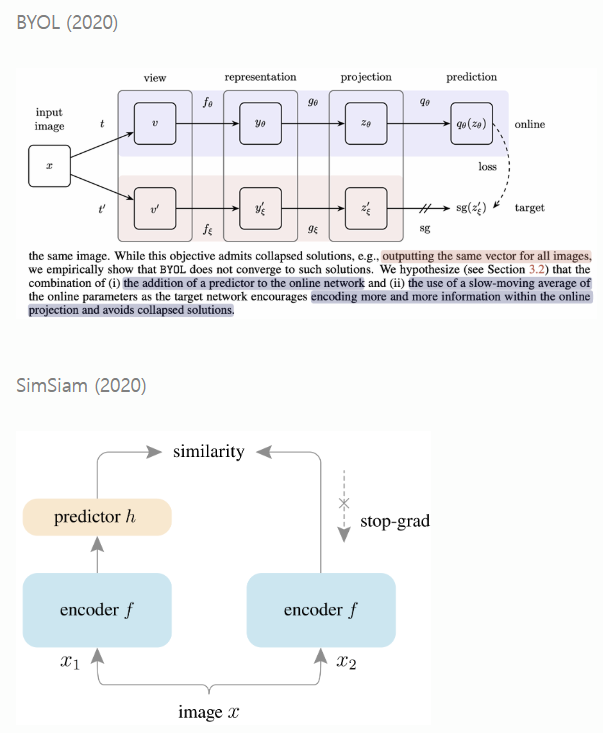
BYOL은 두 개의 신경망(online/target network)을 사용한다. target network는 exponential moving average로 online network의 파라미터로 업데이트 된다.
SimSiam 역시 두 개의 네트워크를 사용하지만, momentum encoder (BYOL의 online network) 를 뺐다. 그리고 encoder 한 쪽에는 stop-gradient를 적용해 collapse를 방지한다.
마무리
오늘은 이렇게 다양한 자기지도학습 관련 내용을 알아보았다. 비교적 최근에 각광받기 시작했으며, LLM과 multi-modal 분야에서 중요성이 급증하고 있는 추세다. 라벨링이 없는 대규모 데이터셋을 효과적으로 훈련할 수 있는 기술들이 계속 떠오르는 것 같다.
앞으로도 다양한 학습 방법에 대해 관심을 기울여야겠다.
참고 자료
서울대학교 김태섭 교수님의 MLDL2 강의 자료
Self-supervised learning (자기지도학습)과 Contrastive learning (대조학습): 개념과 방법론 톺아보기
